



利用 Milvus 增强 Troop 股东平台

扩展
十分轻松
增强
非结构化数据检索
高性价比
基础设施
无需多想,我便可以在 1 小时内轻松设置、扩展 Milvus。而且这个架构能够帮助我轻松应对未来不断增长的业务需求,无需重复造轮子。
Zen Yui
Troop 简介
Troop 聚焦于股东积极主义领域,旨在通过技术构建良好的股东协作环境。其平台吸引并连结价值观和兴趣相似的股东,他们可以通过 Troop 平台加入或发起活动。在过去一年中,Troop 构建了股东社区,管理着价值 2000- 3000 万美元的股票组合,拥有超过 2500 名会员。Troop 的灵感来自于一些著名金融事件,如华尔街赌场(WallStreetBets)、游戏驿站(GameStop)轧空暴乱和激进投资公司 Engine No. 1 成功推动埃克森美孚(ExxonMobil)变革等。
Troop 为股东们提供了一个数字空间,方便他们会面、讨论和采取行动。Troop 平台鼓励股东间发起对话、积极推动股东活动、弥合股东和企业高管之间的分歧。Troop 通过将技术与股东积极主义的理念相结合,不断积极推动提升股东参与度,最终实现更包容和主动的股东生态系统。
Troop 面临技术难题:如何简化复杂的数据流
Troop 期望通过检索增强生成(RAG)技术从庞大的美国证券交易委员会(SEC)数据库中及时发现相关的股东活动机会。起初,Troop 使用 LangChain 进行 PDF解析、问答以及 [FAISS](https://zilliz.com.cn/blog/faiss-milvus-setting up) 进行向量搜索。虽然这个方案看似可行,但实际上,在处理庞大的 SEC 数据时,FAISS 暴露了其局限性。FAISS 无法处理对公司会议投票至关重要的背景文件,而且无法在内存中存储向量数据 Collection。
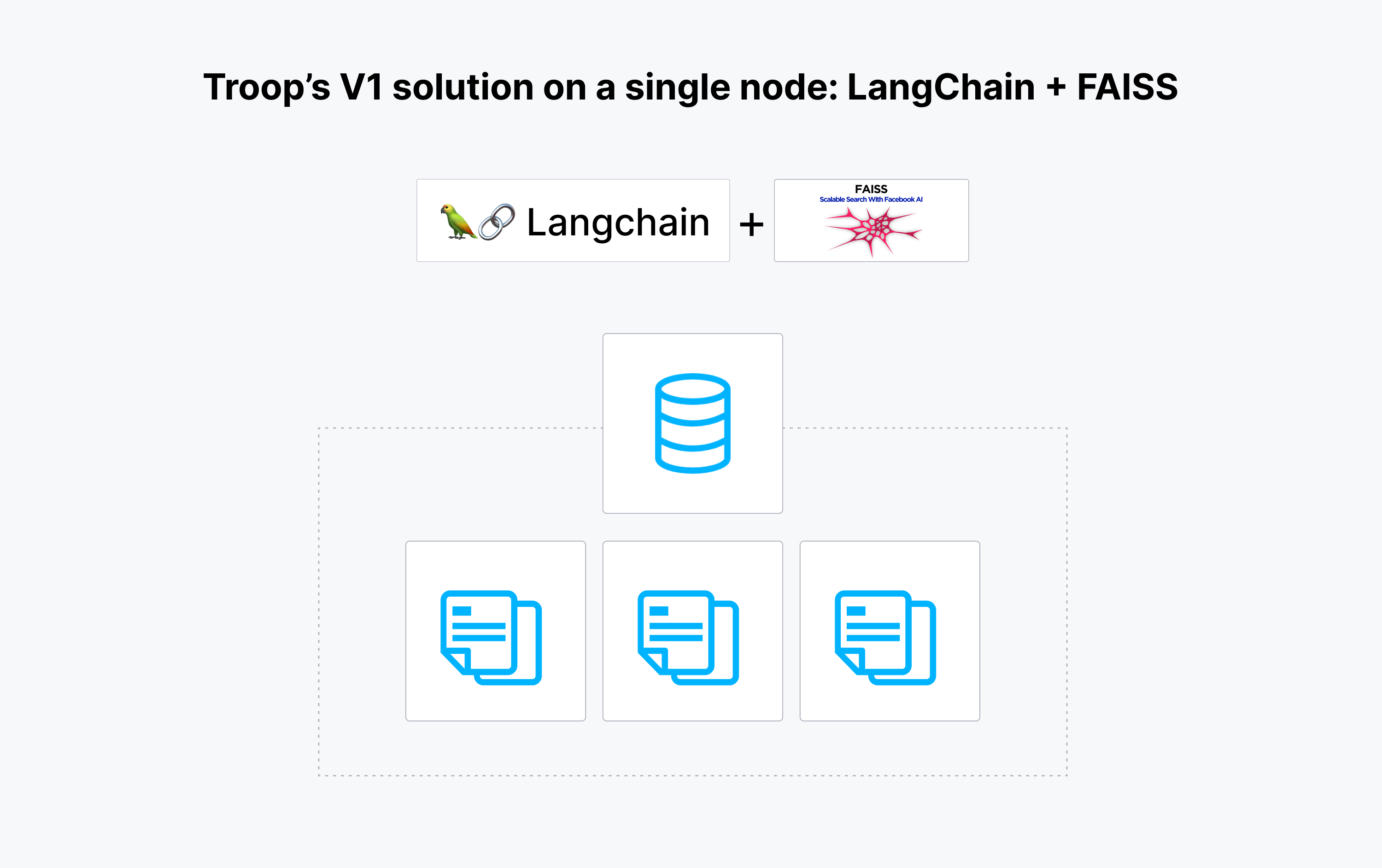
