



我决定给 ChatGPT 做个缓存层 >>> Hello GPTCache

🌟 写在前面
黄老板的一句【AI 的 iPhone 时刻已至】震撼了半个科技圈。或许,应该把这句话再扩展一下:AI 的 iPhone 时刻早已势不可挡,它不是平静随和地跟大家 say hi,而是作为一个强悍的巨人携着一把名为 ChatGPT 的斧子,重重地砸开了那扇通向 AI 新世界的大门。
接连几个月,ChatGPT、AutoGPT 等新事物的不断涌现持续刷新着大家的认知。与此同时,圈内不断有类 ChatGPT 或 ChatGPT 相关的新产品问世,当然,这其中也包括我的团队。
最终,我们从自己的开源项目 Milvus 和一顿没有任何目的午饭中分别获得了灵感,做出了 OSSChat、GPTCache。在这个过程中,我们也在不断接受「从 0 到 1」的考验。作为茫茫 AI 领域开发者和探索者中的一员,我很愿意与诸位分享这背后的故事、逻辑和设计思考,希望大家能避坑避雷、有所收获。
这次,我想先讲讲 GPTCache。
由一次午饭时闲聊开始的项目……
是的,你没看错,GPTCache 的灵感起源是从一次午饭闲聊时开始的。
在展开讲述前,先普及一个背景。我的团队负责开源项目 Milvus 的开发与维护,需要频繁为社区用户答疑解惑。在这个过程中,我们经常会被问及一些基础文档相关或重复性的问题,加之不断有新用户进群,最终便形成了一个【提问、解答、重复提问、重复解答】的循环。而站在用户的角度,询问和答疑不都是同步和即时的(尽管我们一直在努力,但很难做到 24 小时在线)。尤其在遇到紧急情况时,可能根本得不到有效反馈。
这就是 OSSChat 的起源。作为一个开源项目知识库的集成者,它可以在 ChatGPT 的基础上,帮用户解决在 GitHub 上开源项目的很多问题,例如文档查找、安装指南等各种基础问题。
OSSChat 问世后,我们很激动,因为这是一个可以真正造福广大开发者的应用。不过,很快团队便遇到了新的考验,随着使用 OSSChat 的用户越来越多,我们忽然意识到一个问题:ChatGPT 可能会成为阻碍 OSSChat 提升性能的瓶颈。一来不稳定的 ChatGPT 服务会拉低 OSSChat 响应速度;二来每次调用 ChatGPT 接口,都会产生新的费用,这导致 OSSChat 的使用成本不断拉升。
同时,这也验证了我之前的一个猜测:为什么在 ChatGPT 如此火爆的情况下,LLM(大型语言模型)依然没有得到最为广泛的应用?答案是因为受制于性能和成本,甚至可以这样形容,性能和成本是 LLM 难以推广、应用以及获取用户增长的罪魁祸首。
说回 OSSChat,如何在保证它在性能提升的同时还能减少使用成本,成为团队亟待解决的大问题。烦恼于这件事的解决方案,大家经常食不知味。
于是,我明确提出了吃饭时不聊工作的要求。又是一次午饭时间,大家你一言我一语地唠闲嗑。但你知道,程序员聚在一起就那三个话题:计算机、买房和孩子。说着说着,话题就扯到了计算机的发展:在冯·诺依曼的体系结构下有了 CPU、Memory、控制器……由于 CPU 和内存在速度上不匹配,慢慢又发展出了在 CPU 之上的多级缓存。类比到 AI 时代,大模型就是新的 CPU,Vector Database 是内存。那在系统运行很慢的情况下……
对了!缓存层!在系统运行很慢的情况下,缓存层的重要性就不言而喻了!
既然这样,为什么不添加一个缓存层来存储 LLM 生成的响应呢?!这样一来,我们不仅可以提升 OSSChat 的响应速度,还能节省成本。
这就是 GPTCache 诞生的最初过程。
LLM 缓存层的可行性到底有多少?
