使用Gemini 1.5、BGE-M3、Milvus Lite 和 LangChain 搭建多模态 RAG 应用
大语言模型(LLM)能够执行各种自然语言任务,例如文本生成、语言翻译、文本摘要、问答等。然而,使用 LLM 的一个显著局限是 LLM 幻觉。
幻觉是指由 LLM 生成的响应虽然看起来正确且一致,但实际并非完全准确的现象。如果您不是特定领域内的专家,很难发现 LLM 生成的回答是不准确的。
本文将介绍一种减轻 LLM 幻觉的解决方案——检索增强生成(Retrieval-Augmented Generation,RAG)。我们将搭建一个结合了不同模态数据(文本和图像)的多模态 RAG 应用,以减轻 LLM 幻觉。
什么是 RAG?
当我们向 LLM 提出超出其预训练知识范围的问题时,通常 LLM 会出现幻觉。例如,如果我们向 LLM 提出涉及医学或法律等高度专业化的问题,并包含大量内部术语时,我们就有可能得到 LLM 随机生成的不准确的回答。
缓解这一问题的一种方法是使用特定的数据集对 LLM 进行微调。虽然这种方法很有效,但十分耗时且高成本,需要消耗的内存也非常高。
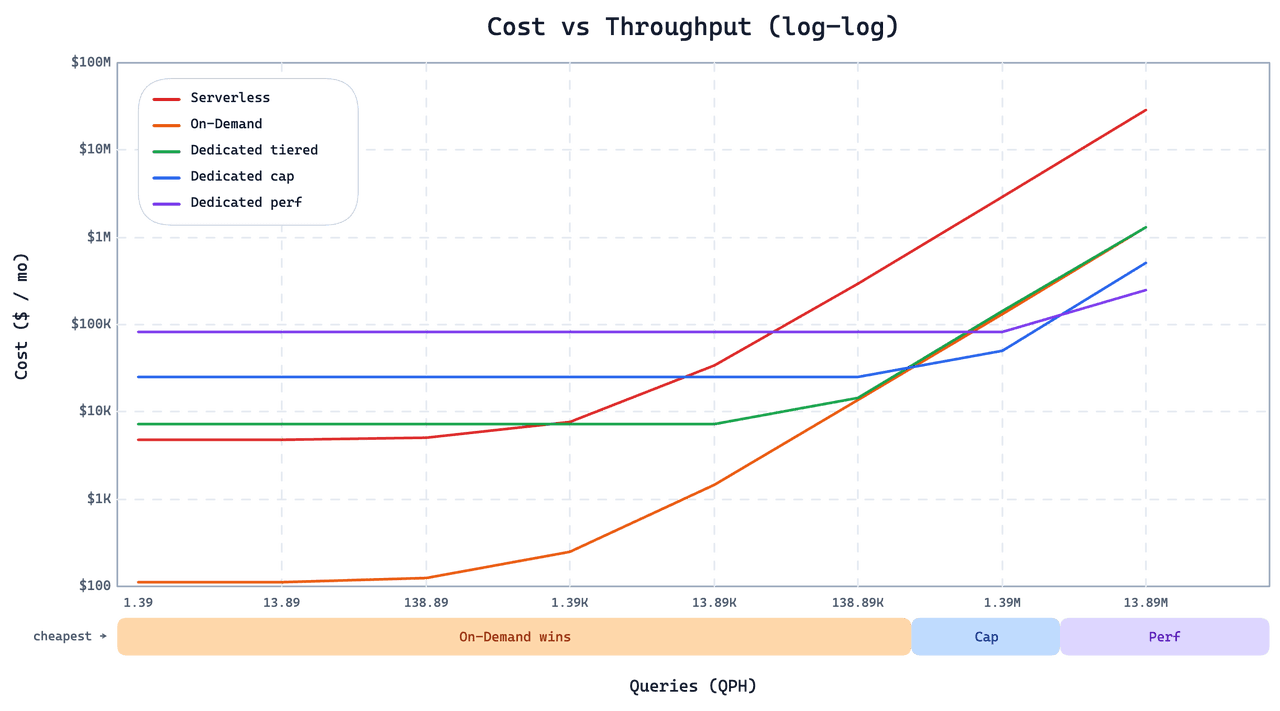
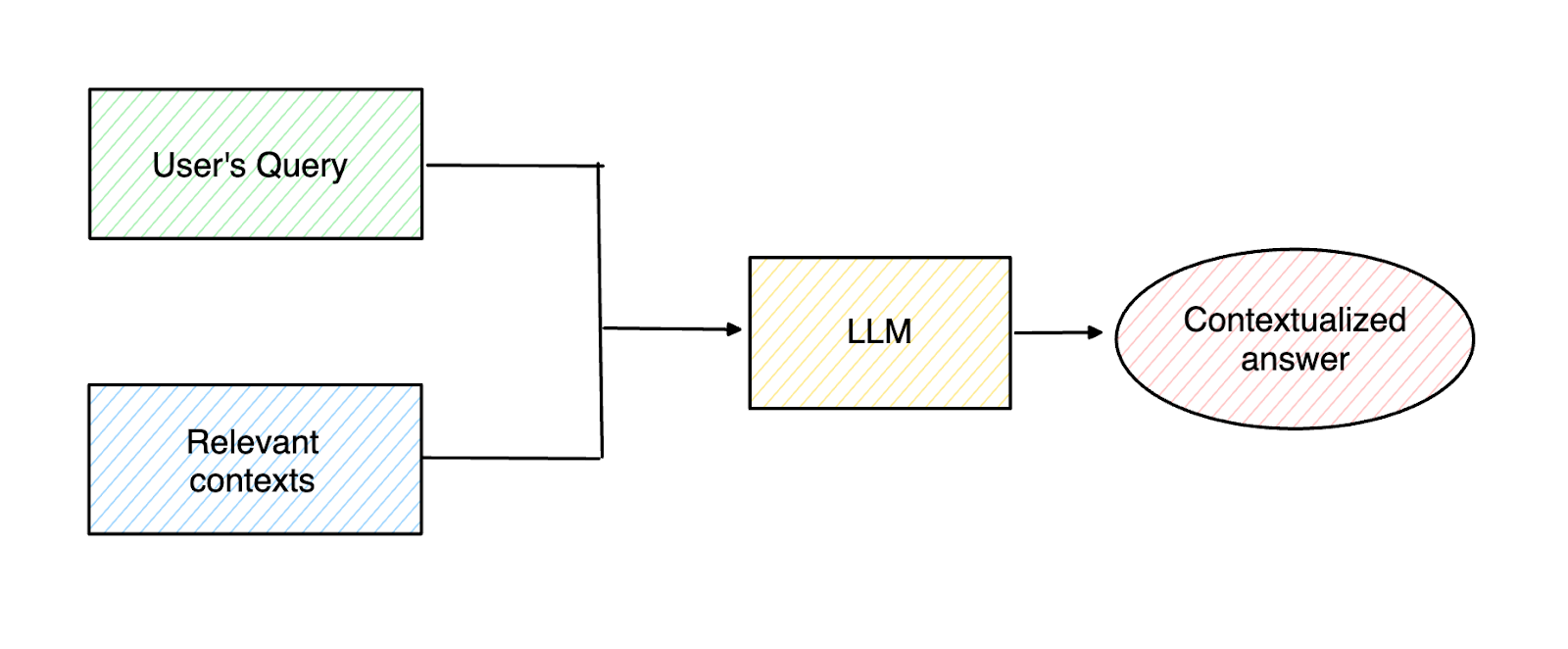
RAG 是另一种基于信息检索方法,可以缓解 LLM 幻觉。 我们首先获取用户的查询,然后在我们的数据库中找到最相关的上下文,这些上下文可以帮助 LLM 生成准确的回答。通过在用户查询的同时提供上下文,我们可以显著提高 LLM 响应的准确性。
 Figure_1_High_level_concept_of_RAG_1014643256.png
Figure_1_High_level_concept_of_RAG_1014643256.png
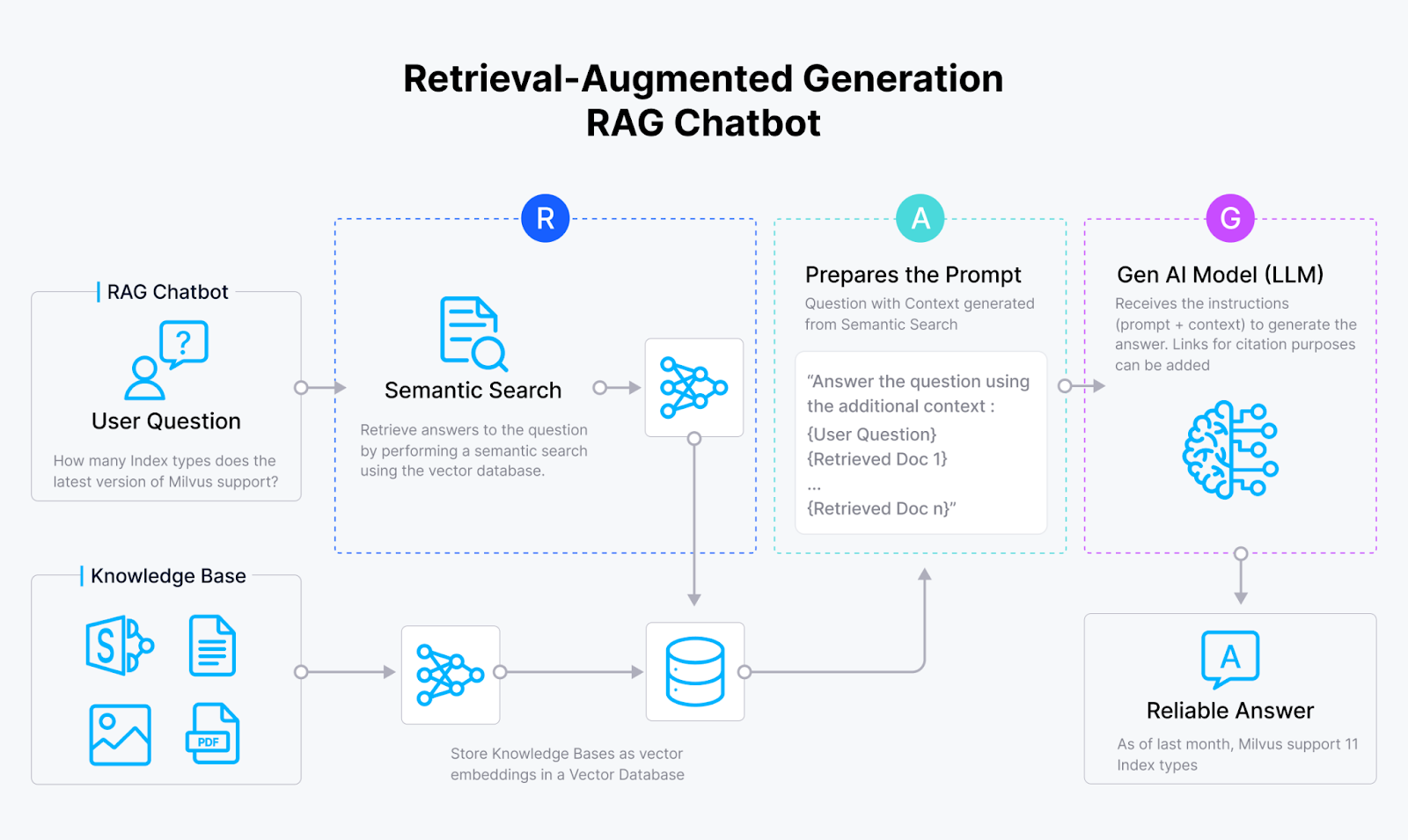
RAG 本身由三部分构成:检索(Retrieval)、增强(Augmentation)、生成(Generation)。
在检索组件中,RAG 检索可以帮助 LLM 生成基于上下文的回答。为了检索上下文,我们首先必须使用如 Sentence Transformers、OpenAI、VoyageAI 等 Embeding 模型将所有上下文信息转换为向量。接下来,我们将这些向量存储在 Milvus 和 Zilliz Cloud(全托管 Milvus 服务)之类的向量数据库中。
当用户进行查询时,我们使用与编码上下文相同的模型将查询转换为向量。然后,在 Milvus 这样的向量数据库中执行向量搜索(也称为向量相似性搜索或语义相似性搜索),以计算查询向量与向量数据库内上下文向量之间的相似性。最后,与用户查询相似度最高的top-k 个结果将被作为相关上下文。
在增强组件中,从检索组件检索到的相关上下文被合并在一起,与原始用户查询一起形成一致的 Prompt,传入 LLM。最后,LLM 根据提供的 Prompt 在生成组件中生成最终响应。
 Figure_2_RAG_workflow_03d6a0c5b2.png
Figure_2_RAG_workflow_03d6a0c5b2.png
什么是多模态 RAG 应用?
RAG 通过在用户查询的同时提供相关上下文,能够有效提高 LLM 响应质量。然而,在现实世界的应用中,并非所有相关上下文都以文本形式提供。
