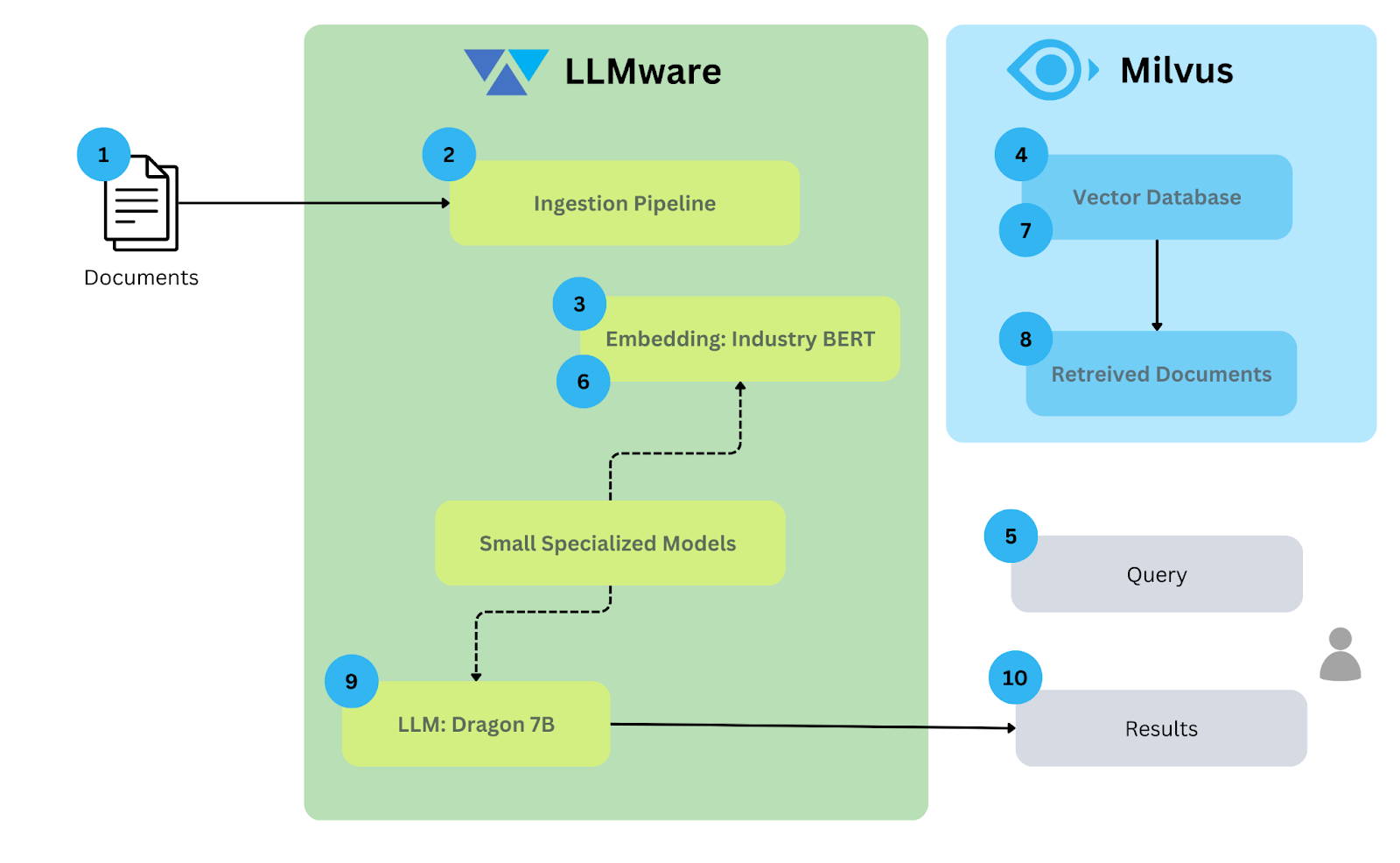
使用 LangChain、LangChain vector store、Fireworks AI DeepSeek V3 和 Ollama bge-m3 构建 RAG 聊天机器人
什么是 RAG
检索增强生成(Retrieval-Augmented Generation,简称 RAG)正引领生成式 AI,尤其是对话式 AI 的新潮流。它将预训练的大语言模型(LLM,如 OpenAI 的 GPT)与存储于向量数据库(如 Milvus、Zilliz Cloud)中的外部知识源相结合,从而让模型输出更准确、更具上下文相关性,并且能够及时融合最新信息。 一个完整的 RAG 系统通常包含以下四大核心组件:
- 向量数据库:用于存储与检索向量化后的知识;
- 嵌入模型:将文本转为向量表示,为后续的相似度搜索提供支持;
- 大语言模型(LLM):根据检索到的上下文和用户提问生成回答;
- 框架:负责将上述组件串联成可用的应用。
核心组件说明
本教程将带你在 Python 环境下,借助以下组件一步步搭建一个初级的 RAG 聊天机器人:
- LangChain: 一个开源框架,帮助你协调大语言模型、向量数据库、嵌入模型等之间的交互,使集成检索增强生成(RAG)管道变得更容易。
- LangChain in-memory vector store: 一个内存型, 临时性 的向量存储,将嵌入数据存储在内存中,并通过精确的线性搜索找到最相似的嵌入。默认的相似度度量是余弦相似度,但可以更改为 ml-distance 支持的任何相似度度量。目前该存储仅适用于演示,不支持 ID 或删除操作。 (如果您需要为应用程序或企业项目提供更具扩展性的解决方案,我们推荐使用 Zilliz Cloud,这是一个基于开源项目 Milvus构建的全托管向量数据库服务,并提供支持最多 100 万个向量的免费套餐。)
- Fireworks AI DeepSeek V3: 这个高级 AI 模型专注于深度数据探索和分析,通过其强大的分析能力提供有力的洞察。它在模式识别和预测分析方面具有优势,特别适合于金融和医疗等领域,在这些领域,揭示隐藏趋势和做出基于数据的决策至关重要。
- Ollama bge-m3: Ollama bge-m3 是一个强大的语言模型,旨在处理复杂的自然语言理解和生成任务。它在提供上下文回应方面表现出色,因此非常适合用于聊天机器人、内容创作和数字助手等应用,在这些应用中,交谈的流畅性和连贯性至关重要。
完成本教程后,你将拥有一个能够基于自定义知识库回答问题的完整聊天机器人。
注意事项: 使用专有模型前请确保已获取有效 API 密钥。
实战:搭建 RAG 聊天机器人
第 1 步:安装并配置 LangChain
%pip install --quiet --upgrade langchain-text-splitters langchain-community langgraph
第 2 步:安装并配置 Fireworks AI DeepSeek V3
pip install -qU "langchain[fireworks]"
import getpass
import os
if not os.environ.get("FIREWORKS_API_KEY"):
os.environ["FIREWORKS_API_KEY"] = getpass.getpass("Enter API key for Fireworks AI: ")
from langchain.chat_models import init_chat_model
llm = init_chat_model("accounts/fireworks/models/deepseek-v3", model_provider="fireworks")
第 3 步:安装并配置 Ollama bge-m3
pip install -qU langchain-ollama
from langchain_ollama import OllamaEmbeddings
