



RAG 修炼手册|如何评估 RAG 应用?

如果你是一名用户,拥有两个不同的 RAG 应用,如何评判哪个更好?对于开发者而言,如何定量迭代提升你的 RAG 应用的性能?
显然,无论对于用户还是开发者而言,准确评估 RAG 应用的性能都十分重要。然而,简单的几个例子对比并不能全面衡量 RAG 应用的回答质量,需要采用可信、可复现的指标来量化评估 RAG 应用。
本文将从黑盒和白盒两个角度来讨论如何定量地评估一个 RAG 应用。
01.黑盒方法 V.S. 白盒方法
我们把评估 RAG 应用类比为测试一个软件系统,可以从两个途径来评估 RAG 系统的好坏,一个是黑盒方法,一个是白盒方法。
当以黑盒方式来评估 RAG 应用时,我们看不到 RAG 应用的内部,只能从输入给 RAG 应用的信息和它返回的信息来评估 RAG 的效果。对于一般的 RAG 系统,我们只能访问这三个信息:用户提问(User's query)、RAG 系统召回的引用上下文(retrieved contexts)、RAG 系统的回答(RAG's response)。我们使用这三个信息来评估 RAG 应用的效果,黑盒方式是一种端到端的评估方式,也比较适用于评估闭源的 RAG 应用。
当以白盒方式来评估 RAG 应用时,我们能看到 RAG 应用的内部所有流程。因此内部的一些关键组件就可以决定这个 RAG 应用表现的好坏。以常见的 RAG 应用流程为例,一些关键的组件包括 embedding model、rerank model 和LLM。有的 RAG 具备多路召回能力,可能还会有 基于词频的搜索方法(term frequency search) 算法,更换和升级这些关键组件也能为 RAG 应用带来更好的效果。白盒方式可以用来评估开源 RAG 应用,或者提升自研 RAG 应用。
