打磨 8 个月、功能全面升级,Milvus 2.3.0 文字发布会现在开始!
Milvus 社区的各位伙伴:
大家晚上好!欢迎来到 Milvus 2.3.0 文字发布会!
作为整个团队的匠心之作,Milvus 2.3.0 历经 8 个月的设计与打磨,无论在新功能、应用场景还是可靠度方面都有不小的提升。
具体来看:Milvus 2.3.0 不仅包含大量的社区呼声很高的新功能,还带来了诸如 GPU 支持、Query 架构升级、更强的负载均衡调度能力、新的消息队列、Arm版本镜像、可观测性、运维工具升级等能力,这标志着 Milvus 2.x 系列从 production ready,走向成熟、可靠、生态繁荣、运维更友好的发展路径。
接下来,我将从 7 个方面带大家深入了解 Milvus 2.3.0。
01.架构升级
GPU 支持
早在 Milvus 1.x 版本,我们就曾经支持过 GPU,但在 2.x 版本中由于切换成了分布式架构,同时出于对于成本方面的考虑,暂时未加入 GPU 支持。在 Milvus 2.0 发布后的一年多时间里,Milvus 社区对 GPU 的呼声越来越高,再加上 NVIDIA 工程师的大力配合——为 Knowhere(Milvus 索引引擎)增加了最新的 RAFT 算法支持,使得 Milvus 不仅加回了 GPU 支持,而且还以最快的速度支持了业界最新的算法。经测试,GPU 版本相较于 CPU HNSW 索引有了 3 倍以上的 QPS 提升,部分数据集有近 10 倍的提升。
下表是 GPU-IVF-FLAT 和 HNSW 在 Milvus E2E 上的 QPS 数据,host 的 size 是 8c32g,NVIDIA A100 GPU。NQ 为 100:

Arm64 支持
随着 Arm64 CPU 的普及程度越来越高,众多云厂商也纷纷发布了基于 Arm64 CPU 的实例。为此,从 Milvus 2.3.0开始,Milvus 不仅会发布 Amd64 镜像,也会发布官方 Arm64 镜像,这一优化也能够帮助 macOS 用户更地开发测试 Milvus。
QueryNodeV2
QueryNode 是继 QueryCoord 之后,第二个重写的服务。
为什么要重写 QueryNode?老版本有哪些问题?展开来讲可以写成万字小作文。简单来说,QueryNode 承担了整个Milvus 系统中最重要的检索服务,其稳定性、性能、扩展性对 Milvus 至关重要,但 QueryNodeV1 存在状态复杂、消息队列重复、代码结构不清晰、报错内容不直观等问题。在 QueryNodeV2 的新设计中,我们重新梳理了代码结构、将复杂的状态改为无状态的设计、移除了 delete 数据的消息队列减少了资源浪费,在后续持续的稳定性测试中,QueryNodeV2 的表现更加优异。
IndexCoord 和 Datacoord 合并
Indexcoord 和 Datacoord 在 2.3.0 版本中被合并,这简化了 Milvus 部署的复杂度,也降低了元信息在不同 coord 之间通信的成本。在接下来的版本中,datanode 和 indexnode 的部分功能也将被合并。
基于 NATs 的消息队列
Milvus 是基于日志的架构,消息队列的扩展性、性能、稳定性对 Milvus 而言至关重要。此前,为了快速完成 2.x,我们选择了业内主流的 Pulsar 和 Kafka 作为核心的 Log Broker。在实际运维的过程中,我们也发现了不少外置消息队列的局限性,一是在多 topic 场景下的稳定性问题,二是大量重复消息时的去重以及空载时的资源消耗问题,三是二者都与Java 生态绑定较紧密 Go SDK 维护不是很积极。
