



官宣:Zilliz Vector Lakebase 正式发布,作为向量数据库开创者,我们为何推出Vector Lakebase
作为全球 Vector Database 领域的领导者,今天,Zilliz Cloud迎来重要版本升级,正式发布 Zilliz Vector Lakebase 的 public preview版本。
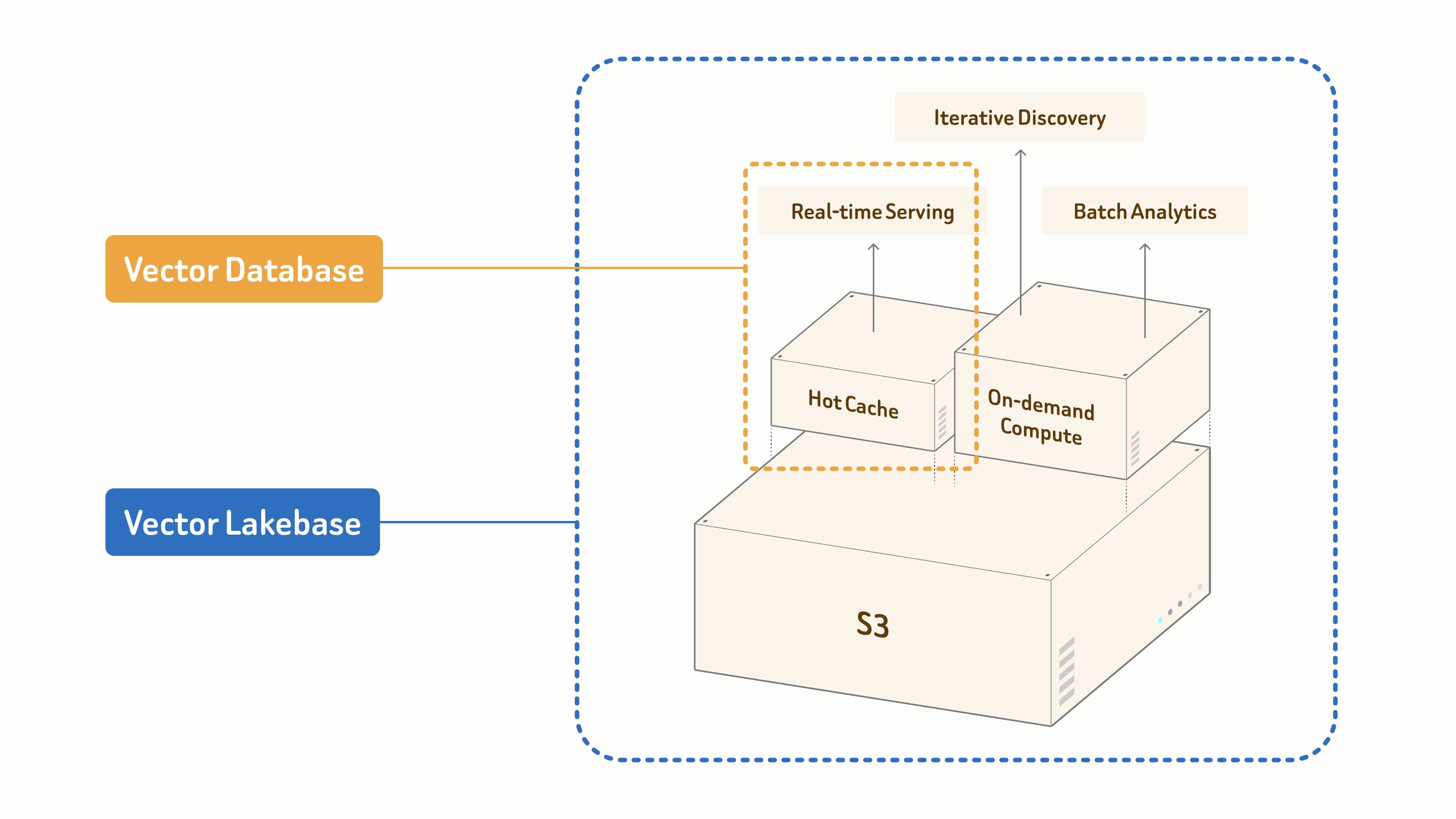
Zilliz Vector Lakebase是一个以语义数据为核心的数据平台, 基于S3的统一数据底座,它可以将开放存储与弹性计算结合起来,帮助用户在 GB 到 PB 级数据规模上,构建完整的 AI 数据闭环。在同一套架构中支持数据全生命周期的三大类型负载:
为对延迟要求极高的生产服务提供实时检索功能;
用于交互式和多步骤探索的迭代发现;
用于离线数据挖掘和数据集优化的批量分析。
为此,当前阶段的Zilliz Vector Lakebase ,主要做了五方面的能力建设:
服务能力升级:推出分层服务方案,为极致性能、容量优化和低成本分层存储等不同场景提供对应选择。
按需搜索能力升级:推出按需搜索(On-Demand Search),让大规模低频检索、数据探索和离线分析不再需要长期维持闲置计算资源。
数据湖搜索能力升级:支持外部数据湖搜索(External Data Lake Search),可直接在已有数据湖上增加高性能索引和大规模搜索能力。
检索能力升级:在同一系统内支持向量搜索、全文搜索、JSON 查询、地理空间搜索、多向量搜索、多路径检索和重排序。
湖原生存储能力升级:同构统一的lake-Native Storage,基于 Vortex 开放格式,为在线服务和离线分析提供统一、高效、低成本的数据底座。与 Lance 和 Parquet 相比,它能提供更快、更便宜的随机读取,以及按列格式的灵活性和更广泛的数据建模能力。
以下是此次 Zilliz Vector Lakebase 发布内容的详细介绍。
为什么我们需要Vector Lakebase做统一的数据基础设施
随着 AI 应用和agent系统进入真实业务场景,在生产中,我们经常需要处理以下三类数据:
底层是原始多模态数据,例如文本、图片、音频、视频和文档。
上层两类数据分别是用于在线服务的语义数据,例如文本、向量和标签,以及生产环境中持续积累的反馈数据,例如用户行为、日志、agent notes和统计信息。
