



Milvus 助力 Tokopedia 提升智能搜索体验
10x 更智能
搜索体验
优化
用户体验
提升
系统可扩展性和稳定性
使用 Milvus 后,我们的搜索系统变得更智能、更稳定、更可靠。
Rahul Yadav
Tokopedia 简介
Tokopedia 是印度尼西亚最大的电商平台,目前拥有逾 9000 万月活跃用户和 860 万家商户,覆盖印尼 98% 的行政区。
Tokopedia 团队甚至帮助用户迅速并精准地找到想要的商品才是产品语料库的价值所在。正因如此,Tokopedia 团队致力于提高用户搜索结果的相关性,并引入了相似度搜索。在 Tokopedia 移动应用端的搜索结果页面上点击 ”...” 按钮,即可选择搜索与当前搜索结果类似的产品。
用户痛点:关键词检索
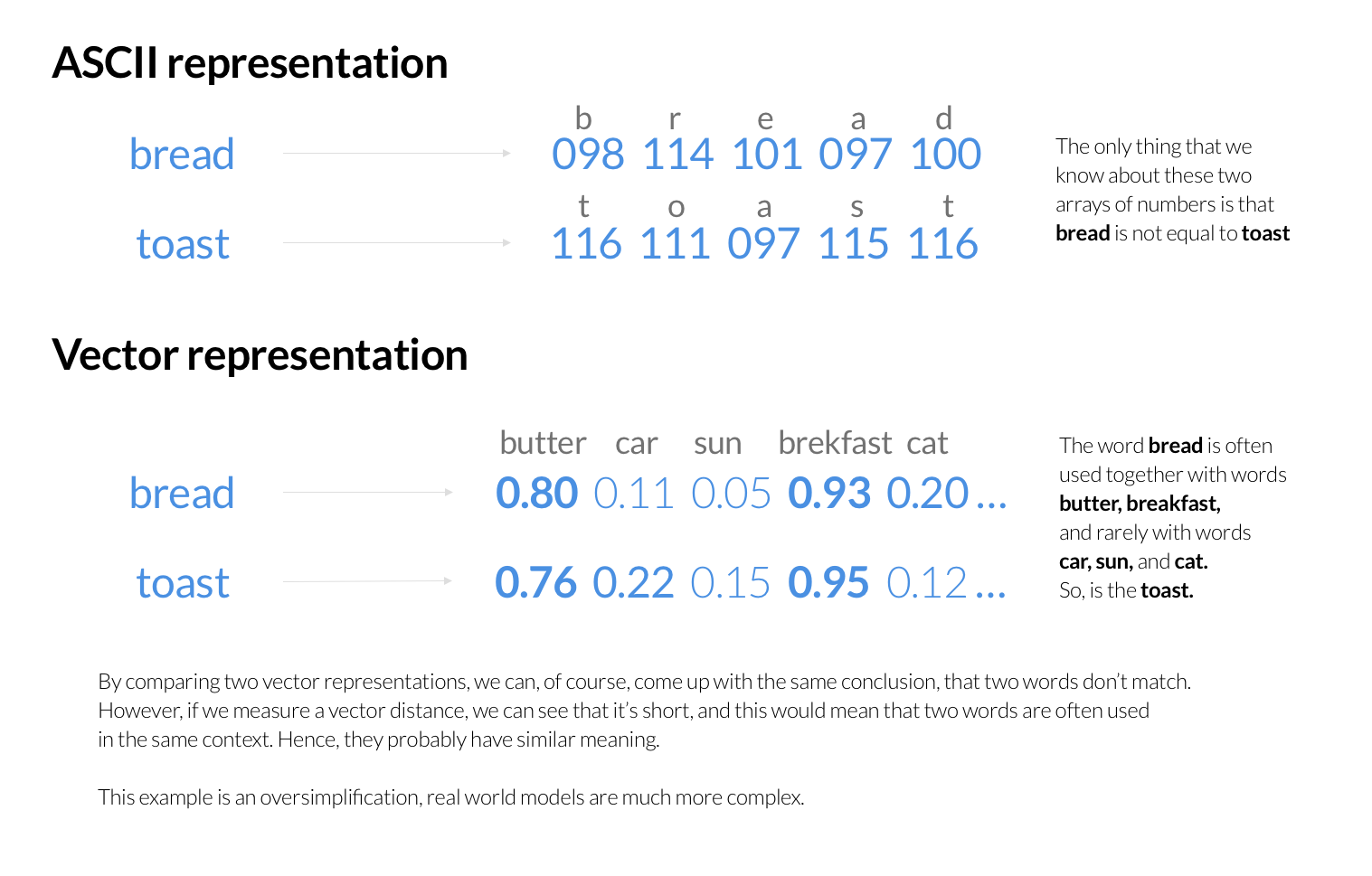
Tokopedia 使用 ElasticSearch 来搜索产品并对搜索结果排序。对于每个搜索请求,ElasticSearch 返回相关搜索结果并根据关键词对搜索结果进行排序。ElasticSearch 将每个单词存储为其组成字母的 ASCII(或 UTF)编码序列,并构建倒排索引以快速检索出包含用户查询关键词的内容,然后使用评分算法找到最佳匹配。这些评分算法鲜少关注这些词的具体含义,而更多基于它们在文档中出现的频率以及它们之间的距离等。尽管 ASCII 编码包含的信息也足以让我们人类理解其原本语义,但仍缺乏一套完善的算法能让计算机也能根据 ASCII 编码理解和比较单词的实际含义。
