使用Ruby和Milvus构建端到端的GenAI应用
引入了像LangChain这样的专业GenAI框架,使我们能够通过利用功能强大的大型语言模型(LLMs)如ChatGPT和LLaMA,快速轻松地构建复杂的AI应用。例如,LangChain允许我们在几行代码中创建一个强大的检索增强生成(RAG)应用,而不需要深厚的理论AI知识。
这种趋势意味着,如今,数据科学家和机器学习工程师不再是唯一能够构建GenAI应用的人。全栈工程师或软件开发人员现在可以使用LangChain构建GenAI应用。
然而,这些GenAI框架通常用Python编写,我们知道一些全栈工程师和软件开发人员很少在他们的项目中使用Python。因此,需要将这些GenAI框架扩展到其他编程语言,以便这些全栈工程师可以利用功能强大的LLMs在他们的软件项目中构建GenAI应用。 在最近的一次演讲中,Source Labs LLC的解决方案架构师Andrei Bondarev介绍了一个名为LangChain.rb的LangChain的Ruby扩展,以使全栈工程师更容易在他们的软件项目中构建GenAI应用。
但在我们讨论如何用Ruby构建GenAI应用之前,让我们简要探索检索增强生成(RAG)的内部工作原理,这是GenAI的一个流行用例。
RAG的工作原理
众所周知,数据是任何GenAI应用的金矿。它作为GenAI用于生成事实和准确响应的信息源。在目前可用的所有数据中,80%可以被归类为非结构化数据。
非结构化数据指的是不符合预定义数据格式的数据。这类数据包括图像、文本、声音和视频。为了让机器理解这些非结构化数据类型,我们需要将它们转换成称为向量嵌入的数值格式。
向量嵌入的基本概念
嵌入由一个n维向量组成,其中n指的是嵌入的维度。维度取决于将数据转换成嵌入的深度学习模型。嵌入携带了它所代表数据的语义含义。