可能存在这样的情况,即最相关的上下文以文档中的图像或表格的形式提供。问题是,由于大多数 LLM 和 Embedding 模型的性质,它们无法推断图像内的内容。它们在推断表格或表格数据的内容时也往往遇到困难。正如你可能已经了解的那样,LLM 被预训练用于预测给定 Token 的下一个最可能的 Token。这意味着 LLM 会自然地尝试按顺序理解文本内容,这并不适用于表格数据。
多模态 RAG 是一种新方法,它接受来自不同模态的数据作为上下文传递给 LLM。我们需要使用具有多模态能力的 LLM 来执行多模态 RAG 任务,例如 LLaVA、GPT-4-V、Gemini 1.5、Claude 3.5 Sonnet 等模型。不过,我们仍然可以使用基于文本的 Embedding 模型,像 CLIP 这样的多模态模型也是一个不错的选择。
我们可以通过几种方式实现多模态 RAG:
使用像 CLIP 这样的多模态 Embedding 模型将文本和图像转换为向量。接下来,通过执行查询和文本/图像向量之间的相似性搜索来检索相关上下文。最后,将最相关上下文的原始文本和/或图像传递给我们的多模态 LLM。
使用多模态 LLM 为图像或表格生成文本摘要。接下来,使用基于文本的 Embedding 模型将这些文本摘要转换为向量。然后,执行查询和摘要向量之间的文本相似性搜索。最后,将最相关摘要的原始图像传递给我们的 LLM 以生成响应。
在接下来的部分中,我们将根据第二种方法实现多模态 RAG。具体来说,我们将使用 Gemini 1.5 模型为图像和表格生成文本摘要,并生成最终响应。
Milvus Lite、Gemini 1.5、BGE M3 和 LangChain 简介
我们即将构建的多模态 RAG(Retrieval-Augmented Generation)系统将使用到以下 4 个部分:Milvus 向量数据库、Gemini 1.5 大语言模型、BGE M3 Embedding 模型和 LangChain 框架。
Milvus Lite
Milvus 是一款开源向量数据库,能够高效存储十亿规模的向量数据,并在 RAG 的检索阶段执行高效的向量搜索。Milvus 提供多种安装方式,但对于初学者来说,最简单的方式是使用 Milvus Lite。如果您是初学者并且只想简单尝试 Milvus,那么我们推荐您使用 Milvus Lite。只需一个简单的命令,您就可以立即开始使用 Milvus 存储至高 1 百万个向量。以下是安装 Milvus Lite 的命令:
pip install pymilvus
然而,如果您需要扩展您的应用,并最终部署到生产环境,我们推荐您在 Docker 容器或 Kubernetes 上部署 Milvus。更多内容,请参考 Milvus 官方安装指南。
Gemini 1.5
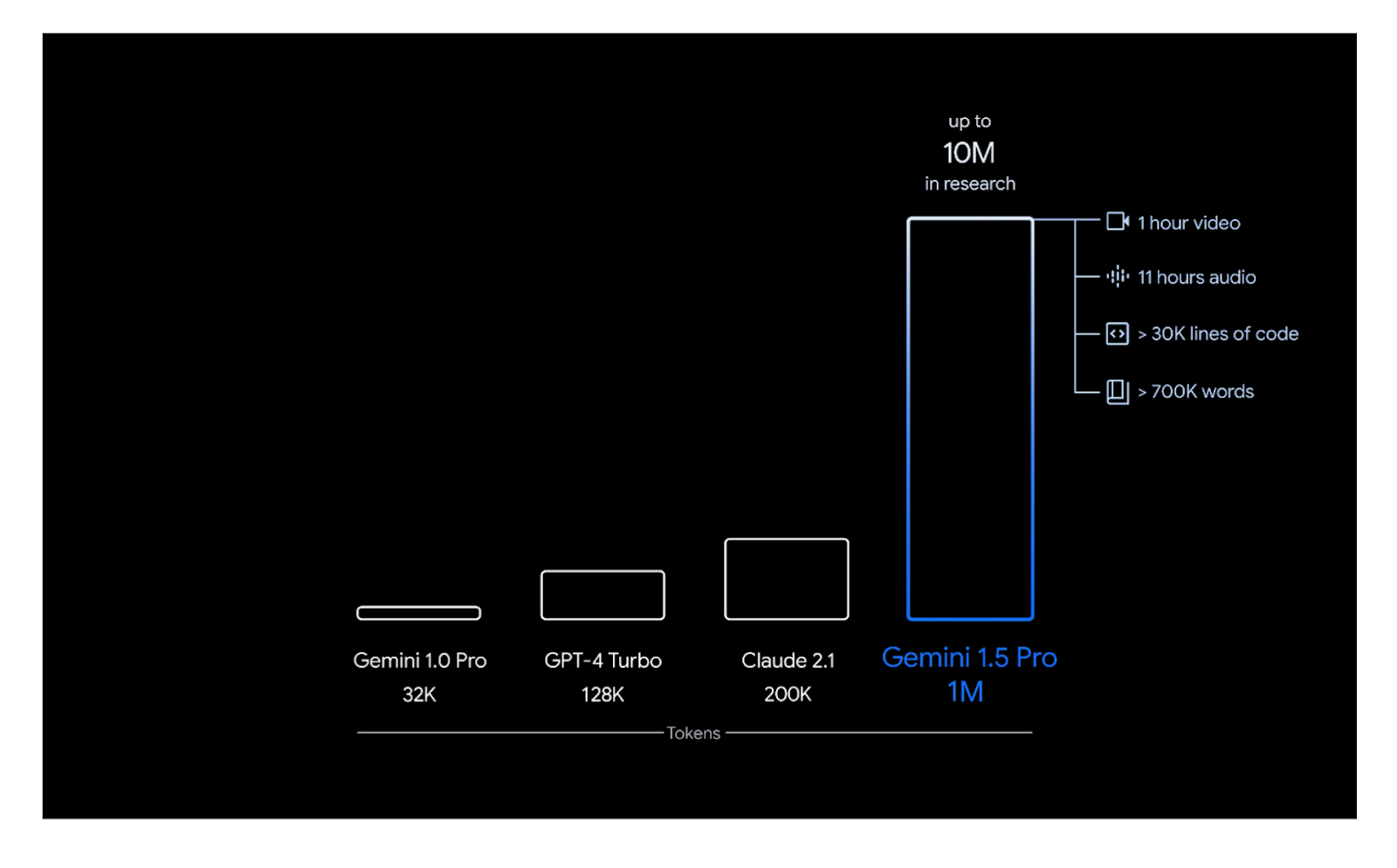
Gemini 1.5 是由 Google DeepMind 开发的一款多模态大语言模型(LLM),基于此前的 Gemini 1.0 模型进行了改进。与 Gemini 1.0 相比,这个模型在数学、编程、多语言能力以及理解图像、音频和视频方面都有显著提升。Gemini 1.5 有两个独特的特点:模型架构和上下文长度。