向量表征
在众多解决方案中,语义向量表征能告诉我们单词是由哪些字母组成的,还能从某种程度上揭露该单词的含义。例如,我们可以对其他经常与该单词一起使用的词进行编码(即潜在上下文,此处默认相似的上下文代表相似的语义),并通过数学计算来比较单词之间的相似度。我们甚至可以试图基于语义对整个句子编码,以得出特征向量。
解决方案:使用 Milvus 向量数据库
在获得目标特征向量后,我们需要从大量的向量数据中检索出与目标向量相似的向量。因此,我们试用了 GitHub 上几个为人熟知的向量搜索引擎和向量数据库,包括 FAISS、Vearch 和 Milvus。
以往的经验告诉我们,FAISS 更像是一个底层库,无法满足我们对于系统便捷性的要求。另外从负载测试结果来看,Milvus 的表现也最令我们满意。随着进一步了解,我们最终决定采用 Milvus,主要基于以下两大优势:
- Milvus 上手容易、使用方便。只需要拉取 Docker 镜像,并根据自己的使用场景修改参数,便可以直接应用于生产环境。
- Milvus 支持更多索引类型,且提供详细的技术文档。
总而言之,Milvus 对用户非常友好,技术文档资源完备。使用过程中遇到的大部分问题都可以在 Milvus 文档中心找到相应的解决方案;即便没有找到合适的解决方案,也可以在 Milvus 社区提问,获取技术支持。
Milvus 集群服务
选定 Milvus 为特征向量数据库后,我们决定将其用于 Tokopedia 广告服务场景中低填充率与高填充率关键词的匹配。我们在开发环境中配置了一个单机版 Milvus 节点提供服务,该节点在数天内都保持了良好的运行状态,明显改善了点击率和转化率。但是,倘若单机版节点在生产环境中宕机,将导致整个搜索服务崩溃。因此,我们需要部署一个高可用的搜索服务。
Mishards 是一款专为 Milvus 开发的集群分片中间件,允许用户搭建内存和算力均可扩容的分布式 Milvus 实例。通过 Mishards 和 Milvus Helm,用户可以轻松部署自己的 Milvus 集群。下图展示了 Mishards 的工作原理:
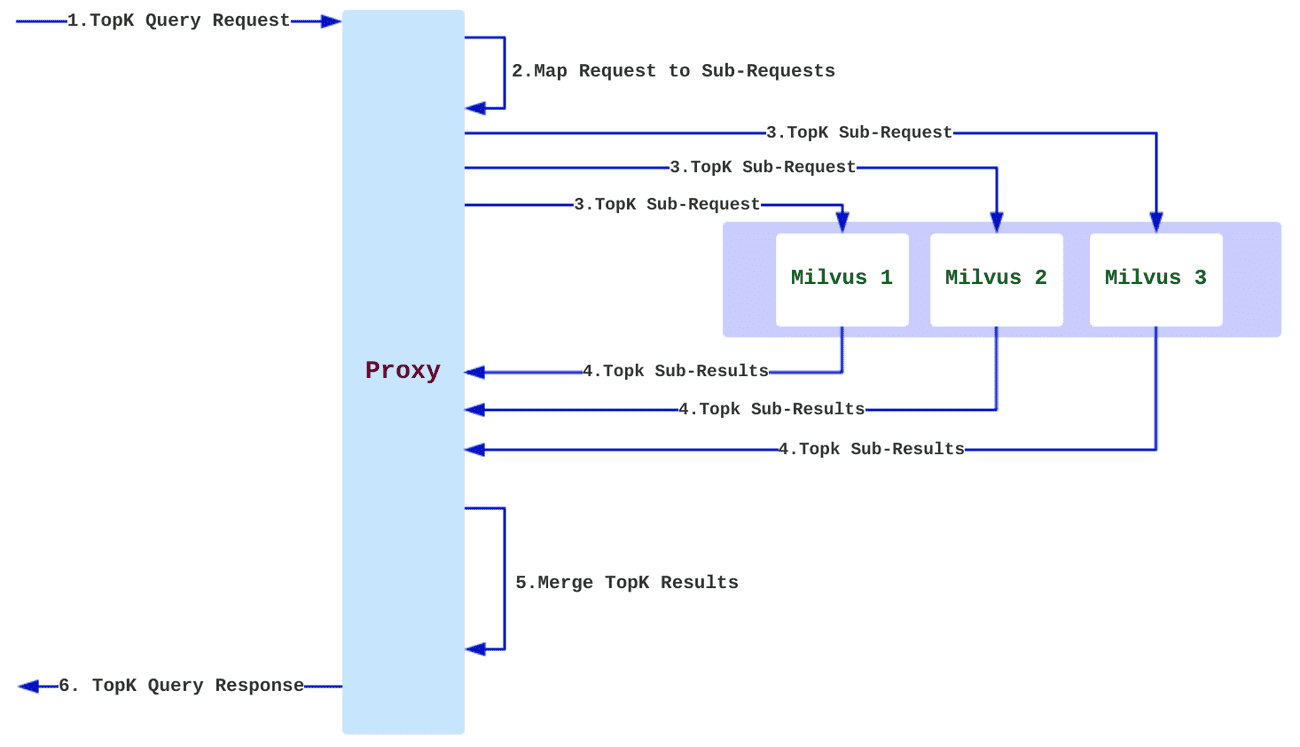 Mishards 工作原理
Mishards 工作原理
Mishards 负责将上游请求拆分,并路由到内部各细分子服务,最后将子服务结果汇总,返回给上游。Mishards 的整体架构如下图所示:
!
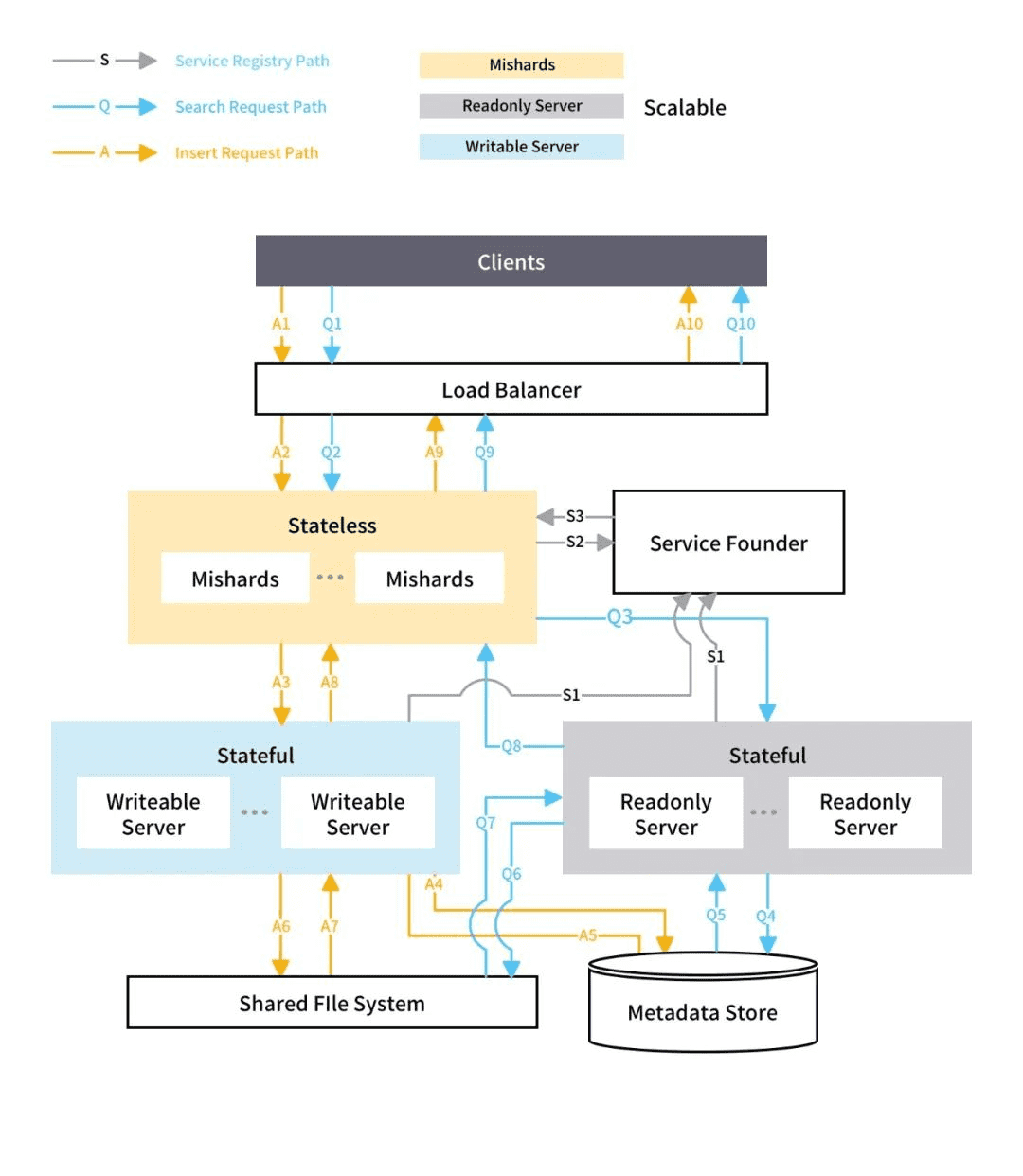 基于 Mishards 的解决方案架构
基于 Mishards 的解决方案架构