我们可以使用深度学习模型将各种数据模态转换成嵌入。例如,如果我们有文本数据,我们可以使用OpenAI或Sentence Transformer模型将这些文本数据转换成嵌入。如果我们有图像数据,我们可以使用专门预训练的模型来提取图像特征,如视觉变换器,作为嵌入模型。
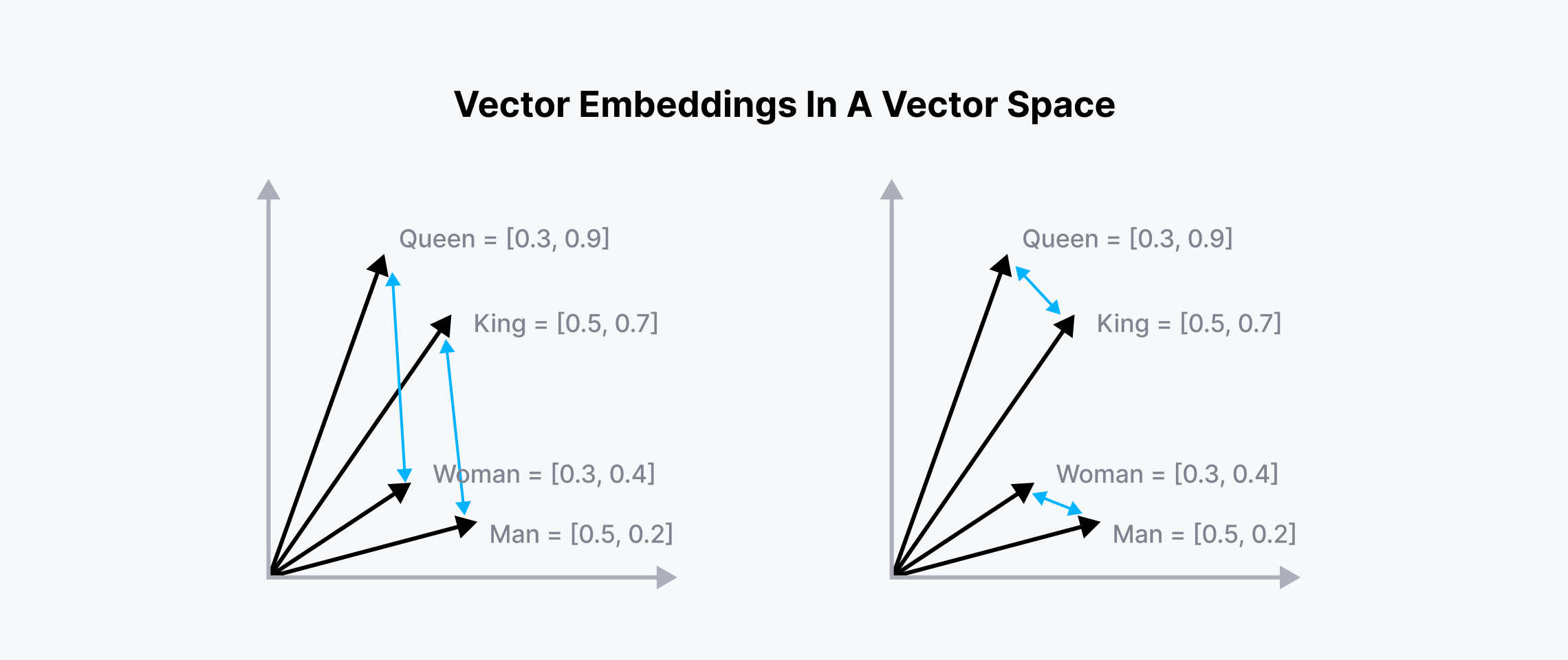
由于嵌入携带了它所代表数据的语义含义,我们可以计算该嵌入与所谓的向量空间中其他嵌入的相似性。语义含义相似的嵌入将被放置在向量空间的彼此附近,如下所示的可视化:
 Vector_embeddings_in_a_vector_space_d7db1f957b.png
Vector_embeddings_in_a_vector_space_d7db1f957b.png
向量空间中相关词的嵌入
如上图所示,“女王”和“国王”的嵌入被放置在一起,同样“女人”和“男人”也是如此。“女王-国王”和“女人-男人”之间的欧几里得距离也大致相同,因为它们携带了相似的含义。
这个概念是向量搜索操作的基础,我们计算一个嵌入与多个嵌入之间的相似性。
向量数据库在向量搜索和RAG应用中的作用
如果我们只处理少量嵌入,实现向量搜索是直接的。然而,在现实世界中,我们通常需要处理成千上万、甚至数十亿的嵌入。因此,我们需要一个解决方案来有效地存储嵌入并对其进行快速的向量搜索。
这就是像Milvus这样的向量数据库发挥作用的地方。Milvus是一个开源向量数据库,您可以在其中存储大量的嵌入,并在这些嵌入上执行向量搜索。
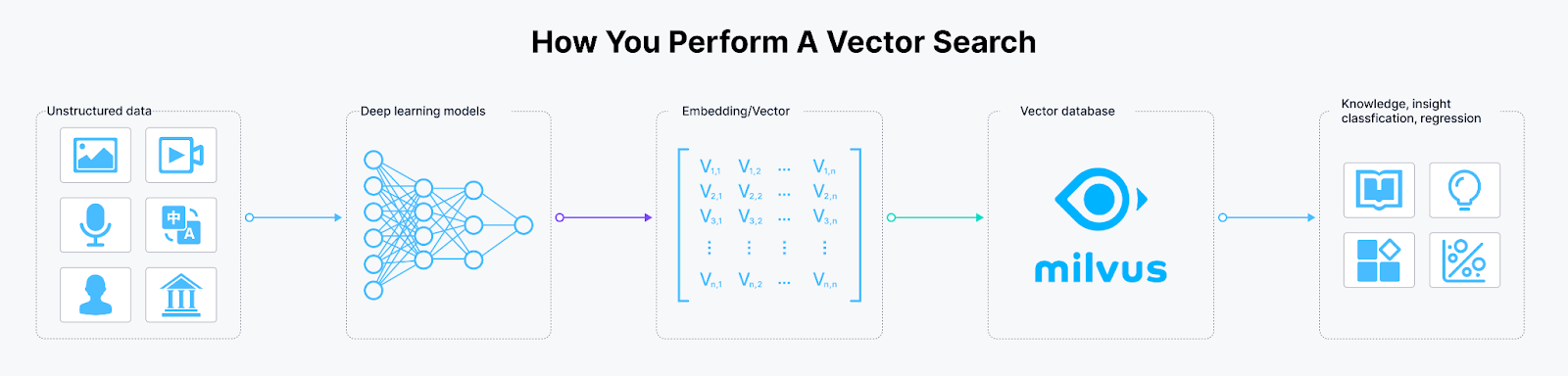 The_workflow_of_transforming_unstructured_data_into_embeddings_and_storing_them_in_Milvus_1801c9b122.png
