



ETCD 损坏,没有备份,Milvus 数据还有救吗?
最近在 Milvus 社区里,我们帮一位用户处理了一个比较棘手的问题。
他的 Milvus 实例遇到了 ETCD 数据损坏。更麻烦的是,他没有保留原始数据,也没有提前使用 Milvus Backup 做备份,业务数据还不知道能不能拿回来。
这基本上是所有主流数据库能想象的最差的情况了。
但好在当时还有一个机会:MinIO 里的对象数据目录仍然存在。
基于这一背景,我们的数据恢复过程中,没有尝试直接“修好”旧 Milvus 实例,而是换了一条路:启动一套全新的 Milvus,重建 collection schema,再利用 Java SDK 的 bulkInsert 从旧 MinIO 里的 binlog 中把 segment 导入到新 collection。最终,这批数据被成功恢复。
这篇文章就是对这次社区救援过程的复盘。
(注意:这不是标准备份方案,也不是推荐的日常恢复方式。它更像最后一条救命绳:当 ETCD 已经损坏、没有原始数据、也没有 Milvus Backup 时,MinIO 中残留的 binlog 可能还能提供一次挽救数据的机会。
而且,这条路有代价的。MinIO 不是元数据真相源。它能告诉你“文件还在”,但不能可靠告诉你“哪些 segment 仍然有效”。所以恢复过程不能只看文件是否存在,还必须做数据校验,避免把历史 segment 或 compaction 前的 segment 重复导入。)
1. 社区紧急求助:ETCD 损坏后,collection 消失了
用户的 Milvus Standalone 实例原本运行正常,核心组件包括 Milvus、ETCD 和 MinIO。ETCD 负责保存 Milvus 的元数据,MinIO 负责保存对象数据,包括 insert log、stats log、index 文件等。
实验环境中,旧实例一开始是健康的:
cd /home/zilliz/mnt/lcl/260milvus
docker compose ps
输出示例:
Plaintext
NAME IMAGE SERVICE STATUS
milvus-etcd quay.io/coreos/etcd:v3.5.18 etcd Up
milvus-minio minio/minio:RELEASE.2024-12-18T13-15-44Z minio Up
milvus-standalone milvusdb/milvus:v2.6.17 standalone Up
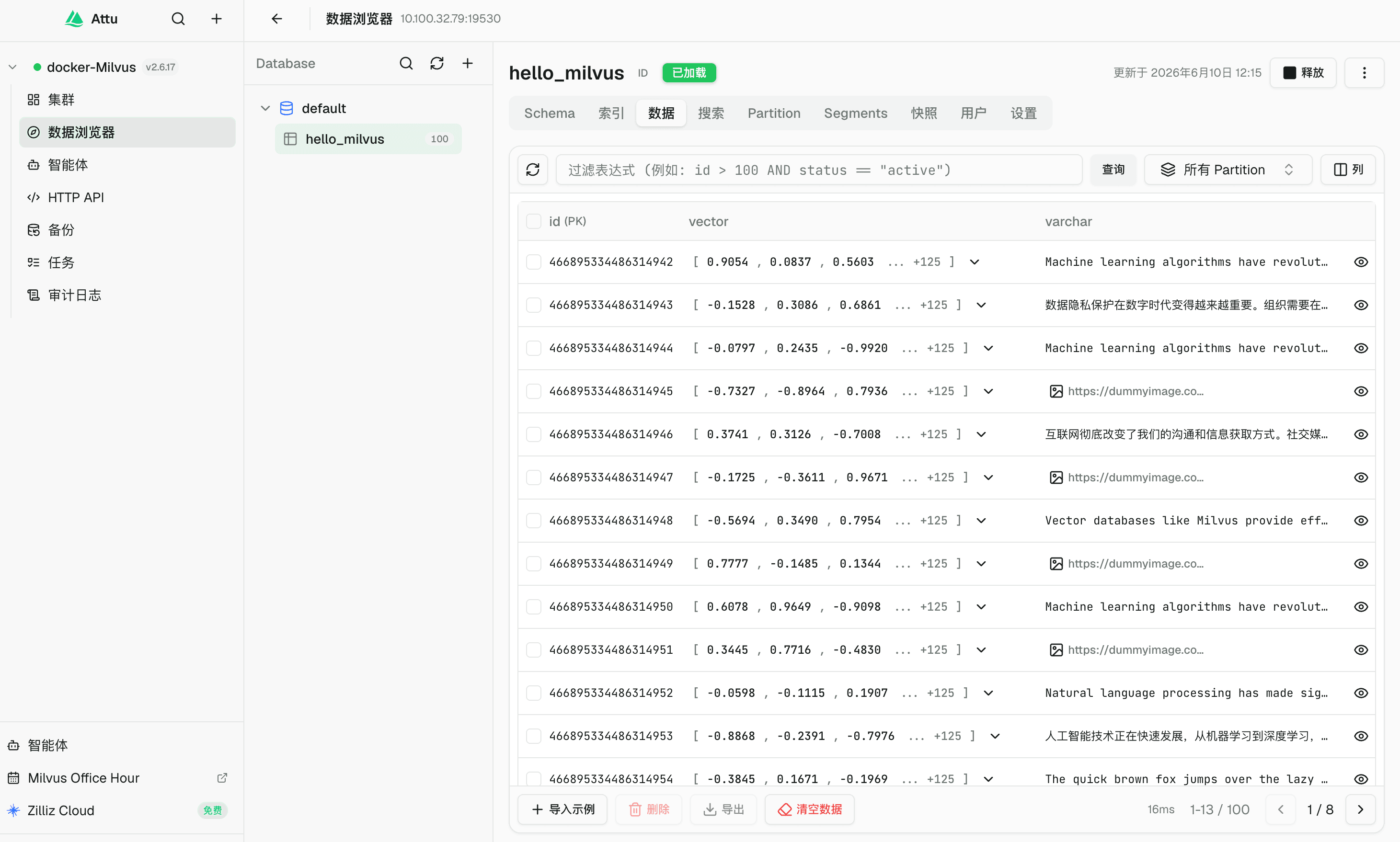
旧实例的 volumes 目录中包含三类数据:
Plaintext
etcd/
milvus/
minio/
为了复现社区用户遇到的问题,我们在实验中直接移走 ETCD 数据目录,模拟 ETCD 损坏:
cd /home/zilliz/mnt/lcl/260milvus/volumes
mv etcd ../etcd_old
这一步之后,Milvus 无法再从 ETCD 中读取 collection 元数据。Attu 中也看不到原来的 collection。
这就是问题的核心:ETCD 损坏后,业务数据文件并不一定丢了,但 Milvus 已经失去了理解这些文件的元数据。
换句话说,MinIO 里的数据可能还在,但 Milvus 不知道这些数据属于哪个 collection,不知道 schema 是什么,也不知道哪些 segment 仍然是有效数据。
2. 为什么 MinIO 还在,Milvus 却不能自动恢复?