Gemini 1.5 的架构结合了 Transformer 架构和 Mixture of Experts(MoE)。这种结合提高了模型的效率,因为 MoE 模型学会了根据用户的输入或 Prompt 有选择地激活其神经网络中最相关的专家路径。Gemini 1.5 还支持更长的上下文,能够处理高达 100 万个 Token 的上下文。相比之下,Gemini 1.0 只能处理 32,000 个 Token。
 Figure_3_Gemini_1_5_Pro_s_context_length_1ee7297ccd.png
Figure_3_Gemini_1_5_Pro_s_context_length_1ee7297ccd.png
Gemini 1.5 模型有两个版本:Flash 和 Pro。Flash 是 Gemini 1.5 的轻量版本,它在生成响应时更快、更高效。而 Pro 是 Gemini 1.5 模型中性能最强的版本,其性能与迄今为止最大的 Gemini模型 —— Gemini 1.0 Ultra 相当。
在本文中,我们将使用 Gemini 1.5 Pro。为了在搭建多模态 RAG 应用时使用这个模型,您需要先设置一个 API 密钥。可以参考这个 Google 页面上的指南来生成 API 密钥。
BGE-M3
BGE-M3 是一个多功能的 Embedding 模型,能够处理多种语言的文本,并支持不同的粒度级别。例如,您可以处理短句,也可以处理长达 8192 个 Token 的长文档。这个 Embedding 模型还能够输出两种不同的向量类型:稠密向量(Dense embedding)和稀疏向量(Sparse embedding)。
稠密向量的维度比稀疏向量更紧凑,并且包含原始输入的语义表示。与此同时,正如其名,稀疏向量具有高维度,但大多数元素都是零。因此,针对稀疏向量可以使用专门的数据结构和算法实现更高效地存储和处理。
在下面的 RAG 应用中,我们将使用 BGE-M3 作为 Embedding 模型,将文本输入转换为向量。我们可以使用以下代码在 Milvus 中使用 BGE-M3:
!pip install "pymilvus[model]"
from pymilvus.model.hybrid import BGEM3EmbeddingFunction
bge_m3_ef = BGEM3EmbeddingFunction(
model_name='BAAI/bge-m3', # Specify the model name
device='cpu', # Specify the device to use, e.g., 'cpu' or 'cuda:0'
use_fp16=False # Specify whether to use fp16. Set to `False` if `device` is `cpu`.
)
docs = [
"Artificial intelligence was founded as an academic discipline in 1956.",
"Alan Turing was the first person to conduct substantial research in AI.",
"Born in Maida Vale, London, Turing was raised in southern England.",
]
docs_embeddings = bge_m3_ef.encode_documents(docs)
# Print embeddings
print("Embeddings:", docs_embeddings)