The_workflow_of_transforming_unstructured_data_into_embeddings_and_storing_them_in_Milvus_1801c9b122.png
将非结构化数据转换为嵌入并存储在Milvus中的工作流程
向量数据库在流行的GenAI应用如RAG中也扮演着关键角色。正如您可能已经知道的,RAG的主要目标是通过提供有助于回答用户查询的上下文,来提高由LLMs如ChatGPT和LLaMA生成的响应的准确性。
在一个RAG应用中,一旦接收到用户的查询,它就会使用嵌入模型转换成嵌入。接下来执行向量搜索,其中查询嵌入与存储在向量数据库如Milvus中的上下文嵌入进行比较。然后获取最相似的上下文数据,并将其实现在查询一起传递给LLM。然后LLM可以使用上下文中的信息生成上下文化的响应来回答用户的查询。
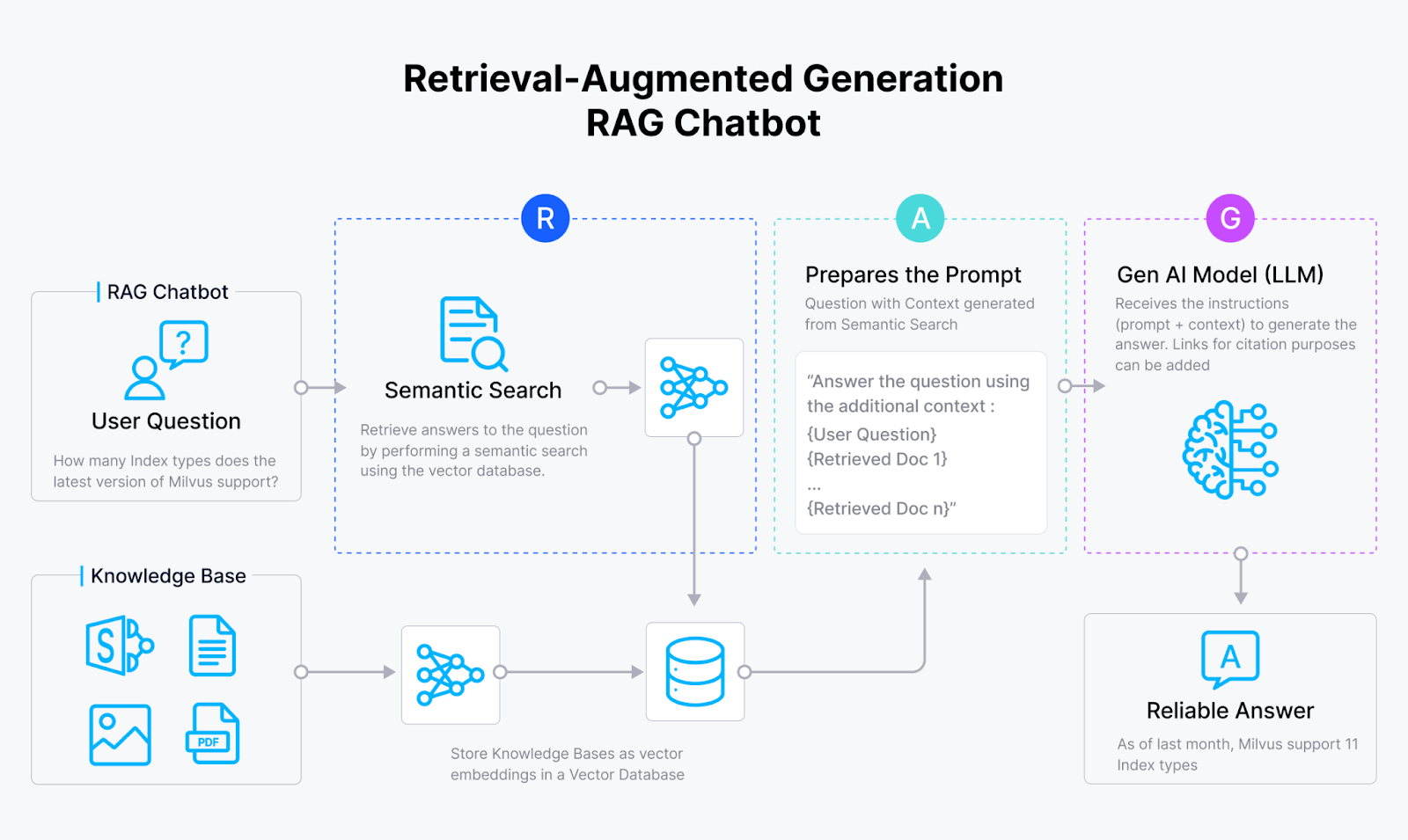 RAG_chatbot_2f1ff9ec07.png
RAG_chatbot_2f1ff9ec07.png
RAGRAG工作流程
LangChain作为流行的GenAI框架
LangChain是一个框架,它使使用最先进的LLM模型构建和开发GenAI应用变得容易。它轻松地与流行的LLM提供商如OpenAI、Anthropic和Google集成,以及向量数据库提供商如Zilliz。
LangChain还为开发LLM驱动的AI应用提供了灵活的抽象,使数据科学家和软件开发人员能够用几行代码构建复杂的系统如RAG。
例如,假设我们想使用GPT-4总结这篇博客文章的内容。我们可以用以下代码完成这项任务:
import os
from langchain.chains.summarize import load_summarize_chain
from langchain_community.document_loaders import WebBaseLoader
from langchain_openai import ChatOpenAI
os.environ["LANGCHAIN_TRACING_V2"] = "True"
loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")
docs = loader.load()
llm = ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo-1106")
chain = load_summarize_chain(llm, chain_type="stuff")
result = chain.invoke(docs)
"""
Output: The article discusses the concept of LLM-powered autonomous agents, with a focus on the components of planning, memory, and tool use. It includes case studies and proof-of-concept examples, as well as challenges and references to related research. The author emphasizes the potential of LLMs in creating powerful problem-solving agents, while also highlighting limitations such as finite context length and reliability of natural language interfaces.
