



当一个程序员决定穿上粉裤子
作为一个大众眼中的“非典型程序员”,我喜欢拥抱时尚和潮流,比如我经常在演讲时穿粉色裤子,这甚至已经成为一个标志性打扮。某天又逢主题演讲日,我站在衣柜前挑选上衣的时候,忽然灵光乍现:有没有可能借助 Milvus 找到和我穿搭风格最为相似的明星呢?

这个想法在我脑海中不停地闪现,始终没有遇到特别合适的契机进行实践。直到最近,我遇到了一个名为 Fashion AI 的项目,它主要利用微调模型对服装图片进行分割(segmentation),然后裁剪出图像中标注(label)的时尚单品,并将所有图片调整为相同的大小,最后将这些图像转化为 embedding 向量存储在开源向量数据库 Milvus 中。通过这个项目可以在 Milvus 数据库中查询并获得 3 个最相似的向量结果。随后,就可以通过上传一张自己穿着打扮的照片,最终确定与我们时尚风格最为相似的明星。
接下来,我将和大家分享这个项目具体的实现路径。
在正式开始前,可以通过这个链接获取项目使用到的图片。此外,想要搭建本项目,还需要升级 Python 版本,通过指令 pip install milvus pymilvus torch torchvision matplotli 安装所需软件工具等。本项目使用了 Hugging Face 上由 Mateusz Dziemian 提供的 clothing segmenter 模型 以及 PyTorch 上由 Nvidia 提供的 ResNet50 模型 对图像进行分割,将图像转化为 embedding 向量。
01.图像分割
为了完成图像分割任务,我在 Hugging Face 上找到了以下 3 个模型:
Mateusz Dziemian 提供的 segformer_b2_clothes 模型
Valentina Feruere 提供的 YOLOS-Fashionpedia 模型
Patrick John Chia 提供的 Fashion-CLIP 模型
最终,我选择了 segformer 模型,因为它可以对不同的服装图片进行准确分割,并识别出 18 种“对象”类型。也就是说,这个模型可以检测到图片中的“上衣”、“连衣裙”、“左脚鞋子”、“右脚鞋子”等诸多服装类型。此外,这个模型还可以检测图片中的”脸部”、“头发”、“右腿”、“左腿”等。浏览该链接 了解模型可以识别的全部 18 种对象(object)类型。
开始前,我们首先需要导入本项目中图像处理时所需的工具包,包括:
torch用于提取图像特征来自
transformers的segformer来自
torchvision的Resize、masks_to_boxes、crop。
import torch
from torch import nn, tensor
from transformers import AutoFeatureExtractor, SegformerForSemanticSegmentation
import matplotlib.pyplot as plt
from torchvision.transforms import Resize
import torchvision.transforms as T
from torchvision.ops import masks_to_boxes