embeddings = OllamaEmbeddings(model="bge-m3")
第 4 步:安装并配置 LangChain vector store
pip install -qU langchain-core
from langchain_core.vectorstores import InMemoryVectorStore
vector_store = InMemoryVectorStore(embeddings)
第 5 步:正式构建 RAG 聊天机器人
在设置好所有组件之后,我们来搭建一个简单的聊天机器人。我们将使用 Milvus介绍文档 作为私有知识库。你可以用你自己的数据集替换它,来定制你自己的 RAG 聊天机器人。
import bs4
from langchain import hub
from langchain_community.document_loaders import WebBaseLoader
from langchain_core.documents import Document
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langgraph.graph import START, StateGraph
from typing_extensions import List, TypedDict
# 加载并拆分博客内容
loader = WebBaseLoader(
web_paths=("https://milvus.io/docs/overview.md",),
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
class_=("doc-style doc-post-content")
)
),
)
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
all_splits = text_splitter.split_documents(docs)
# 索引分块
_ = vector_store.add_documents(documents=all_splits)
# Define prompt for question-answering
prompt = hub.pull("rlm/rag-prompt")
# 定义应用状态
class State(TypedDict):
question: str
context: List[Document]
answer: str
# 定义应用步骤
def retrieve(state: State):
retrieved_docs = vector_store.similarity_search(state["question"])
return {"context": retrieved_docs}
def generate(state: State):
docs_content = "\n\n".join(doc.page_content for doc in state["context"])
messages = prompt.invoke({"question": state["question"], "context": docs_content})
response = llm.invoke(messages)
return {"answer": response.content}
# 编译应用并测试
graph_builder = StateGraph(State).add_sequence([retrieve, generate])
graph_builder.add_edge(START, "retrieve")
graph = graph_builder.compile()
测试聊天机器人
Yeah! You've built your own chatbot. Let's ask the chatbot a question.