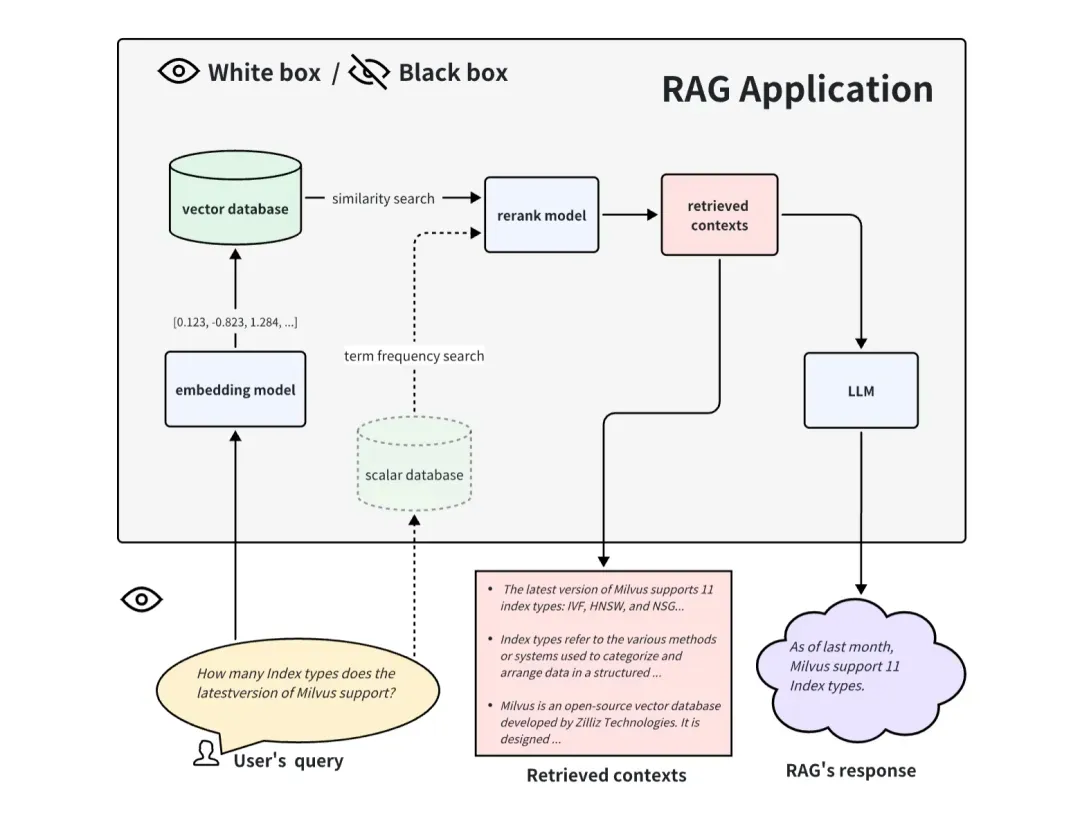
02.黑盒的端到端评估方法
黑盒条件下评估指标
在 RAG 应用是一个黑盒的情况下,我们只能访问这三个信息:用户提问(User's query)、RAG 系统召回的引用上下文(retrieved contexts)、RAG 系统的回答(RAG's response)。它们是 RAG 整个过程中最重要的三元组,两两相互牵制。我们可以通过检测这三元组之间两两元素的相关度,来评估一个 RAG 应用的效果。
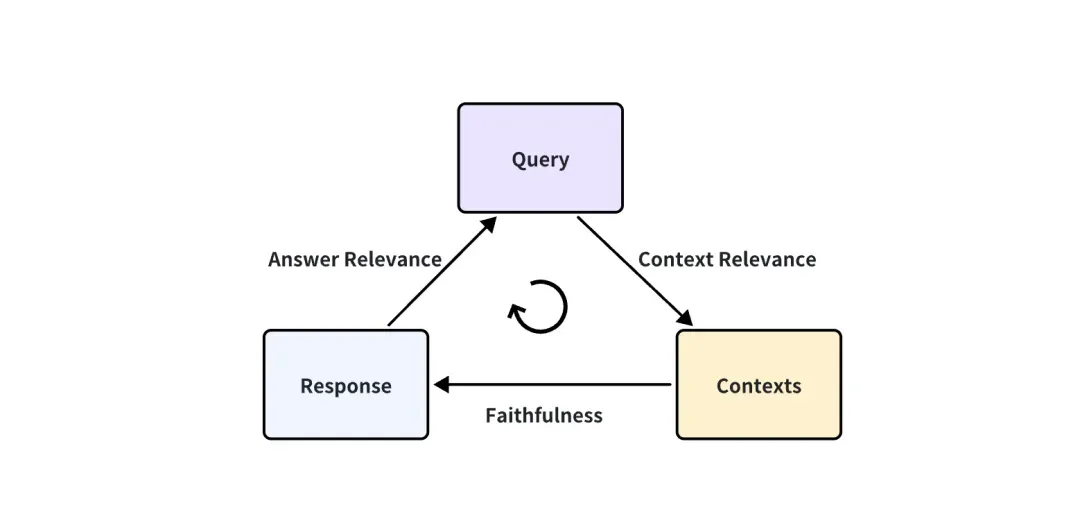
提出下面这三个对应的指标得分:
- Context Relevance: 衡量召回的 Context 能够支持 Query 的程度。如果该得分低,反应出了召回了太多与 Query 问题无关的内容,这些错误的召回知识会对 LLM 的最终回答造成一定影响。
- Faithfulness: 这个指标衡量了生成的答案在给定的上下文中的事实一致性。它是根据答案和检索到的上下文计算出来的如果该得分低,反应出了 LLM 的回答不遵从召回的知识,那么回答出现幻觉的可能就越大。
- Answer Relevance: 侧重于评估生成的答案与给定查询提示的相关性。对于不完整或包含冗余信息的答案,会分配较低的分数。
拿 Answer Relevance 举个例子:
Question: Where is France and what is it’s capital?
Low relevance answer: France is in western Europe.
