



解码 LangChain|用 LangChain 和 Milvus 从零搭建 LLM 应用
如何从零搭建一个 LLM 应用?不妨试试 LangChain + Milvus 的组合拳。
作为开发 LLM 应用的框架,LangChain 内部不仅包含诸多模块,而且支持外部集成;Milvus 同样可以支持诸多 LLM 集成,二者结合除了可以轻松搭建一个 LLM 应用,还可以起到强化 ChatGPT 功能和效率的作用。
本文为解码 LangChain 系列,将深入探讨如何借助 LangChain 与 Milvus 的力量增强 LLM 应用,以及如何构建和优化 AIGC 应用的小秘籍!
LangChain + 向量数据库:解决幻觉问题
LangChain
LangChain 是一种用于开发 LLM 应用的框架。LangChain 设计如下:
- Data-aware:连接 LLM 与其他数据源
- Agentic:允许 LLM 与 LangChain 环境交互
LangChain 包括许多模块,例如 Models、Prompts、Memory、Indexes、Chains、Agents 和 Callbacks。对于每个模块,LangChain 都提供标准化的可扩展接口。LangChain 还支持外部集成,甚至可实现端到端。LLM Wrapper 是 LangChain 的核心功能,提供了许多 LLM 模型,例如 OpenAI、Cohere、Hugging Face 等模型。
向量数据库
LangChain 提供一系列有用的大型语言模型(LLMs),可满足多样的用户需求。LangChain 的另一大亮点是其扩展功能——集成各种向量数据库(如 Milvus、Faiss 等),因此可以很好地进行语义搜索。
LangChain 通过 VectorStore Wrapper 提供了标准化的接口,从而简化数据加载和检索的流程。例如,大家可以使用 LangChain 的 Milvus 类,通过from_text方法存储文档的特征向量,然后调用similarity_search方法获取查询语句的相似向量(也就是在向量空间中找到距离最接近的文档向量),从而轻松实现语义搜索。
通过 ChatGPT-Retrieval-Plugin 项目可以发现,向量数据库在 LLM 应用中起着至关重要的作用,它并不只局限于语义检索的用途,还包括其他用途,比如:
- 存储问答上下文。这是 Auto-GPT 和 BabyAGI 等 LLM 平台提供的有用功能。这种功能可以增强LLM 应用对于上下文的理解和记忆能力。
- 为 GPTCache 等 LLM 平台提供语义缓存,优化性能并节省成本。
- 实现文档知识功能,降低 LLM 应用产生幻觉概率(如:OSSChat)。
如何解决 ChatGPT 的幻觉问题?
人工智能系统经常会产生“幻觉”、捏造事实、返回错误信息,更有甚者把 ChatGPT 形容为“一本正经地说废话“。因此,幻觉问题会降低 ChatGPT 回答的可信度,向量数据库可以有效解决幻觉问题。
其工作流程如下图所示:
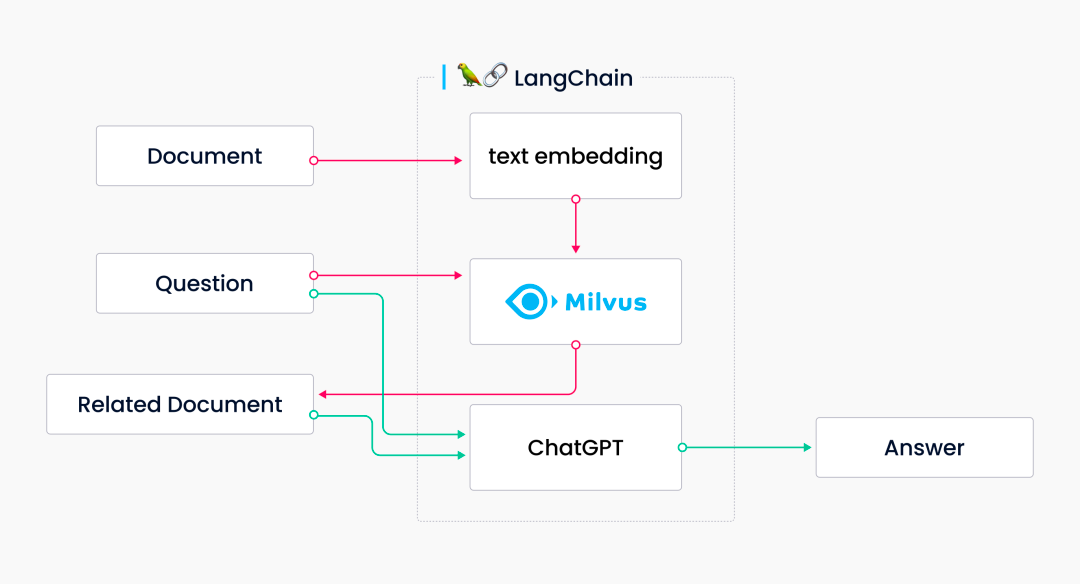 7194.png
7194.png
首先,在 Milvus 中存储由官方文档转化而来的文本向量。然后,在响应问题时搜索相关文档(如上图中红色箭头流程所示)。ChatGPT 最后根据正确的上下文回答问题,从而产生准确的答案(如上图中绿色箭头流程所示)。
上述事例说明,用户无需标记、训练数据或进行额外开发和微调,只需将文本数据转化为向量并存储在 Milvus 中,即可解决 ChatGPT 的幻觉问题。LangChain + Milvus + ChatGPT 的组合可实现文本存储。ChatGPT 的答案也是基于参考文档库中的内容而返回的,可大大提高其回答的准确性。这样一来,聊天机器人可以基于正确的知识进行问答,减少出现“胡说八道”的可能性。
接下来分享一个 LangChain + Milvus + ChatGPT 的组合一个实际的具体应用场景:
如果我是一名 Milvus 社区管理员,每天需要回答各种社区相关问题,那么可以搭建一套智能应用来大大提高自己的工作效率。首先,可以将所有 Milvus 官方文档存储起来。然后,将这些文档作为必要的上下文知识提供给 ChatGPT。这样一来,如果用户问道:“如何使用 Milvus 搭建聊天机器人?”,构建的聊天机器人可以搜索与用户问题语义相关的官方文档。这种方法无需进行额外的数据训练,但能够大大提升工作效率和回答准确性。
LangChain + Milvus :搭建智能应用
搭建流程
- 前提条件
运行 pip install langchain命令安装 LangChain。
安装向量数据库 Milvus 或注册 Zilliz Cloud ——大家可以选择在本地系统上安装和启动开源向量数据库 Milvus 或者选择全托管向量数据库 Zilliz Cloud 服务,免去运维部署的麻烦。Zilliz Cloud 简单易用,具备高扩展性,提供超强性能,本教程将使用 Zilliz Cloud。
- 加载知识库数据
首先,需要使用标准格式加载数据。也就是说,我们需要将文本切成小块,从而确保传入 LLM 模型的数据为一段段小的文本片段。
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Milvus
from langchain.document_loaders import TextLoader
loader = TextLoader('state_of_the_union.txt')
documents = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
docs = text_splitter.split_documents(documents)
接下来,我们需要将小块的文本片段转化为向量并存储在向量数据库中。以下示例代码使用 OpenAI 的模型和 Zilliz Cloud 向量数据库。
embeddings = OpenAIEmbeddings()
vector_db = Milvus.from_documents(
docs,
embeddings,
connection_args={
"uri": "YOUR_ZILLIZ_CLOUD_URI",
"user": "YOUR_ZILLIZ_CLOUD_USERNAME",
"password": "YOUR_ZILLIZ_CLOUD_PASSWORD",
"secure": True
}
)
- 查询数据
加载数据后,可以在问答链(Chain)中使用这些数据,下述代码主要解决上文提到的“幻觉”问题。
使用 similarity_search方法将查询语句转化为特征向量,然后在 Zilliz Cloud 中搜索相似向量,以及相关的文档内容。
query = "What did the president say about Ketanji Brown Jackson"
docs = vector_db.similarity_search(query)
运行 load_qa_chain获取最终答案。这是一个最通用的用于回答问题的接口,它加载一整个链,可以根据所有数据库中文本进行问答。以下示例代码使用 OpenAI 作为 LLM 模型。在运行时,QA Chain 接收input_documents和 question,将其作为输入。input_documents是与数据库中的query相关的文档。LLM 基于这些文档的内容和所提问的问题来组织答案。
from langchain.chains.question_answering import load_qa_chain
from langchain.llms import OpenAI
llm = OpenAI(temperature=0)
chain = load_qa_chain(llm, chain_type="stuff")
chain.run(input_documents=docs, question=query)
Milvus:更适合 AIGC 应用的向量数据库
如果想要提高应用的可靠性,需要使用数据库存储文本向量。但为什么选择 Milvus 向量数据库?