要理解这个问题,先要分清 ETCD 和 MinIO 在 Milvus 里的职责。
ETCD 保存的是元数据,例如:
- database 信息
- collection 信息
- partition 信息
- schema
- segment id
- segment 状态
- 索引元数据
- compaction 后的新旧 segment 关系
MinIO 保存的是对象数据,例如:
- insert_log
- stats_log
- delta_log
- index 文件
- WAL 相关文件
正常情况下,Milvus 需要先从 ETCD 里知道有哪些 collection、每个 collection 的 schema、哪些 segment 当前有效,然后再去 MinIO 读取对应的对象文件。
如果 ETCD 完全不可读,MinIO 只能提供文件。它不能回答这些关键问题:
- 这个 collection id 对应哪个业务 collection?
- 这个 segment 是 live 还是 dropped?
- 这个 segment 是否已经被 compaction 替代?
- 这个 segment 是否来自旧实验或历史残留?
- field id 和业务字段的映射是否仍然可信?
所以,MinIO 里有文件,不等于 Milvus 能自动恢复 collection。
3. 恢复思路:不修旧实例,而是新建 Milvus 再导入旧 binlog
下图是这次恢复的整体思路:旧 ETCD 已经不可读,就不再尝试从旧 ETCD 中读取任何 key/value;可以旧 MinIO 中的 insert_log 和 stats_log 作为数据来源;新 Milvus 负责创建新的元数据和新的 segment。
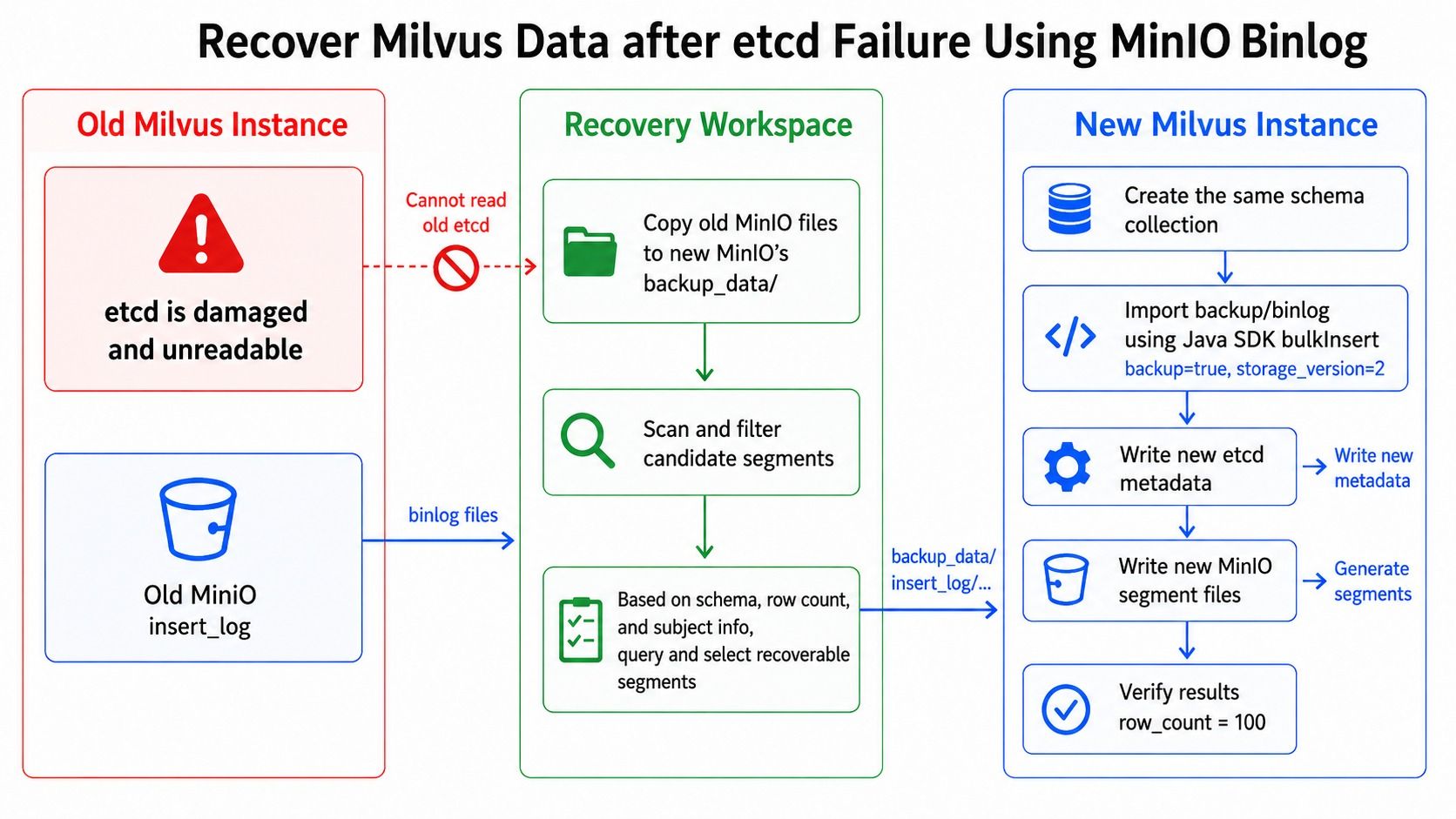
这次恢复没有继续在旧实例上反复尝试启动或覆盖目录。
原因很简单:如果旧实例状态已经不可靠,继续在原目录上操作,可能进一步破坏现场。更稳妥的做法是隔离旧数据,在新路径启动一套干净的 Milvus 实例。
整体流程如下:
- 保留旧 MinIO 数据目录。
- 不读取旧 ETCD。
- 在新路径启动一套空的 Milvus Standalone。
- 根据已有信息创建相同 schema 的新 collection。
- 将旧 MinIO 中的
insert_log和stats_log复制到新 MinIO 的backup_data/前缀下。 - 扫描候选 segment。
- 使用 Java SDK bulkInsert 导入候选 segment。
- 校验 row count、主键范围、抽样数据和向量检索结果。
- 只把确认后的 segment 导入正式恢复 collection。
在实验中,我们先启动一套新的 Milvus:
cd /home/zilliz/mnt/lcl/260milvus/new
docker compose up -d
输出示例:
Plaintext
[+] Running 3/3
✔ Container milvus-etcd Started
✔ Container milvus-minio Started
✔ Container milvus-standalone Started
接着准备新旧 MinIO 路径:
OLD_BUCKET=/home/zilliz/mnt/lcl/260milvus/volumes/minio/a-bucket/files
NEW_BUCKET=/home/zilliz/mnt/lcl/260milvus/new/volumes/minio/a-bucket/files
把旧 MinIO 文件复制到新 MinIO 的 backup_data 前缀:
mkdir -p "$NEW_BUCKET/backup_data"
rsync -a "$OLD_BUCKET/insert_log" "$NEW_BUCKET/backup_data/"
rsync -a "$OLD_BUCKET/stats_log" "$NEW_BUCKET/backup_data/"
复制后,新 Milvus 可以通过下面这种路径读取旧 binlog:
Plaintext