from torchvision.transforms.functional import crop
使用 Hugging Face 生成图像分割掩膜
图像分割方法有很多种,采用哪种方法主要取决于你使用的模型及其检测到的内容。在本项目中,我们使用的模型会返回一个 18 层的图像,每层包含一种检测对象类型,其中包含图像背景。
现在,我们先编写一个函数来生成这个 18 层图像。
get_segmentation函数需要三个参数:特征提取器(feature extractor)、模型(model)和图像(image)。
首先,这个函数会使用图像和提取器生成输入特征(input feature), 然后将模型输出转换为 logits。之后,该函数通过 PyTorch 双线性插值(Bilinear Interpolation)上采样(upsample) logits。最后,该函数仅采取每个像素中的最大预测值,以创建分割掩膜(mask)。
def get_segmentation(extractor, model, image):
inputs = extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits.cpu()
upsampled_logits = nn.functional.interpolate(
logits,
size=image.size[::-1],
mode="bilinear",
align_corners=False,
)
pred_seg = upsampled_logits.argmax(dim=1)[0]
return pred_seg
upsampled_logits中的图像如下所示:
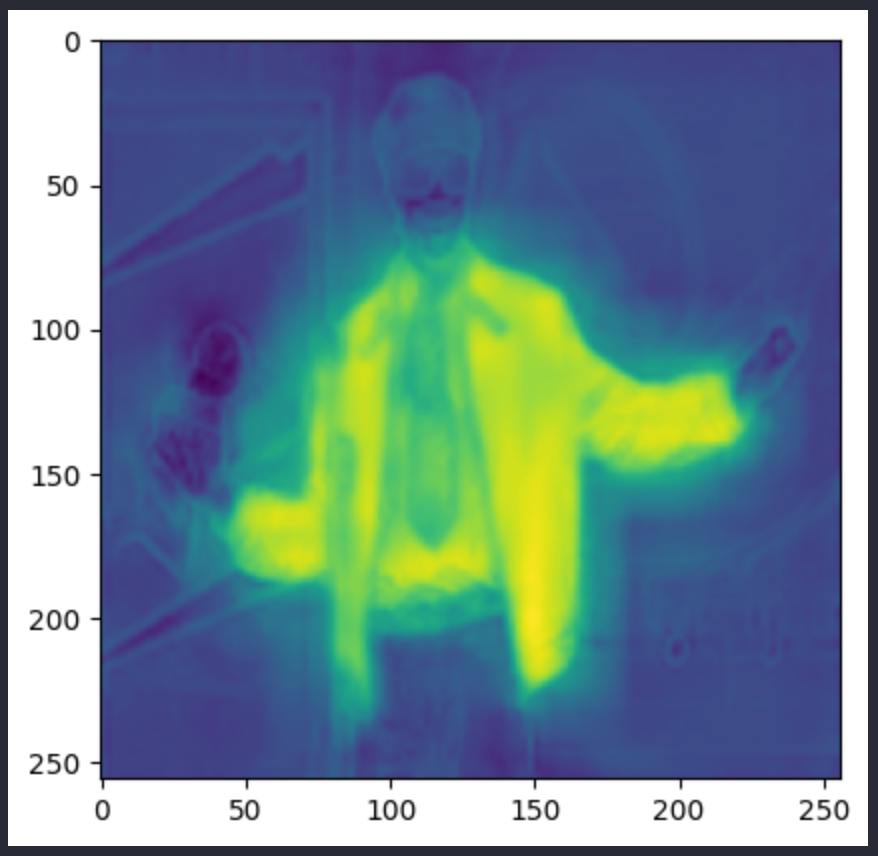
pred_seg图像如下所示。上面两张都是 Andre 3000 的照片,但其实是不同的图像:
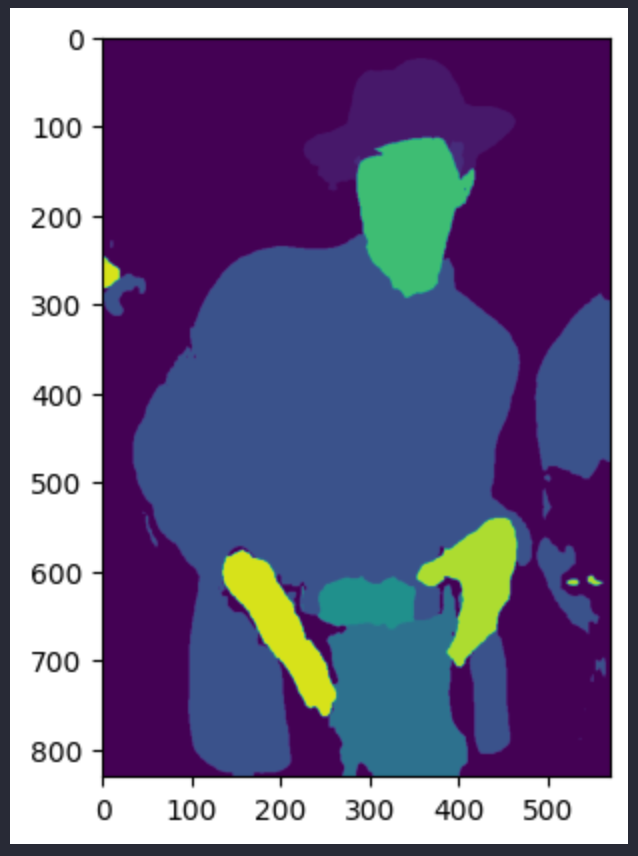
至此,获取分割 mask 的操作就十分简单了。我们获取分割结果中所有的唯一值。根据本项目采用的模型,最多可以获取 18 个值。第一个结果代表的是图像背景,所以可以舍弃这个结果。为了生成 mask,我们提取分割像素中与对象 ID 一致的像素。
以下函数会返回 mask 和 ID,以便可以同时查看二者:
# 返回 2 个 lists masks (tensor) 和obj_ids(int)
# 来自 hugging face 的 "mattmdjaga/segformer_b2_clothes" 模型
def get_masks(segmentation):
obj_ids = torch.unique(segmentation)
obj_ids = obj_ids[1:]
masks = segmentation == obj_ids[:, None, None]
return masks, obj_ids
函数生成的图像 mask 如下所示。左图为头发 mask,右图为上衣 mask:

使用 Pytorch 裁剪和调整图像大小
接下来使用 get_masks 函数为图像中每个监测到的对象以及原图生成新图像。随后用 masks_to_boxes 函数将 mask 转化为边界框(bounding box)。此前,我们已经通过 torchvision.ops 导入了这个函数。
