



优化 FARFETCH 智能能聊天机器人

15x
更快索引速度
5x
更快查询速度
提升转化率
为用户推荐更相关的商品
支持多种相似度类型
适合各种应用场景
Milvus 性能表现始终优于 Weaviate,尤其是 S9 场景下的索引速度非常出色。该场景下的测试数据和 FARFETCH 商品目录中的数据非常相似。
PEDRO MOREIRA COSTA
FARFETCH 简介
作为在线时尚零售业的领军力量,FARFETCH 通过其最新打造的 iFetch 不断升级用户的数字化购物体验。 iFetch 是一个对话式 AI 系统,旨在将奢侈品实体店中提供的个性化高端服务带入线上数字化购物场景。FARFETCH Chat 研发部门正在开发一个对话式推荐系统。集成到 iFetch 后,这个聊天机器人允许用户通过自然语言和图像搜索 FARFETCH 产品目录。例如,用户可以上传一张他们喜欢的夹克外套的图片,聊天机器人将回复类似的精选夹克图片。通过将先进的 AI 技术与用户体验无缝融合,FARFETCH 正在重新定义用户在在线购物领域。
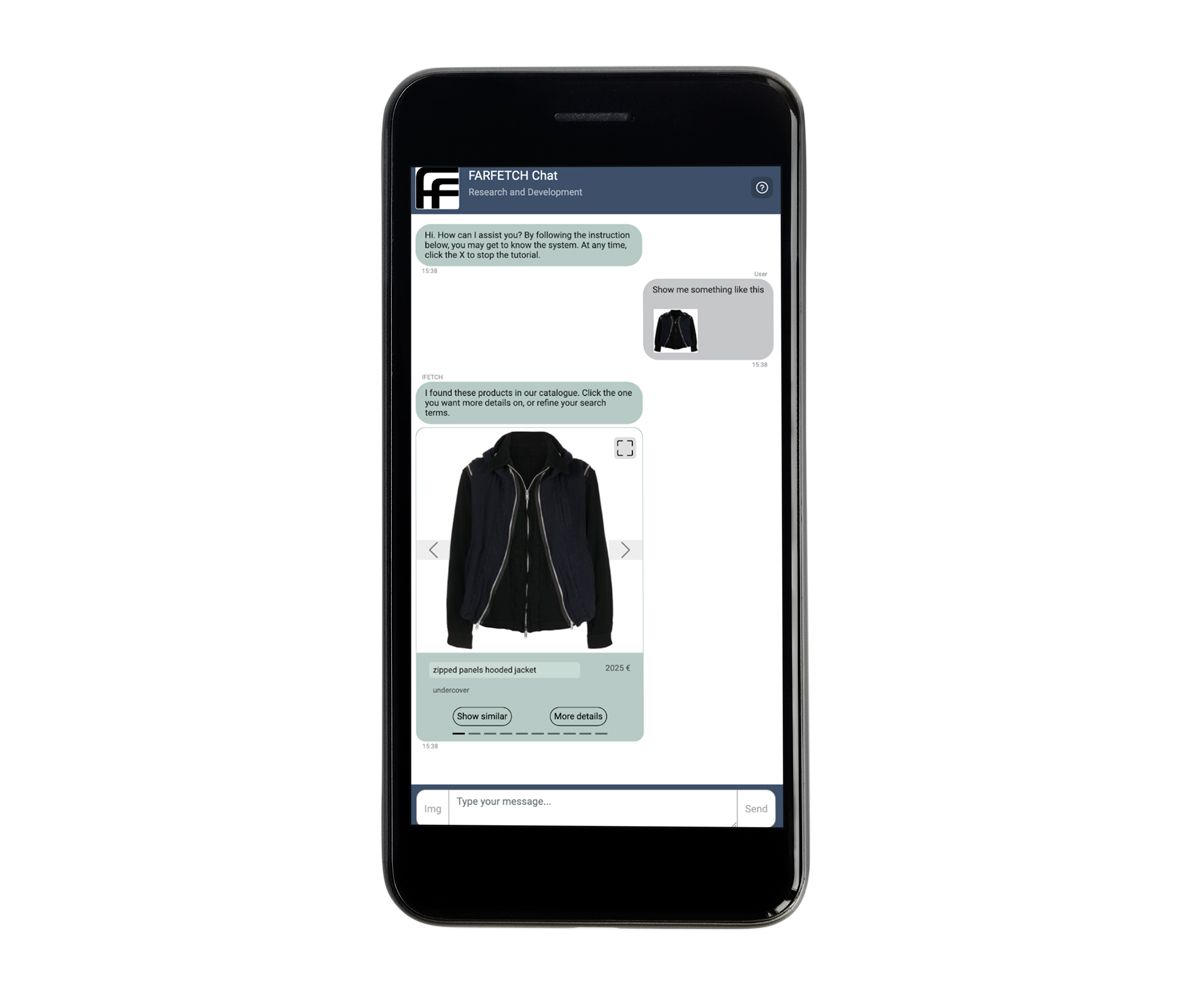 FARFETCH Chat 展示了一件和搜索相似的夹克外套