backup_data/insert_log/<old_collection_id>/<old_partition_id>/<old_segment_id>
backup_data/stats_log/<old_collection_id>/<old_partition_id>/<old_segment_id>
这里的关键是隔离。不要把旧对象文件直接混入新实例自己的数据路径。放到 backup_data/ 下,便于扫描、导入和回滚。
4. 创建相同 schema 的新 collection
旧 ETCD 已经不可读,所以新 Milvus 不知道原 collection 的 schema。恢复前必须人工创建一个 schema 兼容的新 collection,建表的 schema 一般在业务代码中都可以找到。
本次实验中,旧 collection 名为 hello_milvus,核心字段如下:
{
"collection_name": "hello_milvus",
"fields": [
{
"name": "id",
"data_type": 5,
"is_primary_key": true,
"autoID": true
},
{
"name": "vector",
"data_type": 101,
"dim": 128,
"indexes": [
{
"index_name": "vector",
"index_type": "AUTOINDEX",
"metric_type": "COSINE"
}
]
},
{
"name": "varchar",
"data_type": 21,
"max_length": 256
}
],
"enable_dynamic_field": false,
"consistency_level": "Bounded",
"shards_num": 1
}
在新 Milvus 中,我们创建一个 schema 一致的新 collection:
from pymilvus import MilvusClient, DataType
client = MilvusClient(uri="http://localhost:19530", db_name="default")
collection_name = "hello_milvus_recover"
if client.has_collection(collection_name):
client.drop_collection(collection_name)
schema = MilvusClient.create_schema(
auto_id=True,
enable_dynamic_field=False,
)
schema.add_field("id", DataType.INT64, is_primary=True, auto_id=True)
schema.add_field("vector", DataType.FLOAT_VECTOR, dim=128)
schema.add_field("varchar", DataType.VARCHAR, max_length=256)
index_params = MilvusClient.prepare_index_params()
index_params.add_index(
field_name="vector",
index_type="AUTOINDEX",
metric_type="COSINE",
)
client.create_collection(
collection_name=collection_name,
schema=schema,
index_params=index_params,
)
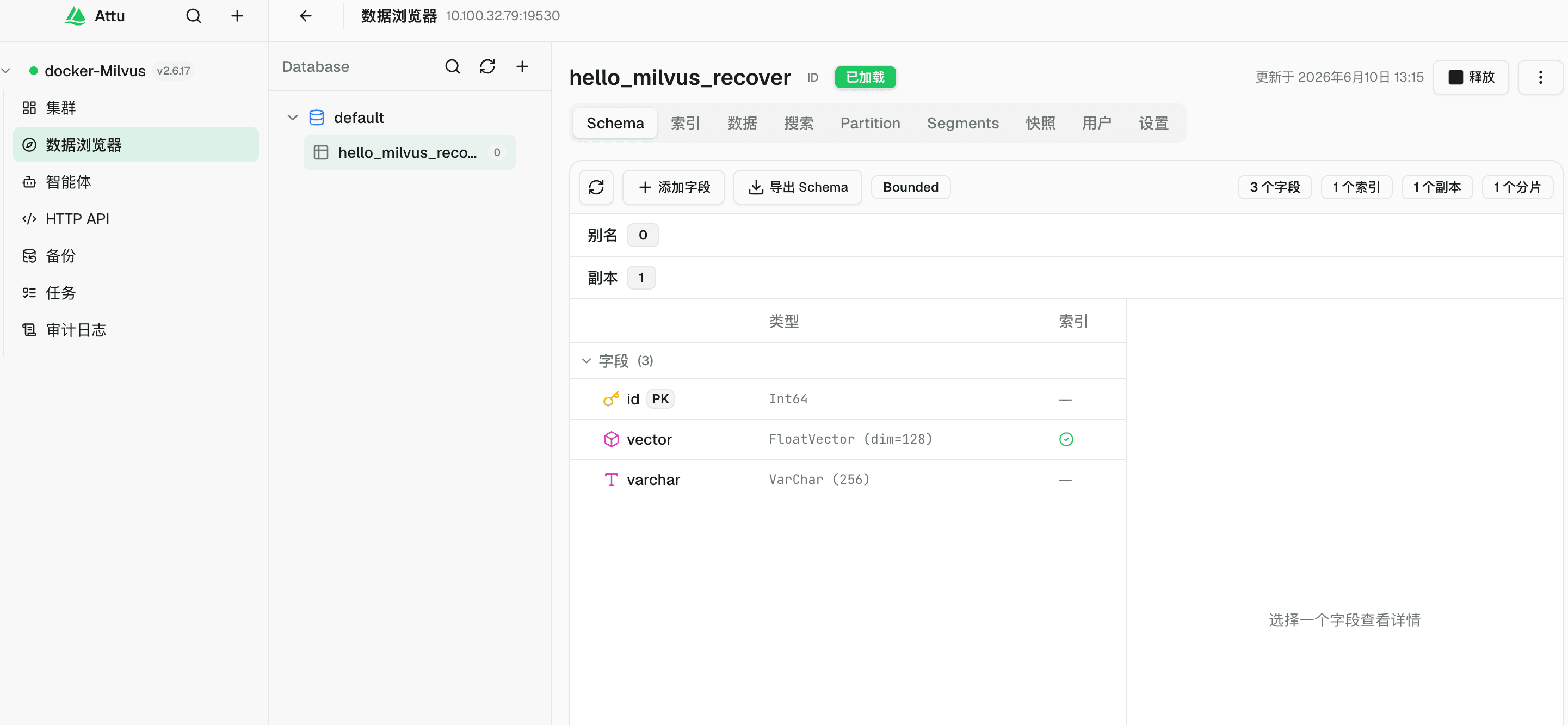
这里一定要注意:schema 必须和旧 binlog 兼容。
字段类型、向量维度、主键设置、动态字段配置如果不一致,导入可能失败。更糟糕的情况是导入成功,但数据解释不正确。
5. 扫描旧 MinIO 中的候选 segment
接下来扫描 backup_data/insert_log 下的旧 segment 路径:
NEW_BUCKET=/home/zilliz/mnt/lcl/260milvus/new/volumes/minio/a-bucket/files
