



大语言模型限制
缺乏领域特定信息
LLM 仅基于公开数据集训练,缺乏领域特定信息、或专有信息等非公开数据。
容易产生幻觉
LLM 只能根据其现有数据提供信息和答案,如果超出该范围,LLM 会提供错误或捏造的信息。
成本高昂且响应较慢
LLM 针对每次查询都会收费,不论是否重复,因此成本高昂。且高峰期 LLM 响应较慢,有所延迟。
无法获取最新信息
LLM 训练成本十分高昂(训练 GPT-3 的成本可高达 140 万美元),因此 LLM 无法及时更新其知识库。
Token 数量限制
LLM 会限制可添加至查询 Prompt 中的令牌数量。例如,ChatGPT-3 设置了 4,096 个 Token 的限制,GPT-4(8K)设置了 8,192 个 Token 的限制。
不变的预训练数据
LLM 使用的预训练数据可能包含过时或不正确的信息,且这些数据无法更正或删除。
Zilliz Cloud:打破限制,增强大语言模型
更新并扩展 LLM 知识库,提升 LLM 回答准确性
Zilliz Cloud 支持个人开发者及企业在 LLM 外安全存储领域特定信息和最新的机密或私有数据。用户提问时,LLM 应用先使用 embedding 模型将用户问题转化为向量。随后,在 Zilliz Cloud 中进行相似性搜索,并获得返回的 top-K 个最相似结果。最后,合并返回结果与原始问题,生成一个包含上下文的新 Prompt,以便 LLM 给出更准确的回答。
