利用向量数据库中的产品量化提高内存效率
当今,数据科学和机器学习在推动组织和企业的运营效率方面发挥着重要作用。在每一个数据科学计划的核心都存在着一个紧迫的任务:高效地管理数据存储和检索。
向量数据库旨在处理复杂和高维数据集的复杂性,其中数据点通过嵌入转换并存储为向量。这些向量可以跨越多个维度,从几十到几千不等,适应多样化的数据结构。向量数据库在许多用例中都受益匪浅,例如检索增强生成(RAG)和推荐系统,它们使得基于相似性度量的流线化搜索操作成为可能。
然而,向量数据库在处理大规模数据集时面临许多挑战,例如高内存使用率和查询检索速度较慢。然而,已经取得了显著的进步来解决这些障碍,特别是通过像产品量化(PQ)这样的技术。这种方法通过惊人的90%减少了内存需求,为部署可扩展、高效和成本效益高的向量数据库奠定了基础。
那么,泡一杯咖啡,做好准备,我们将通过动手示例探索产品量化的复杂性和实际实施。
什么是产品量化,它是如何工作的?
产品量化(PQ)是一种将高维数据向量压缩成紧凑表示的技术,同时最小化信息损失。它提供了一个显著的优势,超越了传统的降维方法,如主成分分析(PCA)。那么,产品量化是如何工作的呢?以下是关键步骤。
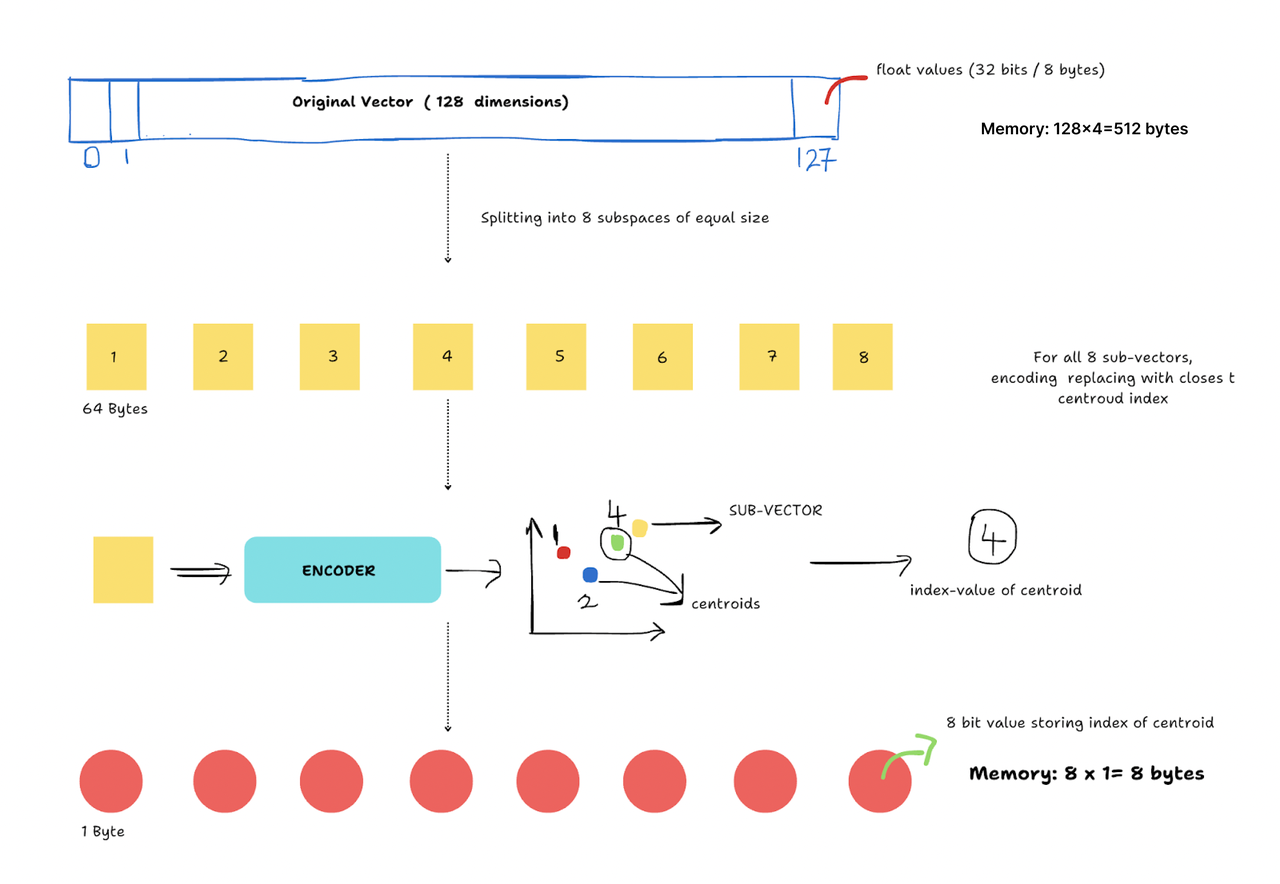
步骤1:将向量分割成子空间
我们将一个高维向量分解成更小、更易于管理的等大小子空间。例如,一个128维向量可以被分成16个子空间,每个子空间包含8个维度。
步骤2:子向量的量化和编码
然后,这些子空间分别进行量化。量化是指将向量映射到每个子空间中的一组有限的参考点。这些参考点通常是从像K-means这样的聚类算法计算出的质心。原始值被替换为最近质心的索引。由于每个索引需要的内存远少于原始向量,这种方法大大减少了数据大小。
步骤3:量化的乘积
为所有子向量找到最近的质心并分配其索引的过程重复进行。每个子向量的索引被连接起来,以获得最终的压缩表示,这可以用于搜索和检索数据。通过将每个子空间的索引对应的参考点结合起来,可以以最小的信息损失检索原始向量的近似版本。
 111.1.PNG
111.1.PNG
图1-产品量化是如何工作的?