find "$NEW_BUCKET/backup_data/insert_log" \
-mindepth 3 -maxdepth 3 -type d \
| sed "s#${NEW_BUCKET}/##" \
| sort
实验中扫描到两个候选 segment:
Plaintext
backup_data/insert_log/466895334486314780/466895334486314781/466895334486514943
backup_data/insert_log/466895334486314780/466895334486314781/466895334486515954
路径格式是:
Plaintext
backup_data/insert_log/<old_collection_id>/<old_partition_id>/<old_segment_id>
对应本次实验:
Plaintext
old collection id: 466895334486314780
old partition id: 466895334486314781
candidate segment 1: 466895334486514943
candidate segment 2: 466895334486515954
这一步只能说明 MinIO 中存在两个候选 segment 目录。它不能说明两个都应该恢复。
这句话很重要。后面出现的 200 行问题,就是因为两个 segment 都能成功导入,但它们并不一定代表两批不同的业务数据。
6. 使用 Java SDK bulkInsert 导入旧 segment
本文实验使用的是 Java SDK MilvusServiceClient.bulkInsert 来调用 backup=true 的 binlog 导入模式。核心接口是 bulkInsert,并设置几个关键参数:
Plaintext
backup=true
storage_version=2 #2.6 以后的版本使用的 storage v2,之前的版本是 v1
files=["backup_data/insert_log/.../<segment_id>"] #files 传的是 insert_log segment 路径
核心代码如下:
R<ImportResponse> importResp = client.bulkInsert(
BulkInsertParam.newBuilder()
.withDatabaseName(dbName)
.withCollectionName(collectionName)
.withPartitionName("_default")
.withOption("backup", "true")
.withOption("storage_version", storageVersion)
.withFiles(Collections.singletonList(segmentPath))
.build()
);
导入任务需要轮询状态,直到完成:
while (true) {
R<GetImportStateResponse> stateResp = client.getBulkInsertState(
GetBulkInsertStateParam.newBuilder()
.withTask(taskID)
.build()
);
ImportState state = stateResp.getData().getState();
System.out.println("Import state: " + state);
if (state == ImportState.ImportCompleted) {
break;
}
if (state == ImportState.ImportFailed ||
state == ImportState.ImportFailedAndCleaned) {
throw new RuntimeException("import failed: " + stateResp.getData());
}
Thread.sleep(1000);
}
Maven 依赖如下:
<dependency>
<groupId>io.milvus</groupId>
<artifactId>milvus-sdk-java</artifactId>
<version>3.0.1</version>
</dependency>
先导入第一个 segment:
cat > /tmp/import_paths.txt <<'EOF'
backup_data/insert_log/466895334486314780/466895334486314781/466895334486514943
EOF
执行导入:
cd /home/zilliz/mnt/lcl/260milvus/etcd_recovery/restore-java
DB_NAME=default \
COLLECTION_NAME="hello_milvus_recover" \
IMPORT_PATHS_FILE=/tmp/import_paths.txt \
STORAGE_VERSION=2 \
mvn -q exec:java \
-Dexec.mainClass=io.milvus.recovery.ImportIntoExistingCollection
输出结果:
Plaintext
Target collection: default.hello_milvus_recover
Segment paths: 1
Importing segment: backup_data/insert_log/466895334486314780/466895334486314781/466895334486514943
Import task ID: 466896649728034340
Import state: ImportPending
Import state: ImportStarted
Import state: ImportStarted
Import state: ImportStarted
Import state: ImportCompleted
collection statistics: [key: "row_count"
value: "100"
]
到这里看起来恢复成功了。row count 是 100,和原始 collection 一致。
但真正的问题出现在第二个 segment。
继续导入第二个 segment:
cat > /tmp/import_paths.txt <<'EOF'
backup_data/insert_log/466895334486314780/466895334486314781/466895334486515954
EOF
继续导入到同一个 collection:
DB_NAME=default \
COLLECTION_NAME="hello_milvus_recover" \
IMPORT_PATHS_FILE=/tmp/import_paths.txt \
STORAGE_VERSION=2 \
mvn -q exec:java \
-Dexec.mainClass=io.milvus.recovery.ImportIntoExistingCollection
输出结果:
Plaintext
Target collection: default.hello_milvus_recover
Segment paths: 1
Importing segment: backup_data/insert_log/466895334486314780/466895334486314781/466895334486515954
Import task ID: 466896649728083097
Import state: ImportPending
Import state: ImportStarted
Import state: ImportStarted
Import state: ImportCompleted
collection statistics: [key: "row_count"
value: "200"
]
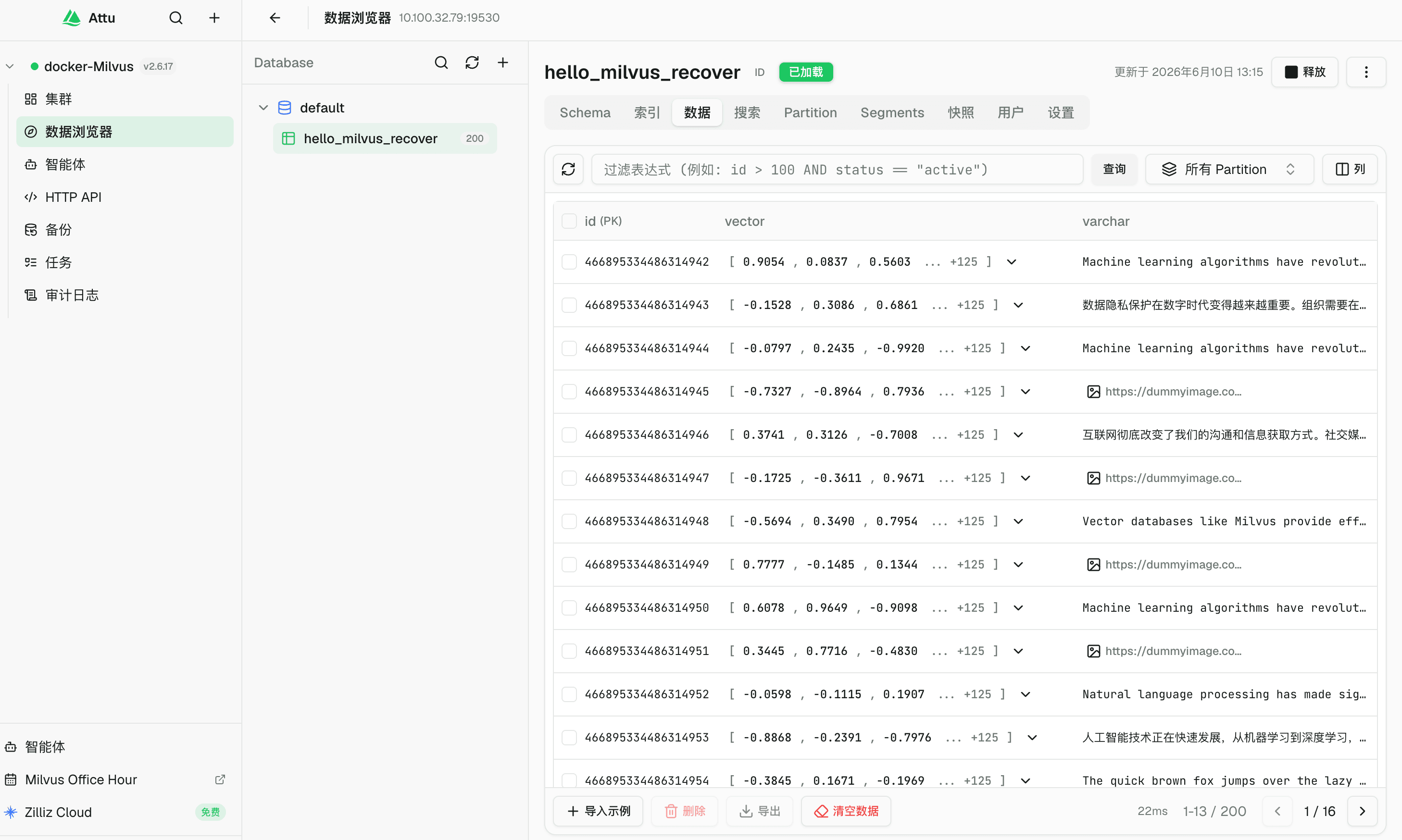
原始 collection 只有 100 行。为什么恢复后变成了 200 行?
