



Llama2 评测大公开!知识库场景下能否赶超 ChatGPT?
AIGC 人狂喜!最近,Meta AI 发布了大语言模型 Llama2,为大模型的开发者注入了一剂强心针,因为无论从其灵活性、竞争力还是便捷性来看,都有不小的优势。
具体来看:
- Llama2 为开源产品且可免费商用,ChatGPT 为闭源产品;
- Llama2 开放了 70 亿、130 亿和 700 亿三种不同参数的模型,对比市面上已有的开源大模型,Llama2 无论在模型规模还是回答质量方面,都显示出强劲的竞争力;
- Llama2 支持的上下文长度多达 4096 个 token;
- Llama2 提供了微调好的 Llama2 chat,可以直接用于对话机器人场景。
当然,这并不意味着 Llama2 完美无缺。如大家所知,业界对于 LLM 的应用场景正处于探索阶段,在应用过程中仍有一定的局限性,例如会出现知识过期和幻觉 (hallucination) 等缺点。为此,AI 社区提出了一种被广泛认可的优化方法,即基于检索增强的文本生成 (Retrieval Augmented Generation, RAG)。
本文将在给定外部知识的情况下,测试 Llama-2-13b-chat 和 ChatGPT(GPT-3.5) 在回答质量上有怎样的区别。
测试方法
在正式开始测试之前,首先需要明确 RAG 的可行性。
在开放领域问答任务中,RAG 方法能够利用外部知识的搜索结果来提升模型性能。与传统基于知识库的方法不同,RAG 采用的 LLM 已经包含了大量的基于公开互联网的知识。通过预先嵌入这些知识,LLM 能够理解一定的逻辑关系,再结合外部知识库中搜索到的相关信息,用 RAG 和 LLM 组合通常可以灵活满足用户的问答需求。
目前,市面上的一些工具已经可以提供知识库和 LLM 结合的功能。例如,Towhee 开源框架中集成了 Llama2 模型,并可以支持灵活的数据处理逻辑。我们通过一个Towhee Pipeline 的小例子来验证 RAG 的可行性。如果我们直接问 Llama2 “如何安装 Towhee”,因为 Llama2 本身并没有 Towhee 项目相关的知识,回答是完全不相关的信息。如果用一个Towhee Pipeline 把外部知识和问答历史组装进问题,就能让 Llama2 根据所提供信息给予高质量的回答。
from towhee import pipe, ops
p = (
pipe.input('question', 'docs', 'history')
.map(('question', 'docs', 'history'), 'prompt', ops.prompt.question_answer())
.map('prompt', 'answer', ops.LLM.Llama_2('llama-2-13b-chat'))
.output('answer')
)
# Retrieve chat history and additional knowledge.
history=[('What is Towhee?', 'Towhee is a cutting-edge framework designed to streamline the processing of unstructured data through the use of Large Language Model (LLM) based pipeline orchestration.')]
knowledge = ['You can install towhee via `pip install towhee`.']
# Query with retrieved info.
question = 'How to install it?'
answer = p(question, knowledge, history).get()[0]
# Example answer is:
# To install Towhee, you can use the following command in your terminal or
# command prompt:\n```\npip install towhee\n\n```\n\n\n\n'
如果想更多了解如何使用 Towhee 构建更完整、复杂的知识增强问答机器人,可以参考开源项目 Akcio(https://github.com/zilliztech/akcio)
其次,由于此次并不是评测 LLM 的逻辑推理能力,因此使用了比较浅层次的文档问答方式,即根据一段召回出来的文本询问逻辑不是非常复杂的问题。现阶段 Llama2 对英文有相对好的支持,因此所有问答均采用英文。Llama2 和 ChatGPT 均采用了相同的问题(prompt)。
测试案例
一切准备就绪后,便可以开始测试了,我们选定了 5 个不同的案例,为展示方便,所有问答案例经过裁剪,点击每个案例标题可查看问答原文:
案例1 新闻知识问答
首先我们考虑的是解决 LLM 的时效性问题,即让 LLM 根据时效性好的新闻语料进行回答。在这里我们模拟一段金融场景下的问答,给出一段大众投资小鹏汽车的金融新闻,让 ChatGPT 和 Llama2 使用相同的问题进行回答。
Prompt
You are an information retriever. You need to use content in [Knowledge] to answer question, when the knowledge is different from your knowledge, the [Knowledge] has higher priority.
[Knowledge Start]:
(这里是一段关于 Volkswagen 投资 XPENG 的新闻原文)
[Knowledge End]:
How much did Volkswagen invest to XPENG?
Answer
ChatGPT: Volkswagen invested about $ 700 million in Xpeng,takeing a 4.99% stake in the Chinese EV maker.