"""
Output:
Embeddings: {'dense': [array([-0.02505937, -0.00142193, 0.04015467, ..., -0.02094924,
0.02623661, 0.00324098], dtype=float32), array([ 0.00118463, 0.00649292, -0.00735763, ..., -0.01446293,
0.04243685, -0.01794822], dtype=float32), array([ 0.00415287, -0.0101492 , 0.0009811 , ..., -0.02559666,
0.08084674, 0.00141647], dtype=float32)], 'sparse': <3x250002 sparse array of type '<class 'numpy.float32'>'
with 43 stored elements in Compressed Sparse Row format>}
"""
如上所示,我们可以基于同一个输入获取两种不同类型的向量:稠密向量和稀疏向量。因为 Milvus 支持混合搜索(Hybrid Search),我们可以在向量搜索中同时使用这两种向量类型,从而增强 RAG 系统中检索到的上下文的准确性和质量。
LangChain
LangChain 框架可以帮助我们在几分钟内构建 LLM 驱动的应用。LangChain 是一个编排工具,连接诸如向量数据库、Embedding 模型和 LLM 等组件,构建一个功能完整的 RAG 系统。LangChain 支持无缝集成主流 LLM (如 OpenAI、Anthropic 和 Google)以及向量数据库(如 Zilliz 等)。
LangChain 还处理 RAG 系统的端到端工作流程,从数据预处理(如数据解析、清洗和分块)到 LLM 生成响应并返回给用户。我们将在下一章节中详细介绍该框架的具体实现方式。
搭建多模态 RAG 应用
在这个部分,我们将构建一个多模态 RAG 应用。正如前面提到的,大多数 LLM 为预训练模型,在处理图像或表格中的上下文时可能会遇到困难。我们即将搭建的多模态 RAG 可以将图像中的上下文考虑在内,从而提高我们 LLM 的整体响应质量。
我们的多模态 RAG 用例如下:我们将构建一个 RAG 系统,帮助我们查询与研究论文(以 PDF 文件格式保存)相关的信息。我们将要处理的研究论文是《Attention is All You Need》,这篇论文介绍了著名的 Transformer 架构。
首先,我们将下载 PDF 文件并提取所有的图表和表格。接下来,我们将使用 Gemini 1.5 Pro 为每个提取的图表和表格生成摘要,以便进行上下文检索。然后,我们将使用 BGE-M3 模型将这些摘要转换为 Embedding 向量,并存储在 Milvus 向量数据库中。
在 RAG 搭建过程中,我们将把用户查询转换为 Embedding 向量,并执行向量搜索以找到最相关的摘要。然后,系统最相关摘要的原始图表或表格检索出来,并传入 Gemini 1.5 以生成响应。
如果您希望跟随以下指南进行操作,可以在这个 Notebook 中获取本文的所有代码。
让我们从第一步开始——下载研究论文。我们可以使用 Arxiv API 来完成这个任务。