FARFETCH Chat 展示了一件和搜索相似的夹克外套
然而,FARFETCH 也面临一个重大挑战:商品目录的元数据不足,难以全面涵盖所有商品的独特特性和商品间的复杂关系。为了解决这个问题,FARFETCH 决定采用机器学习算法将商品转化为向量。这样一来,这些高维向量数据可以使用公司的 AI 系统来处理。而聊天机器人也能够精确理解产品特性,为用户做出最合适的商品推荐。除了上述挑战以外,FARFETCH 还在向量实时存储和检索方面遇到了难题,他们需要寻找一套能够高效处理高维向量数据存储的解决方案。
为什么选择向量数据库?
向量数据库,也被称为向量相似性搜索引擎(VSE),是专门用于处理复杂高维数据的数据库。向量数据库采用了近似最近邻(ANN)算法,能快速准确地检索向量数据。对于 iFetch 这样需要与客户进行实时客户、提供即时回答和产品推荐的应用系统来说,向量数据库是最为合适的选择。但是选择业界的哪个向量数据库也是值得慎重考虑的问题。因为这个战略决策并不仅仅是技术层面上的选型问题,这个决策还会直接影响到 iFetch 的性能和稳定性。为了确保选择最为合适的向量数据库,FARFETCH 进行了全面的向量数据库性能测试。性能测试涵盖主流的向量数据库,包括 Vespa、Milvus、Qdrant、Weaviate、Vald 和 Pinecone,主要评估了各个向量数据库的索引创建速度、查询速度和可扩展性。