



入门指南:什么是目标检测
假设您正在开发一个体育分析系统,需要用到计算机视觉技术。在这个系统中,定位图像或视频中的物体至关重要。在比赛视频中检测和追踪球员可以有效计算特定区域内的球员数量,监控他们在区域间的移动路线,甚至分析他们在关键位置的停留时间。目标检测是一种不仅能识别图像或视频中的物体,而且还能精确定位它们位置的计算机视觉技术。
图像分类是给整个图像分配一个标签。与简单的图像分类不同,目标检测则致力于找到物体并通过边界框标记它们的位置。这种定制化的目标检测模型是许多 AI 应用的重要组成部分,如面部识别、安全监控和医学成像。
本文将帮助你了解目标检测的工作原理、主流的目标检测模型和算法、目标检测面临的挑战以及这项技术的未来趋势。
什么是目标检测?
目标检测是一种计算机视觉技术,利用神经网络对图像或视频中的物体(如人、建筑或汽车)进行分类和定位。目标检测模型以图像作为输入,然后输出所检测物体的边界框坐标,以及识别这些物体的标签。一幅图像可能包含多个物体,每个物体都有自己的边界框和标签,例如一辆车和一座建筑。这些物体也可以位于图像的不同区域,例如几辆车在不同的位置。这种概念通常被称为多物体检测。
为了方便您更好地理解目标检测,我们将其与类似任务进行比较:
图像分类(Image Classification):此任务仅确定图像中是否存在某个物体。例如,图像中有狗吗?
目标检测(Object Detection):用于确定物体的类别并使用边界框在图像中定位该物体。例如,图像中的狗在哪里,它是什么类型的狗?
图像分割(Image Segmentation):图像分割提供像素级的准确性。它不仅像目标检测那样在物体周围画一个框,而且还通过将每个像素分配给特定的物体类别来定义精确的形状。例如,哪些像素属于狗,狗的确切形状是什么?