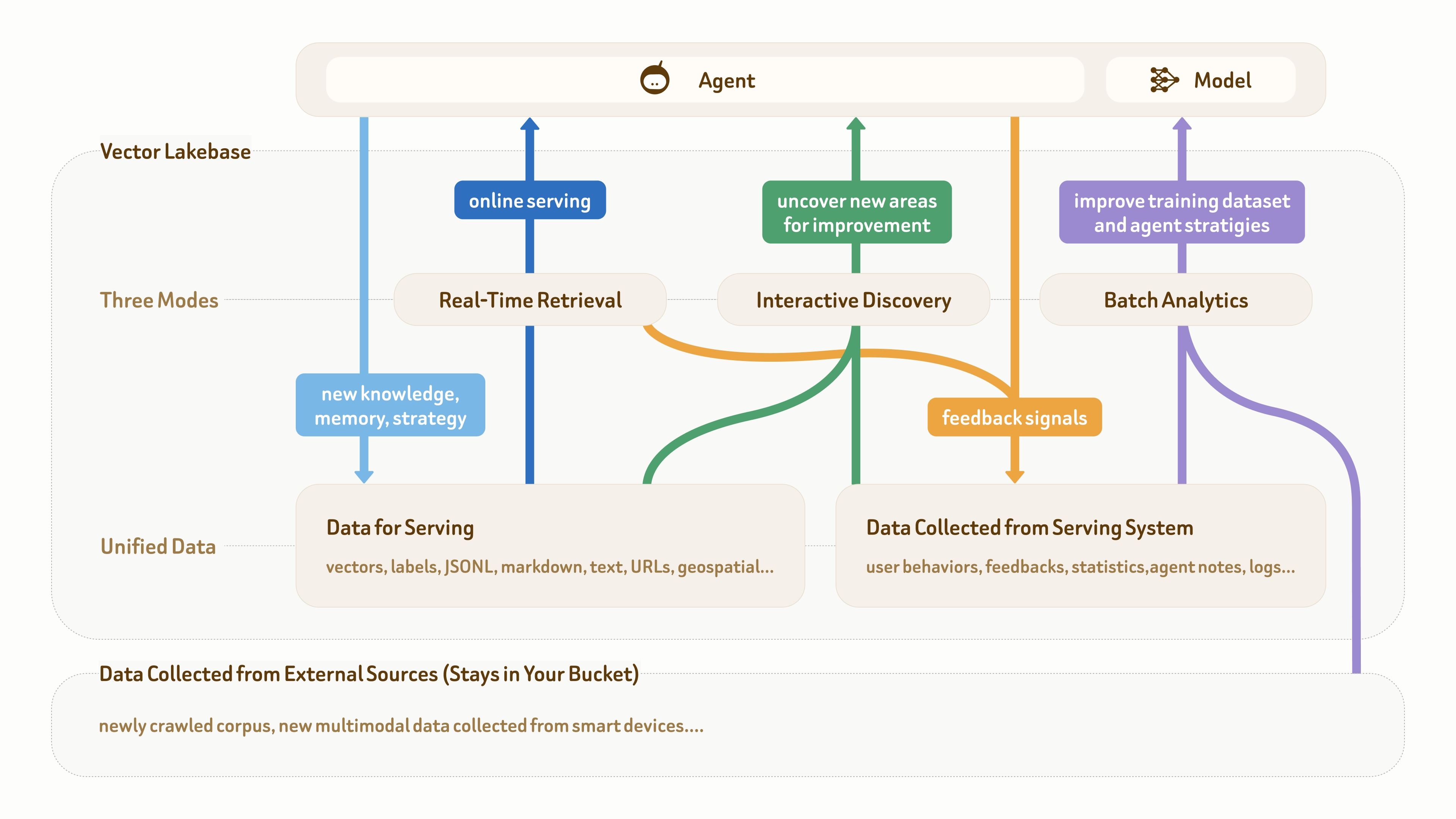
而基于这些数据,在一个完整的数据生命周期闭环(在线服务 → 知识与反馈沉淀 → 洞察发现 → 数据集与策略优化 → 更高质量的在线服务)里,同一批数据,通常需要面临三大类型的负载:
第一类是实时检索,用于对延迟敏感的生产级在线服务。我们常见的电商推荐、企业知识库,都是典型的在线实时检索。
第二类是交互式探索(iterative discovery),用于交互式、多步骤的数据探索和问题定位。比如,AI 开发者需要分析 feedback data 和底层 corpus,找到服务质量下降的原因。agentic system 也可能自动探索日志和用户行为,定位知识缺口、策略问题或数据稀疏区域。
第三类是批量分析,用于离线挖掘、数据集优化和大规模语义分析。自动驾驶的数据挖掘,模型训练中的数据去重,都是典型的代表。
但问题是,过去,这些数据常常分散在不同 pipeline 和系统里,缺少统一、结构化的数据平面来支撑完整工作流。
第一类实时检索可以交由向量数据库解决,但在应对第二类交互式探索、第三类批量分析时,更擅长在生产环境中以低延迟完成高质量向量搜索这样的在线检索问题的向量数据库,会出现一定的的资源冗余与不必要的成本开支。
传统的大数据处理同样难以完成这两类数据处理任务,它们的核心计算不是数值计算,而是语义计算。数据主要由 vectors、text、labels 和 semantic metadata 组成。核心操作包括 vector search、full-text search、reranking、semantic clustering,以及其他 semantic retrieval tasks,不是传统大数据处理的典型负载。
但一定程度上,交互式发现和批量分析在数据层和计算层,其实都与向量数据库天然契合。 也是因此,在许多情况下,在线服务和离线处理其实可以共享相同的底层数据基础。
Zilliz Vector Lakebase 要解决的正是这个问题。
它提供一个统一的0拷贝语义数据平面,让实时检索、交互式探索和批量分析可以访问同一份底层数据,减少重复迁移、重复建模和重复计算,让 AI 应用从能检索走向能持续优化。
亮点一,服务能力升级:面向不同负载的分层服务方案
