



使用 Milvus Lite、Llama3 和 LlamaIndex 搭建 RAG 应用
大语言模型(LLM)已经展示出与人类交互并生成文本响应的卓越能力。这些模型可以执行各种自然语言任务,如翻译、概括、代码生成和信息检索等。
为完成这些任务,LLM 需要基于海量数据进行预训练。在这个过程中,LLM 基于给定的词,预测句子中的下一个词来学习自然语言。这种方法被称为标记预测,帮助 LLM 生成连贯且富含上下文的响应。然而,由于模型更专注于预测最可能的下一个词而非验证事实,因此其输出有时可能不准确或具有误导性。此外,预训练数据集可能已经过时,这使得 LLM 难以回答与最新数据相关的问题。
这种情况下,除非您拥有丰富的专业知识,否则很难评估 LLM 响应的真实性和准确性。检索增强生成(RAG) 可以有效缓解这种情况。本文将深入介绍 RAG。
什么是 RAG
大语言模型(LLM)无疑是人工智能(AI)领域中最炙手可热的话题,因为 LLM 具备解决各种自然语言问题的强大能力。然而,它们也有其局限性——受制于训练数据的更新时间。
例如,GPT-4 Turbo 使用的训练数据最后更新时间为 2023 年 12 月。如果我们询问 ChatGPT 在该日期之后的信息,就有可能收到不准确的响应。这种现象被称为 LLM 幻觉。
幻觉是指 LLM 生成的响应看起来准确,但实际上完全错误。检测 LLM 是否产生幻觉是一大难题,如今仍有许多科研人员对此开展研究。
虽然我们可以通过困惑度(perplexity)等指标来评估生成文本的质量,但这种方法并没有直接解决核心问题:我们如何确保 LLM 生成的响应是正确且符合事实的?这时候我们就需要提到 RAG 的概念了。
RAG 旨在减轻 LLM 幻觉的问题。这个过程很简单:首先,我们向 LLM 提交一个查询。但我们并非直接将该查询提交给 LLM,而是首先识别出可以帮助 LLM 提供更准确答案的相关上下文。
接下来,我们向 LLM 提供两个输入:原始查询和最相关的上下文,这些上下文可以帮助 LLM 做出回答。最后,LLM 基于查询与提供的上下文生成响应。
这样一来,我们可以确保 LLM 不会简单地随机生成响应,而是生成一个富含上下文的相关答案。
RAG 的组件
RAG 主要包含 3 个组件:检索(Retrieval)、增强 (Augmentation)和生成(Generation)。
检索组建
在 RAG 中,检索组件的主要目标是基于给定的用户查询来识别相似的上下文候选项。第一步是用数值来表示输入查询,也就是将输入查询转换为 Embedding 向量。向量的维数取决于您使用的 Embedding模型。市面上有许多开源和免费的 Embedding 模型可供使用,比如 HuggingFace 上的模型或 SentenceTransformers。