接着,创建一系列边界框并将边界框坐标系转为 crop 坐标系。边界框的形式为 (x1, x2, y1, y2)。crop 函数期望输入形式为 (top, left, height, width)。
在正式裁剪图像前,我们还定义了一个图像预处理函数。将每个图像调整为 256x256 的大小,并转化为 PyTorch tensor (目前是 PIL 图像)。裁剪时,循环遍历裁剪框,并调用 crop 函数。随后我们将预处理完成的图片加入到 dictionary 中,以对应分割 ID 的主键值。函数最后会返回 dictionary。
def crop_images(masks, obj_ids, img):
boxes = masks_to_boxes(masks)
crop_boxes = []
for box in boxes:
crop_box = tensor([box[0], box[1], box[2]-box[0], box[3]-box[1]])
crop_boxes.append(crop_box)
preprocess = T.Compose([
T.Resize(size=(256, 256)),
T.ToTensor()
])
cropped_images = {}
for i in range(len(crop_boxes)):
crop_box = crop_boxes[i]
cropped = crop(img, crop_box[1].item(), crop_box[0].item(), crop_box[3].item(), crop_box[2].item())
cropped_images[obj_ids[i].item()] = preprocess(cropped)
return cropped_images
下面的示例图中 Drake 穿着鲜橙色的衣服。我们使用裁剪框框处图像中的对象(时尚单品)并为他们各自生成单独的图像:

02.将图像数据添加至向量数据库中
图像分割裁剪完成后,我们就可以将其添加至 Milvus 向量数据库中了。为了方便上手,本项目中使用了 Milvus Lite 版本,可以在 notebook 中运行 Milvus 实例。接下来,使用 PyMilvus 连接至 Milvus Lite 提供的默认服务器。
这一步骤中,还需要设置一些常量。定义向量维度、数据量、集合名称、返回的结果个数。随后,运行 ssl 函数来创建上下文,从 PyTorch 获取模型。
from milvus import default_server
from pymilvus import utility, connections
default_server.start()
connections.connect(host="127.0.0.1", port=default_server.listen_port)
DIMENSION = 2048
BATCH_SIZE = 128
COLLECTION_NAME = "fashion"
TOP_K = 3
# 如果遇到 SSL 证书 URL 错误,请在导入 resnet50 模型前运行此内容
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
在向量数据库中定制 Schema 并存储元数据