在真实场景中,不同业务对吞吐、延迟、召回率和成本的要求并不一样。为此,Zilliz Cloud (Vector Lakebase )提供的分层服务方案,包含三类服务层级:
性能优先层(Performance-Optimized)、容量优化层(Capacity-Optimized)、分层存储层(Tiered-Storage)。
每个层级都配备专门的索引算法和数据存取策略,并针对不同存储层做了数据布局优化,从而在性能和成本之间提供不同选择。
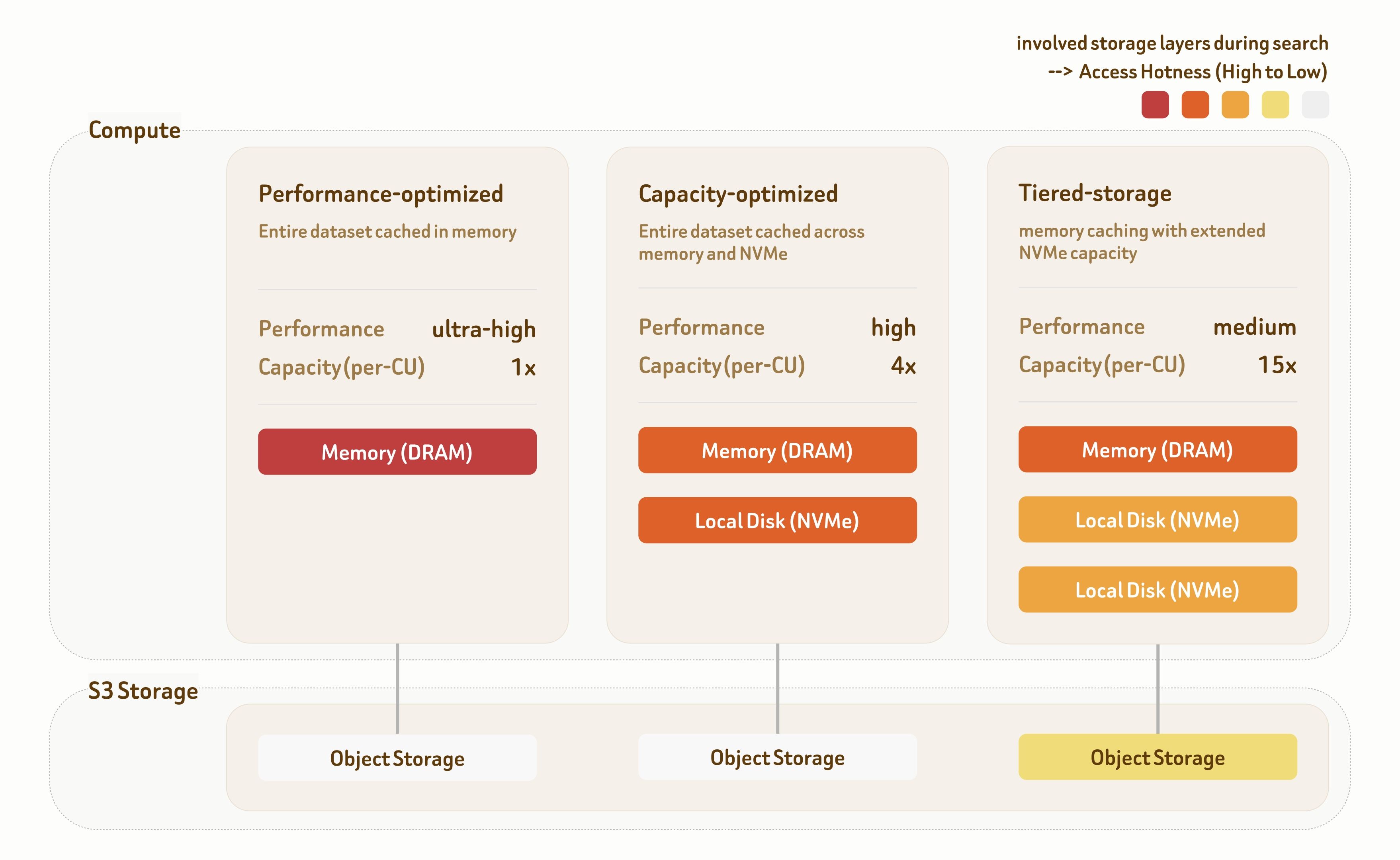
性能优先层级(Performance-Optimized):面向极致性能场景
性能优先层面向对实时性要求最高的检索场景。
该层将数据直接放在内存中提供服务,可实现1000+ QPS和个位数毫秒级延迟。通过多副本部署,吞吐能力还可以继续线性扩展。
适合场景包括:高并发 AI 搜索、低延迟agent记忆检索、高吞吐推荐系统、 对响应时间极其敏感的企业级检索服务
容量优化层(Capacity-Optimized):面向性能与容量平衡场景
容量优化层结合内存和本地 NVMe 存储,在性能和容量之间取得平衡。该层可支持100 到 500 QPS,并保持100 毫秒以内延迟,适合大多数生产级检索工作负载。
适合场景包括:企业级 RAG 知识库、多租户 SaaS 检索服务、中高频业务数据检索、需要兼顾性能与数据规模的 AI 应用
分层存储层(Tiered-Storage):面向海量数据与成本敏感场景
分层存储层横跨内存、本地 NVMe 和对象存储。通过高度优化的预取和缓存策略,超过95%的数据访问仍然可以命中内存或本地磁盘。在显著降低基础设施成本的同时,可提供10 到 50 QPS和约100 毫秒延迟。
适合场景包括:长尾内容检索、历史归档数据查询、大规模低频知识库、冷热数据比例悬殊的生产系统、秒级冷热数据动态调度、100B+ 规模的自动驾驶数据挖掘 以及模型训练数据去重pipeline。
三种服务层级默认提供95% 到 98% 召回率,并支持通过索引和搜索参数灵活调优。用户可以根据业务需求,在90% 到 99%+ 召回率区间内平衡准确率、延迟和成本。
对于 online serving,Zilliz Cloud 还提供 Global Cluster,用于 cross-region high availability 和 disaster recovery,并提供 99.99% uptime SLA。