High relevance answer: France is in western Europe and Paris is its capital.
如何定量计算这些指标?
对于“Where is France and what is it’s capital?”这个问题,一个低相关性的答案是 "France is in western Europe." 这是通过人类的先验知识分析得出的结论,能否有办法定量地打分,这个回答是 0.2 分,另一个回答是 0.4 分?并且客观上要保证 0.4 分的效果确实比 0.2 分得好。
另外,如果每个回答都需要人类来打分,那就要安排大量的劳动力,制定一定的指导标准,让他们来学习这个准则并遵守它来打分。这种方法耗时耗费,显然不太现实,能否有办法自动化地来打分?
好在,现在先进的 LLM 比如 GPT-4,已经可以达到一个类似人类标注员的水平。它可以同时满足我们上面说的两个需求,一是能定量客观公正地进行打分,二是可以实现自动化。
在这篇论文 LLM-as-a-Judge(https://arxiv.org/abs/2306.05685)里,作者提出了 LLM as a judge 的可能性,并在此基础上进行了大量的实验。结果显示,强大的 LLM judge(如 GPT-4)能够很好地匹配控制和众包人类偏好,达到了 80% 以上的一致性,与人类之间的一致性水平相同。因此,LLM 作为 judge 是一种可扩展且可解释的方法,可以近似获取人类偏好,否则让人类打分将会非常昂贵。
你可能会觉得 LLM 和人类打分者得到 80% 的一致并不是表明 LLM 和人类十分一致。但要知道,任何两个不同的人,在受过指导的情况下,对这类主观问题进行打分,也不一定能达到 100% 的一致。因此,GPT-4 与人类达到 80% 一致说明了 GPT-4 完全可以成为一名合格的 judge。
关于具体 GPT-4 是怎么打分的,我们还是拿 Answer Relevance 举个例子,我们使用下面这个 prompt 向 GPT-4 提问:
There is an existing knowledge base chatbot application. I asked it a question and got a reply. Do you think this reply is a good answer to the question? Please rate this reply. The score is an integer between 0 and 10. 0 means that the reply cannot answer the question at all, and 10 means that the reply can answer the question perfectly.
Question: Where is France and what is it’s capital?
Reply: France is in western Europe and Paris is its capital.
GPT-4 的回复:
10
可以看到,只要预先设计好一个合适的 prompt,比如上例这个 prompt,只要把 Qustion 和 Reply 替换掉,就可以自动化地评测所有 Q-A 对。因此,怎么设计 prompt 也很重要,上例这个 prompt 只是一个样例,实际的 prompt 为了让 GPT 打分更加公正和鲁棒,往往是一个很长的内容。这就要用到一些高级的 prompt 工程技巧,比如 multi-shot, 或 CoT(Chain-of-Thought)思维链技巧。在设计这些 prompt 时,有时还要考虑 LLM 的一些偏见,比如 LLM 常见的位置偏见:当 prompt 比较长时,LLM 容易注意到 prompt 里前面的一些内容,而忽略一些中间位置的内容。
好在关于 prompt 的设计我们不用去太关心,这些 RAG 应用的评估工具都已经设计集成好了。社区和时间可以帮助检验它们设计的 prompt 的好坏。我们更需要关心的其实是,大量访问 GPT-4 这种 LLM,需要消耗太多 API key。未来期待有更便宜的 LLM 或本地 LLM,能达到当好一个 judge 的水平。
需要标注 ground-truth 吗?