这些 Embedding 向量保留了原始文本的语义。两个文本向量的语义越相似,他们的在向量空间的位置越靠近。因此,我们可以通过计算任意两个向量之间的欧式距离(L2)来判断文本相似度。下图的示例展示了部分文本向量在二维向量空间的的位置。
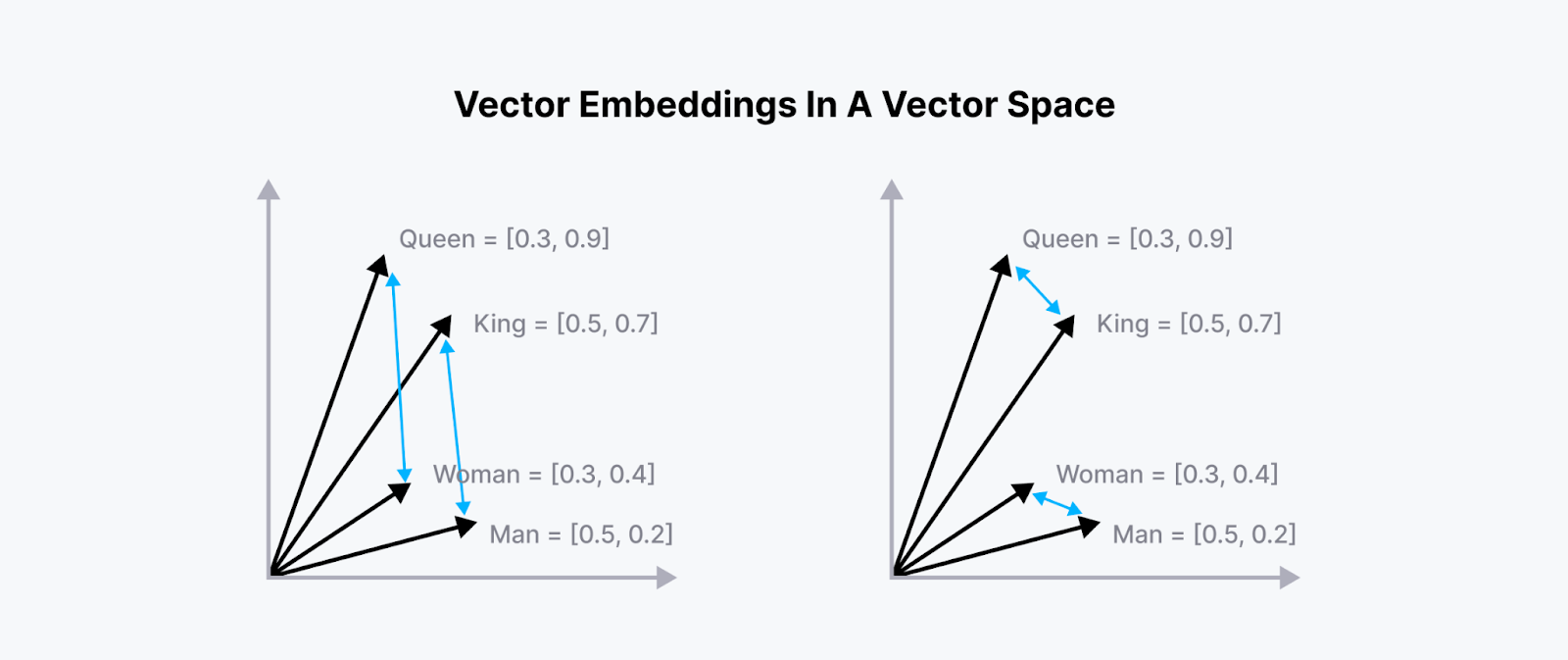 Figure_1_Embeddings_in_2_D_vector_space_6522ce6d91.png
Figure_1_Embeddings_in_2_D_vector_space_6522ce6d91.png
在理解了上述 Embedding 向量的概念后,我们就能更轻松明白如何搜索到相似的上下文。我们需要计算查询向量与数据库中上下文向量之间的距离。
当我们的向量数据比较少时,向量距离的计算量较少且可控。但如果我们拥有数百万个文本向量时,计算成本将变得非常高昂,而且我们的本地机器可能无法存储所有向量。因此,我们需要一个高度可扩展且性能出色的向量数据库(如 Milvus),来高效地处理这一任务。
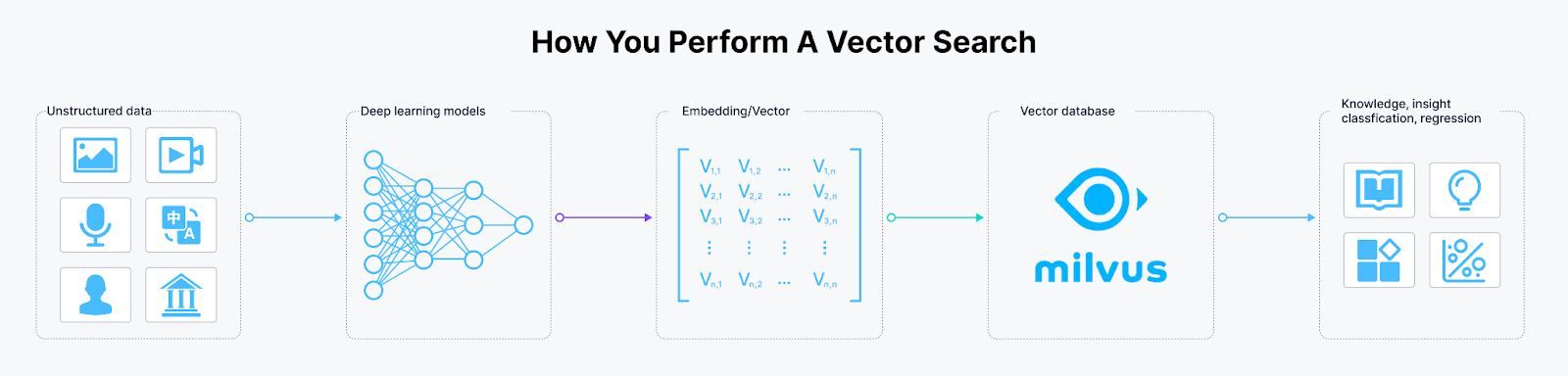 Figure_2_How_to_perform_a_vector_search_f38e8533a2.png
Figure_2_How_to_perform_a_vector_search_f38e8533a2.png
Milvus 提供高级的索引算法,能够高效存储十亿级向量并执行大规模向量相似性计算和搜索。Milvus 还与主流 AI 框架集成,简化了开发 RAG 驱动的 LLM 应用的流程。
增强组件
在使用向量数据库执行向量相似性搜索之后,我们进入了 RAG 应用的增强阶段。将上一步检索到的 top-k 个最相关的上下文与用户查询相结合,形成一个完整的 Prompt 作为 LLM 的输入。
根据您的具体用例,您可以尝试不同的 Prompt。但是,Prompt 的基本模板通常如下所示:
Use the following pieces of context to answer the question at the end.
{context}
Question: {question}
Helpful Answer:
生成组件
RAG 的最后一个组件是生成组件。在这个阶段,我们选择的 LLM(如 GPT、Llama、Mistral、Claude 等 LLM 模型)会根据包含用户查询和最相关上下文的 Prompt 生成响应。
LLM 将基于提供的上下文来生成对用户查询的回答,而不是仅仅依赖其训练数据中的知识。这种方法有助于减轻 LLM 产生幻觉的风险。
下图展示了 RAG 应用的完整组件和工作流程:
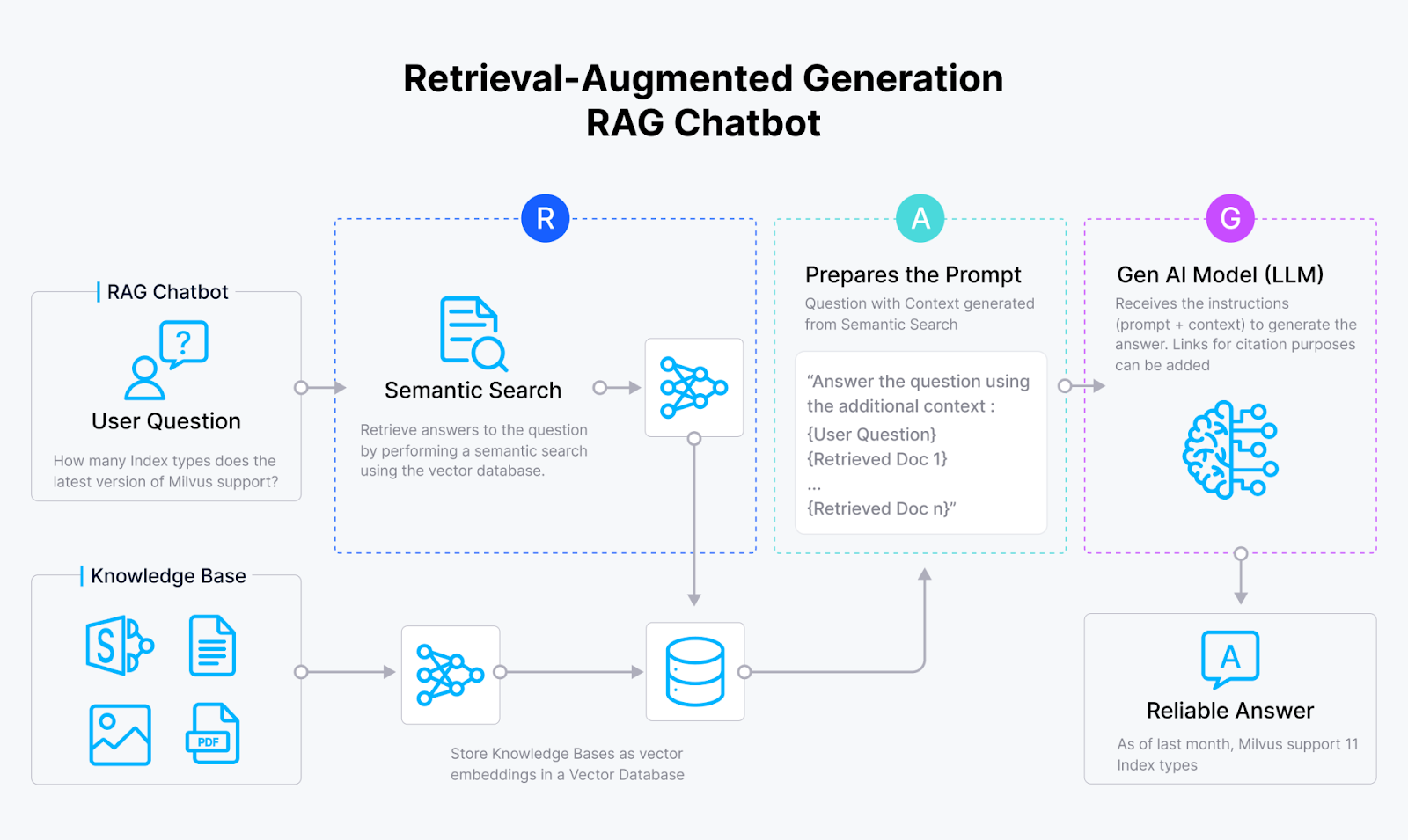 Figure_3_RAG_workflow_d13d98fb43.png