性能测试中还增加了压力测试环节,以评估各个向量数据库在峰值负载、故障转移和恢复等场景下的系统弹性。
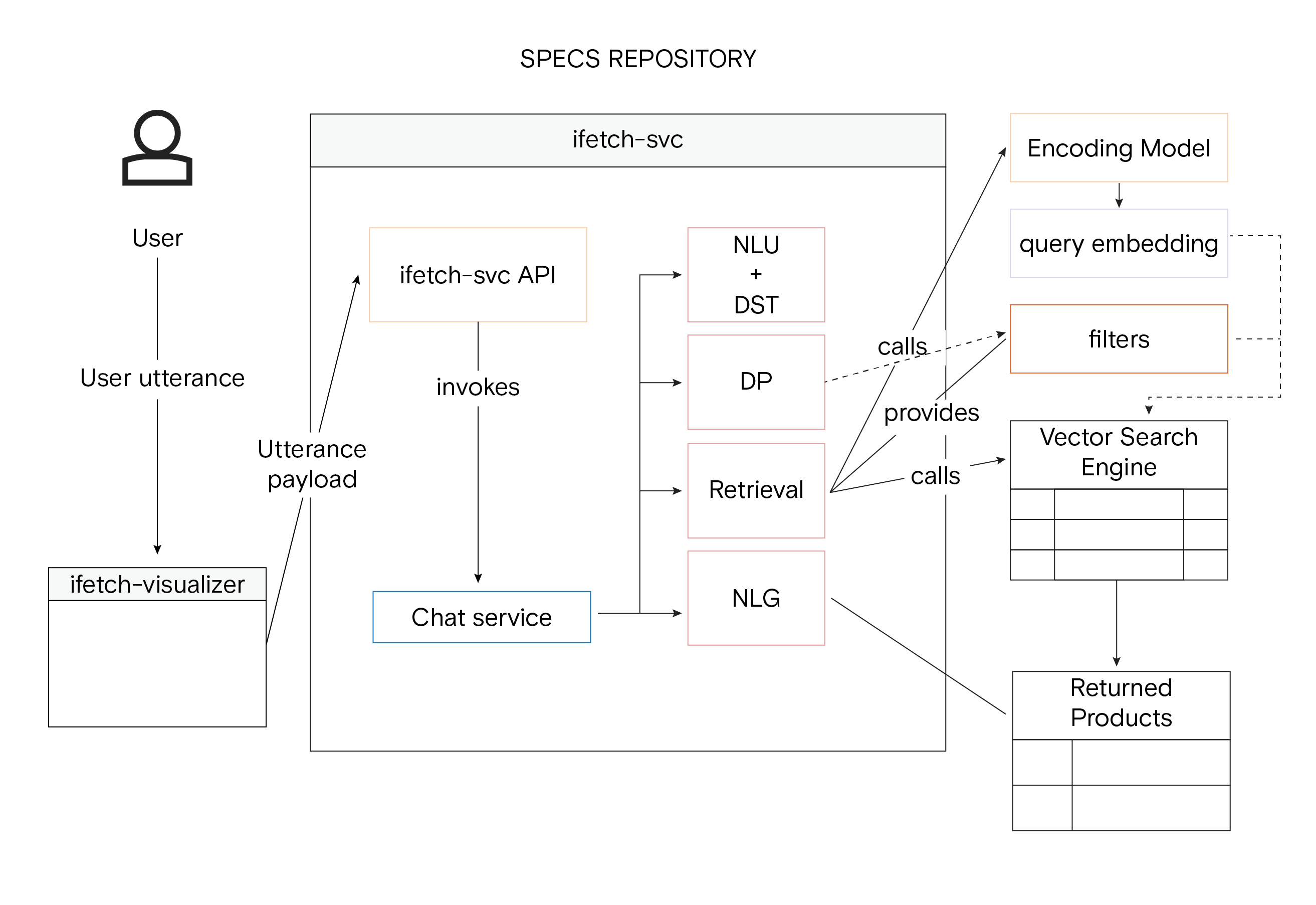 iFetch 系统架构及向量相似性搜索模块
iFetch 系统架构及向量相似性搜索模块
初步筛选的标准及考量指标
FARFETCH 团队对市面上的向量数据库进行了初步筛选。考量指标涵盖了决定 iFetch 性能的各种因素,包括索引类型的多样性、相似度类型、模型服务能力和社区采用率。FARFETCH 还考虑了向量数据库文档质量和提供的技术支持,这些因素将影响系统后续的长期维护。
| 特性 | Qdrant | Milvus | Weaviate | Vespa | Vald | Pinecone |
|---|---|---|---|---|---|---|
| 一致性等级 | N/A | 强一致性 | 最终一致性 | 最终一致性 | N/A | 最终一致性 |
| 是否支持 GraphQL | N/A | N/A | 是 | N/A | N/A | N/A |
| 分片 (Sharding) | 否(何时支持该功能待定) | 是 | 是 | 是 | N/A | N/A |