亮点二,按需搜索能力升级:大规模语义检索不再为闲置资源买单
很多 AI 团队的数据规模,其 交互式探索以及批量分析部分的负载, 通常十倍乃至百倍千倍大于在线服务真正需要常驻访问的部分。
尤其当用户反馈、智能体笔记、日志和爬取语料都被纳入系统后,数据规模很容易达到 TB 甚至 PB 级。
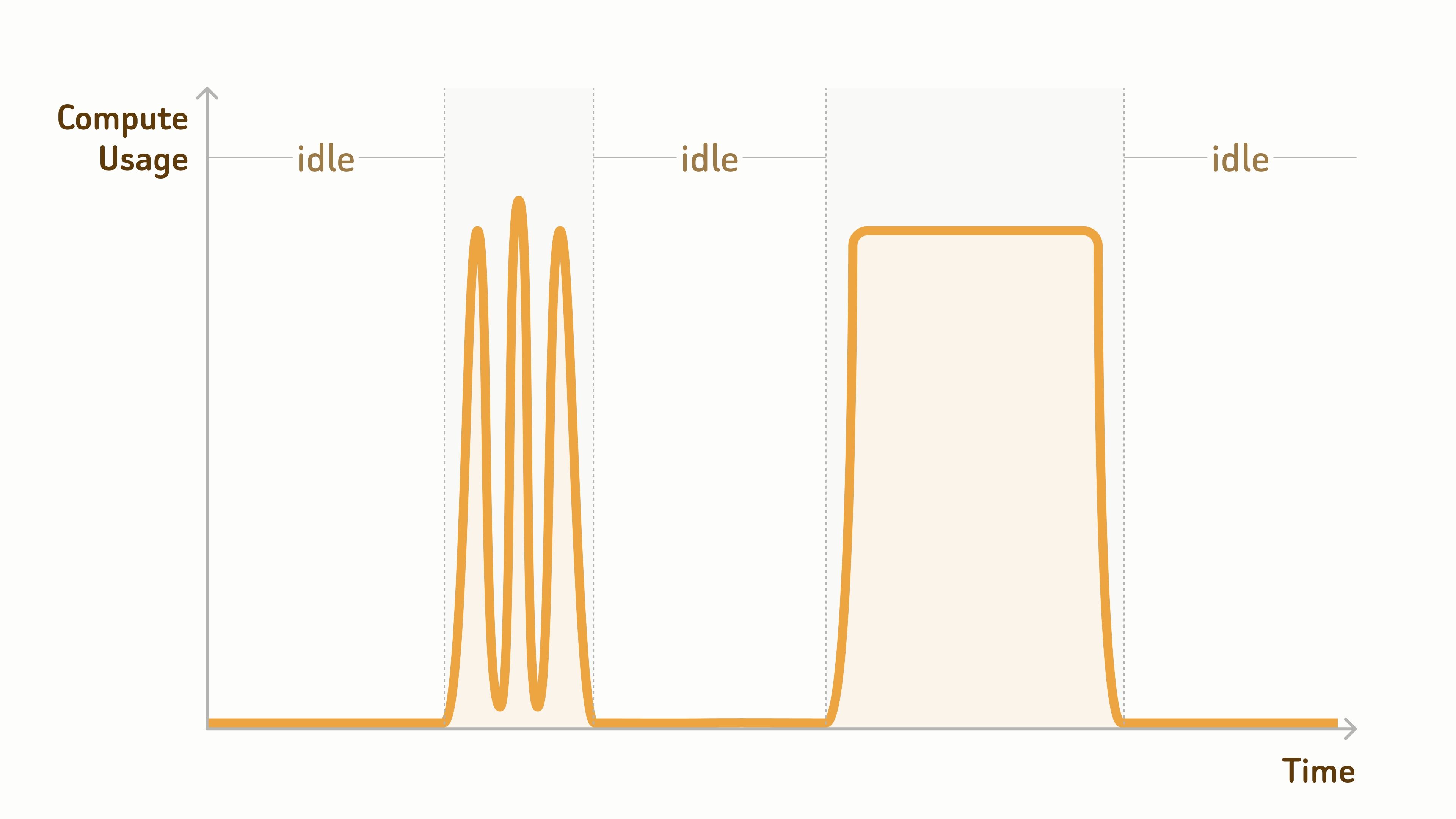
但这类任务通常不是 7x24 小时持续运行。如果为了服务这些数据,长期运行几百甚至几千个 向量数据库 nodes,通常很难从成本收益上算得过来。
更重要的是,这类 workload 通常是任务驱动型:只有在执行数据探索、质量分析、离线挖掘或数据集优化时,才需要大量计算资源。其余时间,计算资源大部分处于闲置状态。idle time 往往超过 97%。
过去,应对这种场景,部分用户会选择Serverless serving 模式,但这对这类负载的成本优化来说,通常不甚明显,甚至会带来负向成本优化。
常规 Serverless 系统虽然也接近按量付费,但往往也会把资源池开销、索引成本和持久化数据成本包装进额外的写入费用和存储费用中。用户看到的是更黑盒的价格,而不是底层资源成本本身。
Zilliz On-Demand Search 则直接围绕对象存储和按需计算计费。它更接近 AWS Lambda 的使用模式,主要根据分配资源大小和执行时间收费,而存储成本接近底层 S3 成本。
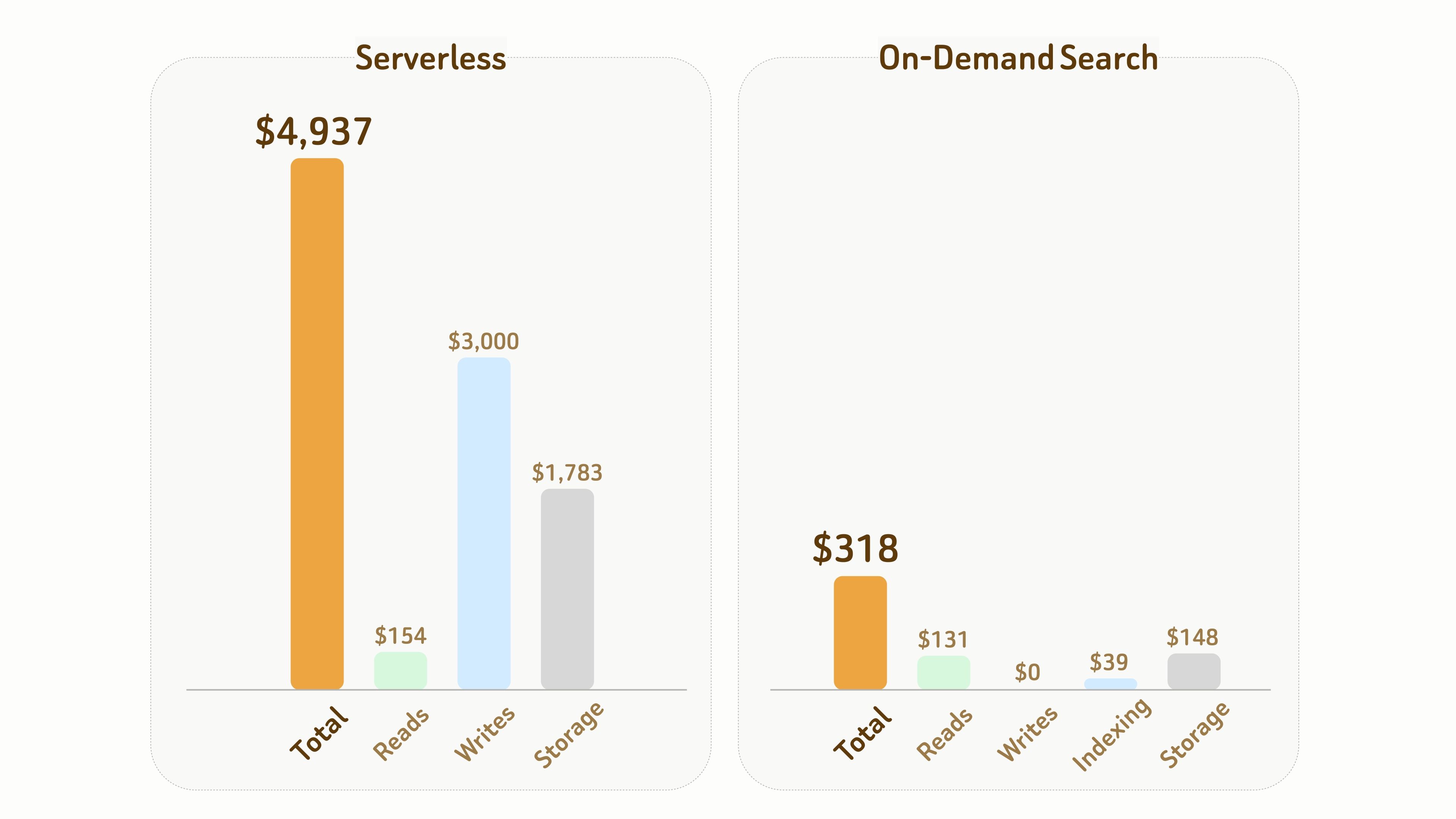
以下是我们做的一个对比:一个包含10 亿个 768 维向量的数据集,连同数据和索引文件约占6TB 存储。
如果一个月内累计实际计算时间为10 小时,按需搜索的总成本约为 Serverless 的1/15,即318 美元对 4,937 美元。
对于大规模语义探索和离线分析,这意味着用户不必再为长期闲置的计算资源持续买单。
亮点三,外部数据湖搜索:不用搬迁数据,也能获得高性能语义检索能力
在当下,很多企业已经建设了成熟的数据湖体系。数据可能已经存放在 Lance、Iceberg、Parquet 或其他数据湖表中。治理、权限、ETL、数据血缘和合规流程也已经围绕现有数据湖建立完成。