 Image_Classification_vs_Object_Detection_vs_Image_Segmentation_8895f60b6c.png
Image_Classification_vs_Object_Detection_vs_Image_Segmentation_8895f60b6c.png
图像分类 vs. 目标检测 vs. 图像分割 | 来源
目标检测工作原理
目标检测系统有几个关键组件协同工作以对物体进行分类和定位。
特征提取(Feature Extraction)
边界框(Bounding boxes)
物体分类和定位(Object Classification and Localization)
特征提取
目标检测的第一步是从图像中提取重要特征。目标检测器中的特征能帮助定义物体的特性,如边缘、角点或纹理。卷积神经网络(CNN)通常被用作现代 ML 中的特征提取器。它们通过在卷积层中对图像应用滤波器自动学习并提取特征。然而,CNN 并不是唯一用于此目的的算法。其他算法包括 RPN(Region Proposal Networks)、HOG(Histogram of Oriented Gradients)和 SIFT(Scale-Invariant Feature Transform)。
当输入图像被传入 CNN 时,会通过多个卷积层。在前面的层中,神经网络识别图像中的基本特征,如边缘和角点。随着图像通过更深层的卷积层,神经网络学习更复杂的特征,如物体的组成部分。这种层次化的过程帮助网络理解不同物体的基本特征,从而更有效地检测物体。
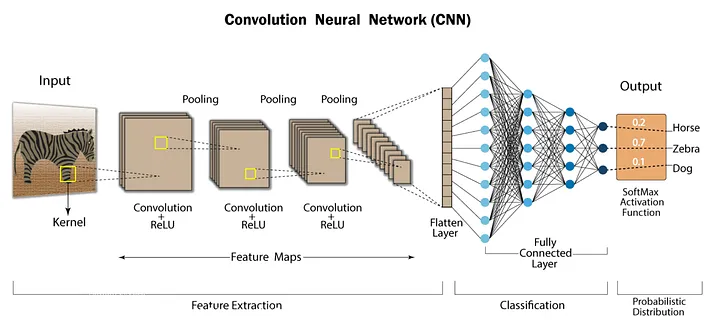 Convolutional_neural_network_CNN_architecture_8ebc6fd544.png