| 分页 | N/A | 否(预计于2022年3月的2.2 版本中推出) | 是 | 是 | N/A | N/A |
| 相似度类型 | 内积、余弦、欧氏距离 | L2、内积、汉明距离、杰卡德距离、谷本距离、超结构、子结构 | 余弦 | 欧氏距离、汉明距离 | L1、L2、汉明距离、余弦(归一化)、杰卡德距离 | 欧氏距离、余弦、内积 |
| 最大向量维度 | N/A | N/A | 32768 | N/A | max.MaxInt64 | N/A |
| 最大索引大小 | N/A | N/A | 无限制 | N/A | N/A | N/A |
| 索引类型 | HNSW | ANNOY、HNSW、IVF_PQ、IVF_SQ8、IVF_FLAT、FLAT、IVF_SQ8_HRNSG | HNSW | HNSW、BM25 | N/A | 专有类型 |
| 模型服务 | N/A | N/A | text2vec-contextionaryWeaviate 独有的向量化工具;其 WMOWE 模块,可与 fastText 和 GloVe 等主流模型一起使用。最新的 text2vec-contextionary 是基于 Wiki 和 CommonCrawl 上的 fastText 训练的。text2vec-transformersTransformer 模型与 Contextionary 不同,支持用户插入预训练 NLP 模块。也就是说,用户可以 在 Weaviate 中直接集成 BERT、DilstBERT、RoBERTa、DilstilROBERTa等模型。 | N/A | N/A | N/A |
经过严格分析,FARFETCH 最终挑选出 Milvus 和 Weaviate 进行深入的性能测试。这两个向量数据库能够满足 iFetch 平台对稳定性、效率和可扩展性的要求。此外,这两个数据库的产品路线图上也不断新增功能,可以解决后续 iFetch 平台的需求,适应产品的发展。
实验设置
FARFETCH 使用了标准化的软硬件设置,以确保测试评估的公正性和全面性。
- 硬件:Intel Xeon E5-2690 v4 CPU,112 GB RAM,1024 GB HDD
- 软件:Linux 16.04-LTS,Anaconda 4.8.3 与 Python 3.8.12
- 数据集:Farfetch 团队使用了来自 startups-list.com 的公共数据集,包含 40,474 条公司简介的向量数据。
测试场景和索引算法