7. 第一次踩坑:可读 segment 不等于 live segment
根因是:MinIO 中有两个 schema 兼容的 segment 目录,bulkInsert 把它们都成功导入了。但这两个 segment 很可能是同一批 100 行数据的两份物理形态。
这不是 bulkInsert 的 bug。
bulkInsert 的职责是导入你指定的 segment。只要路径合法、binlog 可读、schema 兼容,它就可以导入。它不会替你判断这个 segment 是当前有效数据,还是 compaction 前的历史形态。
进一步检查两个旧 segment 的文件结构:
for s in 466895334486514943 466895334486515954; do
echo "SEGMENT=$s"
find /home/zilliz/mnt/lcl/260milvus/volumes/minio/a-bucket/files/insert_log/466895334486314780/466895334486314781/$s \
-type f -printf '%TY-%Tm-%Td %TH:%TM:%TS %s %p\n' | sort
done
关键结果如下:
Plaintext
SEGMENT=466895334486514943
2026-06-10 12:15:36 1621 .../514943/0/.../part.1
2026-06-10 12:15:36 2960 .../514943/1/.../part.1
2026-06-10 12:15:36 47724 .../514943/101/.../part.1
SEGMENT=466895334486515954
2026-06-10 12:15:39 1621 .../515954/0/.../part.1
2026-06-10 12:15:39 2960 .../515954/1/.../part.1
2026-06-10 12:15:39 47724 .../515954/101/.../part.1
两个 segment 的特征非常接近:
- 字段目录一致:
0、1、101 - 文件大小一致:
1621、2960、47724 - 写入时间只差约 3 秒
这直接说明了它们不是两批不同业务数据,而是同一批数据在 Milvus 生命周期中的两个物理 segment。
所以,问题不是“哪个 segment 不能用”。问题是:两个都能用,但不应该都导入到正式恢复 collection。
这就是没有 ETCD 元数据时最大的风险。MinIO 能告诉你有哪些对象文件,但不能告诉你哪些 segment 是 live,哪些 segment 已经 dropped,哪些 segment 已经被 compaction 替代。
8. 如何校验:把候选 segment 分别导入不同 collection
这种情况下,不建议一口气把所有候选 segment 导入正式 collection。
更稳妥的做法是把候选 segment 分别导入不同的临时 collection,例如:
Plaintext
hello_milvus_recover_candidate_1
hello_milvus_recover_candidate_2
然后对比它们的数据是否一致。
可以从几个维度检查:
- row count 是否一致
- distinct primary key 数量是否一致
- 主键最小值和最大值是否一致
- 抽样字段是否一致
- 向量检索结果是否一致
- 是否存在重复主键
- 是否和业务侧记录一致
例如使用 PyMilvus 检查 row count、主键范围和 distinct id 数量:
from pymilvus import MilvusClient
client = MilvusClient(uri="http://localhost:19530", db_name="default")