Convolutional_neural_network_CNN_architecture_8ebc6fd544.png
CNN 架构 | 来源
边界框
边界框是围绕检测到的物体绘制的矩形。它由四个值定义:
𝑥、𝑦、宽度 𝑤 和高度 ℎ。根据模型的不同,坐标 (𝑥, 𝑦) 可以表示框的中心(在像 YOLO 这样的模型中)或者左上角(在像 Faster R-CNN 这样的模型中),而 𝑤 和 ℎ 决定了框的尺寸。在深度学习模型中,通过回归(regression)过程调整边界框坐标。回归过程是一个神经网络细化预测坐标以更好地适应物体的过程。模型预测一个偏移量 (Δ𝑥, Δ𝑦, Δ𝑤, Δℎ) 来调整边界框的位置和大小。
为了评估预测的边界框与真实情况的匹配程度,使用了一个称为交并比(Intersection over Union,IOU)的指标,用于测量预测和实际边界框之间的重叠部分。在数学上,它定义为:
IoU=AIntersectionAUnion
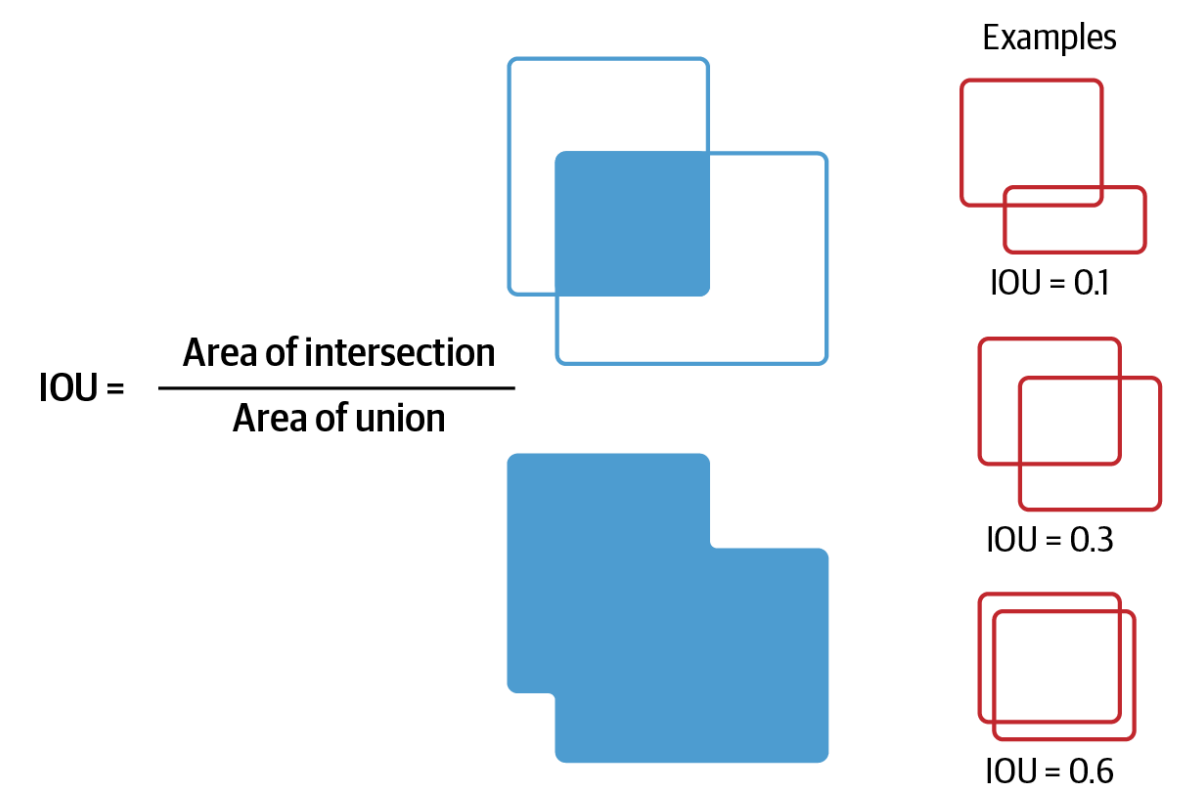 The_IOU_metric_8ad2d2b188.png
The_IOU_metric_8ad2d2b188.png
IOU 指标 | 来源
IoU 值更高,预测与实际物体更匹配。
分类
一旦物体被定位,目标检测系统会为每个检测到的物体分配一个标签,比如“汽车”或“人”。分类过程通常使用卷积神经网络(CNNs)中的全连接层来执行,它们将提取的特征作为输入,并输出类别概率。