Llama2-chat: According to the information provided in the Knowledge section, Volkswagen invested around $700 million in Xpeng, which is approximately 4.99% stake.
分析:在给出清晰的语料以及简单问题的情况下,两个模型都可以正确理解知识并且根据文本内容生成准确的答案。
案例2 错误的召回知识问答
接下来我们模拟一下检索出来的知识和问题并不相关的情况,测试能否诚实地回答不知道。在这里我们给出大众投资小鹏汽车的金融新闻,问一下奥迪对小鹏的投资情况,注意,这个问题不是在新闻中可以获得的信息。
Prompt
You are an information retriever. You need to use content in [Knowledge] to answer question, when the knowledge is different from your knowledge, the [Knowledge] has higher priority.
[Knowledge Start]:
(这里是上面关于 Volkswagen 投资 XPENG 的新闻原文,和问题关于 Audi 的投资无关)
[Knowledge End]:
How much did Audi invest to XPENG?
Answer
ChatGPT:
As per the provided knowledge, there is no mention of Audi directly investing in Xpeng. The information states that Volkswagen, which is the parent company of Audi, has signed a separate deal with its longtime Chinese joint venture partner, SAIC Motor, to jointly develop new Audi-branded EVs for the Chinese market. However, there is no information about Audi making any direct investment in Xpeng. The investment of about $700 million in Xpeng was made by Volkswagen, not Audi.
Llama2-chat: According to the information provided, Audi did not invest any money in Xpeng. It's Volkswagen that invested around $700 million in Xpeng, acquiring a 4.99% stake in the Chinese EV maker.
分析:这两个答案都明确指出了给定的知识不支持所提出的问题,说明两者都能够识别语料无法回答所给出的问题,这能让 RAG 类应用正确处理问题错误或召回文档不相关的情况。
案例3 非常识性知识问答
前两个案例说明 Llama2 和 ChatGPT 都能很好应对一些常识性的问题。这里我们测试一下针对专业领域知识的问答情况。不同于常识性的知识可由训练数据的增多得到加强,小众的专业领域知识以及人为编造的知识一般很少会被全面地蕴含在 LLM 之中。这个例子中,我们提供一段和游戏 Minecraft 中红宝石相关的语料。
Prompt
You are an information retriever. You need to use content in [Knowledge] to answer question, when the knowledge is different from your knowledge, the [Knowledge] has higher priority.
[Knowledge Start]:
(一段游戏 Minecraft 中红宝石相关的语料)
[Knowledge End]:
How to get the ruby?
Answer
ChatGPT:
[ChatGPT 的回答](ChatGPT 根据文本描述了通过玩游戏、做每日任务、收集物品以及现金购买红宝石的方法。)
Llama2-chat: [Llama2-chat 的回答](Llama2-chat 根据文本描述了通过玩游戏、做每日任务、收集物品以及可以现金购买红宝石的方法。)
分析:在这个案例中,两个模型都根据一个非常具体的知识(召回文档中在游戏里获取红宝石的方法)正确回答了问题。这意味着两者也可以针对一些专业领域内的知识组织答案。
案例4 复杂来源的输入
在真实业务场景中,经常会遇到多种多样的文本格式。前面的例子中召回文本都是易读的良好格式,但现实中文档的来源可能多种多样、格式复杂甚至会出现乱码的情况。
这个例子中,我们使用 GitHub 中的一个与 Tailwind CSS 有关的 README.md,测试两个模型在复杂文本格式上面的表现。我们挑选的这个文档由于大量的 Markdown 记号导致内容比较复杂。
Prompt
You are an information retriever. You need to use content in [Knowledge] to answer question, when the knowledge is different from your knowledge, the [Knowledge] has higher priority.
[Knowledge Start]:
(一段包含着许多 Markdown 记号的不易阅读的文本)
[Knowledge End]:
Tell me some websites that use Tailwind
Answer
ChatGPT:
[ChatGPT 的回答](给出了 Markdown 文本中使用 Tailwind 的例子。)
Llama2-chat:
[Llama2-chat 的回答](没有使用 Markdown 中的文本,而是根据自己的知识来回答问题,回答相关性不强。) 分析:ChatGPT 在复杂的 Markdown 标记中能够正确理解文本信息,并且给出了高质量的回答,而 Llama2-chat 没有采纳文本中的信息,完全凭借自身知识给出了一个质量较低的回答。
案例5 内容相同经过排版矫正的输入
是不是 Llama2 无法正确地处理内容本身呢?在文本格式不规整的情况下,如何让 Llama2 能够正确理解并利用里面的知识呢?在这里,我们将同样的内容由 ChatGPT 改写成较容易阅读的文本,然后再使用同样的问题测试 Llama2 的回答质量。
Prompt
You are an information retriever, You need use content in [Knowledge] to answer by question, when the knowledge is different from your answer, the [Knowledge] have higher priority.
