



观点 | 从 Vector Database 到 Vector Lakebase,如何定义AI data infra的下一个十年
Zilliz 不做向量数据库了?
最近很多朋友和用户看到了 Zilliz 官网的新 slogan——Vector Lakebase for AI。不少人在问:Zilliz 是不是 pivot 了?是不是不做向量数据库了?
不是向量数据库不行了。恰恰相反,过去几年随着 AI 的发展,数据在增长,场景在分化,向量数据库的 adoption 也在快速增长,甚至超过我们九年前写下第一行代码时能想象到的影响力。
但企业对非结构化数据的需求正在远远超出"检索"这一个动作。Agent 正在从情报系统走向执行系统,向量数据库做对了很多事——它让开发者第一次可以用极低的门槛把语义检索集成到应用里。但当一个品类成功之后,伴随使用场景的拓宽,我们要用它解决的问题、对它的要求,也就会越来越高。
品类分化,也就成为了必然选择。
我最近在思考:过去十五年,移动互联网催生了数据库领域的三次范式转移,今天 AI 正在以几乎相同的节奏重走这条路,那么摸着移动互联网的石头过河,向量数据库之后又会发生什么变化?
摸着移动互联网的石头过河
2010 年前后移动互联网爆发,最先火的是 MongoDB。因为移动应用产生的数据天然是半结构化的——用户行为、社交动态、设备指纹——关系型数据库的 schema 设计跟不上业务迭代。MongoDB 解决的核心问题就四个字:先接住。不管格式是什么,先写进去再说。
几年后企业开始问下一个问题:这些数据能告诉我什么?于是,Snowflake、Redshift 崛起。数据仓库把业务数据沉淀下来做分析——BI 报表、用户画像、增长归因。数据从运营成本变成商业资产。
再后来,人们发现分析和在线之间的鸿沟太大了。数据在 OLTP 和 OLAP 之间反复搬运,ETL 管道脆弱又低效,经常一份数据被抄写三四次还对不上。于是,Lakehouse 出现——Databricks、Iceberg、Hudi 的核心主张是:一份数据,多种计算,不再搬运。
当然,这是后见之明。当时没人能预测下一步是什么——MongoDB 火的时候没人知道 Snowflake 会出现,Snowflake 火的时候 Lakehouse 还只是论文里的概念。
但回顾这三个阶段,我们可以发现,数据库的演化基本都遵从同一个逻辑:先承接流量,再挖掘价值,最后统一架构消除割裂。前阶段的成功制造了新阶段的结构性矛盾,新的矛盾催生下一个架构,历史如此循环往复,滚滚向前。

那AI 是不是正在走类似的路?
AI 时代:数据库演化的本质不变
2023 年大模型爆发,最先火的是向量数据库。原因和当年 MongoDB 一样:RAG 需要一个地方存 embedding、做语义检索,而大多数传统数据库在高维向量检索上缺乏原生支持。向量数据库解决的也是先接住——只是这次接住的是语义表示,是非结构化数据经过模型编码后的高维向量。
但现在三年多时间过去了。企业的问题变得越来越具体:几十亿条向量能不能做聚类分析?训练数据里的偏差和重复怎么发现?Agent 的历史对话和工具调用结果能不能做关联挖掘?