尽管深度学习现在是主流的方法,但传统的目标检测方法仍然存在。这些方法通常使用手工设计的特征和算法,如哈里斯角点检测(Harris corner detector)、SIFT(scale-invariant feature transform)、SURF(speeded-up robust features)和 HOG(Histogram of oriented gradients)。
让我们比较这些传统的目标检测方法,了解它们与现代深度学习的方法有何不同。
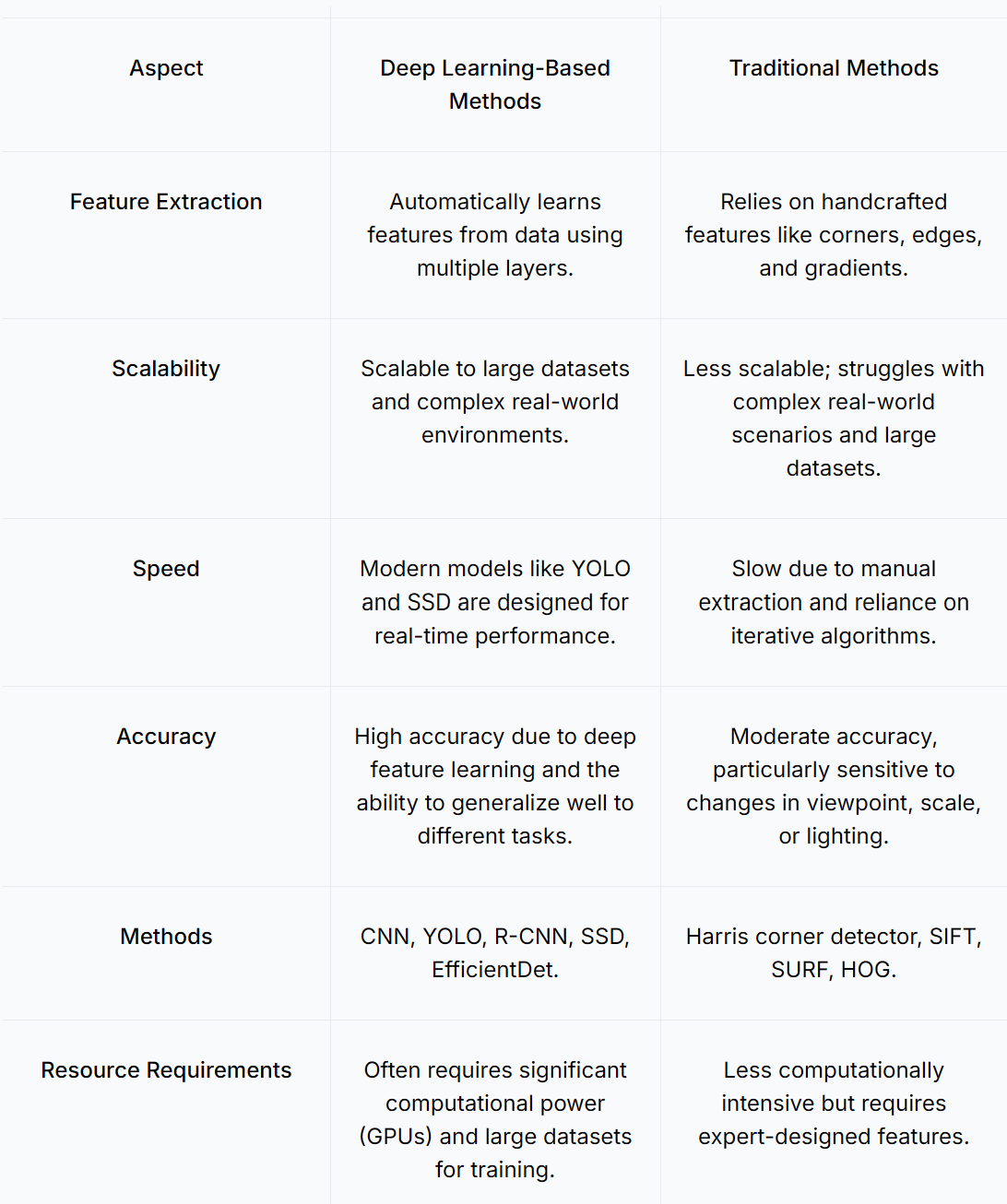 屏幕截图 2024-11-15 101323.png
屏幕截图 2024-11-15 101323.png
主流目标检测模型
在深度学习目标检测领域,有几个有影响力的模型,每个模型都有其独特的优势。以下是一些流行的深度学习异常检测模型:
YOLO
R-CNN
SSD
EfficientDet
YOLO
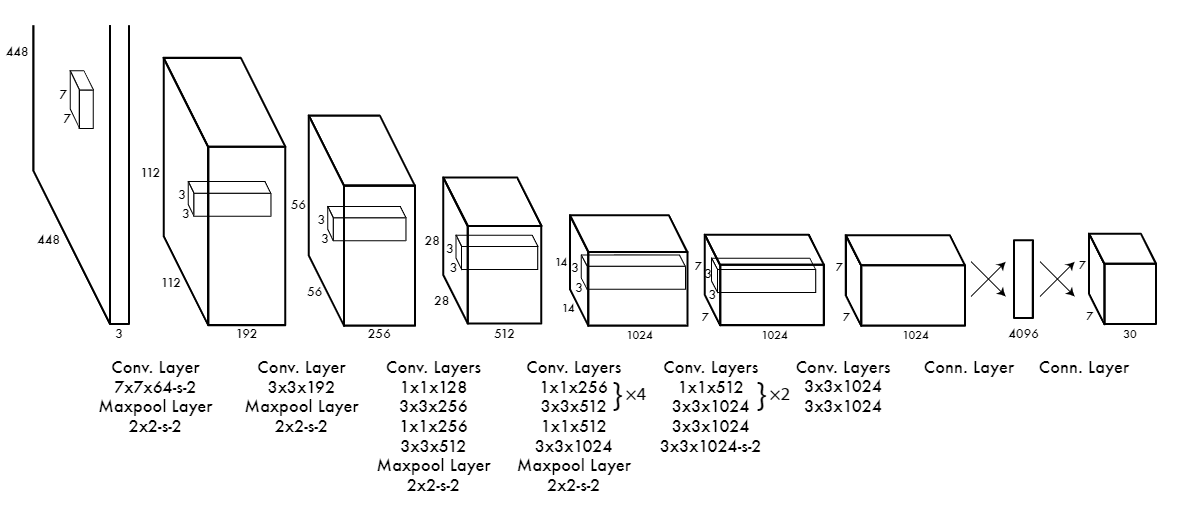 YOLO_Architecture_2214a30cb0.png
YOLO_Architecture_2214a30cb0.png
YOLO 架构 | 来源
YOLO(You Only Look Once)是一种简单而高效的目标检测架构。在检测用时方面,它是最快的模型。因此,被用于许多实时系统,如安全摄像头。与其他采取两步法深度学习目标检测模型(首先提出区域,然后分类物体)不同,YOLO 一次性完成所有操作。它将输入图像划分为网格,并同时为每个网格单元预测边界框和物体类别。这种基于网格的结构使 YOLO 能够在一次网络遍历中快速做出预测,显著减少了处理时间。
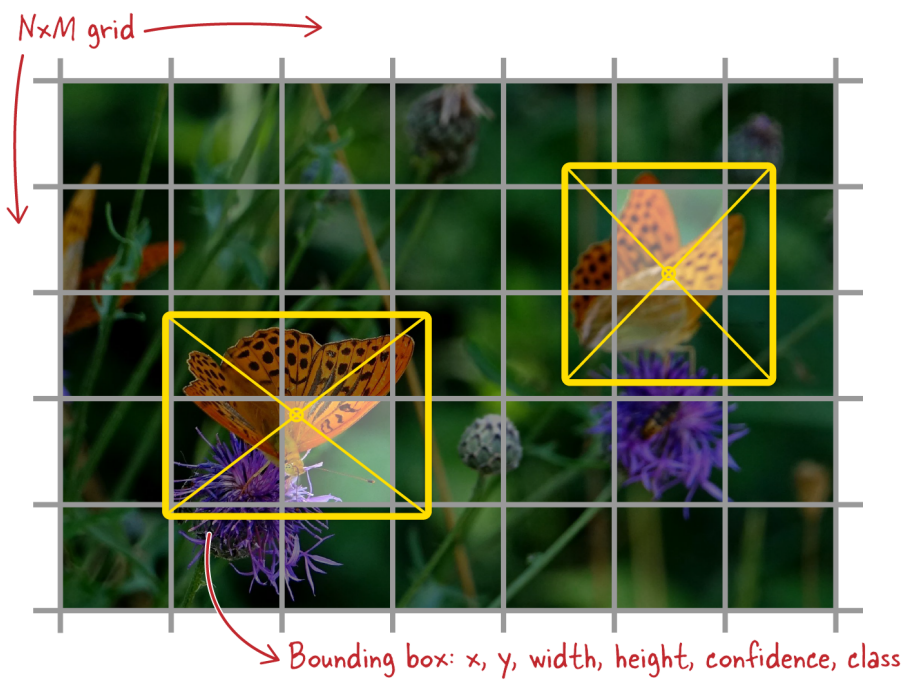 The_YOLO_grid_83d6a30933.png
The_YOLO_grid_83d6a30933.png
YOLO 网格 | 来源