LLM 缓存层的想法让我们看到了更多的可能性。其实,GPTCache 的逻辑类似于过去在搭建应用时,增加一层 Redis 和 Memcache,从而加快系统查询效率并降低访问数据库的成本。有了缓存层,在测试 OSSChat 功能时,就无需再额外调用 ChatGPT 的接口了,省时省事儿,说的就是这个道理。
不过,传统的缓存只在键值相同的情况下检索数据,不适用于 AIGC(人工智能自动生成内容)应用。而 AIGC 需要的是语义近似的缓存,例如【苹果手机】和【iPhone】实际上都是指苹果手机。
所以,需要专门为 AIGC 应用设计搭建了一种全新的缓存,我们给它命名为——GPTCache。
GPTCache 能干什么?有了它,我们就能够对上百万个缓存的提问向量进行向量相似性检索,并从数据库中提取缓存的响应回答。这样一来,OSSChat 端到端的平均响应时间便能显著降低,也能节省更多成本。简言之,它可以加速 ChatGPT 响应速度并优化语义检索。有了 GPTCache,用户只需修改几行代码便可缓存 LLM 响应,将 LLM 应用提速 100 多倍。
当然,进行到这里,GPTCache 还只是一个概念。是否真正具备可行性还需要进一步验证。于是,团队对 OSSChat 发起了多轮调研。几番调查过后,我们发现用户的确喜欢提问某几类特定的问题:
热门话题相关内容
热门 GitHub repo
“什么是 xxx”的基础问题
OSSChat 首页推荐问题
这意味着和传统应用一样,AIGC 应用的用户访问同样具有时间和空间的局部性。因此,可以完美利用缓存来减少 ChatGPT 的调用次数。
为什么不是 Redis?
验证完可行性,便到了搭建系统的环节。这里我有一点必须要分享,在搭建 ChatGPT 缓存系统时,Redis 并不是我们的首选。
个人而言,我很喜欢用 Redis,它性能出色又十分灵活,适用于各种应用。但是 Redis 使用键值数据模型是无法查询近似键的。如果用户提出以下两个问题:【所有深度学习框架的优缺点是什么?】【告诉我有关 PyTorch vs. TensorFlow vs. JAX 的区别?】,Redis 会将其定义为两个不同的问题,而事实上,这两个问题表达的是同一个意思。无论是通过缓存整个问题还是仅缓存由分词器生成的关键字,Redis 都无法命中查询。
而不同的单词在自然语言中可能具有相同的含义,深度学习(Deep Learning)模型更擅长处理语义。因此,我们应该在语义缓存系统中加入向量相似性检索这一环节。
成本是 Redis 不适用于 AIGC 场景的另一个原因。逻辑很简单,上下文越长,键和值越长,使用 Redis 存储内容所产生的费用也可以就会高得离谱。因此,使用基于磁盘(disk-based)的数据库进行缓存可能是更好的选择。加上 ChatGPT 响应较慢,所以对缓存响应速度的要求也不是很高。
从零搭建 GPTCache
话不多说,先放一张 GPTCache 的架构图:
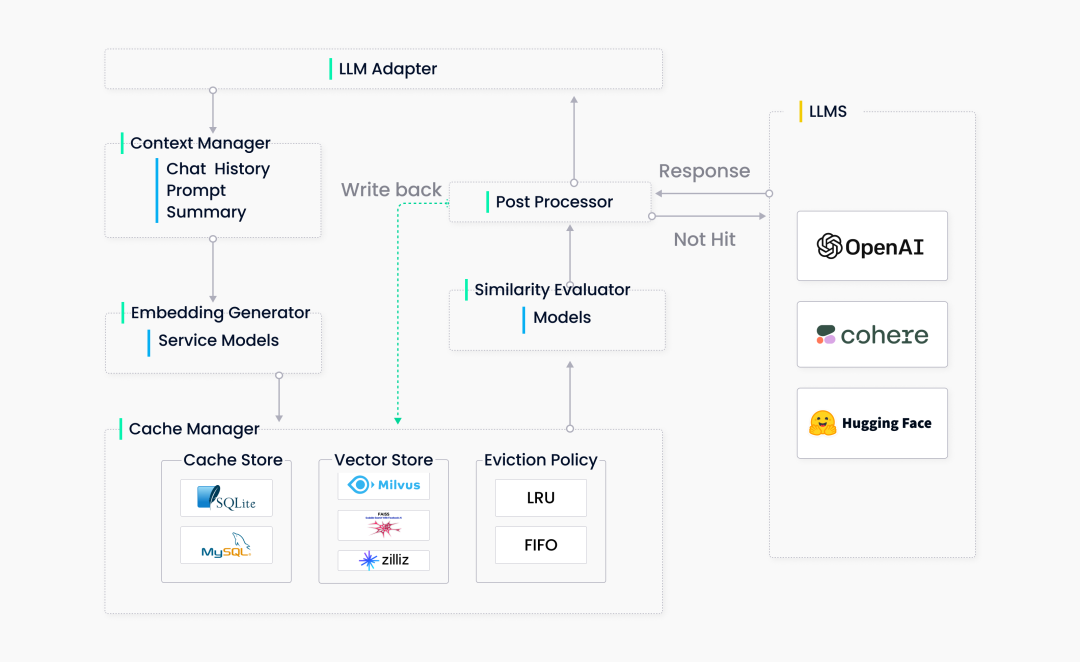
为了简化流程,我们最终决定了删除上下文管理器,所以整个 GPTCache 系统共包含五个主要组件:
- LLM 适配器(LLM Adapter)
适配器将 LLM 请求转换为缓存协议,并将缓存结果转换为 LLM 响应。由于想让 GPTCache 变得更加透明(这样用户无需额外研发,便可将其轻松集成到我们的系统或其他基于 ChatGPT 搭建的系统中),所以适配器应该方便轻松集成所有 LLM,并可灵活扩展,从而在未来集成更多的多模态模型。
目前,我们已经完成了 OpenAI 和 LangChain 的适配器。未来,GPTCache 的接口还能进一步扩展,以接入更多 LLM API。
- Embedding 生成器(Embedding Generator)
Embedding 生成器可以将用户查询的问题转化为 embedding 向量,便于后续的向量相似性检索。为满足不同用户的需求,我们在当下支持两种 embedding 生成方式。第一种是通过云服务(如 OpenAI、Hugging Face 和 Cohere 等)生成 embedding 向量,第二种是通过在 ONNX 上使用本地模型生成 embedding 向量。
后续,GPTCache 还计划支持 PyTorch embedding 生成器,从而将图像、音频文件和其他类型非结构化数据转化为 embedding 向量。
- 缓存管理器(Cache Manager)
缓存管理器是 GPTCache 的核心组件,具备以下三种功能:
缓存存储,存储用户请求及对应的 LLM 响应
向量存储,存储 embedding 向量并检索相似结果
逐出管理,控制缓存容量并在缓存满时根据 LRU 或 FIFO 策略清除过期数据
缓存管理器采用可插拔设计。最初,团队在后端实现时使用了 SQLite 和 FAISS。后来,我们进一步扩展缓存管理器,加入了 MySQL、PostgreSQL、Milvus 等。
逐出管理器通过从 GPTCache 中删除旧的、未使用的数据来释放内存。必要时,它从缓存和向量存储中删除数据。但是,在向量存储系统中频繁进行删除操作可能会导致性能下降。所以,GPTCache 只会在达到删除阈值时触发异步操作(如构建索引、压缩等)。
- 相似性评估器 (Similarity Evaluator)
GPTCache 从其缓存中检索 Top-K 最相似答案,并使用相似性评估函数确定缓存的答案是否与输入查询匹配。
GPTCache 支持三种评估函数:精确匹配(exact match)、向量距离(embedding distance)和 ONNX 模型评估。
相似性评估模块对于 GPTCache 同样至关重要。经过调研,我们最终采用了调参后的 ALBERT 模型。当然,这一部分仍有改进空间,也可以使用其他语言模型或其他 LLM(如 LLaMa-7b)。对于这部分有想法的小伙伴可以联系我们!