import arxiv
import os
import getpass
from langchain_core.prompts import PromptTemplate
from langchain_core.runnables import RunnableLambda, RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
from langchain_milvus.vectorstores import Milvus
from langchain.schema import Document
from langchain.embeddings.base import Embeddings
from pymilvus.model.hybrid import BGEM3EmbeddingFunction
from langchain_core.messages import HumanMessage
from langchain_google_genai import ChatGoogleGenerativeAI
from IPython.display import HTML, display
from PIL import Image
import base64
from pdf2image import convert_from_path
import layoutparser as lp
import cv2
import numpy as np
file_path = "./Dataset/pdf/"
arxiv_client = arxiv.Client()
paper = next(arxiv.Client().results(arxiv.Search(id_list=["1706.03762"])))
# Download the PDF to a specified directory with a custom filename.
paper.download_pdf(dirpath=file_path, filename="attention.pdf")
您可以根据提供的 ID 下载任何研究论文。当您在 Arxiv 上浏览研究论文时,您可以在网页地址中找到这个 ID。例如,《Attention is All You Need》 这篇论文的 ID 是 1706.03762。
接下来,让我们从 PDF 文件中提取图表和表格。根据我的观察,使用基于 PubLayNet 数据集训练的 Mask-RCNN 模型进行这项任务是最准确的。我们可以借助 LayoutParser 库来使用 Mask-RCNN 模型来执行提取任务。
image_path = "./Dataset/img/"
def extract_image_and_table(pdf_path, output_dir):
images = convert_from_path(pdf_path)
model = lp.Detectron2LayoutModel('lp://PubLayNet/mask_rcnn_X_101_32x8d_FPN_3x/config',
extra_config=["MODEL.ROI_HEADS.SCORE_THRESH_TEST", 0.75],
label_map={0: "Text", 1: "Title", 2: "List", 3:"Table", 4:"Figure"})