[Knowledge Start]:
(ChatGPT 将上段格式非常复杂的文本,转换成了更易阅读的文本)
[Knowledge End]:
Tell me some websites that use Tailwind?
Answer
Llama2-chat:
[Llama2-chat 的回答](正确地理解了经过整理的文本,并根据文本进行了回答)
分析:这次 Llama2 给出了和 ChatGPT 质量相近的回答。
03.模型效果评测总结
在经过文本的格式化后,Llama-2-chat 理解了文本的内容并且给出了回答,由此我们可以窥一斑而知全豹,了解 Llama2 在知识库应用上与 ChatGPT 的差异,在不涉及非常复杂的推理(即需要阅读大量不相邻上下文并且需要复杂的逻辑推导)的知识库应用中,我们根据具体案例得出了以下结论:
- 两者都可以在现实类的知识下完成根据问答的问题。
- 两者都可以判断出知识是否可以支持问题的回答。
- 两者都可以用人为定义的知识回答问题。
- Llama2-chat 对于知识文本的格式和质量要求高于 ChatGPT。
- 在将低质量的知识文本转换为高质量的知识文本后,可以帮助 Llama2-chat 进行问题的回答。
在这里我们直接给出了能够帮助 LLM 回答问题的知识。如果想在知识库场景下帮助 Llama2 一类的 LLM 更好地发挥出它的效用,在知识库中如何检索出来相关度高的内容,如何把文本变为更容易让 LLM 理解的格式,如何组装问题(prompt),都是直接影响到回答效果的重要因素,这些我们留到以后的文章中探讨。
04.模型性能评测
Llama 2 模型一共有 7b、13b、34b、70b 4 个版本,其中折衷性能和效率,最受人关注的应该是 34b,但是 Meta 官方还没有释放其对应的权重。这里我们针对次优的 13b 版本进行了性能测试,来评估其部署的成本。模型部署我们选择了当下流行的 llama.cpp,分别测试了 8bit/4bit 量化的推理性能,通过反复执行样例 prompt,得到测试结果。
模型调用我们采用了 Towhee 框架最新提供的 Llama_2 算子,仅需要几行代码就能使用 Llama2,并且能方便地搭配数据预处理编辑组装 prompt。
from towhee import ops
chat = ops.LLM.Llama_2('path/to/model_file.bin', max_tokens=2048, echo=True)