"""
如您所见,仅用大约10行代码,我们就可以利用GPT-4模型准确地总结一篇长博客文章。
有了LangChain,您还可以执行更复杂的任务。例如,您可以将PDF文档中的长文本分割成块,使用您选择的嵌入模型将每个块转换成嵌入,将这些块的嵌入存储在向量数据库中,然后执行RAG。
import getpass
import os
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores.milvus import Milvus
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
from langchain.embeddings import SentenceTransformerEmbeddings
from langchain_openai import ChatOpenAI
# Set the API key
os.environ["OPENAI_API_KEY"] = getpass.getpass("Enter your OpenAI API key: ")
llm = ChatOpenAI(model="gpt-4")
# Text to be processed
texts = "This is a very long text.....:"
# Split text into chunks
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=100) # Example chunk size and overlap
chunk_texts = text_splitter.split_text(texts)
# Instantiate embedding model
embeddings = SentenceTransformerEmbeddings(model_name="all-MiniLM-L6-v2")
# Store embeddings of chunks inside Milvus DB
vector_db = Milvus.from_texts(texts=chunk_texts, embedding=embeddings, collection_name="rag_milvus")
retriever = vector_db.as_retriever()
# Define function to format documents
def format_docs(docs):
return "\\n\\n".join(doc.page_content for doc in docs)
# Perform RAG (Retrieval Augmented Generation)
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| llm
| StrOutputParser()
)
# Example question
question = "What is the main idea of the text?"
# Execute RAG chain and print the result
for chunk in rag_chain.stream(question):
print(chunk, end="", flush=True)
除了上述提供的演示之外,LangChain还提供了一系列功能。例如,它集成了来自外部来源的LLMs和API,如天气应用、计算器或Google搜索。这种方法允许LLMs利用这些来源的信息生成更准确、上下文化的响应。我们将在接下来的部分中看到这种方法的详细实现。
您还可以在他们的文档页面上探索LangChain的所有功能。
使用Ruby和Milvus开发GenAI应用
Python已成为AI研究和开发框架(包括LangChain)的实际编程语言。与此同时,Ruby仍然受到快速软件开发和Web应用开发的欢迎。
然而,正如您在前一节中看到的,LangChain的引入为软件开发人员提供了将LLM的强大功能整合到他们的Web应用中的可能性,而无需了解LLM和AI的详细理论。
这种能力创造了一个日益增长的需求,即将这些GenAI开发框架扩展到全栈开发人员更熟悉的其他语言,如Ruby。为了满足这一需求,Andrei Bondarev介绍了LangChain.rb,这是原始LangChain框架的Ruby扩展。
LangChain.rb使Ruby全栈开发人员能够构建由LLM驱动的Web应用,而无需在项目中整合多种编程语言。有了它,您可以轻松地将流行的向量数据库、LLMs和外部资源整合到您的LLM Web应用中。
LangChain.rb具有与原始LangChain相同的一般功能,例如:
- 提示管理:为您选择的LLM创建、加载和保存提示模板
- 上下文长度验证:根据您选择的LLM和嵌入模型的上下文长度验证输入的上下文长度
- 数据分块:在将数据导入您选择的向量数据库之前,根据预定义的规则将数据分割成块
- 对话记忆:将与LLM的聊天持久保存到记忆中
在接下来的部分中,我们将演示如何在LangChain.rb的帮助下开发简单的LLM驱动的应用。
使用LangChain.rb的通用RAG应用
在这个第一个示例中,我们将使用LangChain.rb构建一个简单快速的RAG应用。在您可以使用LangChain.rb进行Ruby项目之前,请确保通过执行以下命令安装gem:
gem install langchainrb
在这个项目中,我们将使用Milvus作为向量数据库,使用OpenAI的模型作为LLM和嵌入模型。要启动Milvus,我们需要安装Docker中的Milvus,并使用以下命令启动容器:
# Download the installation script
curl -sfL https://raw.githubusercontent.com/milvus-io/milvus/master/scripts/standalone_embed.sh -o standalone_embed.sh
# Start the Docker container
bash standalone_embed.sh start
现在我们已经启动了Docker容器,让我们实例化Milvus和我们将用于RAG应用的模型。
require 'langchain'
milvus = Langchain::Vectorsearch::Milvus.new(
url: ENV["MILVUS_URL"],
index_name: "Documents",
llm: Langchain::LLM::OpenAI.new(api_key: ENV["OPENAI_API_KEY"])
)
我们需要做的第一件事是在Milvus向量数据库中创建一个模式和相应的索引方法。接下来,我们需要在执行向量搜索之前加载该模式。
# Create default schema
milvus.create_default_schema
# Create default index
milvus.create_default_index
# Load default schema
milvus.load_default_schema
现在我们可以将一些数据导入我们的模式。假设我们有一个包含有关员工福利信息的PDF文件。如果我们想将这个PDF中的所有文本存储在Milvus数据库中,我们可以通过执行以下命令来实现:
pdf = Langchain.root.join("path/to/my.pdf")
# Add PDF inside of Milvus
milvus.add_data(path: pdf)
一旦您执行了上述命令,LangChain将在后台完成所有的预处理工作。它将解析PDF文件中的文本,将其分割成几个块,将每个块转换成嵌入,然后将嵌入存储在Milvus向量数据库中。
将数据存储在Milvus向量数据库后,我们就可以开始询问与我们的PDF文档相关的问题。假设我们想问,“公司的休假政策是什么?我可以休多少天?”然后我们可以通过简单地执行这一行代码来向我们的LLMs在RAG系统中提问:
response = milvus.ask(question: "What’s the company’s vacation policy? How much can I take off?")
