保护数据完整性:使用LLMware和Milvus进行本地RAG部署
在我们最新的非结构化数据 meetup 会议上,我们有幸邀请到了AI Blocks的首席执行官Darren Oberst。他毕业于加州大学伯克利分校,拥有物理和哲学学位,目前专注于为金融和法律服务转变大型语言模型(LLM)应用的开发。在这次聚会上,Darren讨论了为什么大型金融和法律服务公司应该在本地部署检索增强生成(RAG)。
在这篇博客中,我们不仅将回顾Darren的关键观点,还会提供一个使用LLMware和Milvus向量数据库在私有云上构建RAG的实际示例。这个示例旨在激发和激励您将这些知识应用到您的项目中。我们还推荐您在YouTube上观看完整会议。
RAG部署的主要挑战
大型语言模型可能是不一致的。有时,它们提供精确的答案,但也可能产生不相关的信息。这种不一致性产生是因为LLMs理解单词之间的统计关系而没有真正把握它们的含义。此外,LLMs是预先训练在过时和公开可用的数据上,限制了它们提供特定于您的私有数据或最新信息的准确答案的能力。
检索增强生成(RAG)是一种流行的技术,通过增强LLM的回答与存储在像Milvus这样的向量数据库中的外部知识源,从而提高内容质量。虽然RAG是一种卓越的技术,但它的部署提出了挑战。
在演讲中,Darren分享了许多企业面临的常见挑战。
- 数据隐私和安全问题:许多企业,特别是金融和法律行业的企业,由于隐私和安全问题,犹豫使用公共云服务。许多现有解决方案也专注于公共云而不是本地,这给需要确保数据安全和合规的公司带来了挑战。
- 成本上升:经常使用大规模模型的公共云基础设施可能会产生高额费用。在缺乏对基础设施、数据和应用程序的完全控制和所有权的情况下支付如此高额的费用,结果是双输局面。
- 忽视检索策略:一个经常被忽视的重要方面是RAG部署中的检索策略的重要性。虽然AI团队倾向于关注生成性AI能力,但检索文档的质量同样重要。
本地RAG部署
上述挑战可以通过一个共同的解决方案有效解决:在私有云上部署RAG。这种方法以以下方式解决问题:
- 更好的数据安全性:敏感的商业文件、监管信息和其他专有数据必须保留在私有云的安全范围内,以满足合规和安全标准。如果一切都在私有云中进行,就不会有违规行为。
- 降低成本:在私有云基础设施上部署AI模型可以提供比公共云服务更具成本效益的解决方案,特别是当需要频繁使用时。当我们使用较小的模型时,成本甚至更低,因为它们比更大、更资源密集的模型更有效地实现实际结果。由于它们的快速创新和定制能力,开源LLMs和技术是RAG的一个很好的选择。
- 在私有云中通过检索增强生成:更好的检索引擎可以补充生成能力有限的小型模型。只有通过制作更好的检索系统,才能显著提高AI应用程序的准确性和效率,如文档解析、文本分块和语义查询。
总之,Darren主张采用私有云解决方案进行AI,特别是LLMs,以解决与数据隐私、成本和结果相关的担忧。接下来,我们将讨论为RAG在Huggingface Transformers库中设计和优化的Dragon模型。
dRAGon(交付RAG)模型🐉
Dragon是AI Blocks推出的一系列模型,专门为检索增强生成(RAG)设计。它是一系列七个在合同、监管文件和复杂金融信息等专有数据集上微调的开源模型。模型有三个类别:
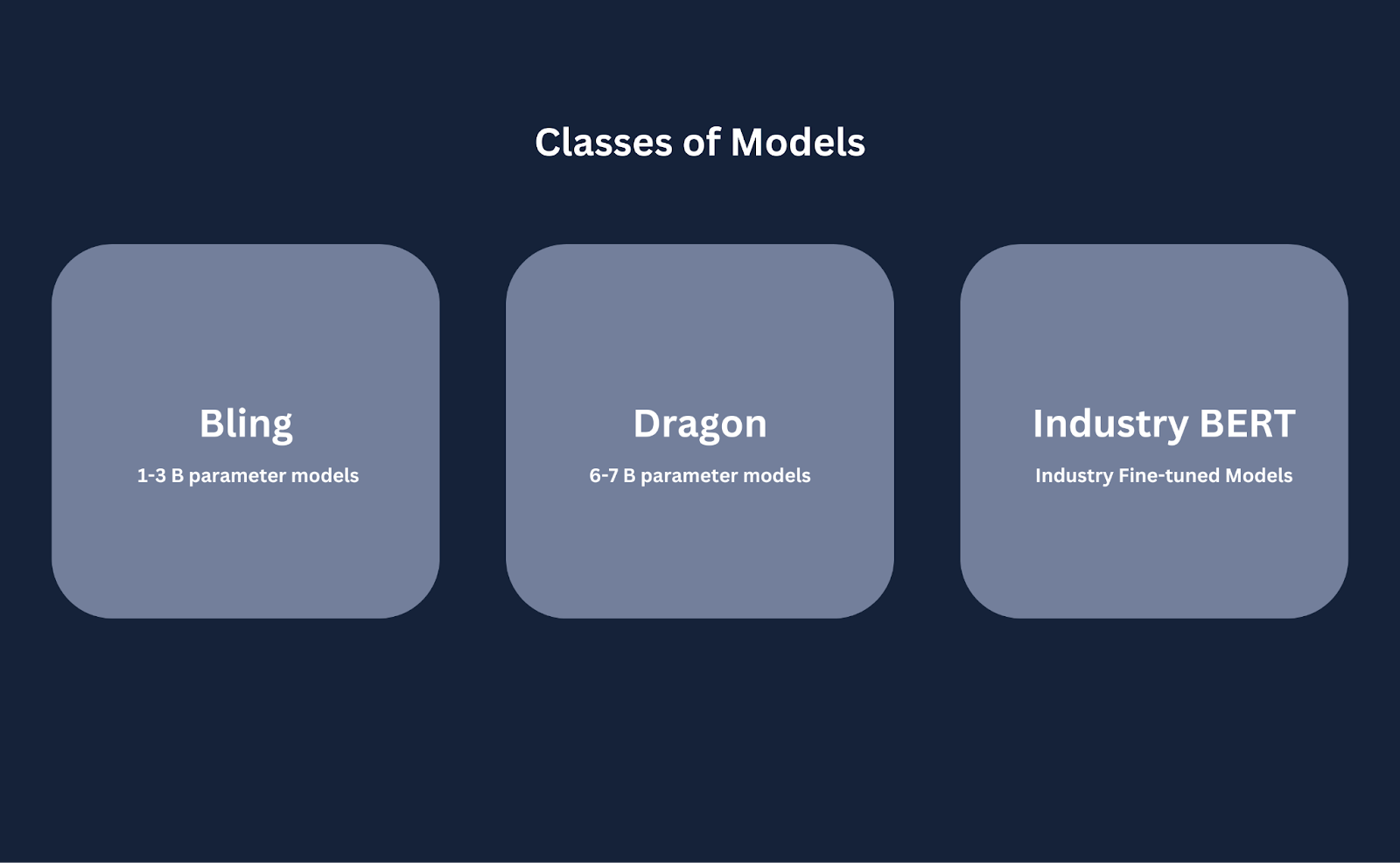 Classes_of_models_and_their_description_5b603cd089.png
Classes_of_models_and_their_description_5b603cd089.png
模型类别及其描述