最近让我触动的一件事:越来越多的用户想对向量数据库里的数据做处理——去重、聚类、重新编码——但把 10 亿条数据从一张表导入到另一张表需要三天。三天。而头部 AI 公司的 researcher 迭代节奏是以小时计的,Data Engineer 疲于奔命,在清洗数据的路上一路狂奔,基础设施跟不上人的速度。
解决这些需求不再是给一个查询接口能解决的。它们需要交互式探索、批量处理、数据治理——和当年从 MongoDB 走向数据仓库的动力一模一样。
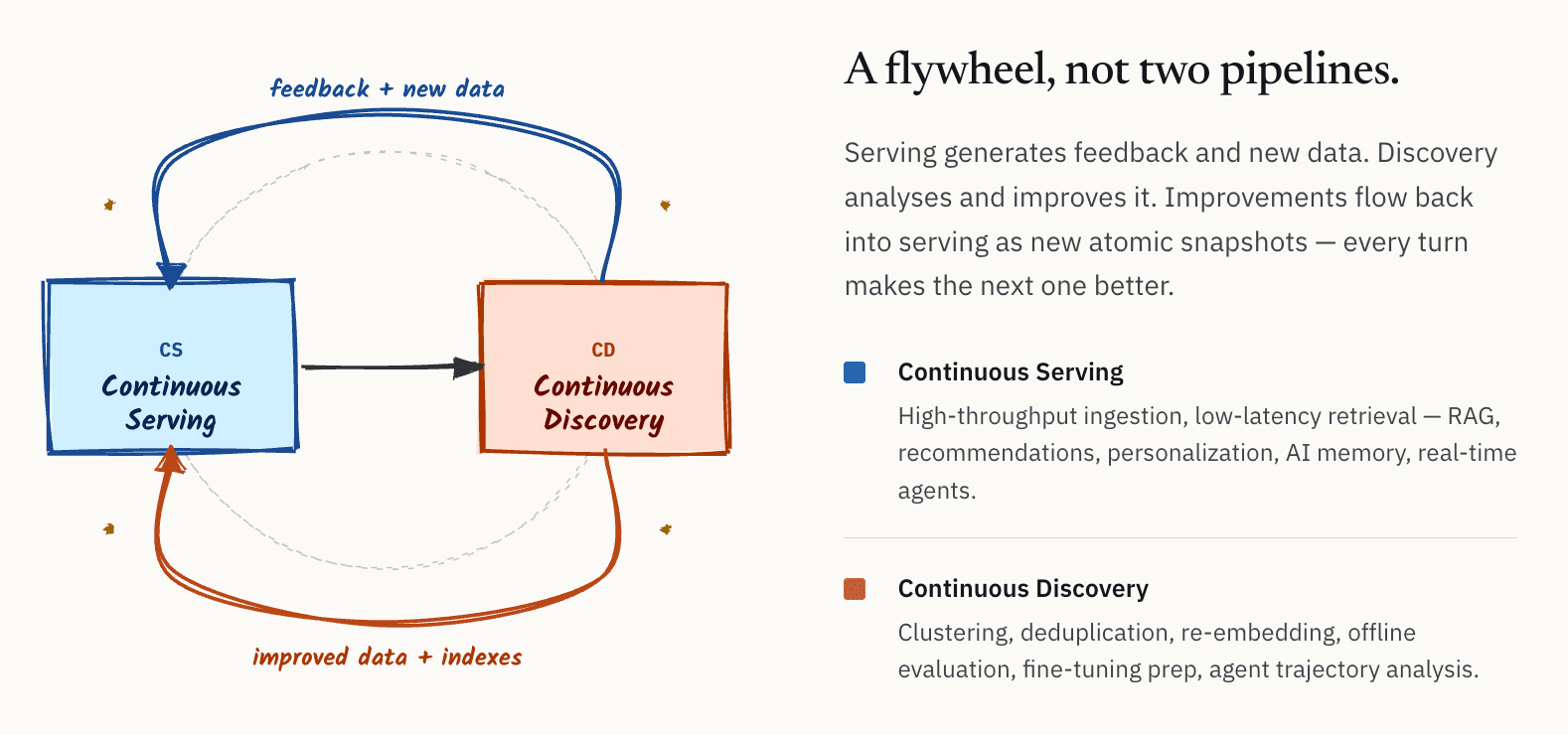
在这个过程中,非结构化数据真正需要的不只是检索系统。它是一个需要持续闭环的行动系统——我给它起了个名字:CS/CD,Continuous Serving + Continuous Discovery。
它既要支撑在线服务:大吞吐数据写入、高 QPS 查询,支撑 RAG 和 Agent 的实时需求。
也能服务持续发现:清洗数据、提取 embedding 和标签、做模型的后训练和 finetuning、分析 agent 运行轨迹、发现数据质量问题并修复。
关键在于——这两大服务不是独立工作流,而是一个飞轮。Serving 产生反馈,Discovery 改进质量,改进后的数据和索引再回到 Serving,循环往复。
Plaintext
CS/CD
Continuous Serving + Continuous Discovery
反馈 & 新数据
╭─────────────────────────╮
│ │
▼ │
┌─────────┐ ┌───────────┐
│Continuous│ │Continuous │
│ Serving │───────────▶│ Discovery │
└─────────┘ └───────────┘
▲ │
│ │
╰─────────────────────────╯
改进后的数据 & 索引
但依赖已有的infra,这个飞轮转不起来。
因为想做离线处理,先得把数据从向量数据库导出到数据湖——十亿条向量,光搬运就要几天,增量同步没有现成方案,每次都是全量重导。搬完之后,处理成本也高得离谱:没有向量索引,聚类和去重只能暴力扫描;处理完想写回线上系统,又没有原子性保证,要么再全量导一次,要么忍受新旧数据不一致。整个链路又慢又贵又脆弱,结果就是大多数团队根本不做——数据躺在那里,没有人去挖掘价值,Discovery 到 Serving 的回馈路径从未真正形成。
这和当年 OLTP/OLAP 之间的鸿沟如出一辙——只是这次割裂的是在线语义检索和离线数据处理。
为什么我认为现有 Infra 都不够
向量数据库的边界
以 Milvus 为例——它解决了向量检索的水平扩展,但当需求超出在线检索时:依然要求数据必须全量加载才能查询,要么全在线要么不可查,冷数据处理成本极高;此外,典型的向量数据库结构,很难完成数据处理类负载,十亿条向量没法做分布式聚类,海量数据没法去重;企业的非结构化数据往往已经在湖里了,全量导入意味着搬迁成本和治理割裂。
当然,这些不是 bug,是架构边界导致的。向量数据库本来就是为在线检索设计的。它已经做好了自己该做的事。
Lakehouse 的边界
另一些团队选择从 Lakehouse 侧切入。存储成本和批量处理解决了,但也有硬伤:Lakehouse 的核心抽象是为结构化数据设计的,向量在里面只是一个很长的 float 数组,没有语义层面的理解;Parquet 文件没有 HNSW、没有 IVF、没有倒排索引。
比如,我们有制药客户做分子结构匹配——用 Spark 全表扫描,换成基于 IVF 和倒排索引的检索后,性能差 1000 倍。没有合适的索引,数据湖上的非结构化数据检索就只能靠暴力扫描。而对于需要低延迟点查的向量工作负载,通用列式格式还会带来严重的远端 I/O 放大——后文会给出我们的测试数字。RAG 需要的 P99 < 100ms 响应,这条路走不通。
所以我的判断是:两条路各自有道理,但都只解决了一半。
因此,我们全新推出的Vector Lakebase 的核心主张是:你不需要在在线检索和大规模处理之间二选一,也不需要用管道缝起来。一个架构,一份数据,就能支撑多种计算模式。
Vector Lakebase 架构解读:一份数据,三种计算