在此情况下,一个更符合 Milvus 需求的 Log Broker 显得至关重要,经过调研和测试,我们选定 NATs + Bookeeper 的方式作为自研的 Log Broker,这更贴合 Milvus 的使用场景。目前,NATs Log Broker 还处于实验阶段,欢迎有兴趣的同学尝试以及反馈问题。
02.New Feature
Upsert 功能
支持用户通过 upsert 接口更新或插入数据。已知限制,自增 id 不支持 upsert;upsert 是内部实现是 delete + insert所以性能上会有一定损耗,如果明确知道是写入数据的场景请继续使用 insert。
Range Search 功能
支持用户通过输入参数指定 search 的 distance 进行查询,返回所有与目标向量距离位于某一范围之内的结果。例如:
// add radius and range_filter to params in search_params
search_params = {"params": {"nprobe": 10, "radius": 10, "range_filter" : 20}, "metric_type": "L2"}
res = collection.search(
vectors, "float_vector", search_params, topK,
"int64 > 100", output_fields=["int64", "float"]
)
该例子中就会返回距离在 10~20 之间的向量。需要注意的是不同的 metric 计算距离的方式不同,所以值域、排序逻辑各异,需要详细了解每个 metric 的特点之后再使用此功能。此外,RangeSearch 依然具有最大返回结果不超过 16384 条的限制。
Count 接口
为了计算 collection 中的数据行数,很多用户会使用 num_entities 接口,但是此接口需要手动调用 flush 之后才能计算准确,但频繁 flush 会造成大量小文件刷盘,对 Milvus 的性能和稳定性都有较大影响。所以在此版本中提供了 count(*) 表达式,可以实时计算准确的 collection 行数。count 操作较为消耗资源,不建议大量并发调用。
Cosine metrics
Cosine 距离在大模型领域有着广泛的应用,尤其是在大模型领域,Cosine Metrics 几乎是衡量向量近似度的事实标准。Milvus 2.3.0 版本原生支持了 Cosine 距离,用户不再需要通过向量归一化计算 IP metrics 来使用 cosine 距离。
查询返回原始向量
出于查询性能的考虑,之前的版本中 Milvus 不支持返回原始向量,此版本中补齐了该功能。需要注意的是,返回原始向量会有二次查询产生,所以对性能会产生较大影响,如果是性能 critical 场景,建议使用HNSW、IVFFLAT等包含原始向量的索引。
目前,部分量化的索引,如 IVFPQ,IVFSQ8 不支持获取原始向量,关于具体哪些索引支持返回原始向量请参考 https://github.com/zilliztech/knowhere/releases.
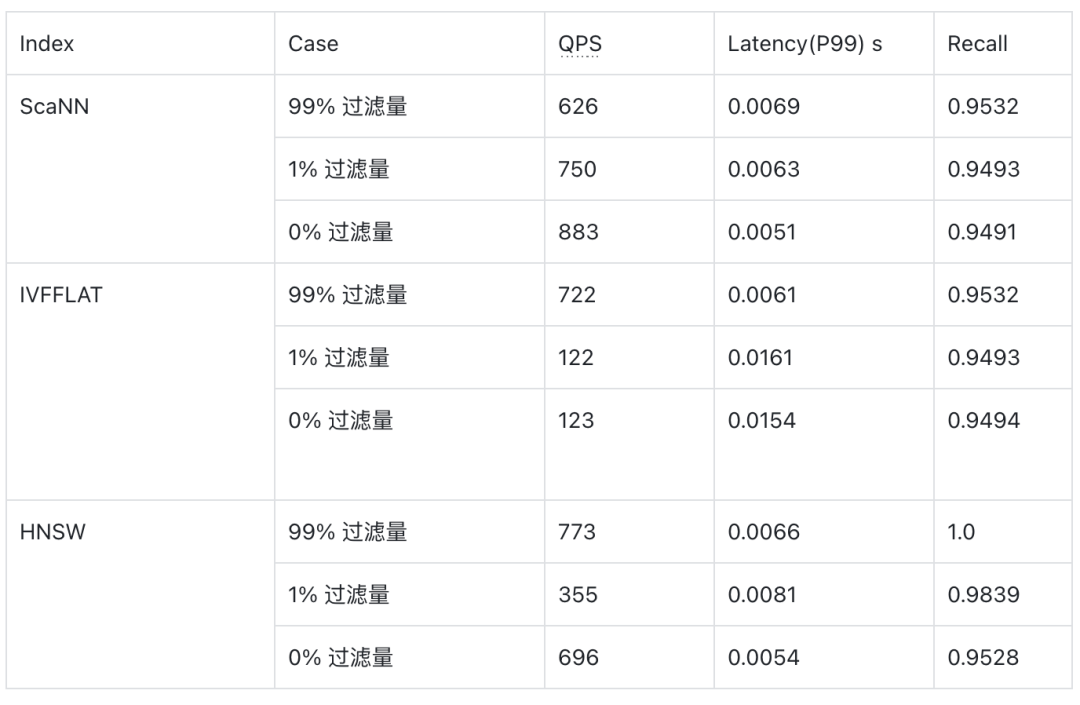
ScaNN 索引