x, y:边界框中心相对于网格单元的坐标。
w, h:边界框的宽度和高度被缩放到整个图像。
Confidence:边界框包含物体的概率。
Class:物体所属的类别。
然而,尽管 YOLO 在速度上表现出色,它可能会牺牲一些准确性,特别是在检测较小物体时。这是因为 YOLO 将输入图像划分为网格,每个网格单元只能预测一个物体。当小物体落在单个网格单元内或跨越多个网格单元的边界时,YOLO 可能难以精确定位或将其与周围物体区分开来。因此,较小的物体可能会被遗漏或错误分类。
R-CNN
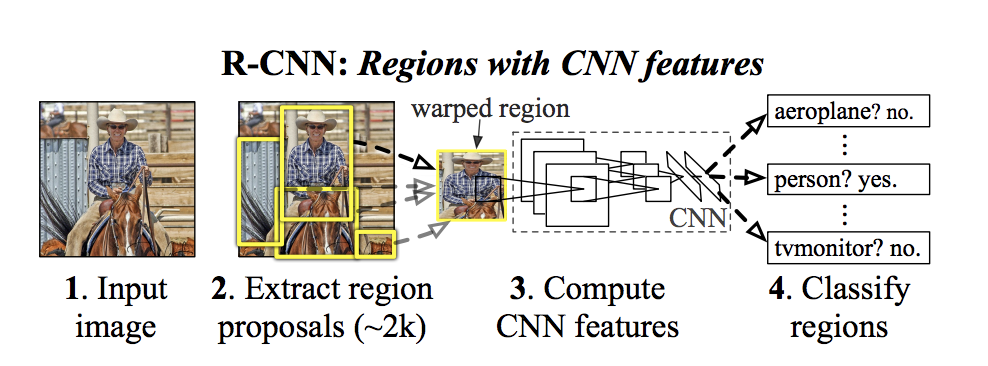 The_R_CNN_Architecture_a7b0dceed8.png
The_R_CNN_Architecture_a7b0dceed8.png
R-CNN 架构 | 来源
R-CNN(区域与卷积神经网络)模型,包括 Fast R-CNN 和 Faster R-CNN,在改进目标检测技术方面扮演了重要角色。原始的 R-CNN 通过首先找到图像中可能包含物体的区域来运行。然后,它使用 CNN 从这些区域提取和分类特征,并利用 SVM 技术。Fast R-CNN 通过允许模型对所有区域重用相同的计算,并添加了同时处理多个任务的方法,使这一过程更快。
最后,Faster R-CNN 通过引入区域提议网络(Region Proposal Network,RPN),使识别过程更快速。
SSD (Single Shot Multibox Detector)
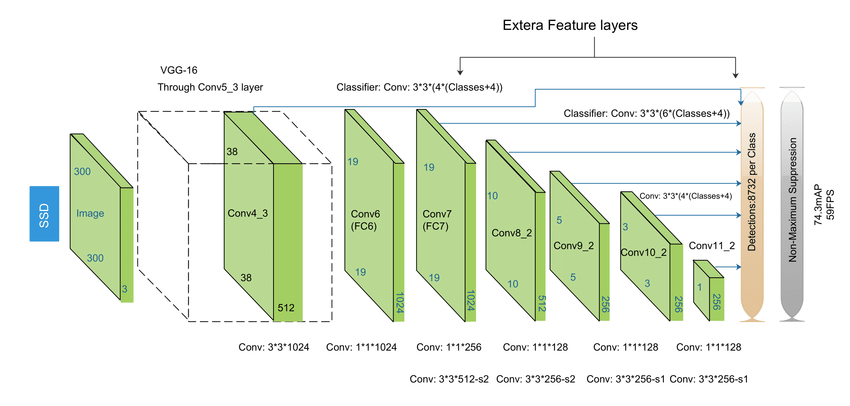 Single_Shot_Multi_Box_Detector_SSD_architecture_402896c18b.png