Vector Lakebase"一份数据,多种计算"的概念很好理解。但怎么让它成立?
我的思考方式是:先想清楚什么是"身子"(统一数据层),再想"三个头"(Long-running、On-demand、Offline Batch 三种计算模式)怎么长上去。
Plaintext
┌─────────────────────────────────────────────────────────────────┐
│ Catalog Service │
│ (全局元数据,集群缩容至 0 仍可见) │
├─────────────────────────────────────────────────────────────────┤
│ 弹性资源调度层 │
│ (秒级拉起 · Warm Pool · 分钟级计费) │
├─────────────────────────────────────────────────────────────────┤
│ 三种计算模式 │
│ ┌──────────────┬───────────────┬───────────────────────┐ │
│ │ Long-running │ On-demand │ Offline Batch │ │
│ │ 在线服务 │ 按需交互 │ 批量处理 │ │
│ └──────────────┴───────────────┴───────────────────────┘ │
├─────────────────────────────────────────────────────────────────┤
│ 索引层 (面向 S3 优化) + GPU Index Pool │
│ IVF 向量索引 · BM25 倒排 · JSON 索引 │
├─────────────────────────────────────────────────────────────────┤
│ Loon 存储引擎 + External Collection │
│ Mixed File Formats · Row Alignment · Manifest 版本化 │
│ Lance · Iceberg · Parquet · Vortex → 零拷贝逻辑映射 │
├─────────────────────────────────────────────────────────────────┤
│ S3 / 对象存储 │
└─────────────────────────────────────────────────────────────────┘
身子:统一数据层
CS/CD 飞轮要转得起来,第一个硬约束是:不同计算模式不能各自维护一份业务数据副本。
Serving 和 Discovery 必须围绕同一份逻辑数据资产工作——对于原生数据(用户向量、文档、日志、元数据、索引),由 Lakebase 统一管理在对象存储底座上;对于已有的湖表数据,则通过 External Collection 管理映射、索引和版本引用,原始数据保留在现有平台。无论哪种路径,计算模式看到的都是同一个逻辑视图。原因很简单:只要数据分散在两个系统里,飞轮每转一圈就要搬运一次,搬运就有延迟、有不一致、有成本。飞轮频率越高,搬运的税就越重,直到这个税吃掉了飞轮本身的收益。
统一数据层意味着系统必须存算分离——数据在 S3 上,计算是无状态的、可以独立伸缩直至归零。因为Serving 和 Discovery 的资源需求波动极大,如果数据绑在计算节点上,要么 Serving 为 Discovery 买单(常驻过多资源),要么 Discovery 被 Serving 的 SLA 卡死(不敢动热数据)。
存算分离的代价:冷查询和 I/O 放大
但存算分离不是免费的。对于缩容到零的 On-demand 和 Offline 模式,首次查询面对的是纯冷数据——计算节点本地什么都没有,所有数据都要从 S3 拉取。这带来两个硬伤:
第一,冷启动太慢。 10 亿条 768 维向量的 HNSW 索引大约 340GB,从 S3 全量拉取超过 4 分钟。没有人愿意等 4 分钟才能开始搜索。