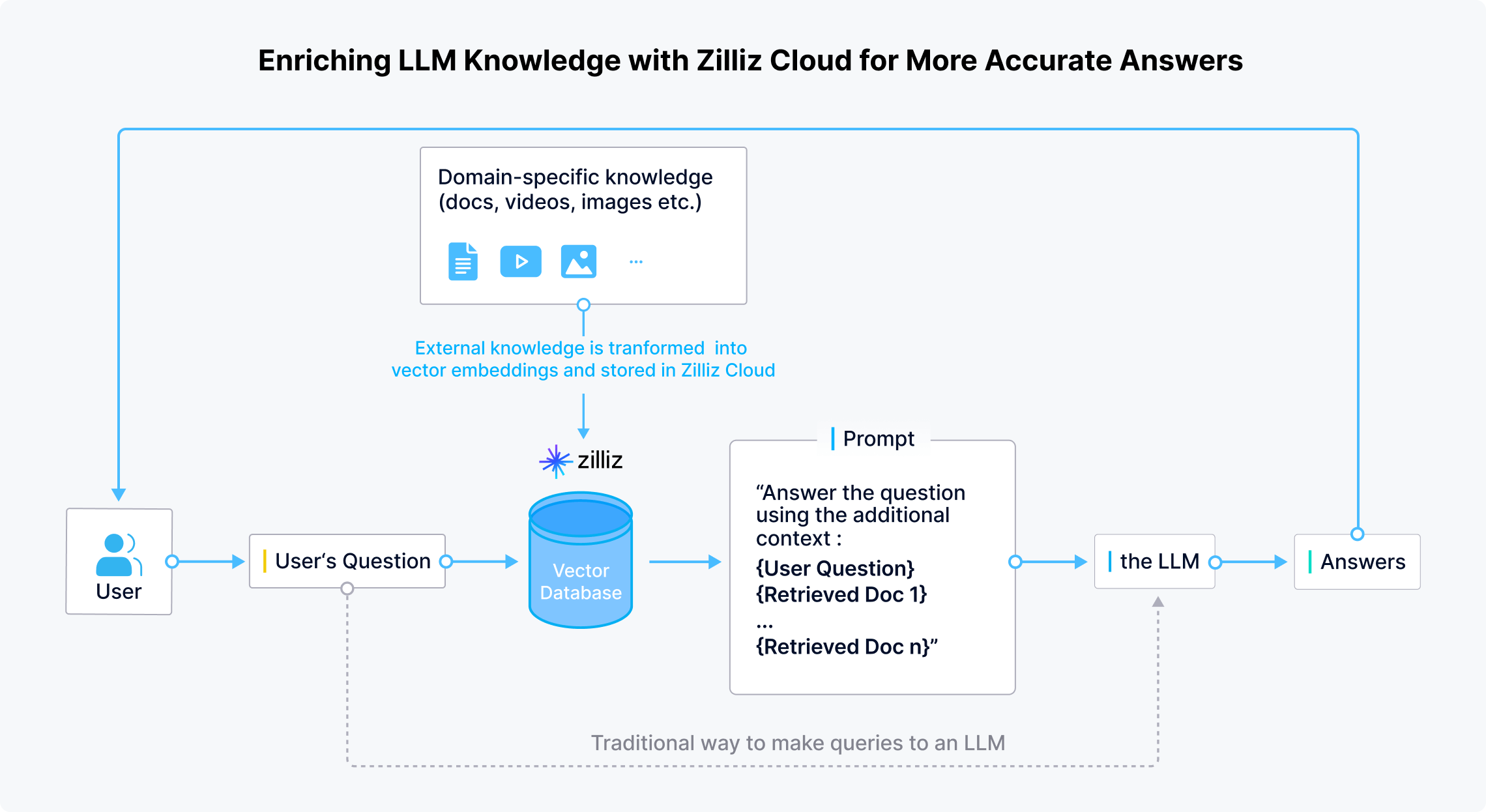
使用 Zilliz Cloud 与 GPTCache 降低 LLM 使用成本及响应时间
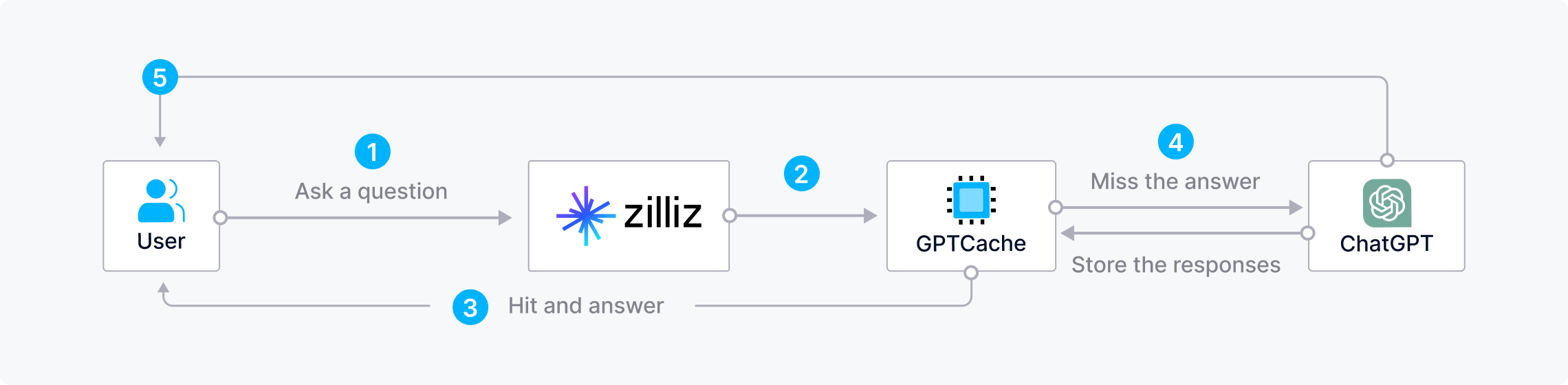
频繁向 LLM 询问重复或相似问题会造成浪费资源且增加使用成本。在高峰期,LLM 的响应时间也会变得漫长。使用云原生向量数据库 Zilliz Cloud 和开源语义缓存 GPTCache 可以有效存储 LLM 响应结果,从减少 AI 应用响应时间,降低开发成本。当用户提出问题时,Zilliz Cloud 会先在 GPTCache 中检查是否已经存有相同问题的回答。如有,Zilliz Cloud 则会快速返回答案。否则,Zilliz Cloud 会将问题发送至 LLM 寻求答案,并存储该问答对以便后续使用。
CVP 技术栈
ChatGPT/LLMs + 向量数据库 + Prompt 即代码
CVP 技术栈(ChatGPT/LLMs + 向量数据库 + Prompt 即代码)的热度与日俱增。以下示例的 OSS Chat 应用采用了 CVP 技术栈并展示了向量数据库如何增强 LLM 应用。
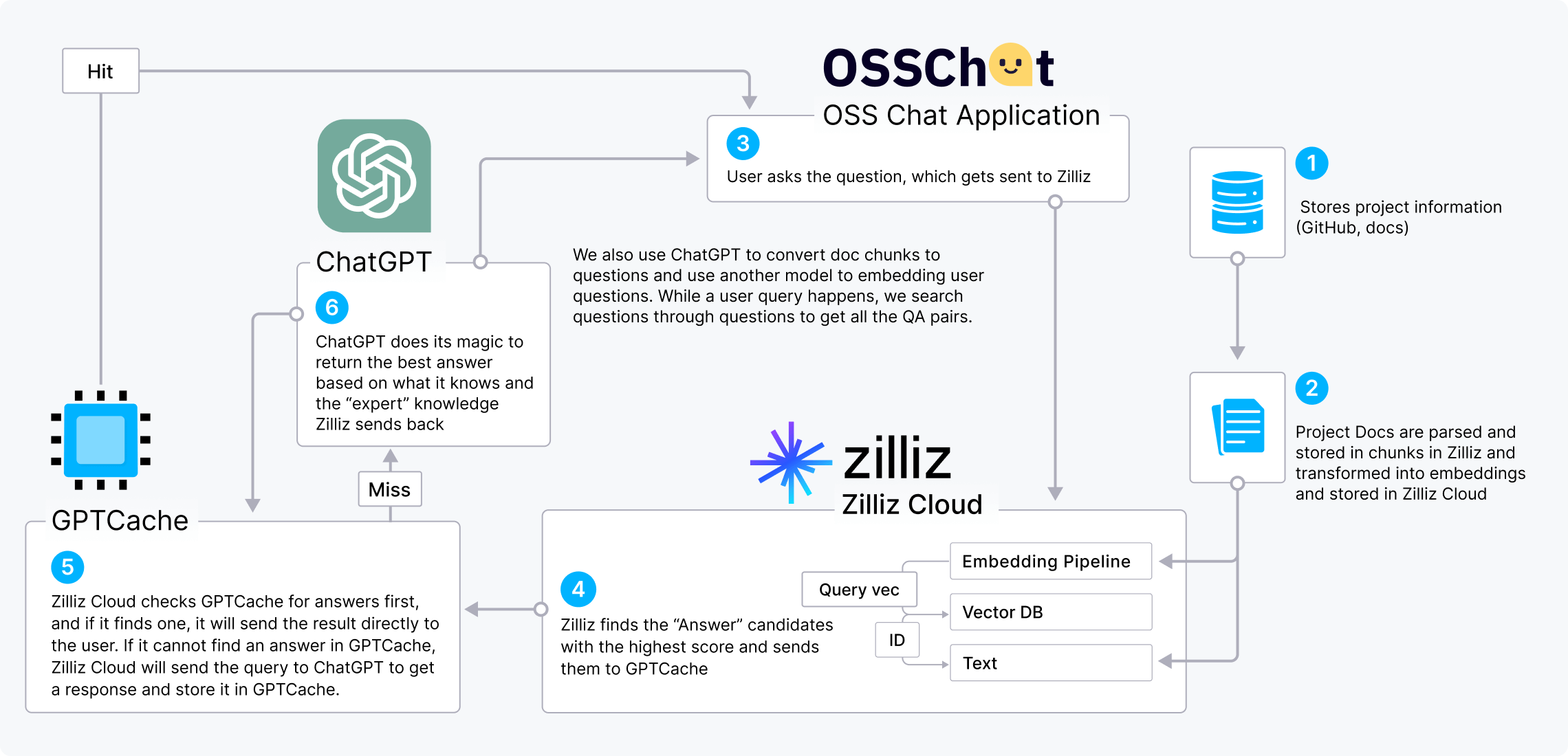
OSS Chat 聊天机器人可以回答用户问题,为用户提供开源项目相关的技术知识。OSS Chat 基于GitHub 上的仓库和文档,将各种开源项目的信息以 embedding 向量的形式收集并存储在 Zilliz Cloud 中。当用户查询关于开源项目的问题时,OSS Chat 会先在 Zilliz Cloud 向量数据库中进行向量相似性搜索以找到 top-k 个最相关问题。随后,OSS Chat 将得到的结果与原始用户问题相结合,从而生成一个带有上下文的新 Prompt,并传入 ChatGPT。该流程可以通过增加问题上下文有效提升 ChatGPT 回答的准确性。
此外,还可以在 CVP 技术栈中整合 GPTCache,进一步降低成本支出,提升 LLM 响应速度。
使用 Milvus 和 Zilliz Cloud 搭建 LLM 应用
了解 Milvus 和 Zilliz Cloud 如何为生成式 AI 应用赋能。
- OSS Chat
- PaperGPT
- NoticeAI
- Search.anything.io
- IkuStudies
- AssistLink AI
Milvus 集成了众多 AI 项目
OpenAI、LangChain、LlamaIndex 等众多火热 AI 项目都继承了 Zilliz Cloud 和 Milvus 以进一步提升向量召回能力。