The data volume was too large to manage in memory, and the LangChain and FAISS setup couldn't offer the scalability and production readiness required for personalized voting recommendations. Troop sought a scalable, self-hosted solution to keep up with the growing user base and data volumes without escalating costs. The technical bottleneck emerged from the existing setup, highlighting the need for a robust vector database solution capable of efficiently handling high-dimensional data and decoupling compute from storage, ensuring streamlined data retrieval—a critical requirement for Troop's evolving operational demands.
数据量过大,无法在内存中管理。LangChain 和 FAISS 搭建的个性化投票建议系统无法满足可扩展性需求。Troop 急需一套可扩展的全托管解决方案,从而应对不断增长的用户数量和数据量,同时合理控制成本。Troop 现在面临的技术瓶颈表明它需要一种能够高效处理高维数据且计算存储分离的强大向量数据库,以确保流畅的数据检索流程——这对于 Troop 的发展至关重要。
解决方案:使用 Milvus 优化向量数据处理流程
Troop 在尝试不同向量数据库过程中发现了 Milvus。Milvus 能够高效管理了大规模数据,从而提升语义搜索能力。Milvus 的一个重要特性就是将存储与计算分离,这对于 Troop 这种数据量极大的应用至关重要。计算存储分离确保 Troop 能够在使用之前对整个语料库进行 embedding,但同时只将必要的内容加载到内存中,从而显著降低计算开销。即使后续数据量不断增加,系统也能保持良好响应。
另一个要点就是系统需要根据查询量而灵活扩展节点。Milvus 与生俱来的高扩展性确保了系统可以随时扩展,满足激增的数据量。这点对于 Troop 的生产环境尤为关键,可以自托管或通过 Kubernetes 扩展。与传统向量数据库不同,Milvus 的架构确保了平稳、可扩展的操作,与 Troop 能够完美融合。
Troop 处理数据的方式类似于处理数据湖(data lake)。通过导入新的 SEC 文件并按时间分区, Troop 可以将每一页分块并写入一个桶中。类似地,embedding 也按时间分区,在需要时针对特定时间分区即可。这种方法不仅简化了数据检索,而且展示了 Milvus 在大数据场景中的潜力。将数据分割成隔离的分区,并控制对每个分区的特定 Milvus 客户端的访问能力,展示了 Milvus 在应对现实世界数据挑战方面的灵活性和适应性,为Troop不断发展的运营需求奠定了坚实的基础。
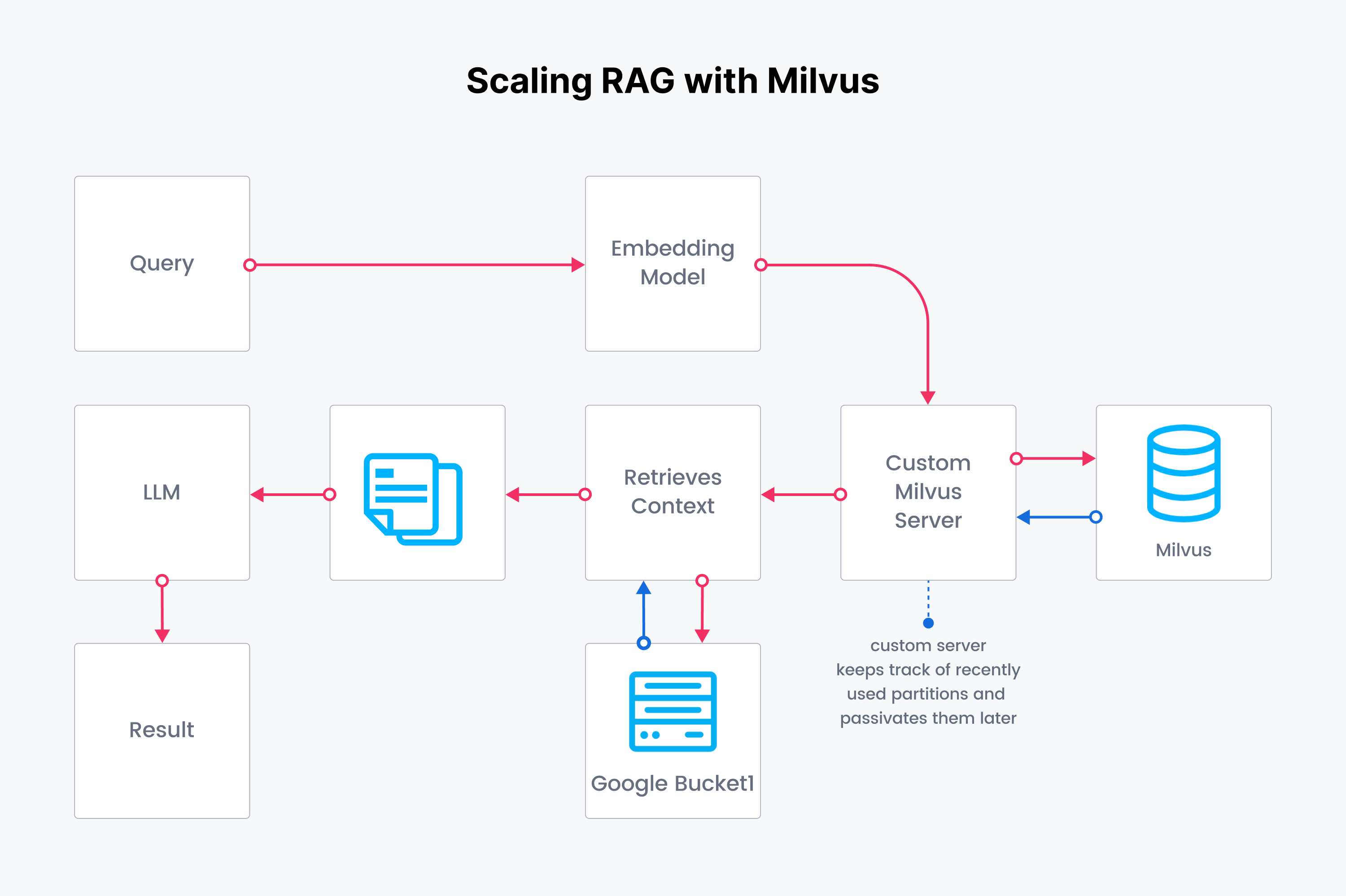
精确轻松地实现灵活扩展
Milvus 在 Troop 高效管理不断增长的数据量方面至关重要。Troop 借助 Milvus 搭建了一个可扩展的 AI 时代基础设施,并完成了推荐引擎,将股东与相关的金融活动联系起来。
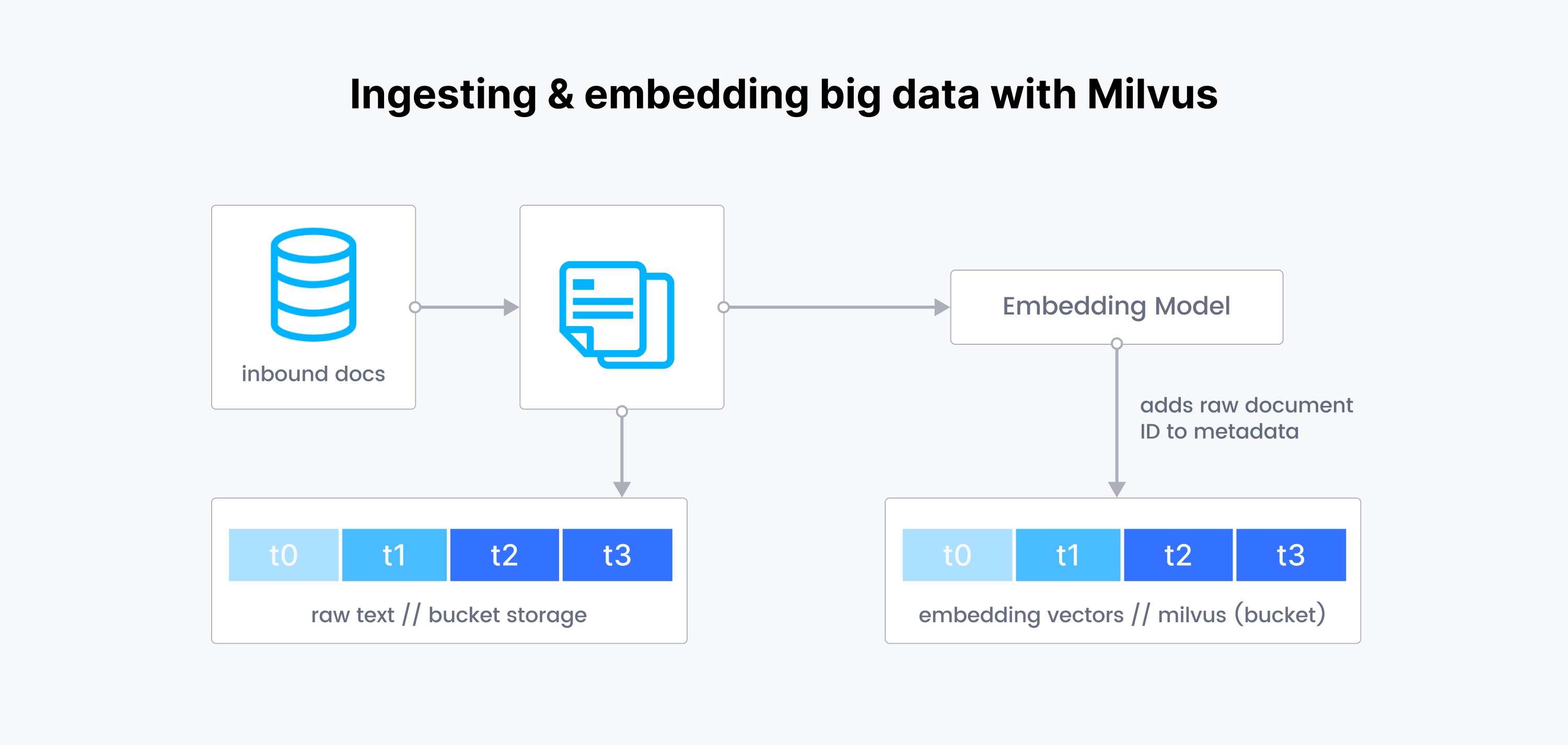