- Bling模型:紧凑的、用于快速原型设计的指导调整模型,能够在CPU上运行,非常适合初始测试和开发阶段。它们对内存的压力较小,因为它们只包含1到30亿参数。
- Dragon RAG模型:微调版本的领先6和70亿参数基础模型,如Llama、Mistral、Red-pajama、Falcon和Deci。为基于事实的问题回答和监管文件分析等任务量身定制。
- 行业BERT模型:专为特定行业应用而设计的行业BERT模型是为合同分析等任务量身定制的句子转换器。
此外,这些模型使用常识RAG结构基准进行了严格的基准测试。与依赖科学指标如MMLU和ARC的开源模型不同,Dragon模型针对现实世界的准确性和实际用例进行了测试。这些模型集合在HuggingFace上可用,如下所示:
 LL_Mware_models_hosted_on_Hugging_Face_5c1d3cfc13.png
LL_Mware_models_hosted_on_Hugging_Face_5c1d3cfc13.png
在HuggingFace上托管的LLMware模型
使用这些模型的主要好处如下:
- 提高准确性:这些模型在广泛的数据集上进行了微调,能够在文档解析、文本分块和语义查询方面提供高精度。
- 成本效益:针对私有云基础设施进行了优化,与公共云上更大、资源密集型的模型相比,提供了成本效益高的解决方案。
- 开源和可定制:这些开源模型在Hugging Face上可用,允许快速创新和定制,以满足特定企业需求。
- 生产级性能:经过可靠性基准测试,这些模型在各种工作流程中提供一致且可靠的性能。
- 无缝集成:提供全面的支持和易于使用的生成脚本,将这些模型集成到现有工作流程中是直接的。
这样的模型在成本、准确性或可定制性上都不妥协;它们在LLMware中的集成使它们易于访问。
LLMware的一瞥
LLMware是一个为企业级LLM基础应用程序设计的库。它使用可以私有部署的小型专用模型,安全地与企业知识源集成,并成本效益地适应任何业务流程。这个工具包与LangChain或LlamaIndex相似,但为企业环境中的高可扩展性和强大的文档管理量身定制。
LLMware的组件:
- RAG管道:为连接知识源到生成性AI模型的整个生命周期提供集成组件。
- 专用模型:包括50多个小型、为企业任务微调的模型,如基于事实的问题回答、分类、摘要和提取。这些模型也包括上述模型;我们将在下一节中使用其中一个。
LLMware的特点:
- 大规模文档摄取:
- 构建以处理数十万份文档的摄取,LLMware支持并行处理和跨多个工作者的分布。
- 文档解析:使用自定义的基于C的解析器,实现对PDF、Word文档、PowerPoints和Excel文件的完整规范解析。
- 端到端数据模型:
- 与MongoDB集成,实现持久化数据存储,允许高效分块和索引文本集合。
- 企业集成:旨在无缝集成到企业数据工作流程中,确保安全且可扩展的数据管理。
- 基于LLM的应用程序框架:
- 优先支持广泛的开源和Hugging Face模型,使构建和部署LLM应用程序变得容易。
- 功能丰富的环境:不断发展以包括支持企业环境中多样化用例的新功能和能力。
- 易用性:
- 提供全面的例子和文档,帮助用户快速高效地开始使用。
- 企业焦点:专门构建以解决企业级LLM部署的独特需求,从文档管理到可扩展处理。
使用Milvus和LLMware在私有云中进行检索增强生成
本节将解释并实现在本地部署的RAG解决方案。让我们看看使用LLMware和Milvus向量数据库的RAG架构。
架构
此架构图说明了在本地使用LLMware和Milvus的RAG工作流程。