我们的解法是把索引压到足够小。基于 RaBitQ 的 1+3 bit 量化把 340GB 压缩到 13GB,分两阶段检索:第一阶段用 1-bit 做粗筛(召回 85-90%,数据量只有原始的三十分之一),第二阶段用 1+3 bit 重排精修到 95% 召回。冷启动从分钟级压到 5-10 秒。再配合 IVF 聚类剪枝,每次查询实际只扫描约 3% 的数据——340GB → 13GB → 单次查询约 400MB。
第二,S3 的 I/O 放大。 向量搜索返回的是 ID,但业务要的是完整记录。标准 Parquet 的 64MB row group 意味着读 3KB 的记录要下载 64MB——I/O 浪费接近 20000 倍。缩小 row group?Parquet 的块级压缩依赖大 row group,缩小了压缩率骤降。
这就是为什么必须重新设计存储格式。我们做了 Loon——混合文件格式 + 行对齐 + Manifest 版本化。标量字段用列存(适合过滤和扫描),向量字段用点查友好的 layout,通过 ColumnGroup 对齐行号。底层文件格式选择了 Vortex(Linux Foundation 开源项目),支持灵活 layout 和嵌套编码,可以在不解压的前提下做 point query。
实测(3M 行、128 维、S3、256 并发 reader):Parquet point read 下载 9.4MB/次,Vortex 只需 0.07MB/次——减少 135 倍,全扫描吞吐也更高。Loon 是开放格式,Spark、Ray、Daft 可以直接读——同一份数据既能被在线系统毫秒级查询,也能被 Spark job 批量扫描。飞轮两侧不需要维护两份数据拷贝。
三个头:三种计算模式
身子统一了,上面三种计算模式各自承担飞轮的不同角色:
Long-running(常驻在线服务)——集群常驻,索引和热数据预加载到内存和本地磁盘,毫秒级响应。这是 CS/CD 飞轮 Serving 侧的主力——RAG、实时推荐、在线 Agent。纯 S3 延迟撑不住 P99 < 100ms,所以 Long-running 的核心是多层缓存:内存 → 本地磁盘 → 预热节点池逐层兜底,让热数据的查询体验和传统数据库一致。
On-demand(按需交互计算)——秒级冷启动,分钟级计费。这是飞轮 Discovery 侧的交互入口——相似度探索、异常样本检查、ML 工程师看 embedding 分布、偶发的冷数据检索。不需要 7x24 集群,用时有资源,不用不花钱。
Offline Batch(批量处理)——向量聚类、训练数据去重、全量重编码、索引重建、数据质量扫描。资源按任务分配,完成即释放。这是飞轮从 Discovery 回到 Serving 的执行层——处理完的数据和新索引由 Catalog 以 snapshot 为单位发布,Serving 在新版本完整就绪前继续读取旧 snapshot,切换时数据与索引一起生效,不会暴露中间状态。
三种模式确定之后,接下来要考虑的就是怎么做极致的资源调度。 传统数据库调度器的思路是"我有这么多节点,把数据分配过去"——优化目标是在固定资源池里做负载均衡。但 Agent 时代的 workload 天然是突发性的,固定资源池下再怎么 balance,也不能覆盖所有可能。正确的做法是系统不只调度数据,也调度资源——资源决策和数据决策必须是统一决策。
具体做法是维护 Warm Pool(预热节点池),节点提前准备好,收到请求后秒级挂载数据开始服务,请求结束后短暂等待再回收。计费是分钟级粒度:不是 Serverless 的按请求收费(隐含风险溢价),不是 Dedicated 的按月包年(隐含空闲浪费),而是用多久付多久。
这背后是一个更大的架构转变——从传统的管控面驱动内核,转向内核自主调度资源。关于这个话题,我们会单独写文章聊聊对下一代云数据库架构的思考。
以下是我们一个自动驾驶客户使用Vector Lakebase之后的成本结构变化,10 亿条 768 维向量,每天实际只有 20 分钟在线查询——Long-running 模式月成本 7,000,切到 On-demand 降到 500。同一个客户,之前用 ANN 逐条搜索做向量去重,仅向量检索就消耗 70 小时;改用 Offline Batch 提供的批量去重能力,相同资源下计算时间降到 10 小时。