大家可能已经注意到了,上面的例子里并没有用到 ground-truth,它是人类写好的可以回答对应提问的标准回答。比如可以定义 Ground-truth 和 Response 之间的一种指标,叫作 Answer Correctness,它是用来衡量 RAG 回答的正确性的。打分原理和上文 Answer Relevance 使用 LLM 打分的方式是一样的。
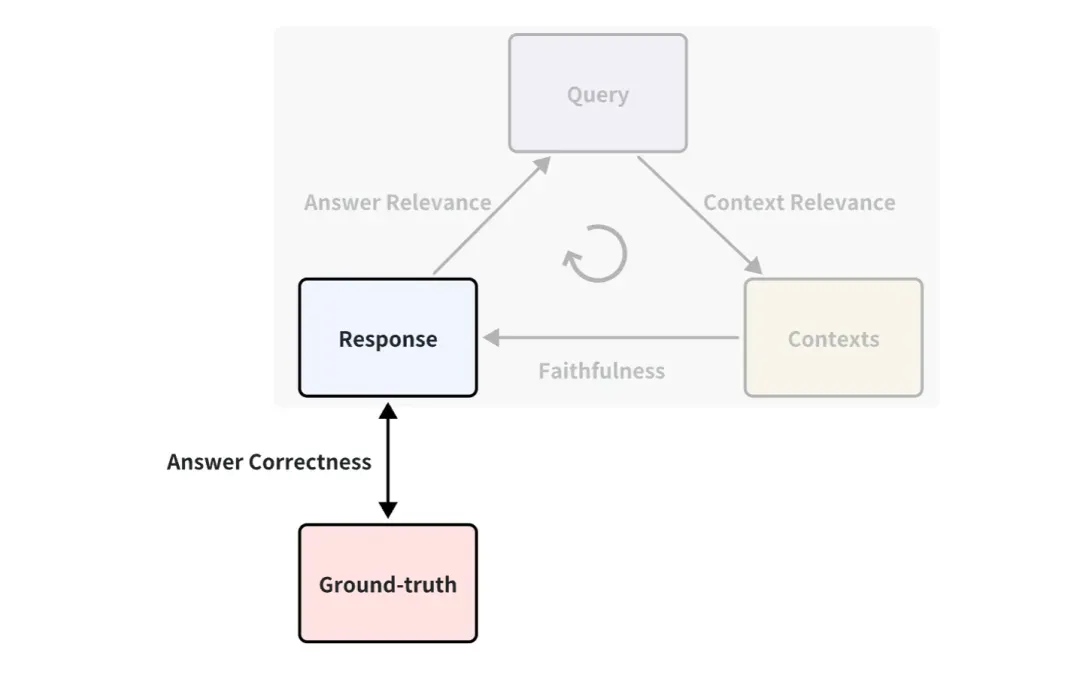
因此,如果有 ground-truth,评估指标就更加丰富,即可以从更多角度来衡量 RAG 应用的效果。但在大多数情况下,获得标准好 ground-truth 的数据集是很昂贵的,可能需要花大量的人力和时间来进行标注。有什么办法可以实现快速标注吗?
既然 LLM 可以生成一切,那让 LLM 来根据知识文档,来生成 query 和 ground-truth 是可行的。比如在 ragas 的 Synthetic Test Data generation 和 llama-index 的 QuestionGeneration 中都有一些集成好的方法,可以直接方便地使用。
我们来看 ragas 中根据知识文档生成的效果:

根据知识文档生成的 questions 和 answers(https://docs.ragas.io/en/latest/concepts/testset_generation.html)