在这种情况下,企业真正需要的并不是把所有数据迁移到一个新系统里,而是:
如何直接在已有数据湖上实现高效搜索和语义探索?
传统大数据系统,例如 Spark 和 Ray,主要围绕全量扫描和批处理计算设计,并不是为索引加速查询和语义检索优化。
Zilliz Vector Lakebase 提供 fully managed storage 和 query compute,用户可以直接把数据存储并运行在 Zilliz Cloud 中。
为解决这个问题,Zilliz Vector Lakebase 提供外部集合(External Collection) 模式。
External Collection可以在 Zilliz 数据平面和客户已有数据湖表之间建立零拷贝逻辑映射,并在这层映射之上启用高性能索引和全谱搜索能力。
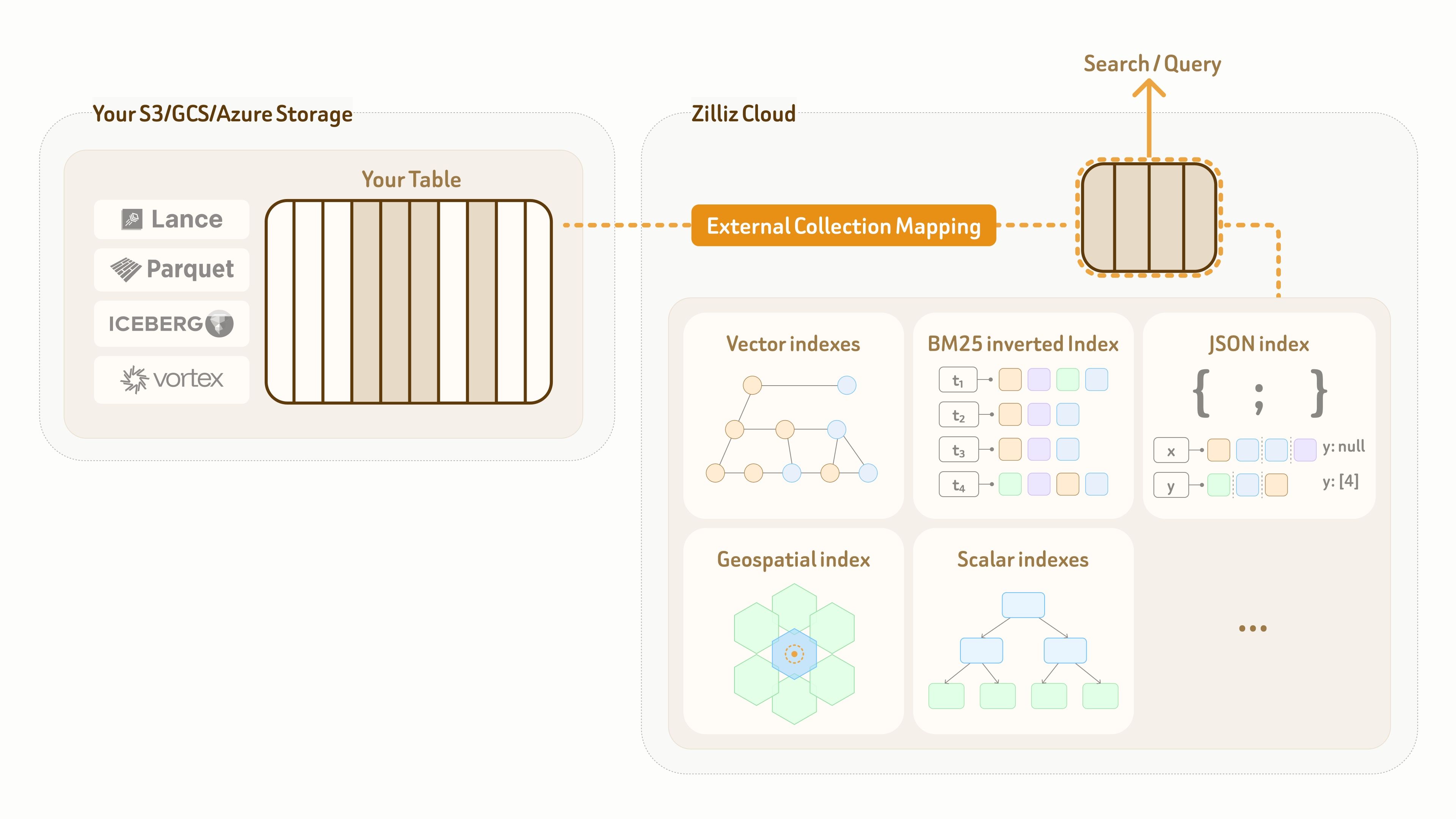
目前,External Collection 支持两类数据湖表格式:Lance 和 Iceberg;同时也支持两类 开放数据格式:Parquet 和 Vortex。
对于持续更新的数据湖,Zilliz External Collection还支持增量同步。 用户可以根据数据湖更新频率和查询可见性要求,通过调用 refresh 接口灵活同步最新数据。
亮点四,检索升级:一个系统内完成向量、全文、JSON、地理空间和多路径检索
真实 AI 应用中的检索,早已不只是向量搜索。
用户往往需要跨来源、跨模态检索和分析数据,并同时处理:语义相似度、关键词匹配、JSON 元数据、地理位置、时间范围、结构化字段、多路召回结果、重排序结果等任务。
传统架构下,这通常意味着多个系统拼接:向量数据库负责语义召回;Elasticsearch 负责全文搜索,关系数据库负责结构化过滤,GIS 系统负责地理空间查询,Spark 或 Ray 负责离线分析。
系统越多,数据同步越复杂,查询链路越长,结果一致性和运维成本也越难控制。
Zilliz Vector Lakebase 提供Full-Spectrum Search,在同一系统中支持多种数据类型和检索方式。
在数据建模上,Vector Lakebase 支持宽表建模,支持稠密向量、稀疏向量、文本、JSON、地理空间数据、基础数据类型,以及 Struct、Array 等复杂结构。用户可以在统一表结构中完成嵌套语义建模,每个 application-level entity 可以映射为单表中的一行。