Figure_3_RAG_workflow_d13d98fb43.png
Milvus Lite、Llama 3 与 LlamaIndex 简介
在接下来的部分中,我们将使用 Milvus 和流行的 AI 框架(如 LlamaIndex)构建一个 RAG 驱动的 LLM 应用。让我们简单介绍一下本项目将使用到的工具。
Milvus Lite
Milvus 是一款开源向量数据库,能够存储十亿级向量数据并执行高效的向量搜索。在接下来的 Demo 中,我们将使用 Milvus 来存储上下文向量并计算查询向量与上下文向量间相似度。
Milvus 提供多种安装方式及部署模式。其中最简单的就是安装 Milvus Lite。Milvus Lite 是 Milvus 的轻量级版本,适用于快速开发原型,例如希望尝试不同的文本文档分块(Chunking)策略或 Embedding 模型的场景。
Milvus Lite 的安装方法非常简单。您只需要执行以下 pip 命令:
pip install "pymilvus>=2.4.2"
安装后,您可以立即使用 Python 轻松初始化 Milvus。需要注意的是,如果您想存储多达一百万个向量嵌入,Milvus Lite 支持最多存储 100 万条向量数据。
如果您需要存储更多的向量数据,并用于生产环境,请使用 Docker 或者 Kubernetes 安装、部署和运行 Milvus。详情请阅读安装指南。
Llama3
除了向量数据库以外,RAG 应用的另一个关键组件是 LLM。市面上有多种开源 LLM,其中 Llama 和 Mistral 是较为受欢迎的两种。在本文将使用 Meta 开发的 Llama3 模型作为我们的 LLM。Llama3 模型相比 Llama2 基于 7 倍更大的数据集进行预训练,极大提升了性能。
Llama3 模型有两种不同的大小:80 亿参数和 700 亿参数。如下图性能测试结果所示,Llama 3 两种大小的模型的性能相比同等规模的 LLM 都更具优势。
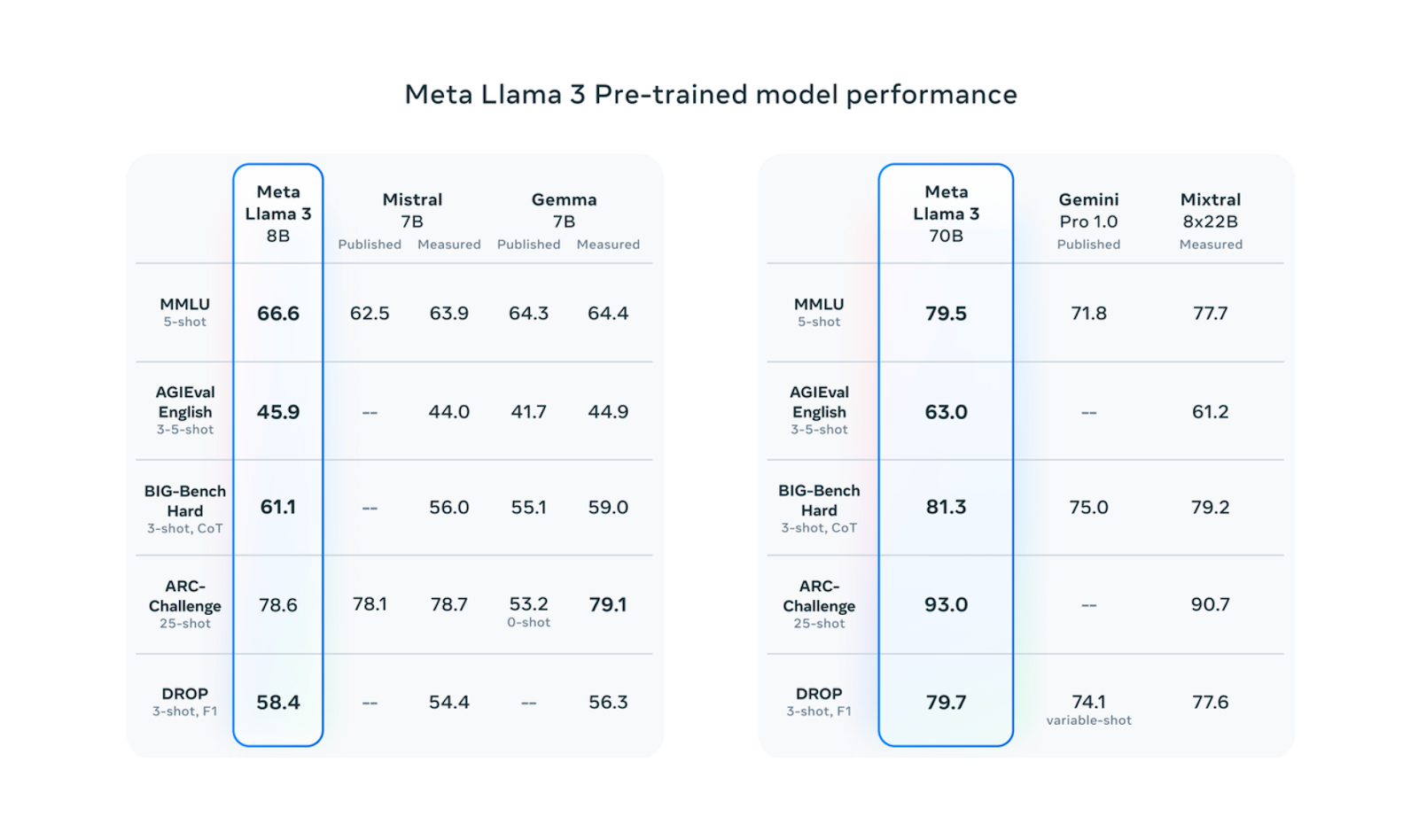 Figure_4_Llama3_performance_on_benchmark_datasets_Source_316a03eea7.png
Figure_4_Llama3_performance_on_benchmark_datasets_Source_316a03eea7.png
本文将使用包含 80 亿参数的 Llama3 模型。默认情况下,该模型需要大约 32 GB 的 VRAM。这超过了免费 GPU 的可用 VRAM 上限。但是,我们可以通过执行 4-bit 量化(quantization)将模型大小缩减到约 4 GB VRAM。