为什么要在相似性搜索中使用产品量化?
产品量化在大规模数据集上的向量搜索操作中可以提供多方面的好处,例如:
更快的搜索速度:
PQ允许向量数据库更快地执行相似性搜索,因为它们只需要比较紧凑的编码而不是完整的高维向量。这种方法在最近邻搜索中特别有益,最近邻搜索在推荐系统、图像检索和类似任务的系统中广泛使用。
减少内存占用:
PQ通过用较小的索引替换原始数据点,大幅减少了存储向量所需的内存。这在处理包含数百万甚至数十亿高维数据点的大型数据集时至关重要。
可扩展性:
PQ数据的压缩性质允许在资源受限的系统上存储和搜索更大的数据集,或者在快速响应时间至关重要的实时应用中。
PQ不受传统技术如PCA的限制,因为它专注于保持数据点之间的相似性关系
产品量化支持复杂的机器学习模型和大规模数据分析任务。它在许多现代AI和数据驱动的应用中是不可或缺的,提供了准确性和内存使用之间的正确权衡。主要用例包括推荐系统、面部识别系统、用于防止欺诈的异常检测等。
产品量化的挑战
每个硬币都有两面。虽然产品量化是向量搜索中的一种创新量化方法,但它也带来了挑战。
准确性的损失:
向量的量化本质上会导致信息的损失。近似意味着一些相似的向量可能由于量化误差而被认为不同,影响查询结果的召回率和精确度。
子空间和码本的选择:
决定最优的子空间数量和码本大小(每个子空间中的质心数量)可能是具有挑战性的。将向量分割成非常小的子空间会大大压缩它,但可能会导致显著的准确性损失。
训练的可扩展性:
训练量化器(如k-means聚类)可能是计算密集型的,尤其是随着数据集的维度和大小增加。有效扩展这一过程对于实际应用至关重要。
管理成本:
编码和解码向量的计算成本可能会影响查询速度,当实时响应至关重要时。
研究人员正在开发技术来解决这些挑战并提高PQ的鲁棒性。例如,基于持续数据摄取动态调整码本可以提供更准确的量化。并行处理技术如多线程被用来抵消与PQ相关的计算成本。
实验结果:实践中的产品量化
在使用产品量化之前,了解如何评估这种技术至关重要。在评估向量数据库中的PQ时,需要考虑一些事情:内存节省量、数据检索期间的召回准确性和成本。
在本节中,我们将使用VectorDBBench,一个向量数据库的开源基准测试工具,来检查不同向量数据库的性能。
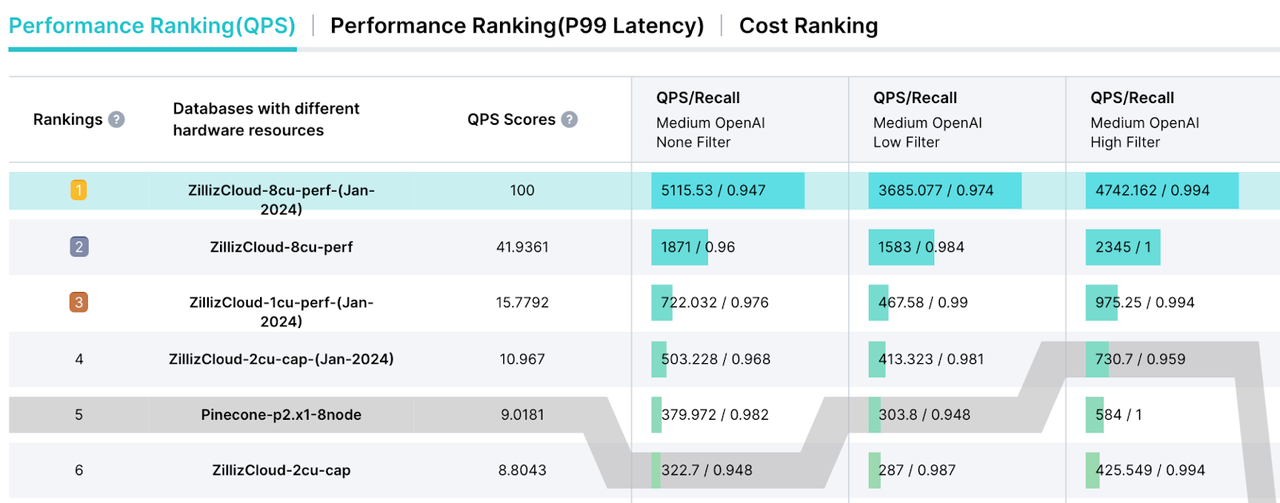
VectorDBBench是一个工具,供数据专业人员比较各种向量数据库并找到最佳解决方案。这个工具包括来自OpenAI和Cohere的真实世界测试场景和公共数据集。它提供了一个全面的绩效分析报告,包括延迟指标、QPS(每秒查询得分)、成本性能比(每QPS产生的成本)以及每百万次查询产生的成本。例如,根据这个基准测试结果,Zilliz Cloud(完全托管的Milvus)显示出比Pinecone高出10倍以上的QPS得分。
 111.2.png
111.2.png
性能比较:Zilliz Cloud与Pinecone
性能比较:Zilliz Cloud与Pinecone
Zilliz Cloud:八个性能优化的CU
Pinecone:一个p2(性能优化)吊舱和八个节点