response = graph.invoke({"question": "What data types does Milvus support?"})
print(response["answer"])
示例输出
Milvus 支持多种数据类型,包括稀疏向量、二进制向量、JSON 和数组。此外,它还支持常见的数值类型和字符类型,使其能够满足不同的数据建模需求。这使得用户能够高效地管理非结构化或多模态数据。
优化小贴士
在搭建 RAG 系统时,合理调优能显著提升性能与效率。下面为各组件提供一些实用建议:
LangChain 优化建议
为了优化 LangChain,需要通过高效地构建链路和代理来减少工作流程中的冗余操作。使用缓存避免重复计算,从而加快系统速度,并尝试采用模块化设计,确保模型或数据库等组件能够轻松替换。这将提供灵活性和效率,使您能够快速扩展系统,而无需不必要的延迟或复杂性。
LangChain in-memory vector store 优化建议
LangChain 内存型向量存储只是一个临时性的向量存储,它将嵌入数据存储在内存中,并进行精确的线性搜索以找到最相似的嵌入。它的功能非常有限,仅适用于演示。如果您计划构建一个功能完整甚至生产级的解决方案,我们推荐使用 Zilliz Cloud,这是一个基于开源项目 Milvus构建的全托管向量数据库服务,并提供支持最多 100 万个向量的免费套餐。)
Fireworks AI DeepSeek V3 优化建议
DeepSeek V3经过优化,专注于高级推理和响应质量,使其成为需要深度上下文理解的RAG应用程序的强大选择。通过实施多阶段排名来提高检索效果,确保只有最相关的文档作为上下文。使用结构化提示,清晰划分检索内容与用户查询之间的界限。调整温度(0.1-0.2)以提高准确性,并微调top-k/top-p以控制响应。通过预计算嵌入和缓存常见查询数据来最小化延迟。利用Fireworks AI的API优化,批量处理多个请求,减少处理开销。在高需求场景中实施动态扩展策略,确保模型在负载下的性能保持一致。如果在多层架构中使用,针对高价值查询部署DeepSeek V3,同时利用较小的模型进行基础查询。
Ollama bge-m3 优化建议
为了优化在检索增强生成设置中的Ollama bge-m3组件,建议实施一个明确定义的缓存策略以存储经常访问的数据,这将显著减少响应时间并提升整体延迟。此外,通过调整检索模型的参数来提升查询相关性,以最大化质量,利用嵌入进行上下文增强。批量处理查询可以进一步提高吞吐量。最后,持续监控性能指标,以识别瓶颈并进行基于数据的调整,确保在生产环境中具有强大的可扩展性和响应能力。