过去,传统做法可能会把一篇文档拆成几百行,分别存储文本块、图片和表格。而在 Zilliz Vector Lakebase 中,可以把整篇文档建模为单行,把不同模态、元数据和结构化字段统一到同一个实体中。
在数据建模之外,Vector Lakebase 还为多种数据类型提供 advanced indexing 和 search 能力,包括:
向量检索: 使用先进索引算法,支持多级召回率与延迟调优,在不同性能目标下灵活平衡准确率和响应速度。
全文搜索: 支持 BM25、短语查询、前缀匹配、模糊匹配和多种分词器。
Grep: 内置正则能力,覆盖常见 grep 风格匹配需求。
混合检索: 结合稠密向量和稀疏向量,提高召回率和相关性。
JSON 查询: 通过 JSON 拆分(JSON shredding)和索引能力,对嵌套 JSON 字段进行快速过滤和查询。
地理空间搜索: 支持半径查询、最近邻查询和区域过滤等地理空间能力。
多向量搜索: 支持对一个或多个模态中的多个向量进行搜索,并通过统一重排序整合结果。
带过滤条件的向量搜索: 支持在属性过滤条件下进行向量搜索,并针对不同过滤选择性做优化。
范围搜索: 返回与查询向量距离处于指定阈值内的所有向量。
迭代式搜索: 支持基于中间结果不断细化查询,适合多步骤探索场景。
多路径检索: 支持在同一次查询中组合多条检索路径,每条路径都可以使用不同检索方法,并与重排序结合。
在重排序方面,Vector Lakebase 支持 Cohere、Voyage AI、Boost、Decay、RRF 和 Weighted 等多种重排序器,帮助用户在多路召回结果之间进行融合和排序,提升最终结果的相关性和业务可控性,详情如下
| Cohere Reranker | 一种 cross-encoder 重排序模型,能够以较高的语义精度为查询与文档对打分,并重新排列检索结果,使最相关的结果排在前面。 |
|---|---|
| Voyage AI Reranker | 一种轻量级、高吞吐的重排序模型,针对大规模检索 pipeline 中快速、低成本的相关性打分进行了优化。 |
| Boost Reranker | 对匹配结果应用条件过滤,并按照指定权重调整结果分数,从而提升或降低其排序。 |