Milvus 目前支持了 Faiss 中的 FastScan 算法,在各项 benchmark 中有着不俗的表现,对比 HNSW 有 20% 左右提升,约为 IVFFlat 的 7 倍,同时构建索引速度更快。ScaNN 在算法上跟 IVFPQ 比较类似,聚类分桶,然后桶里的向量使用 PQ 做量化,区别是 ScaNN 对于量化比较激进,搭配上 SIMD 计算效率较高,但是精度损失会比较大,需要有原始向量做 refine 的过程。
下表是 ScaNN、HNSW 和 IVFFLAT 在 Cohere1M(768维)的数据集下的性能表现,数据来自于 VectorDBBench。
Iterator
Pymilvus 中提供了 iterator接口,可以通过迭代器的方式拉取数据,Query 和 Range Search 场景下,通过迭代器可以获取超过 16384 条数据限制的数据。Iterator 类似于 ES 的 scroll 接口和关系数据库中的 cursor,比较适合后台批量处理数据。
Json Contains
Milvus 2.3.0 支持了Json 数组 contains 表达式,可以支持判断一个 json 数组是否包含了一个元素或者一组元素。详细文档请参考 https://milvus.io/docs/json_data_type.md。
CDC支持
Change Data Capture 是数据库系统中很通用的功能,可以用于跨机房主备数据同步、增量数据备份、数据迁移等场景,得益于 Milvus 基于日志的架构很容易实现此功能。Milvus 的 CDC 代码在 https://github.com/zilliztech/milvus-cdc.
03.Enhancement
MMap 技术提升数据容量
MMap 是 Linux 内核提供的技术,可以将一块磁盘空间映射到内存,这样一来我们便可以通过将数据加载到本地磁盘再将磁盘 mmap 到内存的方案提升单机数据的容量,经过测试使用 MMap 技术后数据容量提升了 1 倍而性能下降在20% 以内,大大节约了整体成本,对于成本敏感的用户欢迎试用此功能。
filter 场景性能提升
对于标量向量的混合查询场景,Milvus 的执行计划是先执行标量过滤再执行向量检索,这就意味着标量过滤之后会有大量的数据被过滤掉,如果过滤掉的数据过多会引起向量索引性能急剧下降,通过优化 HNSW 索引的数据过滤策略,2.3.0 中优化了此场景中的性能。除此之外,通过引入手动的向量化执行技术,标量数据过滤的速度也得到了大幅提升。
Growing 索引
Milvus 的数据分为两类,分别为已索引的数据和流式数据。对于已索引的数据自然可以使用索引加速查询,但流式数据只能使用逐行暴力检索,对性能影响较大,为了解决此类问题在 2.3.0 中加入了 Growing index,自动为流式数据建立实时索引,保障查询性能。
多核环境资源利用率提升
向量近似计算是计算密集型的任务,CPU 使用率是非常重要的指标,在 CPU 核数较多的情况下可能会出现 CPU 使用率无法超过 70% 的情况,经过优化 Milvus 2.3.0 能够更加充分利用好 CPU 资源实现性能提升。
04.稳定性
New load balancer
在 2.1.0 版本中,Milvus 支持了内存多副本,用户可以通过多副本的方式提升 QPS。经过半年多的生产实践,收到了很多来自社区的反馈,其中主要集中在添加副本后 QPS 没有立刻提升、节点下线后系统恢复稳定时间较长、节点之间负载不均衡、CPU 使用率不高等问题。这些问题归因到一起可以认为是负载均衡逻辑鲁棒性低,故障恢复能力较弱的问题,经过重新设计的负载均衡算法,采用基于负载的动态负载均衡算法,能够及时的发现节点上下线、负载不均衡等现象及时调整请求调度。经过测试可以在秒级发现故障、负载不均衡、节点上线等事件,及时调整负载。
