如何选择一个向量数据库|Elastic Cloud 和 Zilliz Cloud 面面观
随着以 Milvus 为代表的向量数据库在 AI 产业界越来越受欢迎,诸如 Elasticsearch 之类的传统数据库和检索系统也开始行动起来,纷纷在快速集成专门的向量检索插件方面展开角逐。
例如,在提供类似插件的传统数据库中,Elasticsearch 8.0 首屈一指,推出了包括向量插入和最相似近邻搜索(ANN)能力在内的一系列特性,并提供了相应的 RESTful API 接口。在这种情况下,作为 Elasticsearch 的完全托管版本,Elastic Cloud 也开始提供向量检索能力。
值得注意的是,作为既有系统的补充,大多数此类向量检索插件提供的 embedding 管理和向量检索方案并不尽如人意,使得这些插件在与检索性能密切相关的时延、容量和吞吐等指标上表现不佳。这就好像人们寄希望于将燃油汽车改造成使用锂电池和电机的新能源汽车一样,存在创新不足的问题。
本文将撇开这些表面差异,通过比较二者的性能基准测试结果和 Elastic Cloud 的相关特性,深入探究 Elastic Cloud 和 Zilliz Cloud (https://zilliz.com.cn/)的差异。
01.Elastic Cloud v.s. Zilliz Cloud:性能大比拼
Zilliz 经常会收到来自开发者和架构师的提问:“Zilliz Cloud 和 Elastic Cloud 比起来,谁进行向量处理能力比较强?”
诸如此类的问题很多,究其根本,大都是开发者/架构师在为语义相似性检索系统进行数据库选型时缺少决策依据有关。最近,随着检索增强生成系统(RAG:https://zilliz.com/use-cases/llm-retrieval-augmented-generation) 的持续火爆,此类提问也越来越多。