我们针对 keyword-to-keyword 服务在 Google Cloud Platform (GCP) 部署了一个 Milvus 写节点、两个 Milvus 读节点以及一个 Mishards 实例,至发稿时始终保持性能稳定。
向量索引如何加速相似性搜索
要想实现百万、十亿甚至万亿级别向量数据的高效检索,索引构建不可或缺。
向量数据库将输入对象与数据库中其他存储对象进行比较,以找到与输入最相似的对象。索引在这个过程中十分重要,它可以高效地组织数据结构,显著加速对大规模数据集的查询性能。对一个大规模向量数据集构建索引后,查询请求将被路由到最有可能包含与该输入相似的向量的集群或数据子集。这加快了数据查询速度,但同时也牺牲了一定程度的准确性。
我们可以将整个数据库比作一本字典,所有单词按字母顺序排列。当查询一个单词时,我们可以通过索引快速跳至仅与查询单词首字母相同的章节,更快速地找到输入单词的定义。
总结
Tokopedia 不断追求性能更加的搜索解决方法。他们最终选择 Milvus,使其语义搜索系统更智能。采用 Milvus 后,Tokopedia 的搜索系统变得更可用,用户可以获得更定制化的搜索结果,用户体验不断提升。借助 Milvus 的力量,Tokopedia 在印度尼西亚甚至是全球电商领域带来了变革。
文本原作者为 Tokopedia 软件工程师 Rahul Yadav。本客户案例经授权后编辑转载。