Single_Shot_Multi_Box_Detector_SSD_architecture_402896c18b.png
SSD 架构 | 来源
像 YOLO 一样,单次检测多框检测器(Single Shot Multibox Detector,SSD)在单次 pass 中处理图像,但它采用了更精细的方法,使用不同尺寸的多个特征图。这使得 SSD 能够检测各种大小的物体,特别是较小的物体。虽然 SSD 比 Faster R-CNN 更快,但它通常比 YOLO 提供更高的准确度,保持了速度和精度之间的良好平衡。
这种平衡使得 SSD 适用于追求效率和检测可靠性的应用。
EfficientDet
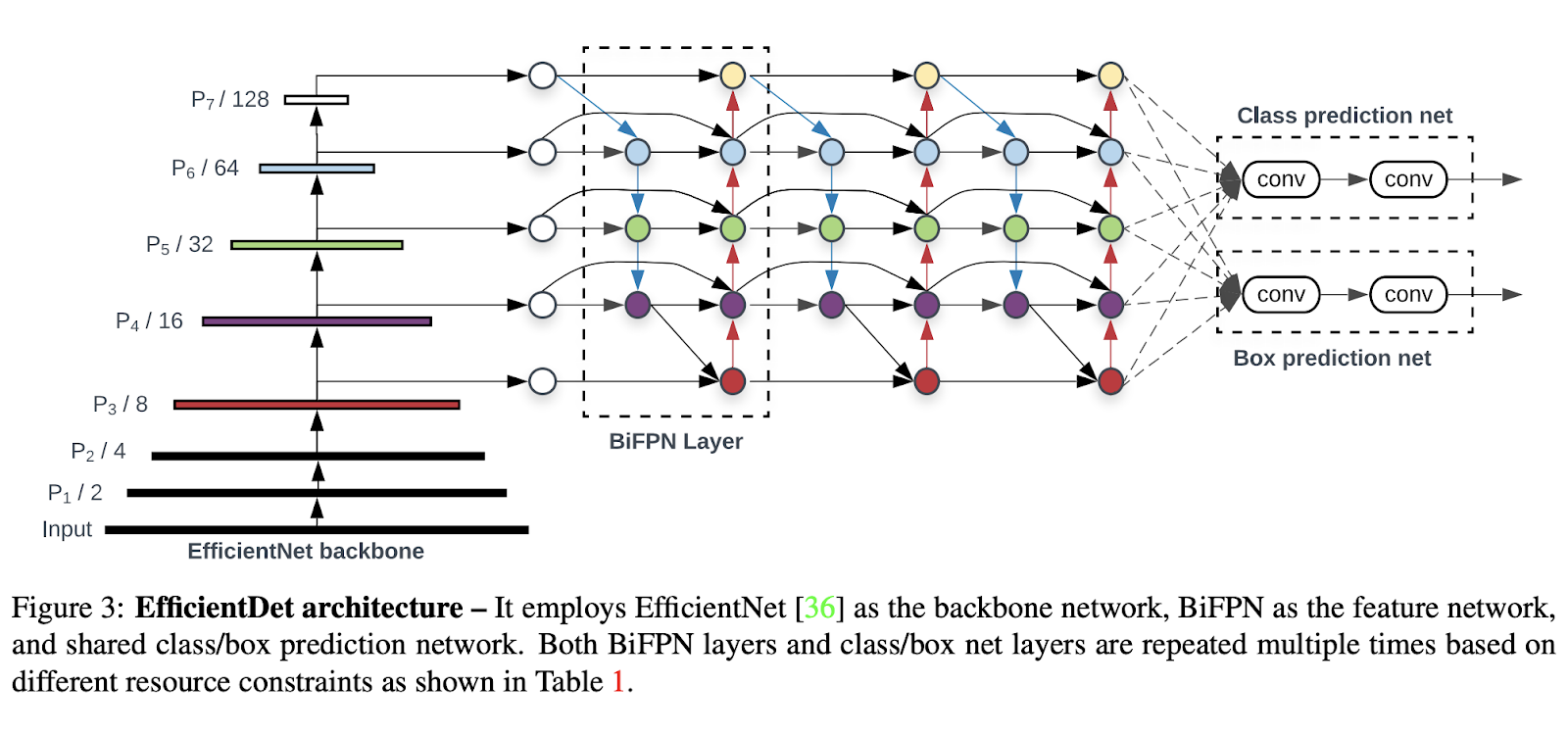 Efficient_Det_architecture_1464b06dff.png
Efficient_Det_architecture_1464b06dff.png
EfficientDet 架构 | 来源
EfficientDet 设计时考虑了效率,旨在以较少计算资源实现高准确度。它使用了双向特征金字塔网络(Bidirectional Feature Pyramid Network,BiFPN),有助于提高模型在不同尺寸上检测物体的能力。此外,EfficientDet 使用复合缩放方法,同时调整网络的深度、宽度和分辨率。
这意味着它以平衡的方式扩展特征提取、分类和边界框预测网络,确保在不过分要求计算能力的情况下实现高性能。
目标检测的应用
目标检测是一项关键技术,帮助机器解释和理解视觉数据。它对于提高各个行业的自动化、安全性和效率至关重要。以下是目标识别和检测在现实世界中的一些重要应用场景:
自动驾驶:自动驾驶汽车系统高度依赖目标检测来识别车辆周围环境中的不同物体。这包括检测行人、其他汽车、骑自行车的人和交通标志。实时检测对于这些车辆的安全运行十分重要,因为它有助于汽车在没有人为干预的情况下穿越复杂环境。
医疗保健:在医疗保健领域,目标检测应用于医学成像,以协助医生和放射科医生在各种类型的扫描(如 X 光、CT 扫描和 MRI)中识别异常,如肿瘤、骨折或其他状况。这项技术有助于提高诊断的速度和准确性,在癌症或内伤等危及生命的病症中至关重要。
监控和安全:在安全和监控领域,目标检测用于不同目的,如面部识别、可疑活动检测和识别限制区域内未经授权的访问。例如,配备目标检测算法的摄像头可以自动识别和跟踪个人或检测公共场所中被遗弃的物体,触发潜在安全威胁的警报。
零售和电子商务:现代商店使用目标检测来跟踪库存并在零售和电子商务领域实现自动化结账流程。亚马逊 Go 商店就是一个典型的例子,顾客可以拿起产品并离开,无需排队等待结账。系统使用摄像头和目标检测算法自动跟踪顾客拿起了哪些商品,并将总额直接计入他们的账户。
目标检测的挑战
目标检测技术虽然在不同应用中具有许多优势,但也面临一些技术挑战:
实时性能: 目标检测的一个主要挑战是在速度和准确性之间取得平衡,特别是在实时应用中。实时系统,如自动驾驶或监控摄像头,需要在几毫秒内做出决策。在一些关键场景(如自动驾驶汽车检测行人)中,检测的轻微延迟可能导致严重的后果。
遮挡(occlusion):当一个物体在图像中部分或完全遮挡另一个物体时会对目标检测模型构成了重大挑战。因为这些模型依赖于物体的完全可见性来正确识别它们。
尺寸变化:图像中的物体可能以截然不同的大小出现,这对检测模型构成了挑战。一个物体在一张图像中可能看起来很小,在另一张图像中看起来很大,这取决于它与相机的距离或实际大小。模型必须以出色的性能处理这些变化,并在准确检测不同尺寸的物体。