有多种方法可以加载 Llama3 模型并进行 4-bit 量化。第一种方法使用 HuggingFace 和 bitsandbytes 库。第二种方法是安装 Ollama 并直接通过 Ollama 加载模型。Ollama 上的 LLM 已默认进行过 4-bit 量化。
文本将使用 Ollama 轻松地在本地机器上运行各种 LLM。请参考 Ollama 文档获取最新的安装指南。
Ollama 安装完成后,您就可以下载 LLM。本文使用 Llama3,因此,您可以运行以下命令:
ollama run llama3
LlamaIndex
LlamaIndex 是用于协调 RAG Pipeline 的框架。在前文中,我们已经为 RAG 应用安装了向量数据库和 LLM。现在缺少的是将这两个组件连接起来,构建一个功能齐全的 RAG 系统的框架。这正是 LlamaIndex 的作用。
LlamaIndex 易于使用,能够预处理来自各种数据源的输入数据,将其转换为 Embedding 向量并存储在向量数据库中,搜索相关上下文,将搜索结果结合查询发送到 LLM,最终输出 LLM 响应。
如下所示,我们可以使用一个简单的 pip 命令来安装 LlamaIndex。
pip install llama
pip install llama-index-vector-stores-milvus llama-index-llms-ollama llama-index-embeddings-huggingface
使用 Milvus Lite、LLama3 和 LlamaIndex 搭建 RAG 聊天机器人
现在让我们使用 Milvus Lite、Llama3 和 LlamaIndex 搭建一个 RAG 系统吧!本示例将构建一个聊天机器人,用于回答针对《Attention is All You Need》这篇论文的问题。这篇论文主要介绍了 Transformer 架构。您也可以替换本示例中使用的研究论文。
您可以通过 notebook 获取本文中所有代码并跟随以下指南一起操作。
首先,让我们导入所有需要的库:
!pip install arxiv
import arxiv
from llama_index.core import SimpleDirectoryReaderfrom llama_index.vector_stores.milvus import MilvusVectorStorefrom llama_index.core import VectorStoreIndex, Settingsfrom llama_index.llms.ollama import Ollamafrom llama_index.embeddings.huggingface import HuggingFaceEmbeddingfrom pymilvus import MilvusClient