| Decay Reranker | 基于距离、时间等因素应用衰减函数来调整结果分数。当结果与目标值偏离越远,其相关性分数会逐步降低。 |
| RRF Reranker | 通过融合多个结果列表中每个结果的排名位置,将多路结果合并成一个统一排序。 |
| Weighted Reranker | 使用可配置权重合并多个结果列表的分数,生成统一排序结果。 |
亮点五,湖原生存储:统一支撑在线服务与离线分析
Zilliz Cloud 构建在存储计算完全解耦的架构之上,所有数据都持久化在云对象存储中。
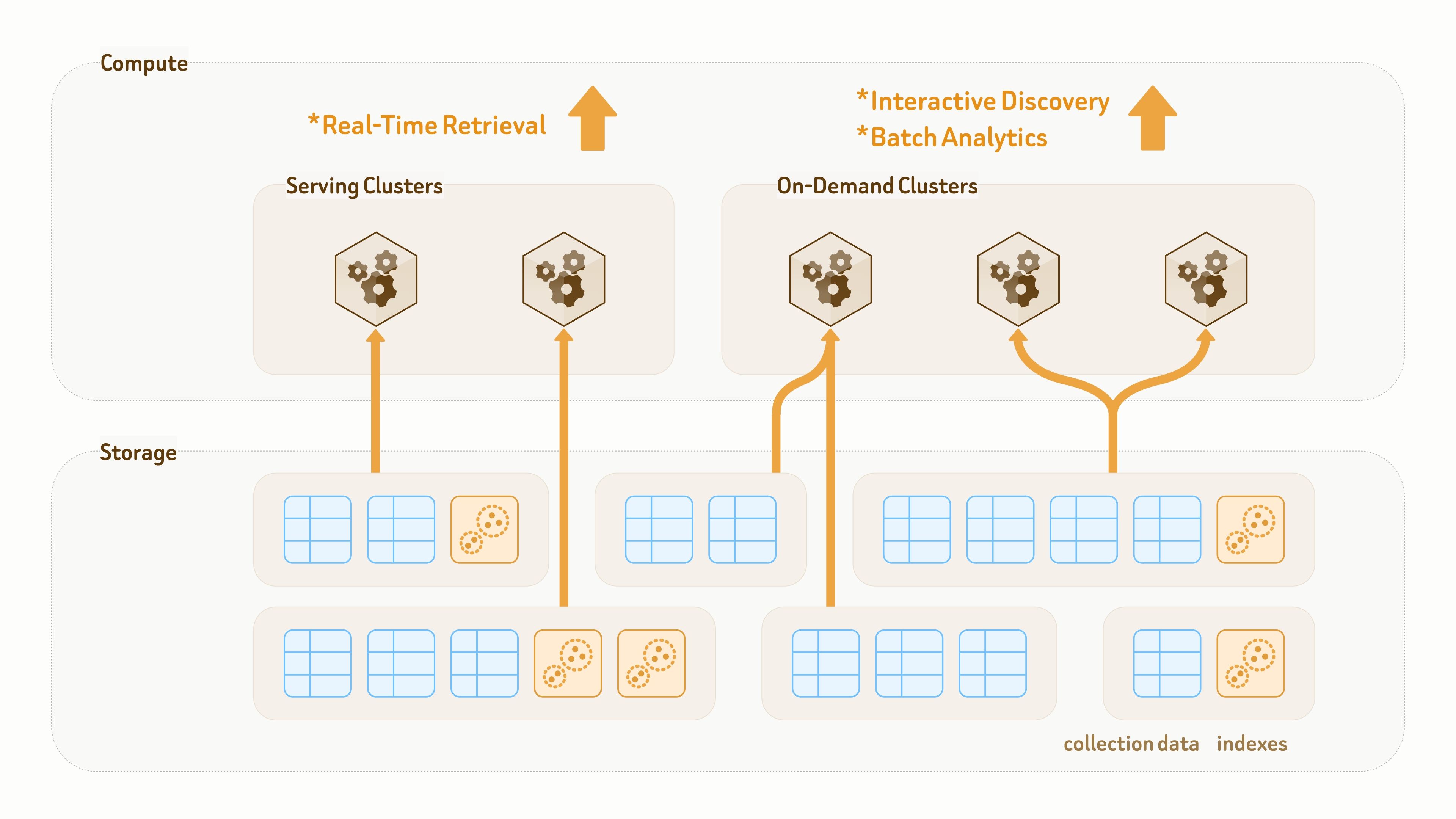
和传统数据湖主要面向存储不同,Zilliz Vector Lakebase 的数据层同时面向持久化和查询执行。
集合和索引与计算集群解耦,因此同一份数据和索引可以通过零拷贝方式挂载到不同集群,用于不同查询、在线服务和分析任务。
对于 AI 和 agent 应用来说,这类应用的数据模型变化很快:团队可能频繁新增标签和特征、可能切换 embedding model、 可能需要对历史数据做回填、 可能要把新的 LLM 生成摘要、元数据或结构化字段加入同一张表。
Zilliz 为此提供高速 schema evolution 和数据回填机制。新增字段会由平台侧共享计算资源完成回填和对齐,再通过元数据更新暴露给查询集群。1 亿行数据回填通常可以在个位数分钟内完成。
此外,由于大部分工作由平台侧计算资源处理,用户现有集群不会受到影响,可以在整个过程中继续处理读写流量。
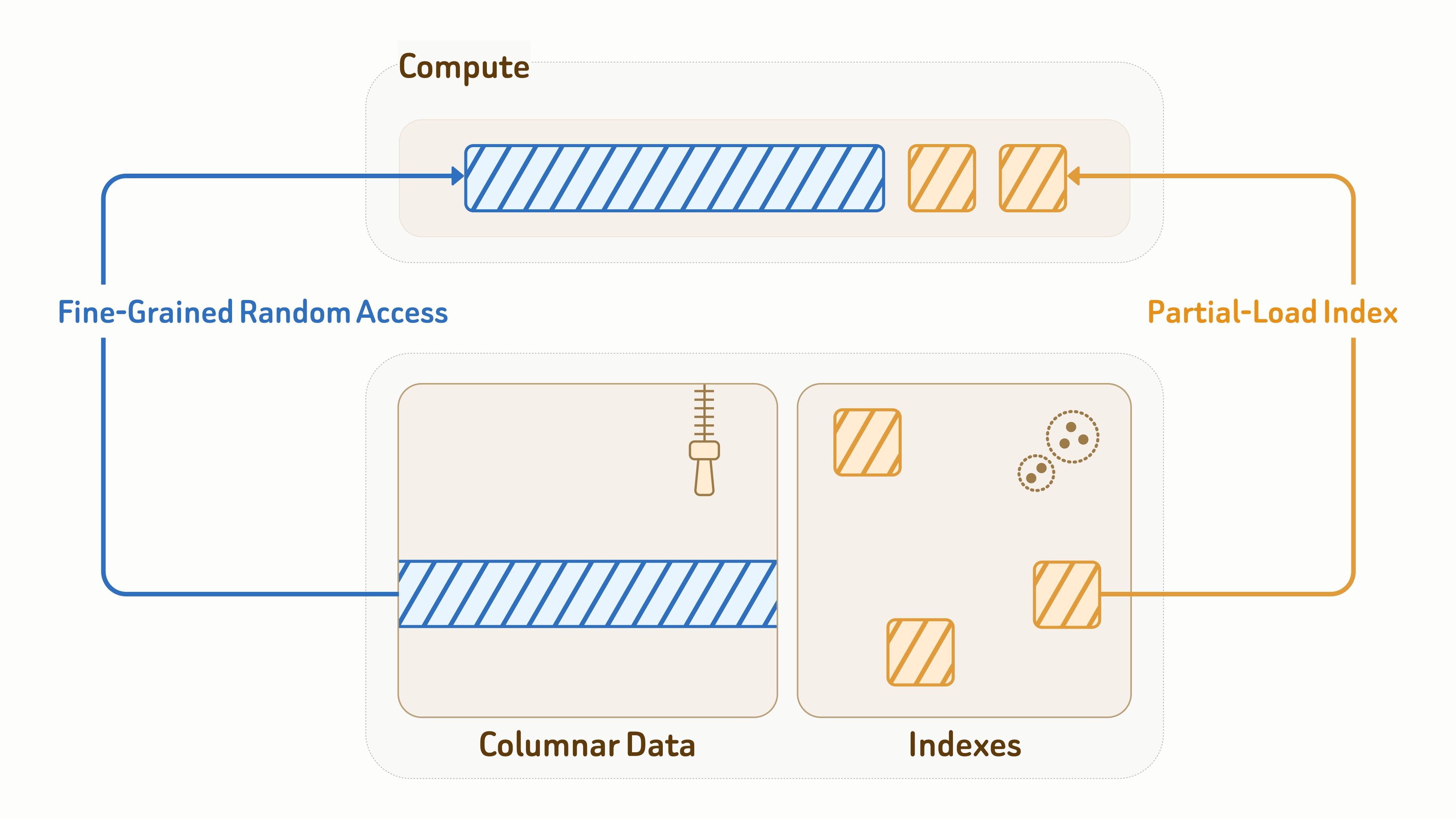
在底层存储格式上,Zilliz 使用Vortex开放格式进行列式存储布局。
Vortex 结合高效编码和细粒度随机访问,在随机读取场景下比 Lance 和 Parquet 更快、成本更低,同时支持按列选择不同格式,便于承载更灵活的数据模型。
针对索引,Zilliz 还提供面向对象存储优化的索引算法设计,并深度优化数据布局和访问路径,以提升 I/O 效率。这些索引包括:vector indexes、BM25 inverted indexes 和 JSON indexes。
在查询执行过程中,计算节点只会加载查询真正触达的索引页和数据实体。结合缓存和数据裁剪,可以将read amplification降低 90% 以上。