可以看到,上图生成了许多 query questions 和对应的 answers,包含对应的 context 出处。为保证生成问题的多样性,还可以选择各种各样的question_type生成的比例,比如 simple question 和 reasoning question 的占比。
这样,我们就可以方便地直接用这些生成的 question 和 ground-truth,去定量评估一个 RAG 应用,再也不需要去网上找各种各样的 baseline 数据集,这样也可以评估企业内部私有的或自定义的数据集。
03.白盒的评估方法
白盒条件下 RAG pipeline
在白盒视角下看 RAG 应用,我们可以看到 RAG 内部的实现 pipeline。以常见的 RAG 应用流程为例,一些关键的组件包括 embedding model、rerank model 和 LLM。有的 RAG 有多路召回能力,可能还会有 term frequency search 算法。很显然,测试这些关键组件也能体现出这个 RAG pipeline 在某一步的能力上的效果,更换和升级这些关键组件也能为 RAG 应用带来更好的性能。
下面我们分别介绍如何评估这 3 个典型的关键组件:
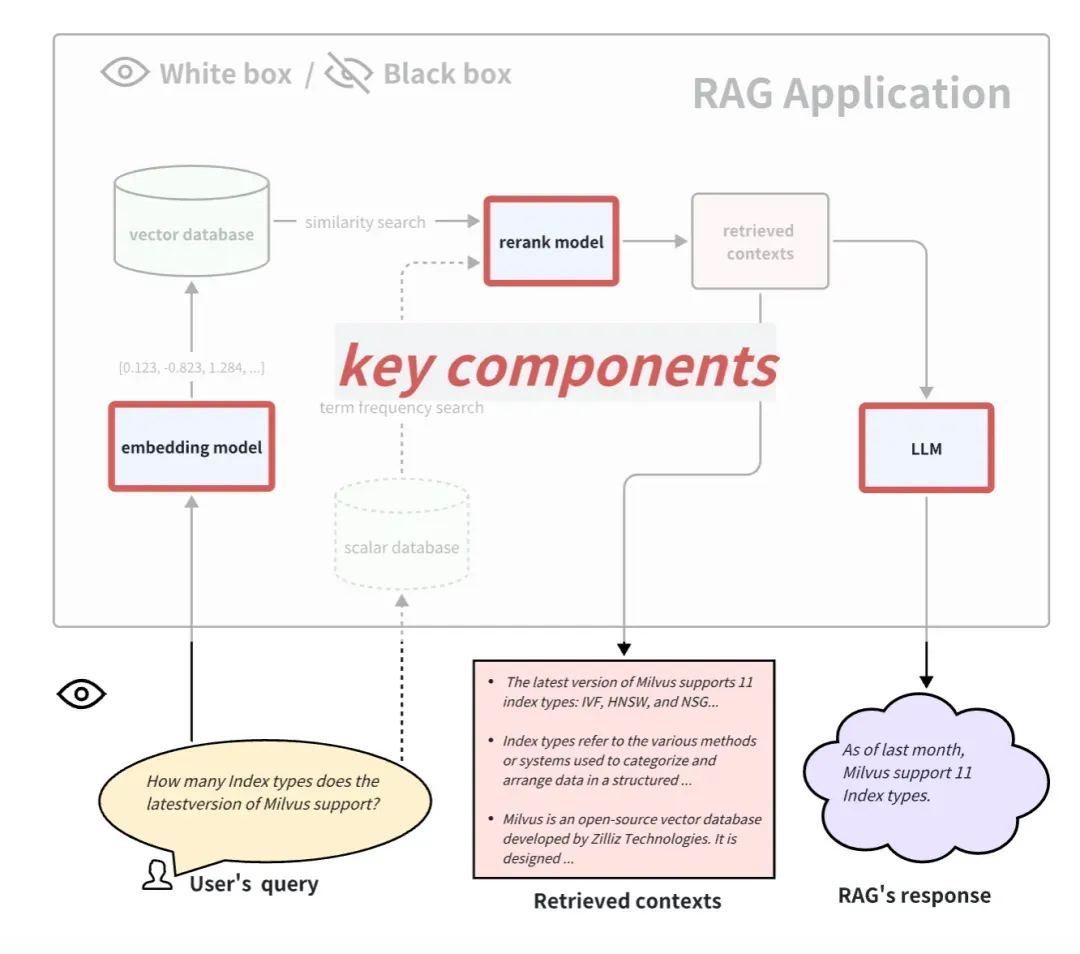
怎么评估 embedding model 和 rerank model
Embedding model 和 rerank model 一同完成相关文档的检索功能。上文中,介绍了 Context Relevance 这一指标,这一指标可以用来评估召回的文档的相关性。但一般对于有 Ground-truth 的数据集,人们更常用信息检索召回领域里的一些确定性的指标来衡量召回的效果。相比于 LLM-based 的 Context Relevance 指标,这些指标计算更快、更便宜、也更加确定性(但需要提供 ground-truth contexts)。