我们可以通过 Arxiv 的官方 Python 库将 PDF 版的研究论文下载到本地机器。
dir_name = "./Documents/pdf_data/"
arxiv_client = arxiv.Client()
paper = next(arxiv.Client().results(arxiv.Search(id_list=["1706.03762"])))
# Download the PDF to a specified directory with a custom filename.
paper.download_pdf(dirpath=dir_name, filename="attention.pdf")
在以上代码中,我们通过其 ID 将论文《Attention is All You Need》下载到本地目录。Arxiv 上的每篇研究论文在 URL 中都有其 ID,您可以直接复制并粘贴其他的论文 ID 到上面的代码中进行替换。
接下来,初始化 Milvus 向量数据库和 Llama3 模型。将原始输入文本转换为向量时,我们将使用可以从 HuggingFace 上的 BGE base 模型。
vector_store = MilvusVectorStore(
uri="./milvus_rag_demo.db", dim=768, overwrite=True
)
embedding_model = HuggingFaceEmbedding(model_name="BAAI/bge-base-en-v1.5")
llm = Ollama(model="llama3",temperature=0.1, request_timeout=480.0)
通过上述代码,我们初始化了 Milvus 向量数据库。Milvus 中可存储的向量维度为 768,与 BGE base 模型生成的 Embedding 向量维度一致。
现在,让我们 Ingest 下载的 PDF 论文。我们只需要调用 LlamaIndex 的 SimpleDirectoryReader 对象即可。
pdf_document = SimpleDirectoryReader(
input_files=[f"{dir_name}attention.pdf"]
).load_data()
print("Number of Input documents:", len(pdf_document))
# OR execute this command if you have multiple PDFs inside the directory
pdf_document = SimpleDirectoryReader(
dir_name, recursive=True