FARFETCH 团队设计了多个测试场景,用于评估不同向量数据库在不同条件下的性能。这些场景中的数据量和向量数量不同。测试中使用了 HNSW 索引类型,因为这个索引类型更适合于高维数据空间。
场景列表如下。
| 场景 | 实体数量 | 每个实体的编码数量 |
|---|---|---|
| 场景#1(S1) | 1 | 1 |
| 场景#2(S2) | 10 | 1 |
| 场景#3(S3) | 40,474 | 1 |
| 场景#4(S4) | 1 | 2 |
| 场景#5(S5) | 10 | 2 |
| 场景#6(S6) | 40,474 | 2 |
| 场景#7(S7) | 1 | 5 |
| 场景#8(S8) | 10 | 5 |
| 场景#9(S9) | 40,474 | 5 |
性能分析
索引性能
Weaviate: 在 Class Schema 创建过程中允许声明索引参数。但是 Weaviate 限制 Class 命名,不支持数字或特殊字符。
Milvus: 提供了更广泛多样的索引算法和相似度类型,支持定义索引文件大小,可优化批处理操作。
结果: 在所有场景下,Milvus 创建索引所需的时间更短。在资源密集型的 S9 场景中,Milvus 创建索引的速度明显更快。
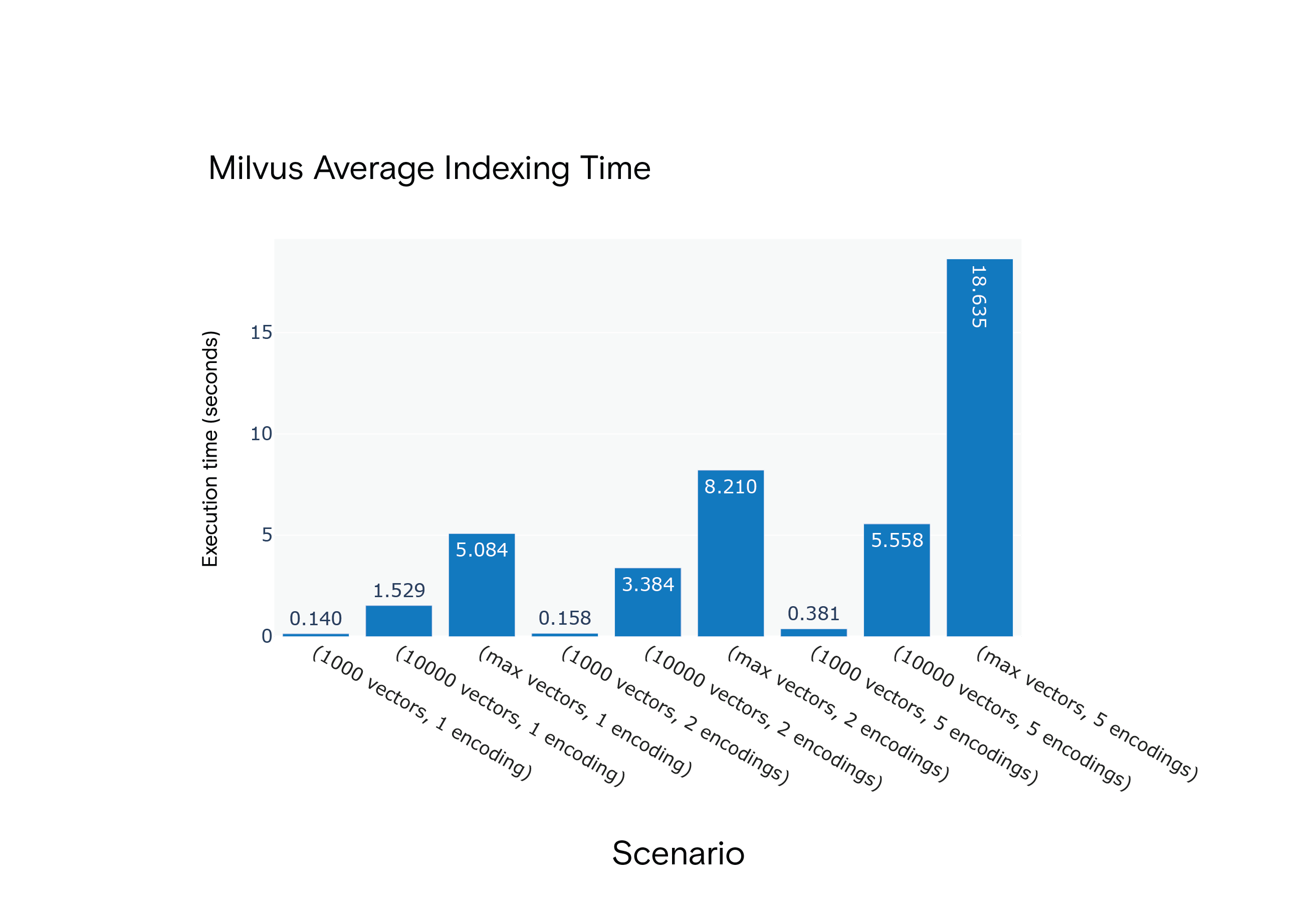 场景 S1 至 S9 下 Milvus 1.1.1 创建索引所需的平均时间
场景 S1 至 S9 下 Milvus 1.1.1 创建索引所需的平均时间
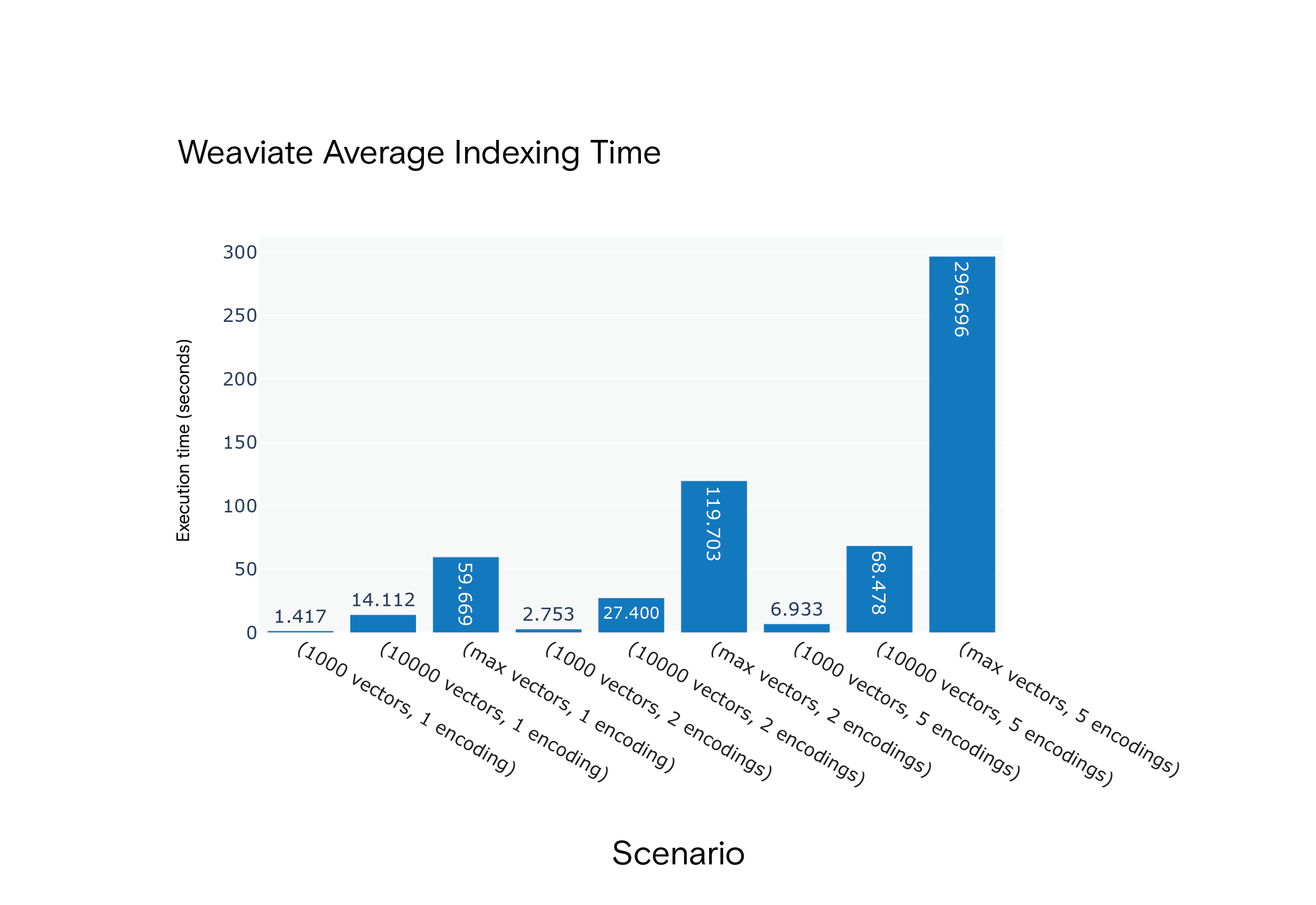 场景 S1 至 S9 下 Weaviate 创建索引所需的平均时间
场景 S1 至 S9 下 Weaviate 创建索引所需的平均时间
查询性能
Weaviate: 其 Python 客户端支持向量搜索,但一次只能使用一个向量进行搜索。
Milvus: 提供了一种更灵活的搜索方法,可以一次性使用多个向量进行搜索。
结果: 在所有场景下,虽然 Milvus 需要“热身”完毕后,才能达到最佳性能,但 Milvus 所需的平均查询时间更短。
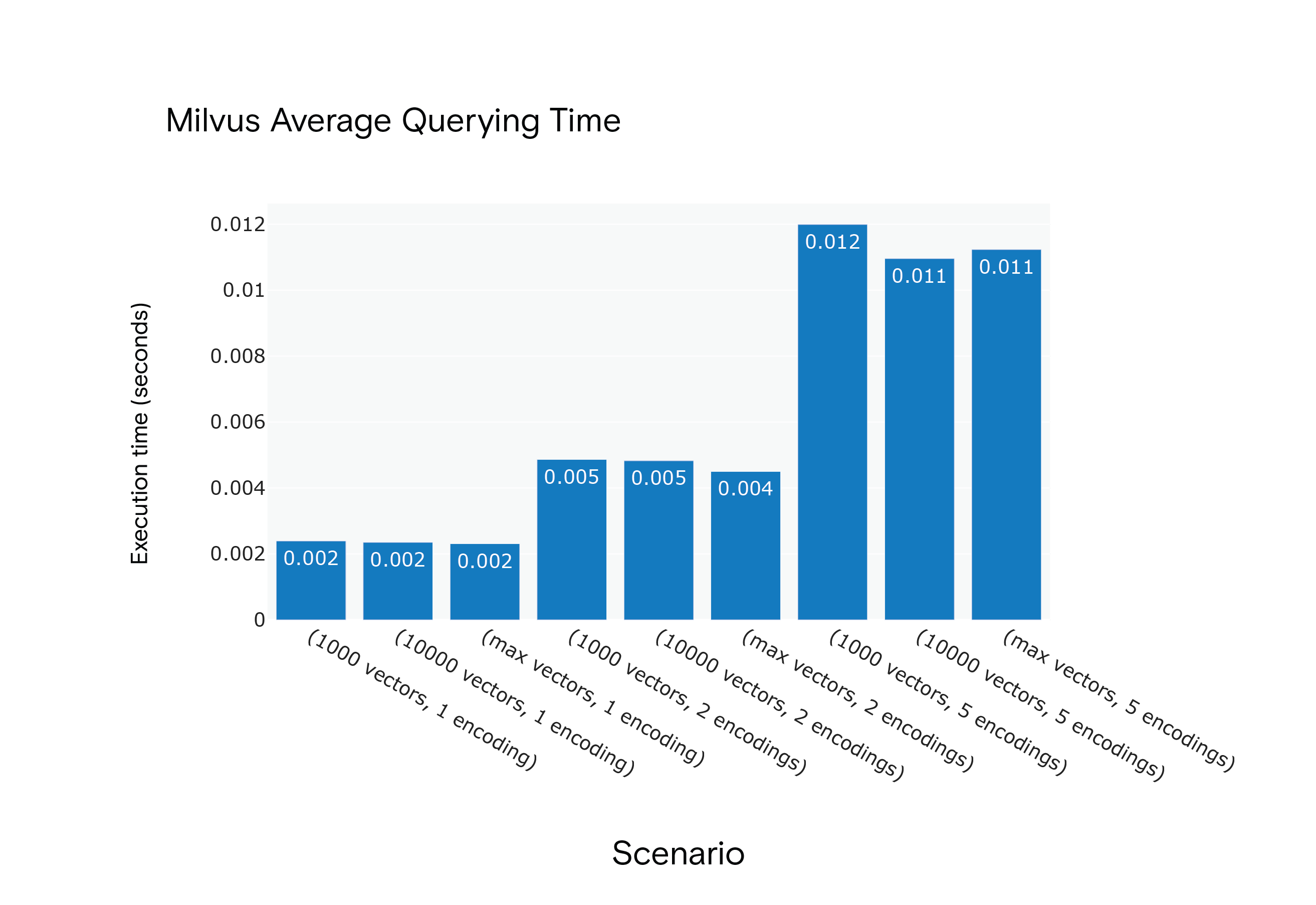 场景 S1 至 S9 下 Milvus 1.1.1 向量查询所需的平均时间
场景 S1 至 S9 下 Milvus 1.1.1 向量查询所需的平均时间
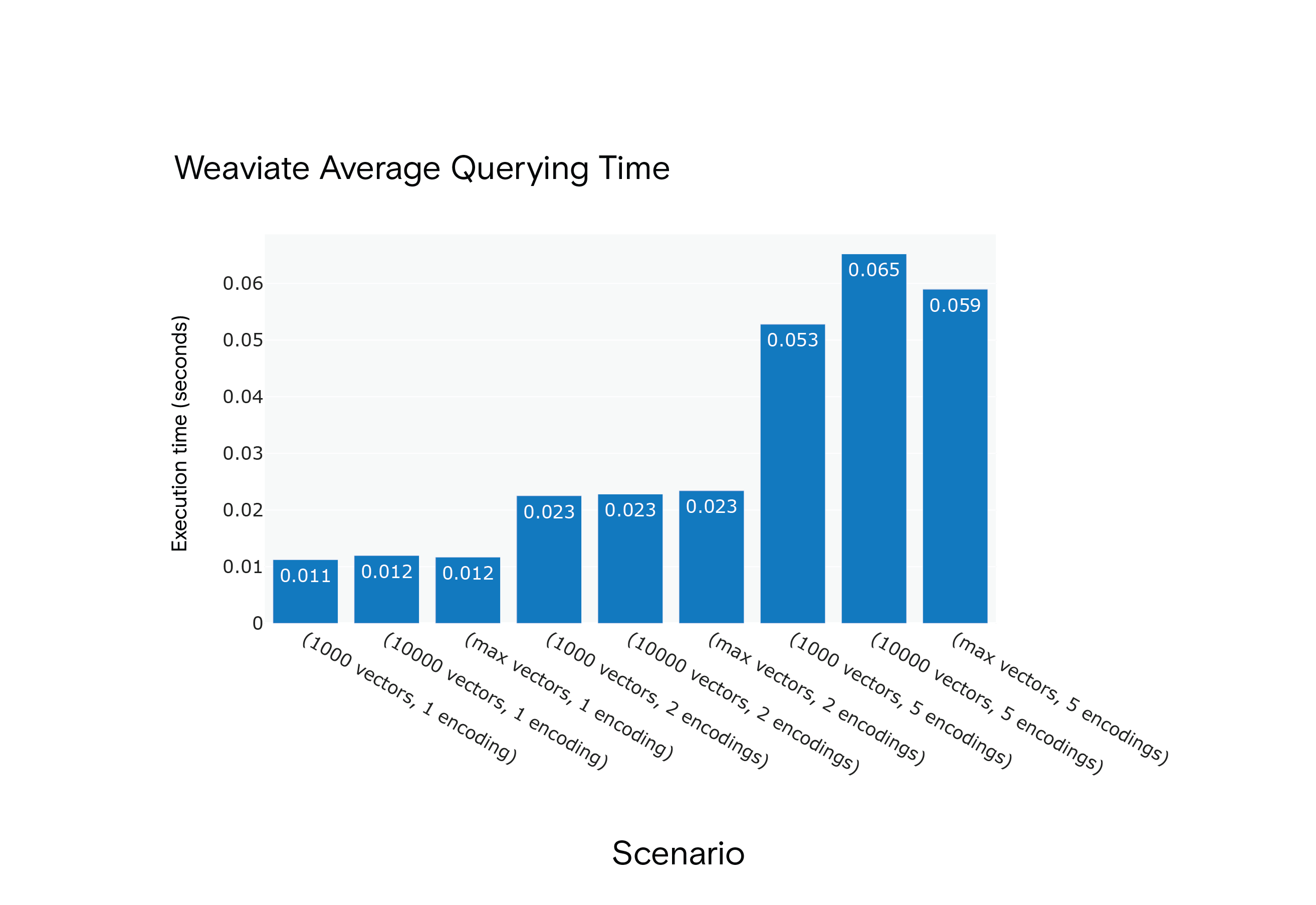 场景 S1 至 S9 下 Weaviate 向量查询所需的平均时间
场景 S1 至 S9 下 Weaviate 向量查询所需的平均时间
FARFETCH 团队认为 Milvus 和 Weaviate 向量数据库均展示了不俗的表现,且这两个向量数据库的产品路线图上还包含水平扩展、分片和 支持 GPU 等功能。FARFETCH 团队的需求是处理 30 万~ 500 万个商品,因此其选择的向量数据库应该具备以下特点:
- 高质量、高准确性的搜索结果
- 高效的索引能力
- 快速的查询能力
- 具备负载均衡和数据复制等有助于系统扩展的功能
根据 FARFETCH 团队开展的性能测试,不论是索引创建和向量查询速度,Milvus 始终优于 Weaviate。但是这两个向量数据库都有一定的局限性,比如不支持多编码。FARFETCH 团队将持续密切关注这两个向量数据库的发展,并在开发新功能时重新对这两个向量数据库进行评估。
本案例研究节选自 PEDRO MOREIRA COSTA 的博客。更多相似分析和评估,请阅读博客原文:******POWERING AI WITH VECTOR DATABASES: A BENCHMARK - PART I 和 POWERING AI WITH VECTOR DATABASES: A BENCHMARK - PART II******。