通过系统性实施这些优化方案,RAG 系统将在响应速度、结果准确率、资源利用率等维度获得全面提升。 AI 技术迭代迅速,建议定期进行压力测试与架构调优,持续跟踪最新优化方案,确保系统在技术发展中始终保持竞争优势。
RAG 成本计算器
估算 RAG 成本时,需要分析向量存储、计算资源和 API 使用等方面的开销。主要成本驱动因素包括向量数据库查询、嵌入生成和 LLM 推理。RAG 成本计算器是一款免费的在线工具,可快速估算构建 RAG 的费用,涵盖切块(chunking)、嵌入、向量存储/搜索和 LLM 生成。能帮助你发现节省费用的机会,最高可通过无服务器方案在向量存储成本上实现 10 倍降本。
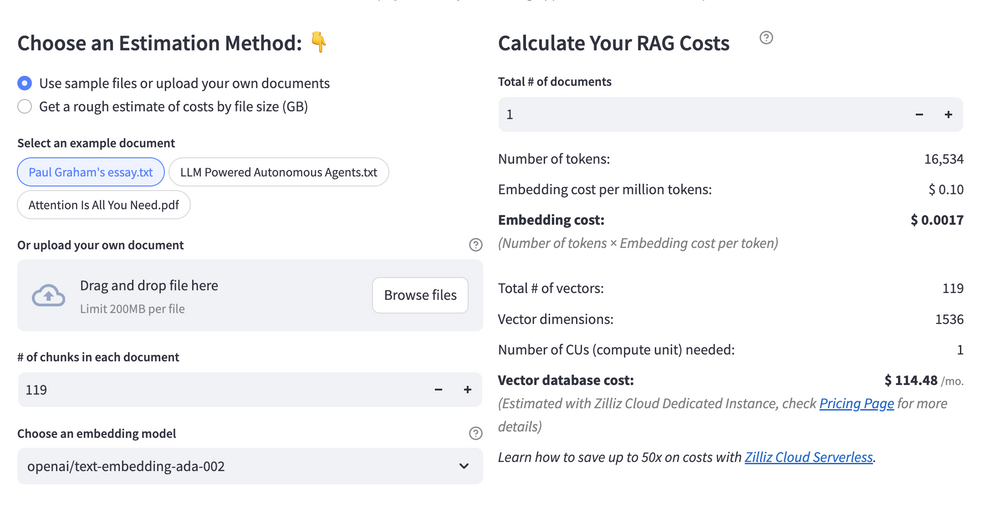 Calculate your RAG cost
Calculate your RAG cost
收获与总结
通过深入了解这个教程,您已经迈出了进入智能应用世界的巨大一步!您学习了如何从零开始构建一个强大的RAG系统,结合了四个关键组件:LangChain作为灵活的框架,协调您的管道,LangChain Vector Store作为您快速检索上下文的记忆库,Fireworks AI的DeepSeek V3带来前沿的语言理解,生成类人响应,以及Ollama的bge-m3嵌入模型将文本转化为丰富的语义向量,以捕捉意义。它们共同形成了一个无缝的流程——摄取数据,智能索引,并精确检索信息,以增强您LLM的响应。您已经看到LangChain如何简化复杂的工作流程,向量数据库如何实现快速的相似性搜索,以及现代嵌入模型如bge-m3如何使上下文检索比以往更智能。此外,您还获得了优化性能的专业技巧,比如调整块大小和在速度与准确性之间找到平衡,确保您的系统不仅强大而且高效!
但等等,精彩还不止于此!您还发现了像免费RAG成本计算器这样的工具,可以估算开支并在不破产的情况下进行实验,使您能够无畏地进行迭代。这不仅仅是按照步骤操作;这关系到获得创新的信心。想象一下您接下来可以构建的东西:真正理解细微差别的聊天机器人,挖掘金色见解的研究助手,或是将知识与想象力融合的创意工具。您在这里获得的技能是您的发射平台。那么,继续吧——调整那些参数,尝试新的数据集,推动RAG的边界。人工智能驱动的应用的未来掌握在您手中,一次一个查询。让我们构建一些惊人的东西吧! 🚀
欢迎反馈!
我们很期待听到你的使用心得与建议! 🌟 你可以:
- 在下方留言;
- 加入 Milvus Discord 社区,与全球 AI 爱好者一起交流。 如果你觉得本教程对你有帮助,别忘了给 Milvus GitHub 仓库点个 ⭐,这将激励我们不断创作!💖