先定制 Schema。Schema 用于组织向量数据库中存储的数据。id 字段就和 SQL 或者 NoSQL 数据库中的 key ID 一样。Milvus Schema 中的其他字段可以设置 int64、varchar、float 等数据类型。
在本项目中,我们是保存文件路径、明星名字、分割 ID,并将其作为元数据,后续还会考虑添加更多字段,例如边界框、mask 位置等。定义好 FieldSchema、CollectionSchema 后,就可以创建 1 个 Miluvs Collection。
Collection 创建完成后,构建索引。索引参数十分简单。选择 IVF Flat 的索引类型和 L2 相似度类型。这个索引是针对于 Collection 中的 embedding 向量字段。索引构建完成后,将 Collection 加载到内存中,以便后续操作。
from pymilvus import FieldSchema, CollectionSchema, Collection, DataType
fields = [
FieldSchema(name="id", dtype=DataType.INT64, is_primary=True, auto_id=True),
FieldSchema(name='filepath', dtype=DataType.VARCHAR, max_length=200),
FieldSchema(name="name", dtype=DataType.VARCHAR, max_length=200),
FieldSchema(name="seg_id", dtype=DataType.INT64),
FieldSchema(name='embedding', dtype=DataType.FLOAT_VECTOR, dim=DIMENSION)
]
schema = CollectionSchema(fields=fields)
collection = Collection(name=COLLECTION_NAME, schema=schema)
index_params = {
"index_type": "IVF_FLAT",
"metric_type": "L2",
"params": {"nlist": 128},
}
collection.create_index(field_name="embedding", index_params=index_params)
collection.load()
从 Nvidia ResNet50 模型获取 embedding 向量
我们需要先从 PyTorch 中加载 Nvidia ResNet50 模型,然后删除最后一层输出层,因为 embedding 向量是模型的倒数第二层输出。
# 加载 embedding 模型并删除最后一层输出
embeddings_model = torch.hub.load('NVIDIA/DeepLearningExamples:torchhub', 'nvidia_resnet50', pretrained=True)
embeddings_model = torch.nn.Sequential(*(list(embeddings_model.children())[:-1]))
embeddings_model.eval()