过去几周,我们从性能和特性能力两个方面对 Elastic Cloud(https://www.elastic.co/cn/cloud) 和 Zilliz Cloud 进行了详细的对比。在对比过程中,我们使用了开源的性能基准测试套件 VectorDBBench,围绕诸如每秒查询次数(QPS)、每美元查询次数(QP$)以及时延等关键指标展开测试。
测试用数据集
以下为测试中使用的两类数据集:
数据集 1 包含 1,000,000 条 768 维的向量数据。
数据集 2 包含 500,000 条 1,536 維的向量数据。
测试对象
以下为测试时使用的实例,这些实例在硬件配置上基本相近:
Zilliz Cloud (1cu-perf):Zilliz Cloud 1 CU 性能型实例
Zilliz Cloud (1cu-cap):Zilliz Cloud 1 CU 容量型实例
Elastic Cloud (up to 2.5c8g):Elastic Cloud 2.5 vCPU 和 8 GB 内存
注:关于 Zilliz Cloud 计算单元(CU)的更多信息,可以参考《适配各类大模型应用!手把手教你选择 Zilliz Cloud 实例类型》。
每秒查询次数(QPS)
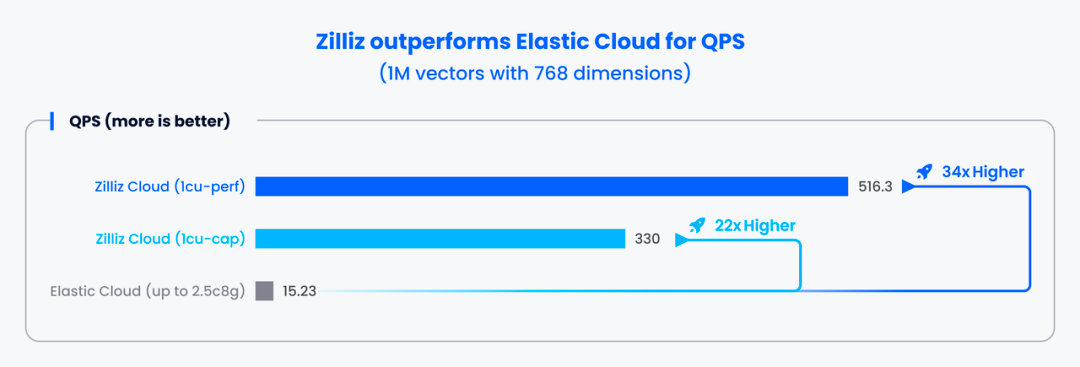
测试结果显示,在 1,000,000 条 768 维的向量数据中进行检索时,Zilliz Cloud 两款实例的 QPS 分别是 Elastic Cloud 实例的 34 倍和 22 倍。
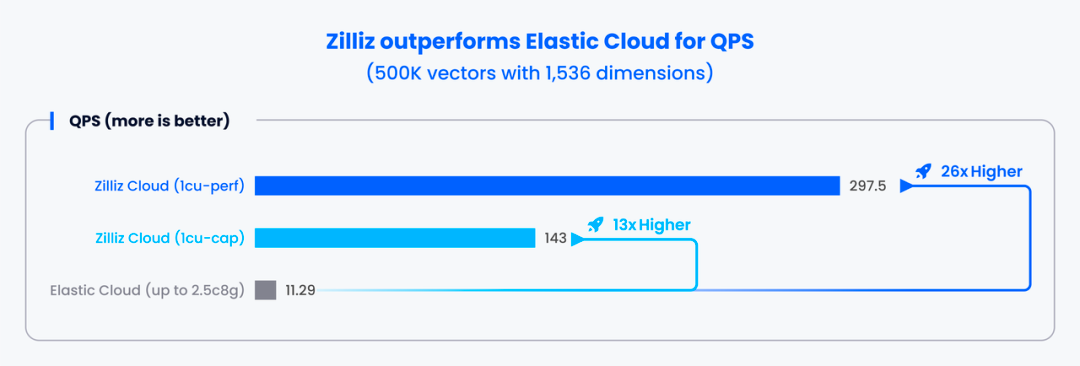