信息检索常用的指标
在信息检索召回领域,常用的指标包括考虑排名的指标和不考虑排名的指标。
考虑排名的指标对于召回的 ground-truth 文档的在所有召回文档中的排名是敏感的,也就是说,改变召回的所有文档之间的相关顺序,会使得这个指标得分发生变化,而不考虑排名的指标则与之相反。
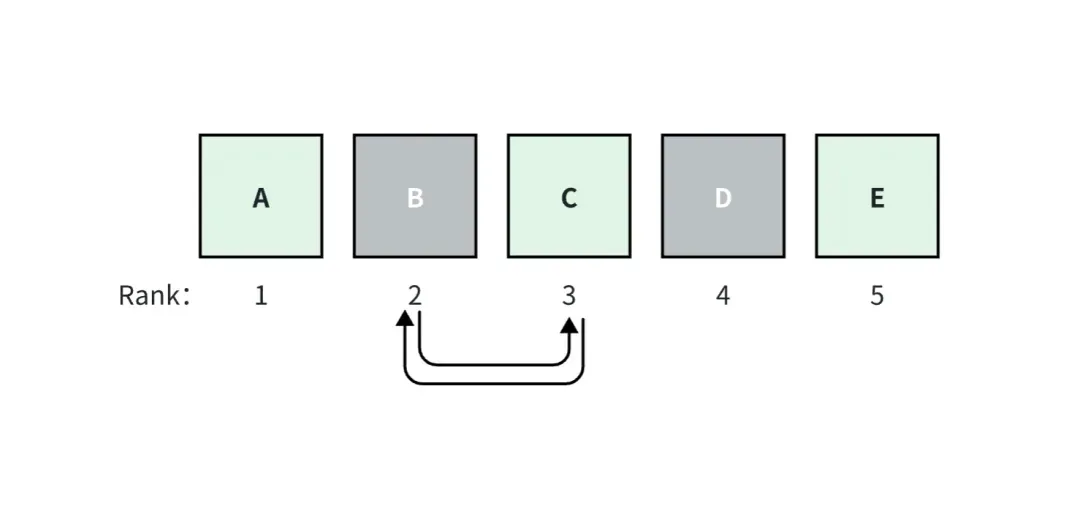
比如在上图中,我们假设 RAG 应用召回了 top_k=5 个文档,其中,A、C 和 E 文档是 ground-truth。A 文档排名为1,它的相关性得分最高,并且得分向右依次减小。
如果 B 和 C 文档调换了位置,那么考虑排名的指标得分就会发生变化,而不考虑排名的指标的得分则不会发生变化。
下面是一些常见的具体指标:
不考虑排名的指标
- 上下文召回率(Context Recall):系统完整地检索到了所有必要的文档的程度。
- 上下文精确率(Context Precision):系统检索到的信号(与噪音相比)的程度。
考虑排名的指标
- 平均精确率(AP)测量检索到的所有相关块并计算加权分数。数据集上的AP的平均值通常被称为MAP。
- 倒数排名(RR)测量您的检索中第一个相关块出现的位置。数据集上的RR的平均值通常被称为MRR。
- 归一化折扣累积增益(NDCG)考虑了您的相关性分类非二元的情况。
最主流评估 Benchmark:MTEB