这让 Vector Lakebase 不只是把数据放在对象存储上,而是真正让对象存储成为可服务、可检索、可分析的语义数据底座。
Vector Lakebase 的主要使用场景
Vector Lakebase 适合的典型场景包括:
实时服务场景
面向低延迟、高并发、生产级检索任务,例如:对延迟敏感的智能体记忆和策略检索,法律、医疗、金融等垂直行业知识库,Web 级 AI 搜索引擎,超高吞吐推荐系统,跨存储层级的秒级冷热数据动态调度,面向企业付费用户和大规模免费用户池的差异化服务层级。
交互式探索场景
面向问题定位、质量分析和多步骤探索任务,例如:基于用户反馈、智能体笔记和日志进行 AI 服务质量分析,发现知识缺口、检索失误和策略问题,高效探索大规模数据集,支持多步骤深度研究和数据分析。
批量分析场景
面向大规模离线语义计算任务,例如:超大规模语料去重和聚类、 训练数据筛选、 微调数据集准备、大规模过滤、检索和粗召回到精排的两阶段查询流程,为 Spark、Ray 等系统补充索引加速的语义检索能力。
数据湖融合场景
面向已有数据湖和持续演进数据模型的企业用户,例如:在 Lance、Iceberg 等数据湖表上直接启用索引和检索,在 Parquet 数据上增加语义搜索能力。
支持频繁的大规模数据回填,将向量、元数据、LLM 生成摘要和结构化字段统一到以实体为中心的表中,保持统一的版本管理和数据血缘追踪。
现在开始体验 Zilliz Vector Lakebase
从 Vector Database 到 Vector Lakebase,变化的不只是产品名称。它代表的是 AI 数据基础设施的一次升级:
从单一实时检索,走向在线服务、数据探索和批量分析的统一;从孤立向量索引,走向统一语义数据底座;从固定资源集群,走向湖原生存储和弹性计算;从简单 RAG 查询,走向完整 AI 数据闭环。
Zilliz Vector Lakebase Public Preview 现已开放。
如果你正在构建 AI 搜索、智能体记忆、企业知识库、多模态检索、数据湖语义分析或大规模批量分析工作流,现在就可以开始体验新一代面向 AI 工作负载的语义数据平台。
尝鲜链接:https://zilliz.com.cn
 Robert Guo
Robert GuoRobert Guo is Co-Founder & VP of Product Management at Zilliz.