在 500,000 条 1,536 维的向量数据中进行检索时,Zilliz Cloud 两款实例的 QPS 分别是 Elastic Cloud 实例的 26 倍和 13 倍。
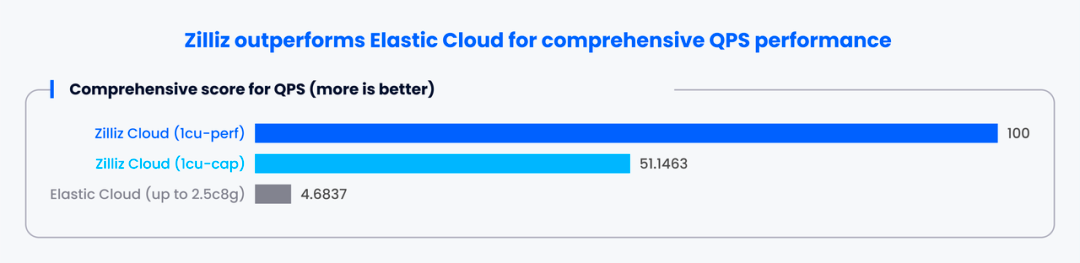
下图展示了各实例在不同用例下的性能评分(百分制)情况,分数越高,性能越强。具体的评分标准可以参考此处。
由此可以看出,Zilliz Cloud 在该指标上全面碾压 Elastic Cloud。
每美元查询次数(QP$)
在 1,000,000 条 768 维的向量数据中进行检索时,Zilliz Cloud 两款实例的 QP$ 分别是 Elastic Cloud 实例的 102 倍和 65 倍。
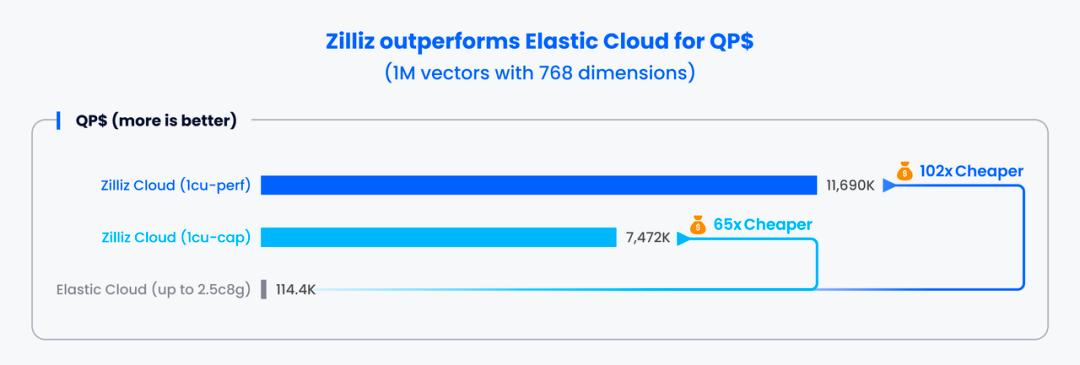
在 500,000 条 1,536 维的向量数据中进行检索时,Zilliz Cloud 两款实例的 QP$ 分别是 Elastic Cloud 实例的 79 倍和 38 倍。
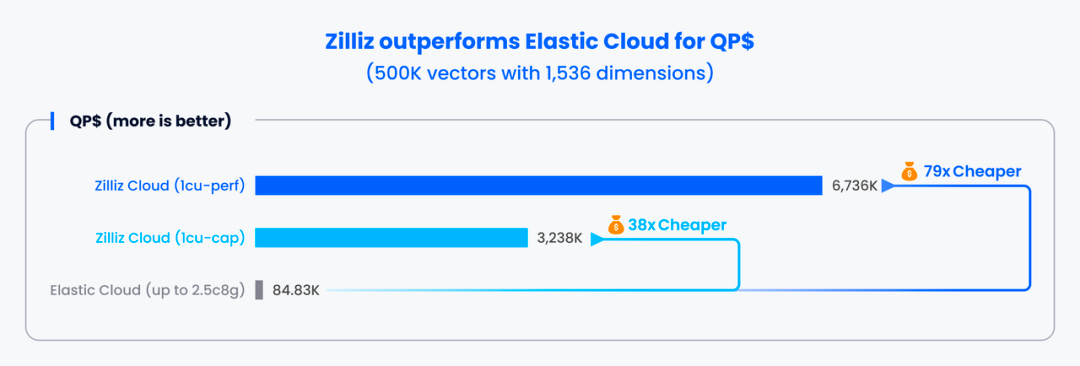
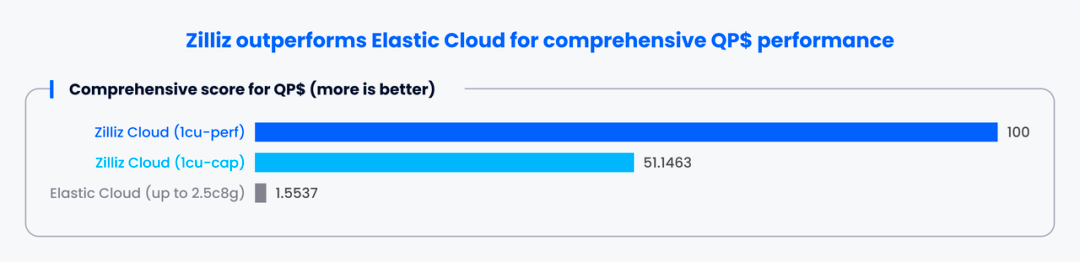
下图展示了各实例在不同用例(https://zilliz.com/vector-database-benchmark-tool#comparison-section)下的性能评分(百分制)情况,分数越高,性能越强。具体的评分标准(https://github.com/zilliztech/VectorDBBench/tree/main#leaderboard)可以参考此处。由此可以看出,Zilliz Cloud 在该指标上全面碾压 Elastic Cloud。
时延
在 1,000,000 条 768 维的向量数据中进行检索时,Zilliz Cloud 两款实例的 P99 时延分别是 Elastic Cloud 实例的 123 倍和 96 倍。