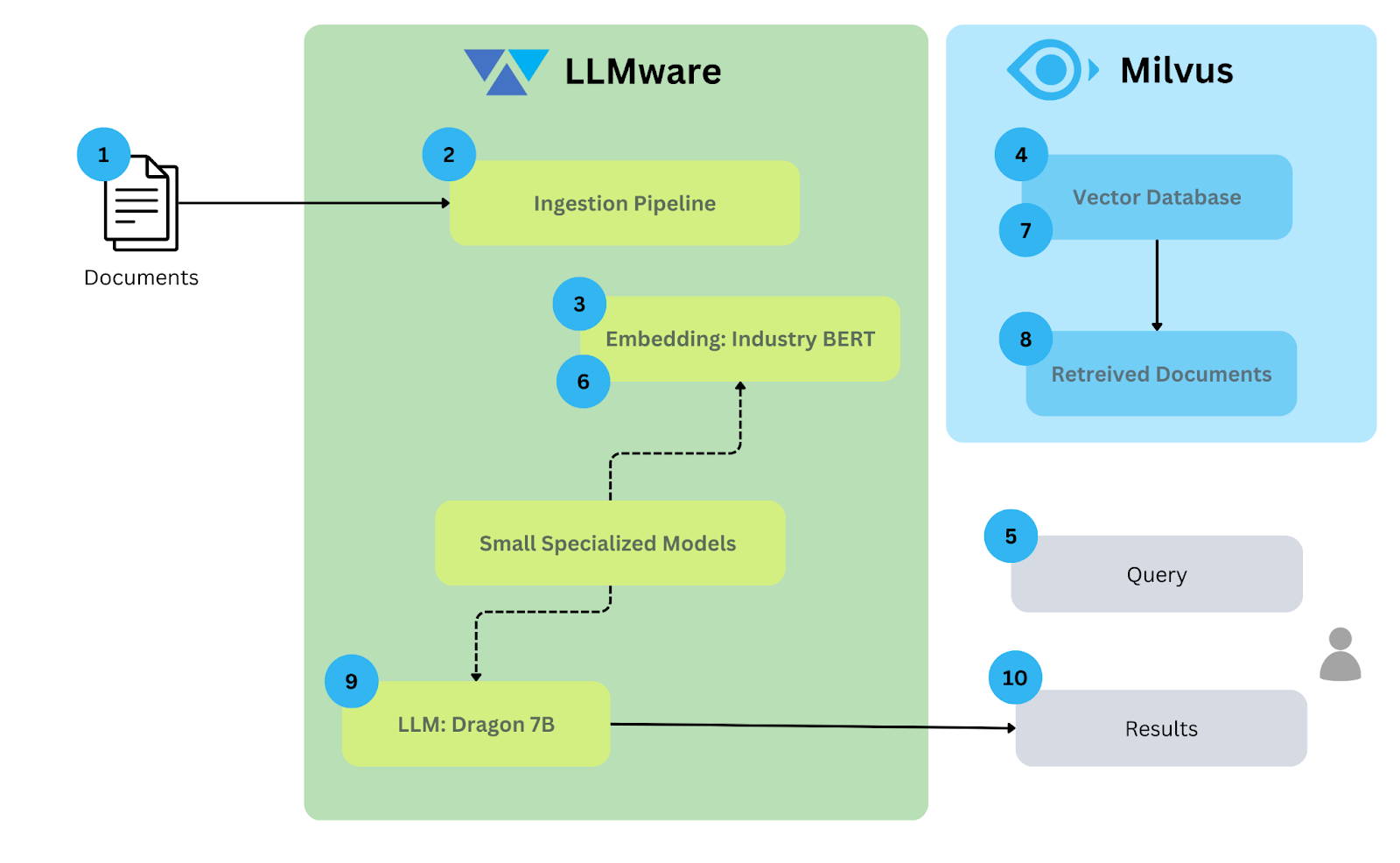 Architecture_diagram_for_RAG_on_premises_using_LL_Mware_and_Milvus_9845650a88.png
Architecture_diagram_for_RAG_on_premises_using_LL_Mware_and_Milvus_9845650a88.png
使用LLMware和Milvus在本地部署RAG的架构图
这里是每个组件的解释:
文档:输入数据由各种要处理的文档组成。在这个例子中,大约80个样本文档从S3桶中提取。
摄取管道:这是初始步骤,文档被摄取到系统中。这个管道通过提取相关信息并可能执行预处理任务(如清理或格式化数据)来准备文档以进行进一步处理。
生成嵌入:摄取后,文档被传递到嵌入模型。在这种情况下,Industry BERT模型将文档转换成捕获文本语义的数值表示(向量嵌入)。
向量数据库:由Industry BERT模型生成的嵌入与文档一起存储在向量数据库Milvus中。这个专门的向量数据库旨在处理和高效搜索大规模向量数据。
查询:用户向系统提交查询。
查询嵌入:此查询也被转换成嵌入,以便与存储在Milvus中的文档嵌入进行比较。
搜索文档:计算查询和文档嵌入之间的相似性,相似性更大的文档排名更高。
检索文档:检索相似性高的相关内容。检索文档的数量和相似性阈值可以自定义。
LLM:检索到的文档和查询将被发送到LLM;在我们的例子中,LLM是Bling 7B。
结果:LLM的响应提供给用户。
下一节将展示在私有云中实现RAG应用程序的过程。
实现
在这次实现中,我们将通过将大约80个法律文档摄取到Milvus向量数据库中,并使用LLM提问来构建RAG应用程序。我们假设用户已经为这篇博客安装了Milvus,并可以启动服务。
导入
我们首先安装所需的库,并将它们导入到我们的环境。我们将需要llmware和PyMilvus。以下是如何安装它:
pip install llmware
Pip install pymilvus>=2.4.2
此步骤之后,让我们从llmware导入所需模块。
import osfrom llmware.library import Libraryfrom llmware.retrieval import Queryfrom llmware.setup import Setupfrom llmware.status import Statusfrom llmware.prompts import Promptfrom llmware.configs import LLMWareConfig, MilvusConfig
导入数据后,我们将设置配置。
配置
配置步骤非常简单。在这一步中,我们存储嵌入模型、向量数据库和LLM的名称。
embedding_model = "industry-bert-contracts"
vector_db = "milvus"
llm = "llmware/bling-1b-0.1"
设置包括industry-bert-contracts嵌入模型,Milvus作为向量数据库,以及llmware/bling-1b-0.1语言模型,以优化AI驱动的文档处理和分析。
设置Milvus
由于其集成,使用llmware设置Milvus非常简单。在PyMilvus安装后,我们需要将vector_db设置为Milvus,同时将active_db设置为sqlite,如下所示:
LLMWareConfig().set_active_db("sqlite")
MilvusConfig().set_config("lite", True) # No dependency