message = [{"question": "Building a website can be done in 10 simple steps:"}]
answer = chat(message)
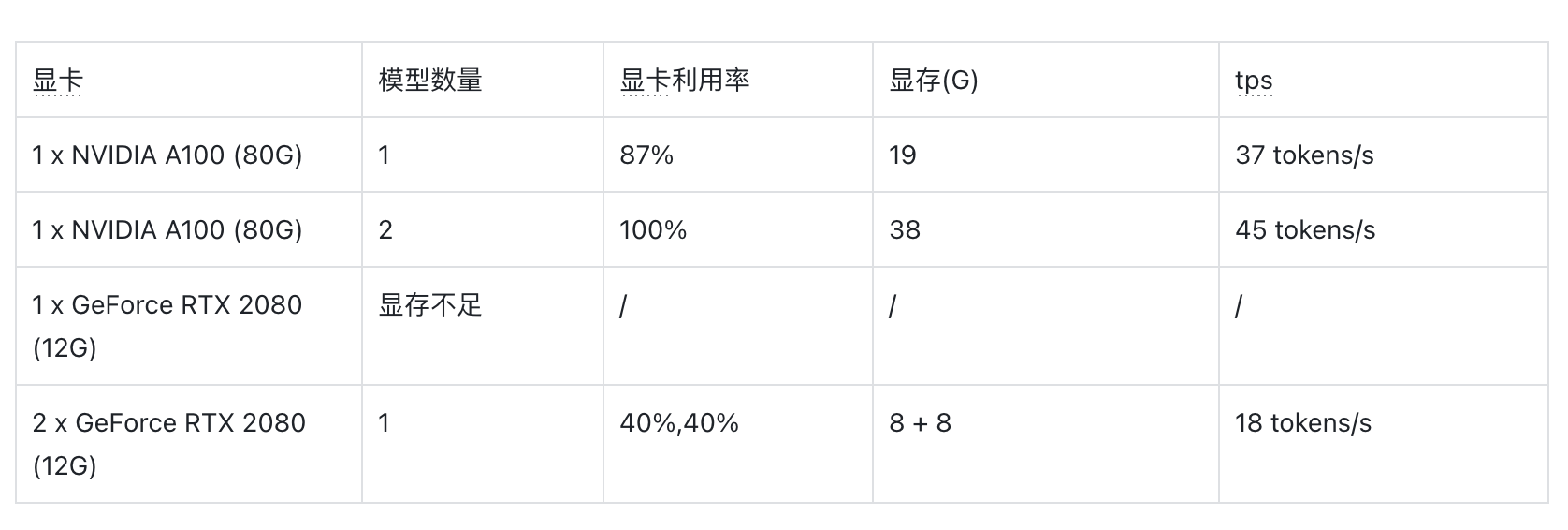
8bit 量化
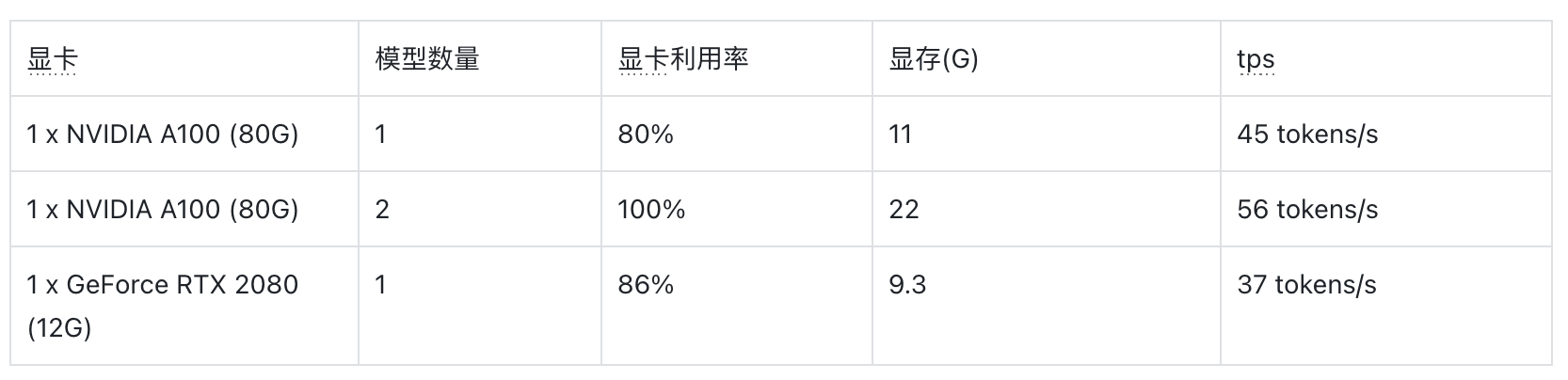
4bit 量化
05.模型性能评测总结
我们分别在专业级显卡 A100 (80G 显存)和桌面级显卡 2080 (12G 显存)上进行测试,可以发现:
- 在经过低比特的量化后,单块桌面级显卡可以运行起 Llama2 13b。
- 在 A100 上部署 Llama2 13b 模型,显存的利用率不高。
- Llama2 13b 在 A100 和 2080 上的性能差距并不大,主要的差距在于桌面卡显存小,单卡无法加载更大的模型。
使用多块桌面卡,可以解决桌面卡显存不足的问题,但显卡间的数据通信,会造成计算资源的浪费。
06.总结
在本文中,我们测试了 Llama2-13b-chat 在基于检索增强的文本生成 (Retrieval Augmented Generation, RAG)场景下的回答质量以及 llama.cpp 部署模式下的性能。
评测说明 Llama2 在简单问题下可以正确理解知识文本中的信息,在同等条件下和 ChatGPT 有相近的回答质量。然而,在文本格式较复杂的情况下其回答质量显著低于 ChatGPT。Llama2 的部署对显卡要求不高,经过低比特的量化后在桌面级显卡上也可以正常运行。在单张 NVIDIA A100 单个模型可达到 45 tokens/s 的吞吐性能。优化吞吐量可以使用单块显卡运行多个模型。
Llama2 对文本信息的处理能力能够胜任大部分 RAG 场景类的需求,利用知识库搭配如 Milvus 等向量数据库召回相关知识文本用以提供高质量的回答。开发者可以方便地使用较为平价的桌面级显卡部署自己的 Llama2 实例。
此外,对于开源模型,也可以考虑使用微调(finetune) 对特定场景进行针对性的优化,从而进一步提高回答质量。我们相信以 Llama2 为代表的开源大型语言模型会带来更多 AI 领域的创新,为广大用户和开发者带来更优秀的问答体验。
欢迎大家在 Towhee 中试用 Llama2!
 Zilliz
Zilliz