Massive Text Embedding Benchmark(MTEB)是一个全面的基准,旨在评估文本嵌入模型在各种任务和数据集上的性能。MTEB 涵盖了 8 个嵌入任务,包括双语挖掘(Bitext Mining)、分类、聚类、成对分类、重新排序、检索、语义文本相似度(STS)和摘要。它涵盖了总共 58 个数据集,跨越了 112 种语言,使其成为迄今为止最全面的文本嵌入基准之一。
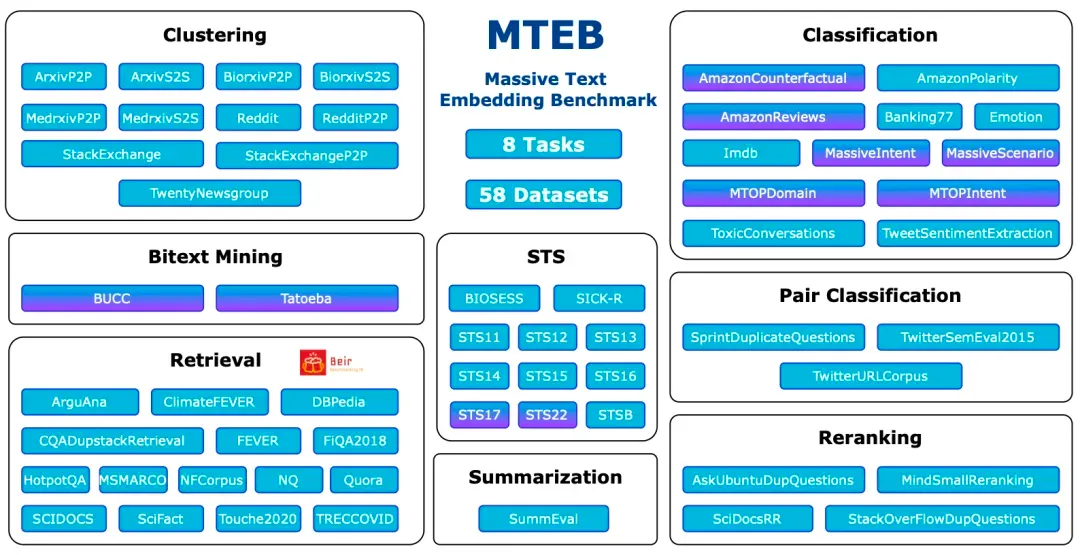
MTEB: Massive Text Embedding Benchmark
https://arxiv.org/abs/2210.07316
可以看到,在 MTEB 里包含 Retrieval 任务和 Reranking 任务,在 RAG 应用评估 Embedding 和 Rerank 模型时,要重点关注这两个任务得分较高的模型。在 MTEB的论文 (https://arxiv.org/abs/2210.07316)建议中,对于 Embedding 模型,NDCG 是最重要的指标;对于 Rerank 模型,MAP 是最重要的指标。
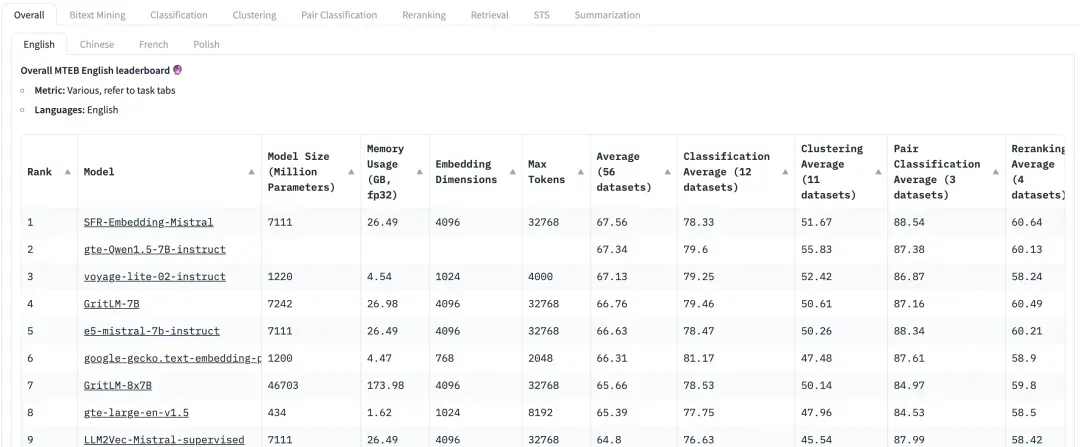
在 HuggingFace 上,MTEB 是大家非常关注的 leaderboard。然而,由于数据集是公开的,可能目前有一些模型对这个数据集已经在一定程度上过拟合了,这会使得在实际的数据集中的性能下降。所以在评测召回效果时,也需要更多地关注业务偏向的自定义数据集上的评测性能。
如何评估 LLM?