for i, image in enumerate(images):
image_np = cv2.cvtColor(np.array(image), cv2.COLOR_RGB2BGR)
layout_result = model.detect(image_np)
blocks = lp.Layout([b for b in layout_result if b.type=='Table' or b.type=='Figure'])
for j, block in enumerate(blocks._blocks):
x1 = int(block.block.x_1)
y1 = int(block.block.y_1)
x2 = int(block.block.x_2)
y2 = int(block.block.y_2)
cropped_image = Image.fromarray(image_np).crop((x1, y1, x2, y2))
cropped_image.save(f'{output_dir}/{i}_{j}.png', 'PNG')
extract_image_and_table(f"{file_path}attention.pdf", image_path)
我们已经从研究论文中提取了所有的图表和表格,现在让我们使用 Gemini 1.5 Pro 生成每个图表和表格的摘要。您需要使用您的 API 密钥来访问这个 LLM。
我们从 PDF 文件中提取的图表和表格被存储为 PNG 文件。然而,我们不能将这些原始图像作为输入直接提供给我们的多模态 LLM,因为大多数 API 都要求输入的是文本。因此,我们需要将这些图像文件编码为 base64 格式。通过编码,我们可以将图像作为文本字符串在 API 请求中发送。
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode("utf-8")
def image_summarize(img_base64, prompt):
msg = llm_model.invoke(
[
HumanMessage(
content=[
{"type": "text", "text": prompt},
{
"type": "image_url",
"image_url": {"url": f"data:image/jpeg;base64,{img_base64}"},
}
]
)
]
)
return msg.content
def generate_img_summaries(path):
# Store base64 encoded images
img_base64_list = []
# Store image summaries
image_summaries = []
# Prompt
prompt = """You are an assistant tasked with summarizing images for retrieval.
These summaries will be embedded and used to retrieve the raw image.
Give a concise summary of the image that is well optimized for retrieval."""