以下函数负责接收向量并将数据插入 Milvus。主要有三个参数:数据、集合对象和模型(也就是本项目中使用的 embedding 模型)。为了解插入到数据库中的数据,以下代码中添加了几条打印语句。
除了打印调试数据外,我们还将 data[0] 中的所有值堆叠到一个 tensor 中,然后使用 squeeze 函数从输出中删除维度是 1 的值。随后,插入新的数据列表,其中包括原数据中的最后三条以及由 tensor 输出转化而来的数据列表,这些数据对应文件路径、名称、分割 ID、2048 维向量。
def embed_insert(data, collection, model):
with torch.no_grad():
print(len(data[0]))
print(data[0][0].size())
output = model(torch.stack(data[0])).squeeze()
print(type(output))
print(len(output))
print(len(output[0]))
print(output[0])
collection.insert([data[1], data[2], data[3], output.tolist()])
打印的数据如下图所示:
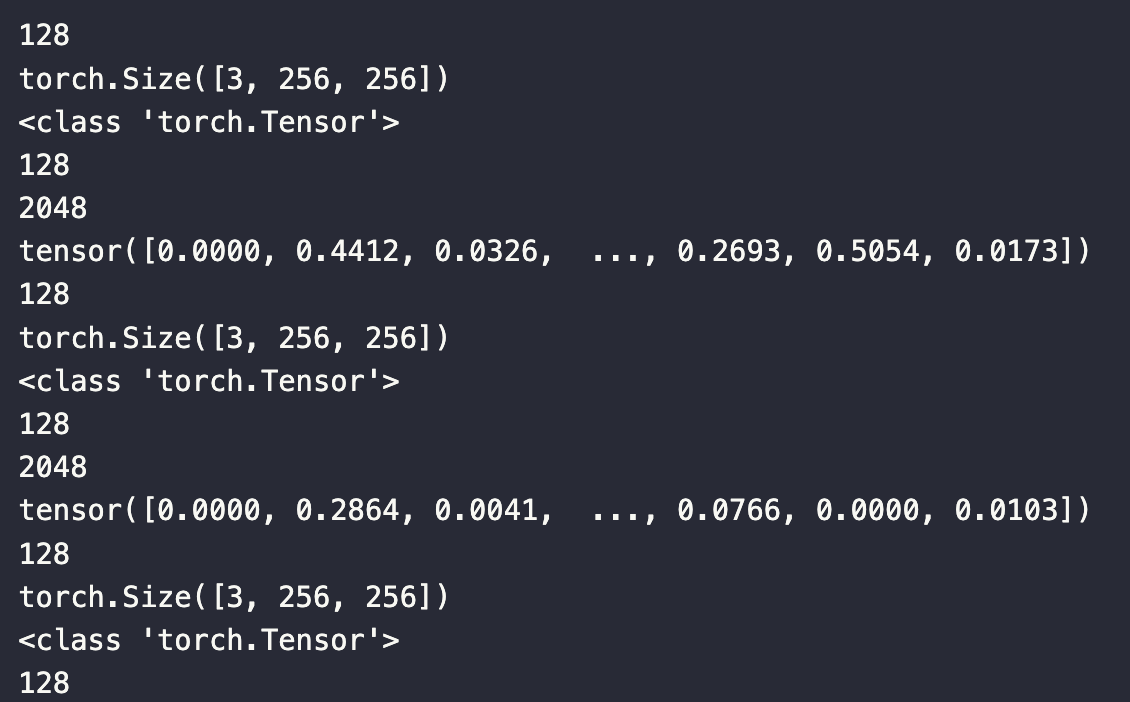
每个数据批次的大小为 128,每条数据的大小为 3x256x256。输出是 PyTorch tensor,长度为 128,输出中的每条数据长度为 2048。打印的 tensor 是数据批次中的第一条数据。
将图像数据存储到向量数据库中
还记得前文提到的特征提取器和分割模型吗?接下来轮到它们出场了。我们需要用到 segformer 预训练模型, 在循环遍历所有文件路径之后,将所有文件路径放入一个列表中。
extractor = AutoFeatureExtractor.from_pretrained("mattmdjaga/segformer_b2_clothes")
model = SegformerForSemanticSegmentation.from_pretrained("mattmdjaga/segformer_b2_clothes")
import os
image_paths = []
for celeb in os.listdir("./photos"):
for image in os.listdir(f"./photos/{celeb}/"):
# print(image)
image_paths.append(f"./photos/{celeb}/{image}")
Milvus 期望输入格式为列表。在本项目中,我们使用了 4 个列表,分别对应图像、文件路径、名称和分割 ID。在 embed_insert 函数中,将图像转换为 embedding 向量。然后,循环遍历每个图像文件的文件路径,收集它们的分割 mask 并对其进行裁剪。最后,将图像及元数据添加到数据批处理中。
每 128 张图像作为一批数据,我们将其转化为向量并插入到 Milvus 中,然后清空这批数据。在循环结束时,会 flush 数据完成索引构建。注意,在配备 M1 2021 Mac 和 16GB RAM 的计算机上,运行此过程需要约8分钟。
from PIL import Image