).load_data()
"""
Output:
Number of Input documents: 15
"""
输入文档的数量是 15,这是因为我们使用的论文共有 15 页。
我们需要使用 LlamaIndex 的 Settings class 将 LLM 与 Embedding 模型进行绑定。在 Settings 中,我们还可以自定义 PDF 文档的分块大小(chunk size)和 overlap。
Settings.llm = llm
Settings.embed_model = embedding_model
Settings.chunk_size = 128
Settings.chunk_overlap = 64
然后,将 PDF 文档 Ingest 到 Milvus 向量数据库中。通过以下命令,PDF 文档将被分割成块(Chunk)。使用 BGE base 模型将每个 Chunk 转换为向量。最后,将这些 Chunk 向量存储在 Milvus 向量数据库中。
index = VectorStoreIndex.from_documents(pdf_document)
print("Number of nodes:", len(index.docstore.docs))
query_engine = index.as_query_engine()
"""
Output:
Number of nodes: 196
"""
可以看到,现在向量数据库中共有 196 个 Chunk 的向量。我们还在 index 中调用了as_query_engine 的方法实现对向量数据库中的数据提出问题。
以上就是使用 LlamaIndex 构建一个完整的 RAG Pipeline 的所有步骤。现在我们可以问一个与研究论文相关的问题。例如 “What is the benefit of multi-head attention instead of single-head attention?”。
query = "What is the benefit of multi-head attention instead of single-head attention?"
result = query_engine.query(query)
print(result)
"""
Output:
Multi-head attention allows the model to jointly attend to information from different representation subspaces at different positions. With a single attention head, averaging inhibits this.