- 助力语义搜索:不同于传统数据库,Milvus 专为向量设计,可以实现语义检索。
- 高度可扩展:支持灵活扩展,用户可轻松存储和检索十亿级向量数据。此外,可扩展性对于检索速度和效率至关重要。
- 支持混合查询:Milvus 支持混合查询,将向量相似性搜索和标量过滤相结合,可满足不同的搜索场景和要求。
- 提供丰富的 API:Milvus 提供多语言的 API,包括 Python、Java、Go、Restful 等,方便用户在各种应用中集成和使用 Milvus。
- 集成多种 LLM 模型:Milvus 可与多种主流 LLM 模型集成,包括 OpenAI Plugin、LangChain、LLamaIndex 等,方便用户灵活定制化其应用。
- 多种部署版本和配置:Milvus 提供多种版本(如:MilvusLite 版、单机版、分布式版和云服务版),可以轻松适应不同类型的应用场景,即可支持小型项目,也可适用于企业级数据检索。
如何优化 AIGC 应用?
人工智能领域中不断涌现各种新技术、新突破。本文将介绍 2 种优化 AIGC 应用的秘籍,帮助你进一步提升 AIGC 应用的性能和搜索质量。
提升 AIGC 应用程序性能:使用 GPTCache
如果想要提升 AIGC 应用性能并节省成本,可以试试 GPTCache。这个创新项目旨在创建语义缓存,以存储 LLM 响应。
具体而言,GPTCache 会缓存 LLM 的响应。在收到问题时,GPTCache 使用向量数据库检索相似的问题并查询此前缓存的响应。这样一来,应用便可快速准确地回答用户。GPTCache 可有效避免重复问题多次调用 LLM 接口所产生的费用以及需要等待的响应时间,从而提供更快速、更准确的答案,使 AIGC 应用更受用户欢迎。
提高搜索质量:调整 Embedding 模型和 Prompt
此外,我们可以通过微调 Embedding 模型和 Prompt 达到提高搜索质量的效果。Embedding 模型在 AIGC 应用中不可或缺,发挥着将文本转化为向量的关键作用。微调模型具体指调节模型从而使其注重关注某些关键词或短语,并调整模型权重和评分机制,从而迎合用户的需求和偏好。微调后,模型可以更准确地理解用户问题、将其进行分类,从而提高语义搜索结果的准确性和相关性,返回准确的结果。
影响搜索质量的另一重要因素是搜索提示。例如“我有什么可以帮助您的?”或“您有什么想法?”都可以用于提示用户该输入何种提问。通过测试和修改这些提示,可以提高搜索结果的质量和相关性。如果你的应用程序面向特定行业或人群,可以在提示内加入一些行业术语,这样有助于指导用户进行更相关的搜索查询。
总之,LangChain + Milvus 的组合方式可以帮助开发者从零开始搭建 LLM 应用。LangChain 为 LLM 提供了标准化且易用的接口,Milvus 则提供出色的存储和检索能力,从而整体提升 ChatGPT 等应用的功能和效率。
本文最初发布于 The Sequence,已获得转载许可。
🌟「寻找 AIGC 时代的 CVP 实践之星」 专题活动即将启动!
Zilliz 将联合国内头部大模型厂商一同甄选应用场景, 由双方提供向量数据库与大模型顶级技术专家为用户赋能,一同打磨应用,提升落地效果,赋能业务本身。
如果你的应用也适合 CVP 框架,且正为应用落地和实际效果发愁,可直接申请参与活动,获得最专业的帮助和指导!联系邮箱为 business@zilliz.com。
如果在使用 Milvus 或 Zilliz 产品有任何问题,可添加小助手微信 “zilliz-tech” 加入交流群。
欢迎关注微信公众号“Zilliz”,了解最新资讯。
 陈室余
陈室余