puts response
"""
Response:
=> The company's vacation policy allows employees to take any reasonable amount of time off with pay,
as long as they consult with their manager in advance and get their work done.
"""
就这样!除了构建一个通用的RAG应用,我们还可以在下一部分讨论的LangChain.rb的帮助下构建一个代理性的RAG应用。
利用代理与第三方工具交互
许多LLMs的主要限制是它们的知识截止日期。例如,GPT-4的知识截止日期是2023年4月。这意味着,如果我们想问有关2023年4月之后一般或事实事件的问题,我们将无法从LLM获得准确的响应。
为了解决这个问题,LangChain.rb使我们能够构建一个代理性的RAG应用。这种类型的RAG应用增加了另一层智能,包含一个充当决策者的“代理”。代理分析用户查询,然后决定可以提供最适合回答查询的上下文的最有效第三方工具。
假设我们想问我们的LLM有关纽约当前的天气。有了一般的RAG系统,LLM无法知道纽约的实际天气。它很可能会开始幻想,并给我们一些随机的天气预测。
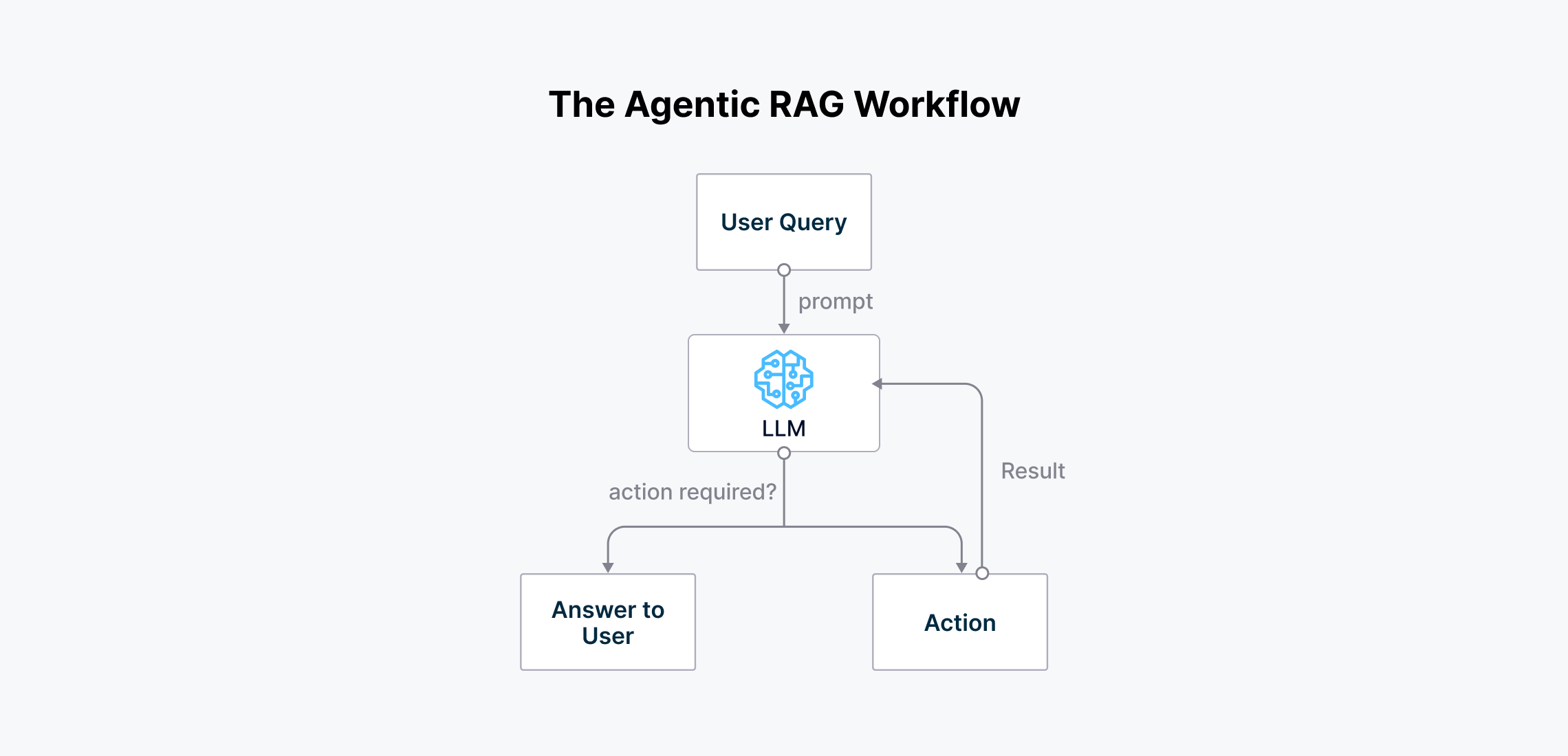 The_agentic_RAG_workflow_1_7a34b6155c.png
The_agentic_RAG_workflow_1_7a34b6155c.png
代理性RAG的工作流程
代理性RAG通过使我们能够使用工具或API(如OpenWeather API)来获取纽约的实际天气来解决这个问题。代理首先处理用户查询,然后决定可以提供相关上下文来回答查询的工具,然后再将上下文合成为准确答案。
以下演示将在我们的RAG系统中使用第三方工具,如计算器、OpenWeather应用和Google搜索。
weather = Langchain::Tool::Weather.new(api_key: ENV["OPEN_WEATHER_API_KEY"])
google_search = Langchain::Tool::GoogleSearch.new(api_key: ENV["SERPAPI_API_KEY"])
calculator = Langchain::Tool::Calculator.new