"""
基于研究论文中提供的信息,不难看出我们得到了一个高度相关的答案!同样,您可以通过 RAG 应用询问更复杂的问题。
优化 RAG Pipeline
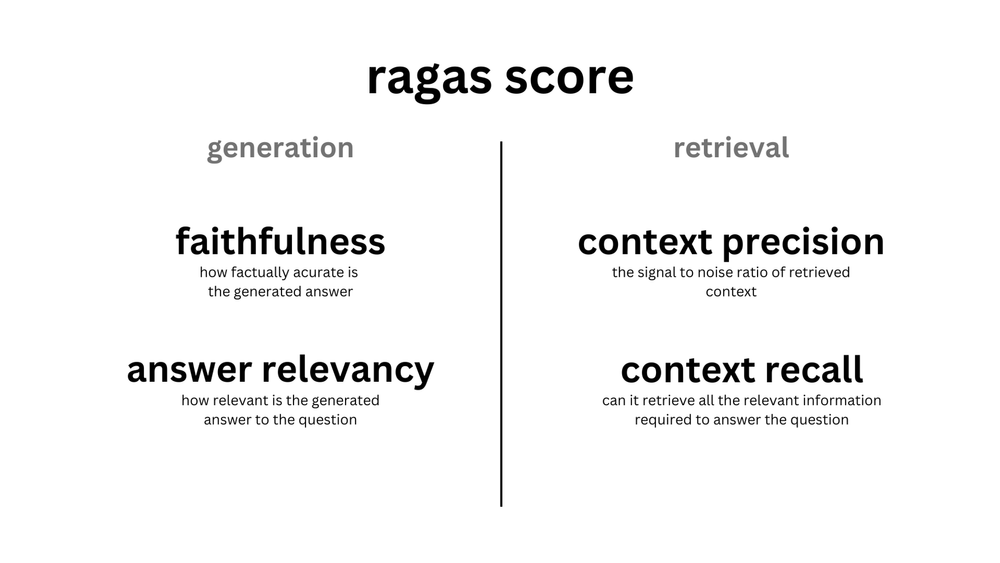
在生产环境中部署 RAG Pipline 比原型开发更具挑战!一个最常见的问题就是如何评估 RAG 系统生成的响应质量。好在市面上有几个开源工具可以用于评估 RAG 系统响应质量,比如 Ragas 和 TruLens-Eval。
如需评估检索组件的质量,Ragas 也提供了测试上下文精确度的方法。Ragas 中有关忠实度(Faithfulness)和答案相关性等指标可用于评估生成组件质量。更多信息,请参考文档。
 Figure_5_Figure_RAG_evaluation_metrics_using_Ragas_3f71b3f768.png
Figure_5_Figure_RAG_evaluation_metrics_using_Ragas_3f71b3f768.png
如果发现 RAG 响应质量有所下滑时,我们可以采取的初步行动就是查看这些评估指标。如果指标结果不佳,我们可以针对性地改进 RAG 应用。当然,最重要的第一步是评估我们的数据质量。
我们需要思考以下几个问题:向量数据库中是否含有正确的上下文数据帮助 LLM 有效用户回答问题?文档的分块大小是否合适?在数据分块前是否需要先清理数据?
在确认数据质量不存在问题后,我们可以尝试替换性能更好的 LLM 和 Embdding 模型,从而提升 RAG Pipeline 的总体质量。
针对 RAG 优化,我们推荐您阅读以下文章:
总结
多亏诸如 Ollama、LlamaIndex 和 HuggingFace 之类的 AI 框架,构建 RAG Pipeline 变得前所未有的简单。Milvus 支持高效存储海量上下文向量数据,与各种 AI 框架无缝集成。因此,我们只需几行代码便可轻松构建一个 RAG 应用。Milvus Lite 帮助我们通过一个简单的 pip 命令快速完成向量数据库的安装和设置,从而轻松开发多个 RAG 应用原型。
本文示例展示了如何快速搭建一个 RAG 应用。欢迎您尝试搭建更多 RAG 应用!
 Ruben Winastwan
Ruben WinastwanFreelance Technical Writer