已有数据的接入:External Collection
架构定好之后,在真实生产场景,往往还面临一个现实约束:企业的非结构化数据往往已经在湖里了——Lance 表、Iceberg 表、大量 Parquet 文件。让他们全部搬进来不现实。
所以我们推出了External Collection ,它不只是零拷贝的逻辑映射——它在外部数据之上建立了独立的索引层。原始数据仍由现有平台管理,但系统会在这些数据上构建 IVF、倒排、JSON 索引,让它们具备和原生数据相同的检索能力。核心主张是 One Data, One Index:无论数据物理上存在哪里,都通过同一套索引体系被统一管理和检索,不搬迁、不双写。
这意味着飞轮不只转自己的数据,也能把湖里已有的数据纳入 CS/CD 循环——Discovery 可以覆盖全量数据资产,不止是已经导入系统的那部分。
定义初代 Vector Lakebase中,我们的经验
Vector Lakebase建设的过程中,我们也踩了不少坑,也逐渐对这个东西到底该长什么样形成了一些比较确定的工程判断。
第一,存算分离 + 多层缓存。 数据在 S3,计算独立扩缩容直至完全释放。但光有分离不够——纯远端存储延迟撑不住在线检索,必须配合多层缓存(内存、本地磁盘、预热节点池)把热数据访问延迟压到毫秒级。存算分离解决成本弹性,缓存解决性能弹性,缺一不可。
第二,统一的多模态非结构化数据管理。 不只是向量,还有原始文档、图片、音频、视频的 embedding 及标量元数据。只能存向量而不能管理背后原始数据和元信息的系统,只是索引服务,不是数据底座。
第三,原生向量数据库能力。 毫秒级 ANN、向量索引管理、混合查询(向量 + 标量过滤 + 全文检索)、多种相似度度量——这些必须是系统原生能力,不是对接外部向量数据库的集成方案。
第四,多种计算模式。 在线检索、按需交互、离线批处理,至少覆盖三种。按需交互是在线和离线之间的桥梁,也是 Discovery 侧的核心入口。
第五,开放格式,数据不锁定。 存储格式能被 Spark、Ray、Daft 等外部引擎直接读,湖里已有的 Iceberg 表和 Parquet 文件可以零拷贝映射进来。数据所有权属于用户,不属于引擎。
第六,资源跟着数据走,不用不花钱。 计算可以释放到零,元数据始终可见可查。有请求时秒级拉起,空闲租户不承担独占计算成本,只保留对象存储和共享 Catalog 的开销。这不是自动扩缩容——它要求资源决策和数据决策统一在引擎内部,系统自己就是资源的调度者。
这六条是我们今天的认知,不是终态。未来一定还会修正。但有一个第一性原理的判断我比较确信:数据一定会越来越大,而预算不会无限扩张。工程师在优化成本的路上只会越走越远,不会回头。
尾声
回到开头那个问题:Zilliz 是不是不做向量数据库了?
现在你应该能看到我的答案了。向量数据库没有消失——它是 CS/CD 飞轮 Serving 侧的引擎,是整个系统里响应最快、离用户最近的那一层。就像 OLTP 没有被 Lakehouse 取代,它变成了更大数据架构的在线层。向量数据库也是一样:它不是被替代了,而是被放进了一个更大的蓝图里。
这个蓝图就是 CS/CD。Serving 产生数据和反馈,Discovery 从中发现问题、改进质量,改进后的数据和索引原子性地回到 Serving——飞轮每转一圈,系统就比上一圈更懂你的数据。前面所有的架构决策——冷启动压缩、IVF 剪枝、Loon 存储格式、控制面瘦身——都是为了让这个飞轮转得起来、转得经济、转得快。每一个都是飞轮上的一个轴承,少一个都会卡住。
我不确定 Vector Lakebase 五年后会长成什么样。九年前写下 Milvus 第一行代码时,我们也想不到向量数据库会变成今天这个形态。但我们坚定地押注一个方向:非结构化数据需要自己的 CS/CD 闭环,谁先让这个飞轮真正转起来,谁就定义了这个领域的下一个十年。 我们决定做那个让飞轮转起来的人。
本文中的性能与成本数字来自开源VectorDB Benchmark,内部测试及匿名无人驾驶客户场景,结果受数据规模、分布、索引参数和资源配置影响。
 James Luan
James LuanJames Luan is Co-Founder & CTO of Zilliz.