for name in ["hello_milvus_recover", "hello_milvus_recover2"]:
print(name, client.get_collection_stats(name))
rows = client.query(
collection_name=name,
filter="id >= 0",
output_fields=["id", "varchar"],
limit=10000,
)
ids = [r["id"] for r in rows]
print(
"query_rows", len(rows),
"distinct_ids", len(set(ids)),
"min", min(ids),
"max", max(ids)
)
输出如下:
Plaintext
hello_milvus_recover {'row_count': 200}
query_rows 100 distinct_ids 100 min 466895334486314942 max 466895334486315041
hello_milvus_recover2 {'row_count': 100}
query_rows 100 distinct_ids 100 min 466895334486314942 max 466895334486315041
这个结果说明:hello_milvus_recover 的 row_count=200 是因为物理导入了两个 segment。但从查询结果、distinct id、主键范围看,两份 segment 对应的是同一批主键数据。
如果使用 Attu,也可以把两个候选 segment 分别导入两个临时 collection,然后直接对比数据样例、主键范围和行数。
这种校验很重要。没有 ETCD 时,恢复流程不能只依赖 MinIO 目录结构,必须依赖外部信息和数据对比来判断最终候选 segment。
9. 正确恢复:只导入确认后的 segment
在这次实验中,两个候选 segment 内容等价。本实验结合文件大小、写入时间、单独导入校验、主键范围和业务样本,最终选择较新的这个 segment 路径:
Plaintext
backup_data/insert_log/466895334486314780/466895334486314781/466895334486515954
我们新建了一个恢复 collection:
Plaintext
hello_milvus_recover2
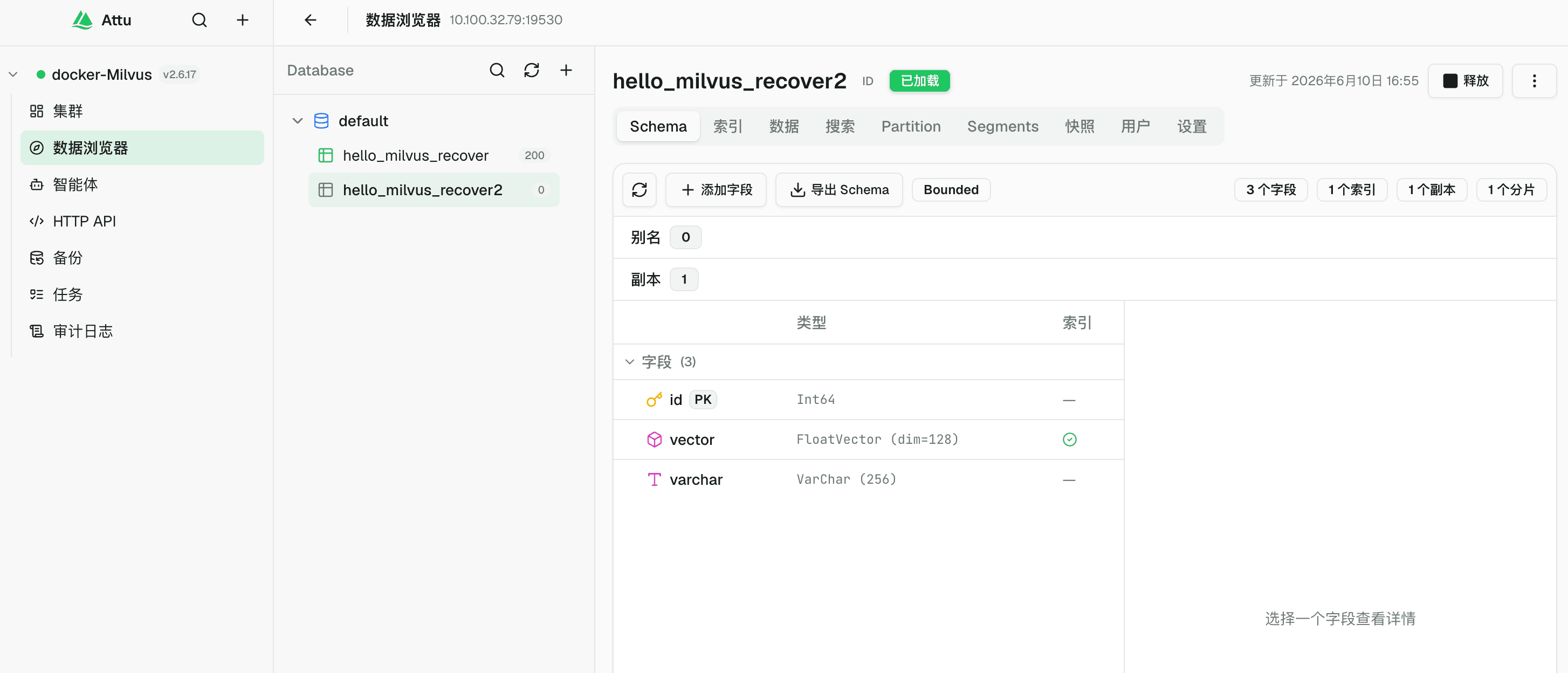
然后只导入这个较新的 segment:
cat > /tmp/import_paths.txt <<'EOF'
backup_data/insert_log/466895334486314780/466895334486314781/466895334486515954
EOF
cd /home/zilliz/mnt/lcl/260milvus/etcd_recovery/restore-java
DB_NAME=default \
COLLECTION_NAME="hello_milvus_recover2" \
IMPORT_PATHS_FILE=/tmp/import_paths.txt \
STORAGE_VERSION=2 \
mvn -q exec:java \
-Dexec.mainClass=io.milvus.recovery.ImportIntoExistingCollection
输出:
Plaintext
Target collection: default.hello_milvus_recover2
Segment paths: 1
Importing segment: backup_data/insert_log/466895334486314780/466895334486314781/466895334486515954
Import task ID: 466896649729193732
Import state: ImportPending