Troop 的联合创始人兼首席技术官(CTO) Zen Yui 对 Milvus 的可扩展性赞不绝口。Yui 评价到:“我们可以在第二天立即投入一百倍的数据量,只需小小修改我们的分区和索引就可以适应这些数据。”这种感觉也反映在操作便捷性上。Yui 继续说到:“无需多想,我便可以在 1 小时内轻松设置、扩展 Milvus。而且这个架构能够帮助我轻松应对未来不断增长的业务需求,无需重复造轮子。”
Milvus 的精细分区和索引方案与 Troop 的 B2B 产品需求无缝对接,可满足不断扩大的用户群体和不断增长的 SEC文件数据。正如团队所称赞的那样,按时间分区和按客户分区的能力反映出一种可扩展、简单的方法来管理多样化的数据流。有了 Milvus,Troop 能够很好地应对数据管理和实时推荐的动态环境,确保一个有韧性的、可扩展的基础设施。这正与市场和利益相关者不断演变的需求保持一致。
未来计划:通过 Embedding 推进数据民主化
Troop 期望利用 Embedding 推动数据民主化,而 Milvus 正是这一愿景的基石。Troop 计划使用像 GPT-4 这样的高级模型来评估和训练更具性价比的模型,从而有效利用其庞大的数据。他们打算将 embedding 和语义搜索应用于各种数据类型,包括用户数据、用量情况和情感数据。Milvus 的可扩展性和实时能力对 Troop 的计划至关重要。通过将昂贵的基础模型评估与更便宜的、精调或定制训练的模型分离,Troop 能够优化计算资源,同时保持搜索质量。
Troop 还计划利用 embedding 释放其数据湖的潜力。其数据湖充满了来自各种来源的信息。Troop 希望能够搭建一个工具帮助他们的团队和用户群高效探索数据湖。通过在 Streamlit 之上开发应用程序,Troop 已经开始弥合非结构化文本和结构化数据之间的差距,实现了定制化的 RAG pipeline。
Troop 将 Milvus 视作其基础设施中的重要一环,帮助他们探索更多业务可能,更好服务不断增长的用户群体。