恶劣光照条件:尤其是在户外,光线不足或不一致的光照条件会显著影响目标检测模型的准确性。
未来趋势和突破
技术进步和各行业对应用的需求增长而不断推动目标检测技术的变革。以下是一些未来趋势:
边缘计算(Edge Computing):许多设备,如无人机和智能手机,通过人工智能直接在设备上执行目标检测等任务。这减少了将数据发送到云端服务器进行处理的需求。例如,配备人工智能相机的现代智能手机,如谷歌 Pixel,使用边缘计算进行实时目标检测。
3D目标检测:随着机器人技术、增强现实(AR)和虚拟现实(VR)等领域的进步,对三维空间中目标检测的需求变得越来越重要。3D 目标检测超越了传统的 2D 检测,支持更准确的空间建模。例如,特斯拉和 Waymo 等公司开发的自动驾驶车辆使用 3D 目标检测来识别行人、其他车辆和环境中的障碍物。
混合模型:将目标检测与其他人工智能领域如追踪和推理相结合,实现更高级的应用——比如理解复杂场景或预测目标行为。举个例子,在监控系统中,混合模型不仅能检测目标(人或车辆),还能跟踪它们的运动轨迹并预测行为。
总结
目标检测技术是一种变革性的技术,使计算机能够准确感知和解释视觉世界。从自动驾驶汽车到用语检测异常的医学成像系统,这种技术的应用范围十分广泛且仍在持续扩大。
我们探讨了目标检测模型的基本原理及其关键组成部分,例如特征提取、边界框和分类。我们还考察了目标检测模型的演变,从传统方法到当今主流的基于深度学习的架构。
虽然挑战依然存在(例如在复杂环境中实时处理遮挡和尺寸变化),但目标检测的未来是光明的。边缘计算、3D目标检测和混合模型的突破将进一步增强目标检测技术的能力并释放无限的新可能。
相关资源
 Haziqa Sajid
Haziqa SajidFreelance Technical Writer