在 500,000 条 1,536 维的向量数据中进行检索时,Zilliz Cloud 两款实例的 P99 时延分别是 Elastic Cloud 实例的 502 倍和 108 倍。

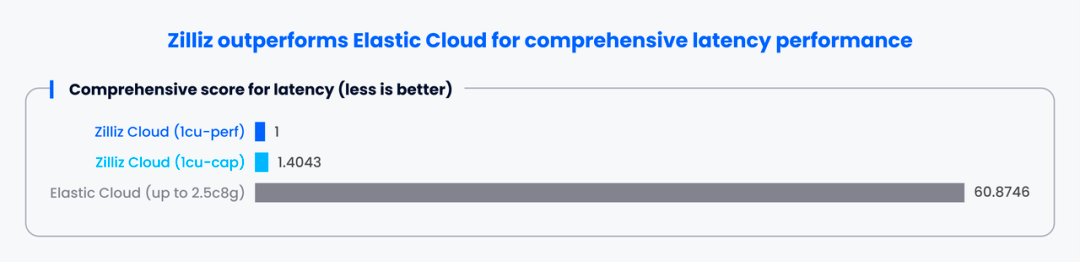
下图展示了各实例在不同用例下的性能评分(>1分制)情况,分数越接近 1,性能越强。
由此可以看出,Zilliz Cloud 在该指标上全面碾压 Elastic Cloud。
上述性能基准测试结果由开源的 VectorDBBench(https://github.com/zilliztech/VectorDBBench) 工具提供。在工具的 GitHub 主页上,还可以看到向量数据库的排行榜。
02.Elastic Cloud 特性对比
随着向量数据库可以存储的数据量呈几何级数的增长,性能也成为了向量数据库的重大挑战。为了保障数据检索性能,数据库的跨节点横向扩展能力至关重要。另外,数据插入速率、检索速率以及底层硬件的不同可能会衍生出不同的应用需求,这也让全局参数调节能力成为向量数据库的必备能力之一。
向量数据库为何而生
向量数据库是用来存储通过机器学习模型生成的非结构化数据的向量表示,为其创建索引,并在其中进行检索的一套全托管解决方案。它应该提供如下特性:
可扩展性和参数调节能力
多租户和数据隔离
完整的 API 套件
直观的用户界面和控制台
可扩展性
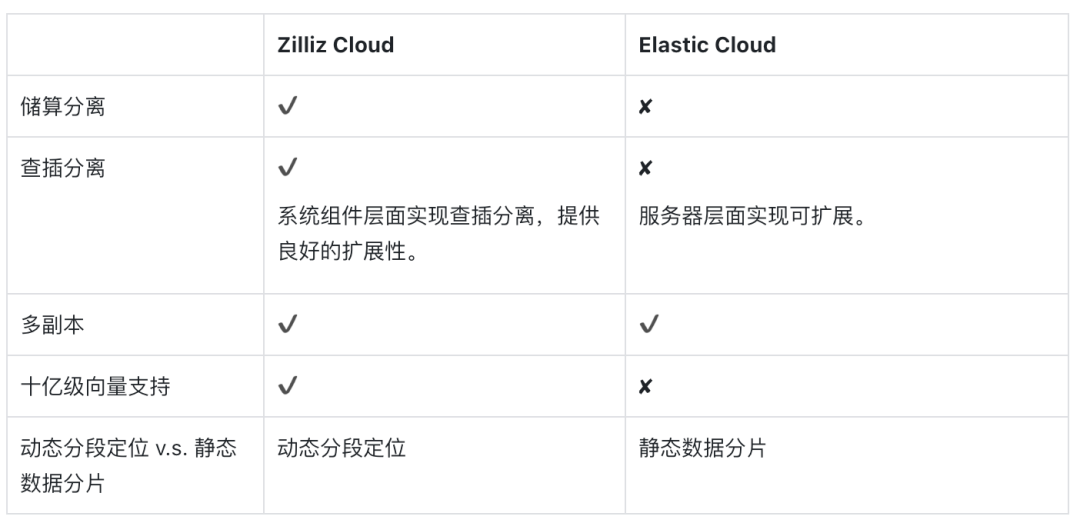
功能

专门打造

更多详情,请参见比较页面 https://zilliz.com/comparison/milvus-vs-elastic。
 Zilliz
Zilliz