# Apply to images
for i, img_file in enumerate(sorted(os.listdir(path))):
if img_file.endswith(".png"):
img_path = os.path.join(path, img_file)
base64_image = encode_image(img_path)
img_base64_list.append(base64_image)
image_summaries.append(image_summarize(base64_image, prompt))
return img_base64_list, image_summaries
img_base64_list, image_summaries = generate_img_summaries(image_path)
documents = [Document(page_content=image_summaries[i], metadata={"source": img_base64_list[i]}) for i in range (len(image_summaries))]
现在,让我们通过一个例子来检查 Gemini 1.5 Pro 生成的对应摘要是否合适。您可以通过以下代码实现:
def plt_img_base64(img_base64):
# Create an HTML img tag with the base64 string as the source
image_html = f'<img src="data:image/jpeg;base64,{img_base64}" />'
# Display the image by rendering the HTML
display(HTML(image_html))
plt_img_base64(img_base64_list[0])
print(image summaries[0])
 Figure_5_Example_of_a_table_and_its_corresponding_summarization_0eed08f8f3.png
Figure_5_Example_of_a_table_and_its_corresponding_summarization_0eed08f8f3.png
由 Gemini 1.5 Pro 模型生成的摘要准确概括了图表中提供的整体信息。接下来,我们需要将这些摘要与编码后的图像一起存储在 Milvus 向量数据库中。
首先,需要将摘要转换为 Embedding 向量。我们将使用 BGE-M3 模型来执行这项任务。稍后,我们将仅使用 BGE-M3 生成的稠密向量进行上下文检索。
在 LangChain 中使用这个 Embedding 模型时,我们需要创建一个自定义 Class,其中包含两个不同的 Method:embed_documents 和 embed_query。LangChain 会默认调用这两个函数,将输入转换为向量并存储在向量数据库中。
class BGEMilvusEmbeddings(Embeddings):
def __init__(self):
self.model = BGEM3EmbeddingFunction(
model_name='BAAI/bge-m3', # Specify the model name
device='cpu', # Specify the device to use, e.g., 'cpu' or 'cuda:0'
use_fp16=False # Specify whether to use fp16. Set to `False` if `device` is `cpu`.
)
def embed_documents(self, texts):
embeddings = self.model.encode_documents(texts)
return [i.tolist() for i in embeddings["dense"]]
def embed_query(self, text):
embedding = self.model.encode_queries([text])
return embedding["dense"][0].tolist()
# Instantiate embedding model and LLM
embedding_model = BGEMilvusEmbeddings()
os.environ['GOOGLE_API_KEY'] = getpass.getpass('Gemini API Key:')
llm_model = ChatGoogleGenerativeAI(model="gemini-1.5-pro",
temperature=0.7, top_p=0.85)
URI = "./milvus_demo.db"
# Create Milvus vector store and store the embeddings inside it
vectorstore = Milvus.from_documents(
documents,
embedding_model,
connection_args={"uri": URI},
collection_name="multimodal_rag_demo"
)
# Create a retriever from the vector store
retriever = vectorstore.as_retriever()