05.可运维性
动态配置
修改配置是运维、调优数据库中的常见操作,从此版本开始 Milvus 支持动态修改配置项而无需重启集群,支持的方式有两种一是修改 etcd 中的 kv,二是直接修改 Milvus.yaml 配置文件。需要注意的是并不是所有的配置项都支持动态配置,详见 Milvus文档 https://milvus.io/docs。
Tracing 支持
通过 tracing 发现系统中的瓶颈点,是调优的重要手段,从 2.3.0 开始 Milvus 支持 Opentelemetery tracing 协议,支持此协议的 tracing collector 例如 jaeger 都可以接入观测 Milvus 的调用路径。
Error Code增强
团队重新梳理了 Milvus 的 error code 以及设计了新版 error code 的架构,这次升级后,Milvus 的报错会更清晰。
06.工具升级
Birdwatcher tool 升级
配套的 Birdwatcher 在这几个月中经过持续的演进,增加了众多功能,例如:
支持 restful API,更方便集成到其他诊断系统中
支持 pprof 命令,更方便的与 go pprof tool 集成
增加 storage analysis 命令分析存储占用
与 2.3.0 的 event log 模式集成,支持通过结构化的数据分析 Milvus 内部事件,提升分析日志效率
支持修改/查看 etcd 中的配置
可以说,升级后的 Birdwatcher 功能众多,对需要深度运维 Milvus 的用户很有帮助。未来,Birdwatcher还会增加更加有用的命令,欢迎大家试用。
Attu 升级
全新设计了 Attu 界面,用户体验更友好:
07.Break Change
移出 Time travel 功能
由于 Time travel 功能几乎没有用户使用,且 time travel 功能对 Milvus 的系统设计提出了较大挑战,先暂时废弃。
移出 CentOS7 支持
由于 centos 官方对 centos7 的支持即将到期,而且 centos8、centos9 仅有 stream 版本,官方并未提供正式的 docker 镜像,所以 Milvus 放弃对 centos 的支持,改为使用 Amazonlinux 发行版进行替代。此外,基于 ubuntu20.04 的镜像依旧是 Milvus 的主推版本。
删除了部分索引和 Metrics 支持
我们删除了包括 Annoy 索引和 RHNSW 索引,以及 binary 向量下的 Taninato、Superstructure 和 substructure 距离。
以上就是本次 Milvus 2.3.0 文字发布会的全部内容,如果大家还有不理解的地方,可以点击链接观看解析视频。
接下来我们也会针对重点功能进行详细解读,欢迎大家关注后续文章。当然,也期待 Milvus 的社区用户尝鲜,遇到问题尽快在 GitHub 提交 issue 反馈,希望我们共同把 2.3.0 版本打磨得更加出色!
🌟「寻找 AIGC 时代的 CVP 实践之星」 专题活动即将启动!
Zilliz 将联合国内头部大模型厂商一同甄选应用场景, 由双方提供向量数据库与大模型顶级技术专家为用户赋能,一同打磨应用,提升落地效果,赋能业务本身。
如果你的应用也适合 CVP 框架,且正为应用落地和实际效果发愁,可直接申请参与活动,获得最专业的帮助和指导!联系邮箱为 business@zilliz.com。
 焦恩伟
焦恩伟