- 后期处理器(Post Processors)
后期处理器整理最终响应返回给用户。它可以返回最相似的响应或根据请求的温度参数调整响应的随机性。如果在缓存中找不到相似的响应,后期处理器则会将请求转发给 LLM 来生成响应,同时生成的响应将被存储在缓存中。
激动人心的测评环节
接下来便是检验成果的重要一步了!为评估 GPTCache 的性能,我们选取了一个数据集,其中包含三种句子对:语义相同的正样本、语义相关但不完全相同的负样本、语义完全不相关的中间样本。
- 实验 1
为了确定基线(baseline),我们先将 30,000 个正样本的键存入缓存中。接下来,我们随机选择 1,000 个样本,并使用对应的另 1,000 条句子(句子对中的另一个句子)作为查询语句。
以下是我们获得的结果:

我们发现,将 GPTCache 的相似性阈值设置为 0.7 可以较好地平衡命中率和负相关比率。因此,所有后续测试中都会应用这个设置。
用 ChatGPT 生成的相似度分数来确定缓存的结果是否与查询问题相关。将正样本阈值设置为 0.6,使用以下 prompt 生成相似度分数:
请将以下两个问题的相似度评分在0到1的范围内,其中0表示不相关,1表示完全相同的含义。
问题“有关自学的一些好的技巧是什么?”和“自学的聪明技巧是什么?”非常相似,相似度得分为1.0。
问题“野外生存的一些必需品是什么?”和“你需要什么东西才能生存?”相当相似,相似度得分为0.8。
问题“如果您16岁,您会给自己什么建议?”和“我应该在哪里在线推广我的业务?”是完全不同的,因此相似度得分为0。
*(注:以上 prompt 为中文翻译。原文请见:https://zilliz.com/blog/Yet-another-cache-but-for-ChatGPT)
- 实验 2
进行包含 50% 正样本和 50% 负样本的查询,在运行 1,160 个请求后,产生了如下结果:

命中率几乎达到了 50%,命中结果中的负样本比例与实验 1 相似。这说明 GPTCache 善于区分相关及不相关的查询。
- 实验 3
将所有负样本插入到缓存中,并使用它们句子对中的另一个句子作为查询。虽然某些负样本获得了较高的相似度得分(ChatGPT 认为它们的相似度打分大于 0.9),但是没有一个负样本命中缓存。原因可能是相似性评估器中使用的模型针对该数据集进行过微调,所以几乎所有负样本的相似性打分都降低了。
以上就是团队进行的典型实验,目前,我们已将 GPTCache 集成到 OSSChat 聊天机器人中,并努力收集生产环境中的统计数据。后续,我也会发布基准测试报告,报告中还包含实际用例,可以期待一下!
在进一步规划上面,团队正努力在 GPTCache 中接入更多 LLM 模型和向量数据库。此外,GPTCache Bootcamp 也即将发布。大家可以通过 bootcamp 学习如何在使用 LangChain、Hugging Face 等过程中加入 GPTCache,也可以 get 如何将 GPTCache 融入其他多模态应用场景中。
🌟写在最后
两周,仅仅用了两周,我们便完成搭建了 GPTCache 并将其开源。在我看来,这是一件了不起的事情,这离不开团队每一位成员的付出。从他们的身上我一次又一次地感受到开发者这个群体的冲劲,以及努力实践“技术改变未来”的信念,感慨良多。
对于团队以外的开发者,我也有一些话想说。正如开篇提到的,写这篇文章的初衷是站在 AIGC 从业者的角度,和大家分享 ChatGPT 引领的浪潮下,开发者【从 0 到 1】【从 1 到 100】的探索经历和心得,以求和大家讨论、共勉。
当然,最最重要的是希望各位开发者能参与到 GPTCache 的共建中。作为一个新生儿,它仍有很多需要学习的地方;而作为一个为开源而生的项目,它需要大家的建议、指正。
欢迎大家点击链接【https://github.com/zilliztech/GPTCache】使用并参与 GPTCache 的开源项目!(千万!千万记得管理缓存的容量!)
 栾小凡
栾小凡