数据集:OpenAI,500,000个具有1536维的向量
使用您的数据集基准测试PQ
在本节中,我将说明如何使用Python中的Milvus对您的数据集进行产品量化(PQ)基准测试。在开始之前,请确保您已安装Milvus。有关更多详细信息,请参阅我们的Milvus安装文档。
安装Milvus后,安装Milvus和必要的Python客户端。您可以使用pip安装Milvus客户端。
pip install pymilvus
下一步是准备您的数据集。清理数据以去除可能扭曲您的基准测试结果的噪声和异常值。数据集应具有向量作为特征。每个数据点(例如,图像或文本文档)应转换为数值向量。您也可以使用随机值合成生成一个样本数据集。
import numpy as np
# 生成简单的1000个128维向量
dataset = np.random.random((1000, 128)).tolist()
设置您的Milvus连接并配置具有PQ设置的集合。决定如何将您的向量分割成子空间。子空间的数量(M)和每个子空间的维度(K)是影响压缩和准确性的关键因素。
python
from pymilvus import CollectionSchema, FieldSchema, DataType, Collection
# 连接到Milvus服务器
from pymilvus import connections
connections.connect("default", host='127.0.0.1', port='19530')
# 定义存储向量的集合的模式
fields = [
FieldSchema(name="id", dtype=DataType.INT64, is_primary=True, auto_id=True),
FieldSchema(name="embedding", dtype=DataType.FL
是一个迭代过程,以找到效率和准确性之间的最佳平衡。这些代码示例为使用Milvus进行PQ基准测试提供了基本框架。始终使用特定的数据集和用例要求验证设置和结果。
产品量化的最佳实践提示
从小处开始:根据召回率,从较小的子空间开始,并根据需要逐步增加。
聚类质量: 确保量化步骤中的聚类质量高;较差的聚类会显著降低近似的质量。
硬件利用:如果可用,使用硬件加速(例如,GPU),特别是在处理大型数据集时。
并行处理:利用Milvus的并行处理能力,加快量化器的训练和查询阶段。
 111.3.png
111.3.png
产品量化在向量搜索中的应用
结论
产品量化(PQ)是一种创新的相似性搜索方法。通过将数据压缩成紧凑的表示形式,而不会显著影响检索准确性,PQ使企业和研究人员能够在现有硬件上管理更大的数据集,降低成本的同时保持性能。Milvus是一个高级的开源向量数据库,支持产品量化以实现高效的向量搜索。无论您是寻求改进搜索功能的数据科学家,还是希望优化数据基础设施的企业,Milvus都是您应用的最佳解决方案。
 ShriVarsheni R
ShriVarsheni RFreelance Technical Writer