data_batch = [[], [], [], []]
for path in image_paths:
image = Image.open(path)
path_split = path.split("/")
name = " ".join(path_split[2].split("_"))
segmentation = get_segmentation(extractor, model, image)
masks, ids = get_masks(segmentation)
cropped_images = crop_images(masks, ids, image)
for key, image in cropped_images.items():
data_batch[0].append(image)
data_batch[1].append(path)
data_batch[2].append(name)
data_batch[3].append(key)
if len(data_batch[0]) % BATCH_SIZE == 0:
embed_insert(data_batch, collection, embeddings_model)
data_batch = [[], [], [], []]
if len(data_batch[0]) != 0:
embed_insert(data_batch, collection, embeddings_model)
collection.flush()
03.寻找与你时尚风格最相似的明星
上述步骤都完成后,就可以开始玩转这个系统了,它可以根据你上传的图片返回前 3 个与你穿搭风格最相似的明星。
将上传图像转化为向量
首先需要处理上传的图像。以下函数需要两个参数:数据和 (embedding)模型。我们使用模型将图像转化为向量、处理图像,图像转化为列表并返回图片列表。
def embed_search_images(data, model):
with torch.no_grad():
print(len(data[0]))
print(data[0][0].size())
output = model(torch.stack(data))
print(type(output))
print(len(output))
print(len(output[0]))
print(output[0])
if len(output) > 1:
return output.squeeze().tolist()
Else:
return torch.flatten(output, start_dim=1).tolist()
如下图所示,传入本函数的 data 实际上是 data[0] 对象:
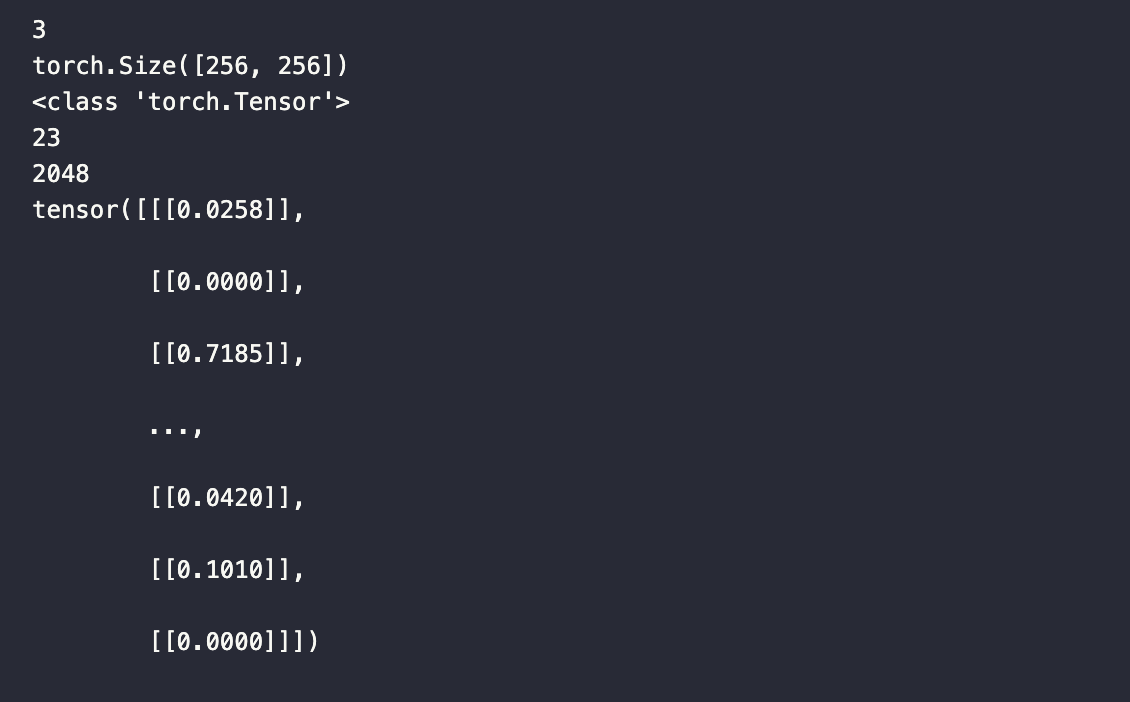
在查询时,我们只需要向量数据,但还是可以保留其他数据字段,就像把数据插入到 Milvus 中一样。
# data_batch[0] is a list of tensors
# data_batch[1] is a list of filepaths to the images (string)
# data_batch[2] is a list of the names of the people in the images (string)
# data_batch[3] is a list of segmentation keys (int)
data_batch = [[], [], [], []]