接下来,我们需要使用以下命令将这三个工具添加到我们的RAG系统中:
openai = Langchain::LLM::OpenAI.new(api_key: ENV["OPENAI_API_KEY"])
agent = Langchain::Agent::ReActAgent.new(
llm: openai,
tools: [weather, google_search, calculator]
)
现在,我们可以开始向我们的LLM提问。假设我们想问以下问题:“找出波士顿,马萨诸塞州和华盛顿特区当前的天气,然后取平均值。”
response = agent.run(question: "Find current weather in Boston, MA and Washington, D.C. and take an average")
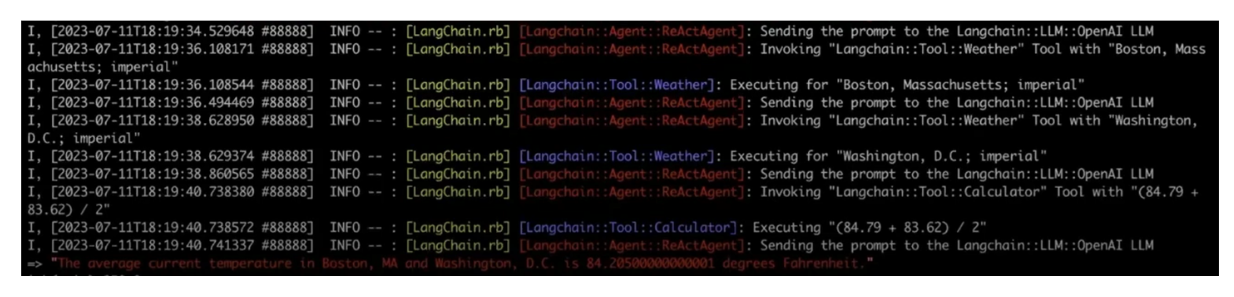 Output_of_RAG_with_tools_integration_186129052d.png
Output_of_RAG_with_tools_integration_186129052d.png
RAG与工具集成的输出
如上图所示,我们的代理性RAG系统能够准确地回答查询。这个RAG系统的工作流程如下:
- 查询首先发送到OpenAI LLM。
- 代理识别需要使用OpenWeather API获取波士顿和华盛顿特区当前的天气。
- 检索到天气数据后,代理看到查询需要对两个城市的天气进行平均。
- 代理然后调用计算器工具来计算天气平均值。
- 最后,LLM将结果合成为一个连贯的答案,并将其返回给用户。
这个示例展示了代理性RAG方法的强大功能。通过整合外部工具和API,系统克服了LLM知识截止日期的限制,并为用户提供了准确、最新的响应。
利用代理与内部数据库交互
我们还可以使用代理性RAG与我们的内部数据库交互。这非常有用,因为我们可以询问有关我们数据的洞察,使用类似人类的语言,而不是依赖传统的SQL查询。
假设我们有一个在线商店和用户数据存储在数据库中。通常,我们需要编写SQL查询来从数据中提取洞察。有了代理性RAG,我们只需要向LLM询问我们想要的洞察,答案将立即返回。
例如,假设我们想知道数据库中存储了多少用户记录。我们可以简单地问:“有多少用户?”并执行以下命令:
require 'langchain'