现在让我们来试用这个 RAG 应用。
假设我们的查询为:“What's the BLEU score of the base model on English to German translation task?”
我们可以通过以下示例代码来查看 RAG 系统检索到的最相关图像。
# Use the retriever
query = "What's the BLEU score of the base model on English to German translation task?"
retrieved_docs = retriever.invoke(query, limit= 1)
plt_img_base64(retrieved_docs[0].metadata["source"])
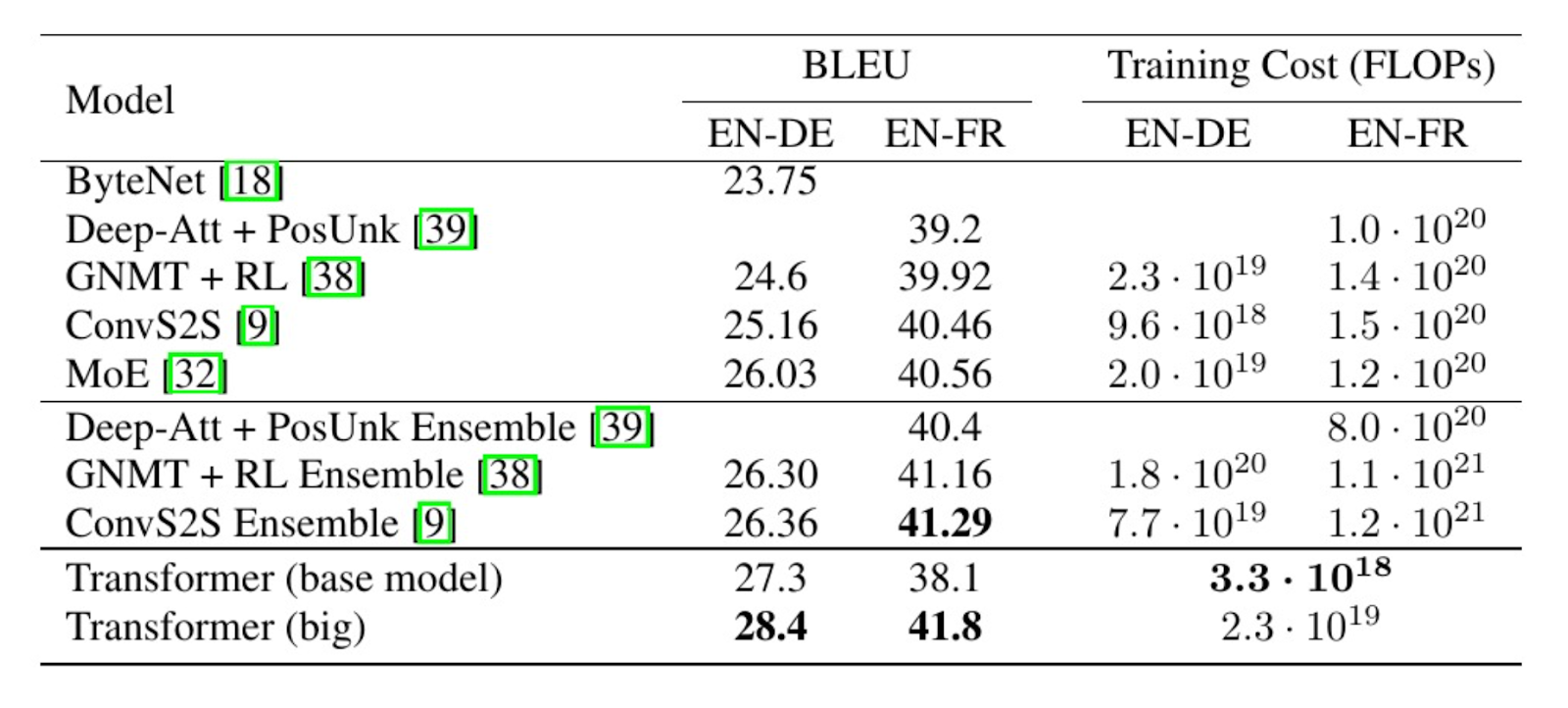 Figure_6_Example_of_the_retrieved_context_for_a_given_query_ff5d9fc112.png
Figure_6_Example_of_the_retrieved_context_for_a_given_query_ff5d9fc112.png
我们可以看到,RAG 系统能够根据查询检索到最相关的图像。在 RAG 流程中,这张图像将作为上下文传入 Gemini 1.5 Pro,生成一个基于上下文的答案。
剩下要做的事情就是构建端到端的响应生成工作流程。这个过程包括接收用户查询、获取最相关的上下文、将该上下文和用户查询合并成一个连贯的 Prompt、将 Prompt 传入 LLM,最后从 LLM 生成响应并返回给用户。您可以使用 LangChain 并通过几行代码完成所有上述步骤。
def prepare_image_context(docs):
b64_images = []
for doc in docs:
b64_images.append(doc.metadata["source"])
return {"images": b64_images}
def img_prompt(data_dict):
messages = []
if data_dict["context"]["images"]:
for image in data_dict["context"]["images"]:
image_message = {
"type": "image_url",
"image_url": {"url": f"data:image/jpeg;base64,{image}"},
}
messages.append(image_message)
text_message = {
"type": "text",
"text": (
"You will be given an image or a table.\n"
"Use information contained in the image or table to provide contextualized answer related to the user question. \n"
f"User-provided question: {data_dict['question']}\n\n"
),
}
messages.append(text_message)
return [HumanMessage(content=messages)]
def multi_modal_rag_chain(retriever):
# RAG pipeline
chain = (
{
"context": retriever | RunnableLambda(prepare_image_context),
"question": RunnablePassthrough(),
}
| RunnableLambda(img_prompt)
| llm_model
| StrOutputParser()
)
return chain
# Create RAG chain
chain_multimodal_rag = multi_modal_rag_chain(retriever)
我们可以用一行代码调用 RAG 应用来处理查询。
# Run RAG chain
chain_multimodal_rag.invoke(query)
"""
Output:
The BLEU score of the base Transformer model on English to German translation task is 27.3.
"""
查看 notebook 获取本示例所有代码。
总结
恭喜!您已成功搭建了一个基于 Milvus、Gemini 1.5、BGE-M3 和 LangChain 的多模态 RAG 系统。多模态 RAG 系统可以增强 LLM 对特定用户查询的响应准确性,特别是在相关上下文以非文本格式存储的场景中。
现在,您可以将这个基础 RAG 流程应用于查询其他研究论文或更丰富的用户场景中。在本文示例中,我们在向量数据库中仅存储了约 15 个上下文向量。但 Milvus Lite 允许您存储多达一百万个向量,我们推荐您通过安装 Milvus Lite 或在 Docker/Kubernetes 上部署 Milvus 或使用全托管 Mlivus 服务——Zilliz Cloud 来存储更多上下文向量,从而扩展您的应用。
 Ruben Winastwan
Ruben WinastwanFreelance Technical Writer