search_paths = ["./photos/Taylor_Swift/Taylor_Swift_3.jpg", "./photos/Taylor_Swift/Taylor_Swift_8.jpg"]
for path in search_paths:
image = Image.open(path)
path_split = path.split("/")
name = " ".join(path_split[2].split("_"))
segmentation = get_segmentation(extractor, model, image)
masks, ids = get_masks(segmentation)
cropped_images = crop_images(masks, ids, image)
for key, image in cropped_images.items():
data_batch[0].append(image)
data_batch[1].append(path)
data_batch[2].append(name)
data_batch[3].append(key)
embeds = embed_search_images(data_batch[0], embeddings_model)
查询向量数据库
将上传图片转化为向量后,便可以开始在向量数据库中查询相似数据了。为了测试,我们添加了 time 模块记录每次查询所需的时间。本项目中测量了查询 23 个 2048 维向量数据所需的时间,如果没有这个需求,可以直接使用 search 函数。
import time
start = time.time()
res = collection.search(embeds,
anns_field='embedding',
param={"metric_type": "L2",
"params": {"nprobe": 10}},
limit=TOP_K,
output_fields=['filepath'])
finish = time.time()
print(finish - start)
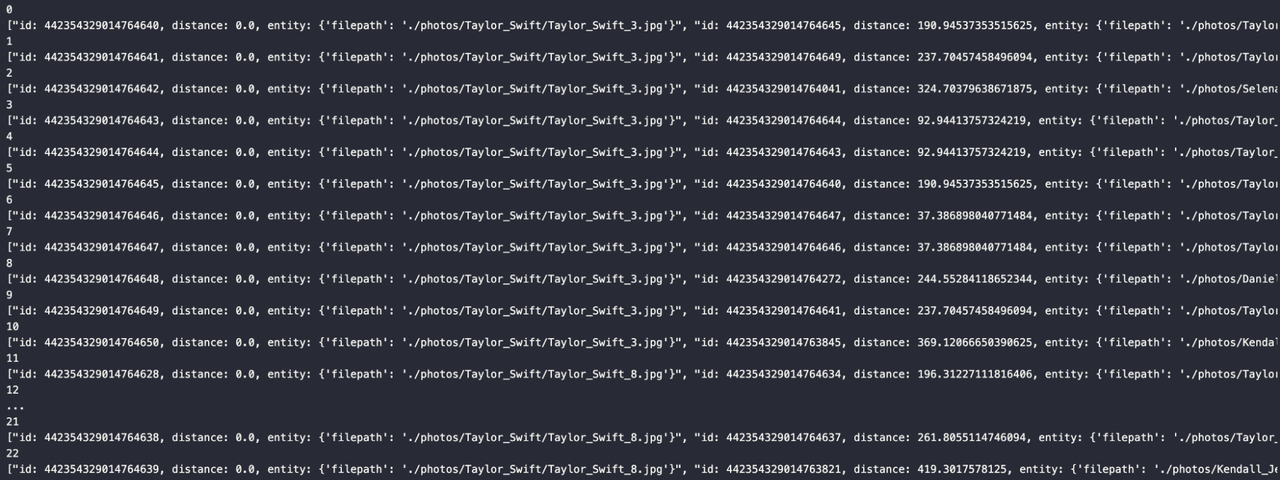
在循环后,可以看到以下生成的响应:
for index, result in enumerate(res):
print(index)
print(result)
欢迎大家上手操作,期待你们的结果分享!
本文最初发布于 AI Accelerator Institute,已获得转载许可。
🌟「寻找 AIGC 时代的 CVP 实践之星」 专题活动即将启动!
Zilliz 将联合国内头部大模型厂商一同甄选应用场景, 由双方提供向量数据库与大模型顶级技术专家为用户赋能,一同打磨应用,提升落地效果,赋能业务本身。
如果你的应用也适合 CVP 框架,且正为应用落地和实际效果发愁,可直接申请参与活动,获得最专业的帮助和指导!联系邮箱为 business@zilliz.com。
 Yujian Tang
Yujian Tang