# Instantiate the database connection
database = Langchain::Tool::Database.new(connection_string: "postgres://localhost:5432/my_database")
# Create OpenAI LLM instance
openai = Langchain::LLM::OpenAI.new(api_key: ENV["OPENAI_API_KEY"])
# Create SQLAgent with the LLM and database connection
agent = Langchain::Agent::SQLAgent.new(
llm: openai,
db: database
)
# Ask a question to the agent
response = agent.run("How many users are there?")
以下是命令的示例输出:
 Output_of_RAG_with_SQL_integration_43f25849ae.png
Output_of_RAG_with_SQL_integration_43f25849ae.png
RAG与SQL集成的输出
如您所见,我们的代理性RAG系统能够准确地回答与我们数据库数据相关的特定问题。代理的工作流程与前一个示例相似:
- 查询发送到OpenAI LLM。
- 代理分析查询并确定需要进行数据库查找以计算用户数量。
- LLM根据数据库表模式生成适当的SQL查询。
- SQL查询针对数据库执行并返回结果。
- 数据库输出发送回LLM。
- LLM将数据库结果合成为一个连贯、易于阅读的答案,并将其作为最终响应提供。
结论
LangChain的引入使LLMs易于接触那些可能没有深厚AI和数据科学理论知识的专业人士。我们可以使用LangChain用几行代码构建一个强大的RAG应用。
这种可访问性是Andrei Bondarev引入LangChain.rb的原因,LangChain.rb是Ruby的LangChain扩展。这个框架使全栈开发人员能够将LLM的强大性能整合到他们的Web应用中,而不需要广泛的AI专业知识。此外,LangChain.rb消除了全栈开发人员在想要在Web应用中利用LLMs时切换到另一种编程语言的麻烦。
注:本文为AI翻译,查看原文