LLMWareConfig().set_vector_db("milvus")
llmware支持Milvus-lite,它是自包含的,不需要其他依赖项。
创建库
在llmware中,库是组织非结构化信息的主要构造。用户可以创建一个包含多样化内容的大型库,或者创建多个库,每个库专门用于特定主题、项目、案例、交易、账户、用户或部门。
要创建库,我们可以简单地调用Library类的create_new_library函数,它需要一个任意名称作为参数。让我们看看。
Library_name = "contracts-Rag"
library = Library().create_new_library(library_name)
摄取文档
LLMware中的Setup类从AWS S3桶下载样本文件,包括合同、发票、财务报告等各种样本文档。您总是可以通过使用load_sample_files获取这些样本的最新版本。在这个例子中,我们将上传“Agreements”
sample_files_path = Setup().load_sample_files(over_write=False)
contracts_path = os.path.join(sample_files_path, "Agreements")
Llmware有一个有用的功能,名为add_files,这是一个通用摄取工具。将其指向包含混合文件类型的本地文件夹,它将自动根据文件扩展名将文件路由到适当的解析器。然后文件被解析、文本分块,并在文本集合数据库中索引。
library.add_files(input_folder_path=contracts_path)
文档已加载。让我们创建其嵌入。
创建嵌入
这次实现中的一切都在本地运行。因此,嵌入模型在本地下载。如上所述,嵌入模型是industry-bert-contracts,而Milvus是向量数据库。
library.install_new_embedding(embedding_model_name=embedding_model, vector_db=vector_db)
在库中安装嵌入后,您可以检查嵌入状态以验证更新的嵌入,并确认模型已准确捕获。
Status().get_embedding_status(library_name, embedding_model)
让我们看看如何在下一节中调用LLM。
加载大型语言模型
我们将使用load_model函数加载Bling模型。这些模型较小,适合快速测试。
prompter = Prompt().load_model(llm)
搜索文档
在Llmware中,Query类用于搜索和检索,需要Library作为必需参数。这种方法允许检索利用Library抽象,支持与不同用例、用户、账户和权限对齐的多个不同的知识库。
这个类允许许多搜索功能,如文本搜索和语义搜索。我们将在我们的示例中使用语义搜索。
query = "what is the executive's base annual salary"
results = Query(library).semantic_query(query, result_count=50, embedding_distance_threshold=1.0)
将所有部分组合在一起
这一节将循环遍历所有合同,过滤相关结果,并使用LLM生成响应。以下是代码片段:
for i, contract in enumerate(os.listdir(contracts_path)):
qr = []
for j, entries in enumerate(results):
if entries["file_source"] == contract:
print("Top Retrieval: ", j, entries["distance"], entries["text"])
qr.append(entries)
source = prompter.add_source_query_results(query_results=qr)
response = prompter.prompt_with_source(query, prompt_name="default_with_context", temperature=0.3)
for resp in response:
if "llm_response" in resp:
print("\nupdate: llm answer - ", resp["llm_response"])
# start fresh for next document
prompter.clear_source_materials()
这是它的指南。
- 遍历合同:对于目录中的每个合同文件,它初始化一个列表来存储相关查询结果。
- 过滤相关结果:它过滤与当前合同匹配的结果,并打印顶部检索结果。
- 生成响应:过滤后的结果使用语言模型生成响应,并打印生成的响应。
- 为下一个合同重置:它清除源材料,为下一个合同做准备。
查询结果如下所示:
>>> Contract Name: Rhea EXECUTIVE EMPLOYMENT AGREEMENT.pdf
Top Retrieval: 1 0.6237360223214722The Board (or its compensation committee) will annually review the Executive's base salary following the Employer's standard compensation and performance review policies for senior executives. While the salary may be increased, it cannot be decreased. The specific amount of any yearly increase will be determined based on these policies. For the purposes of this Agreement, "Base Salary" refers to the Executive's base salary as periodically established in accordance with Section 2.2.
上述,我们已成功使用Milvus和LLMware为法律文档创建了RAG应用程序。最好的部分是,没有数据发送给外部供应商;包括向量数据库、嵌入模型和LLM在内的一切都在本地。
结论
随着AI的日益普及,与数据交互变得前所未有地容易。然而,许多企业仍然犹豫将数据发送到云端,这是正确的。LLMware提供了一种在本地而不是公共云上构建AI系统的解决方案。这种解决方案确保了数据隐私,降低了成本,并提供了更多的控制权。
使用LLMware和Milvus向量数据库,我们可以结合向量相似性搜索和LLMs的力量,对我们的私有文档提出问题。Milvus是一个强大的开源向量数据库,可以存储、处理和搜索十亿规模的向量数据。一旦Milvus检索了LLM的前K个最相关结果,LLMs将具有回答您查询的上下文。
注:本文为AI翻译,查看原文
 Haziqa Sajid
Haziqa SajidFreelance Technical Writer