Import state: ImportStarted
Import state: ImportStarted
Import state: ImportCompleted
collection statistics: [key: "row_count"
value: "100"
]
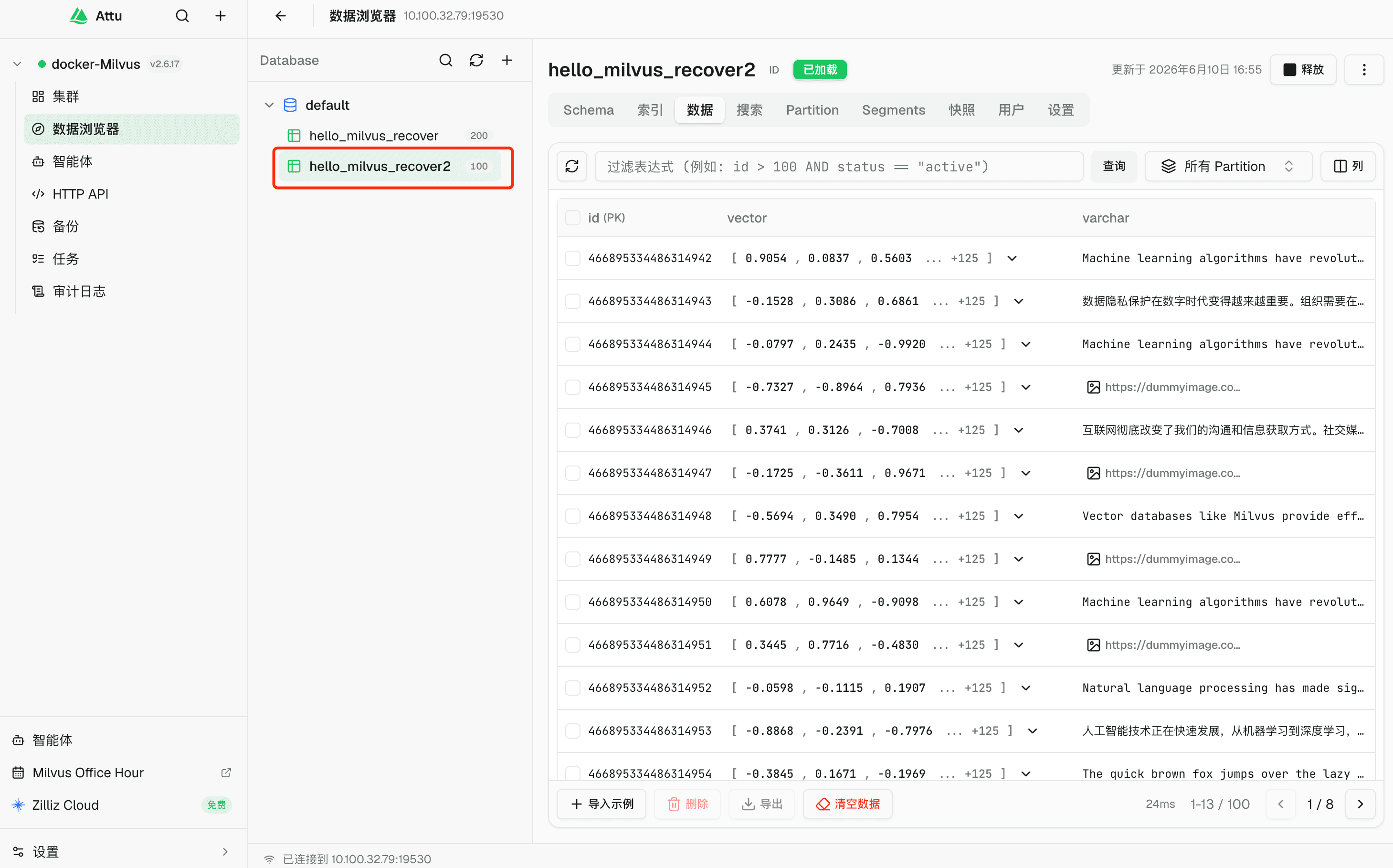
这次恢复结果和原始 collection 一致:100 行。
最终我们没有把 MinIO 中所有可读 segment 全部导入,而是先对候选 segment 做探测和校验,再把确认后的 segment 导入正式恢复 collection。
10. 这种方法有哪些局限?
这次案例能恢复成功,但它并不代表“ETCD 坏了,只要 MinIO 在就一定能完整恢复”。
这套方法有几个明确限制。
第一,无法仅凭 MinIO 判断 segment 是否 live。
MinIO 保存对象文件,但不保存完整的 segment 生命周期状态。segment 是否 live、是否 dropped、是否被 compaction 替代,原本要从 ETCD 元数据判断。
第二,可能出现重复导入。
这次 row count 从 100 变成 200,就是最直接的例子。如果把 compaction 前后的 segment 都导入,Milvus 会把它们登记为新 collection 中的 live segment,物理行数就会增加。
第三,必须知道原 collection schema。
如果 schema 完全丢失,恢复难度会大幅增加。字段类型、向量维度、主键配置、动态字段配置、字段 id 映射等信息都可能影响导入结果。
第四,delete 和 delta log 会让问题更复杂。
如果原 collection 有大量删除操作,仅导入 insert log 可能无法还原删除后的可见数据状态。是否需要处理 delta log,要结合具体数据和 Milvus 版本判断。
第五,多 collection、多 partition、多 database 会让人工判断成本上升。
这次实验只有一个 collection,数据量也很小,所以可以用 row count 和主键范围快速判断。真实生产环境中的 segment 数量可能很多,人工校验会复杂得多。
所以,这种方法只能作为最后兜底手段。它可以帮助你在极端情况下尽量救数据,但不能替代标准备份。
11. 经验总结:备份永远比抢救便宜
当 ETCD 已经损坏、没有原始数据、也没有 Milvus Backup 时,MinIO binlog 仍然可能提供最后一次挽救数据的机会。但这不是个常态化解决方案。整个过程你需要重建 schema,扫描 segment,逐个导入,反复校验,还要承担重复导入和数据不一致的风险。
更稳妥的做法,是不要让自己走到这一步。
如果你在生产环境中使用 Milvus,建议至少做好三件事。
第一,定期备份 ETCD。
ETCD 是 Milvus 的元数据中心。collection、schema、segment 状态等关键信息都依赖它。一旦 ETCD 损坏,恢复难度会明显上升。
第二,优先使用 Milvus Backup。
Milvus Backup 是更适合生产环境的备份恢复工具。它比事后从 MinIO 里手动判断 segment 更可靠,也更适合自动化和演练。
第三,如果是 Standalone 部署,定期备份完整 volumes 目录。
对于 Docker Compose 或单机 Standalone 部署,至少要备份完整 volumes 目录,包括:
Plaintext
volumes/
├── etcd/
├── milvus/
└── minio/
不要只备份 MinIO,也不要只备份 ETCD。Milvus 的完整恢复依赖元数据和对象数据同时可用。
当然,更直接可靠的方案,是直接选择ZillizCloud,把复杂的运维与安全交给我们,企业只需要关注应用与创新的速度。
 Jack Li
Jack Li