一般情况下,生成过程可以直接使用上文介绍过的由 Context 到 Response 这一步的 LLM-based 的指标,即 Faithfulness 来评估。
但对于一些比较简单的 query 测试,比如标准答案只有一些简单的短语的,也可以使用一些经典的指标。比如 ROUGE-L Precision、Token Overlap Precision。这种确定性的评估也需要有标注好的 ground-truth context。
ROUGE-L Precision 测量生成的答案和检索到的上下文之间的最长公共子序列。
Token Overlap Precision 计算生成的答案和检索到的上下文之间 token overlap 的精度。
比如下面这种相对简单问题可以还是可以用 ROUGE-L Precision、Token Overlap Precision 这些指标来评估。
Question: How many Index types does the latest version of Milvus support?
Reply: As of last month, Milvus support 11 Index types.
Ground-truth Context: In this version, Milvus support 11 Index types.
但要注意,这些指标在提问复杂的 RAG 场景下不太适用,这时就需要用 LLM-based 的指标来评估。比如像下面这种开放性的提问:
Question: Please design a text search application based on the features of the latest version of Milvus and list the application usage scenarios.
04.常用的评估工具介绍
目前开源社区已经出现了专业的工具,用户可以使用它们来方便快速进行定量评估。下面我们介绍目前比较常见好用的 RAG 评估工具,以及它们的一些特点。
Ragas(https://docs.ragas.io/en/latest/getstarted/index.html):Ragas 是专注于评估 RAG 应用的工具,通过简单的接口即可实现评估。Ragas 指标种类丰富多样,对 RAG 应用的框架无要求。也可以通过 langsmith(https://www.langchain.com/langsmith)来监控每次评估的过程,帮助分析每次评估的原因和观察 API key 的消耗。
Continuous Eval(https://docs.relari.ai/v0.3):Continuous-eval 是一个用于评估 LLM 应用 pipelines 的开源软件包,重点放在检索增强生成(RAG)pipelines 上。它提供了一种更便宜、更快速的评估选项。此外,它还允许创建具有数学保证的可信的集成评估管道。
TruLens-Eval:Trulens-Eval 是专门用于评估 RAG 指标的工具,它对 LangChain 和 Llama-Index 都有比较好的集成,可以方便地用于评估这两个框架搭建的 RAG 应用。另外,Trulens-Eval 也可以在浏览器中启动页面进行可视化地监控,帮助分析每次评估的原因和观察 API key 的消耗。
Llama-Index:Llama-Index 是很适合用来搭建 RAG 应用,并且它目前的生态比较丰富,目前也在快速迭代发展中。它也包含评估 RAG 的功能和生成合成数据集的功能,用户可以方便地对由 Llama-Index 本身搭建的 RAG 应用进行评估。
除此之外,还有一些评估工具,它们在使用功能上,与上述的这些大同小异。比如 Phoenix(https://docs.arize.com/phoenix)、DeepEval(https://github.com/confident-ai/deepeval)、LangSmith、OpenAI Evals(https://github.com/openai/evals)。这些评估工具的迭代发展也非常快,关于具体的功能与使用方式可以查阅相应的官方文档。
05.总结
对于 RAG 应用的用户和开发者来说,评估 RAG 应用的性能在实践中至关重要。本文将从黑盒和白盒两个角度介绍定量评估 RAG 应用的方法,并介绍一些实用的评估工具,旨在帮助读者快速理解评估技术并能够迅速上手。如需了解更多关于 RAG 的信息,请参考本系列的其他文章《RAG 修炼手册|一文讲透 RAG 背后的技术》《RAG 修炼手册|RAG敲响丧钟?大模型长上下文是否意味着向量检索不再重要》。
 张晨
张晨Cheney Zhang is an accomplished Algorithm Engineer at Zilliz.


