



唯品会使用 Milvus 搭建个性化推荐系统:性能提升 10 倍

查询速度提升 10 倍
相较于基于 Elasticsearch 搭建的系统
<30 毫秒响应速度
搜索百万级向量数据库
提升用户体验
基于用户购买行为提供更精准的推荐
基于 Milvus 的向量召回在推荐场景的搜索中已经能够稳定使用,其高性能使我们在模型的维度和算法选择上有了更大的发挥空间。
唯品会搜索团队
唯品会简介
唯品会是一家在纽约证券交易所上市的知名在线零售商,总部位于中国,专为消费者提供热门品牌产品及折扣。其产品涵盖时尚、服装、配饰、美容产品、家居用品和电子产品等。唯品会拥有超过 5200 万的庞大客户群,并每年订单量达 2.7 亿,在《财富》杂志中国 500 强排行榜中荣获第 115 位。
用户痛点:使用 Elasticsearch 导致高延时和高运维成本
随着互联网数据规模的爆炸式增长,当前主流电商平台的商品品类及数量越来越多,用户却越来越难以便捷地找到自己需要的产品。
电商搜索推荐系统的核心作用是根据用户的搜索意图及偏好,从海量商品中检索出合适的商品并展示给用户。在这个过程中,系统需要计算商品与用户的搜索意图及偏好之间的相似性,从而将相似度最高的 TopK 个商品推荐给用户。
商品数据、用户搜索意图、用户偏好等数据都属于非结构化数据。唯品会团队曾尝试使用搜索引擎 Elasticsearch(ES)的 CosineSimilarity (7.x) 计算此类数据的相似度,但这种方式存在以下缺点:
- 计算响应时间较长——检索百万商品并召回 TopK 结果的平均延时在 300 ms 左右。
- ES 索引维护成本较高——商品向量数据和其他相关信息数据都使用同一套索引,不仅不便于索引构建,还导致数据规模变得过于庞大。
唯品会团队曾尝试自研局部敏感哈希插件以加速 ES 的 CosineSimilarity 计算,尽管加速后的性能与吞吐量较之前有显著提升,但 100+ ms 的延时还是难以满足实际的线上商品检索需求。
Milvus 解决方案
经过调研比较,唯品会团队决定采用开源向量数据库 Milvus。相较于业界使用的单机版 Faiss,Milvus 的优势在于:支持分布式、多语言 SDK 支持、读写分离等等。
唯品会团队通过各种深度学习模型将海量非结构化数据转化成特征向量导入 Milvus。凭借 Milvus 的出色性能,唯品会团队搭建的电商搜索推荐系统能够高效地查询出与目标向量相似的 TopK 个向量。
基于 Milvus 搭建的唯品会推荐系统架构
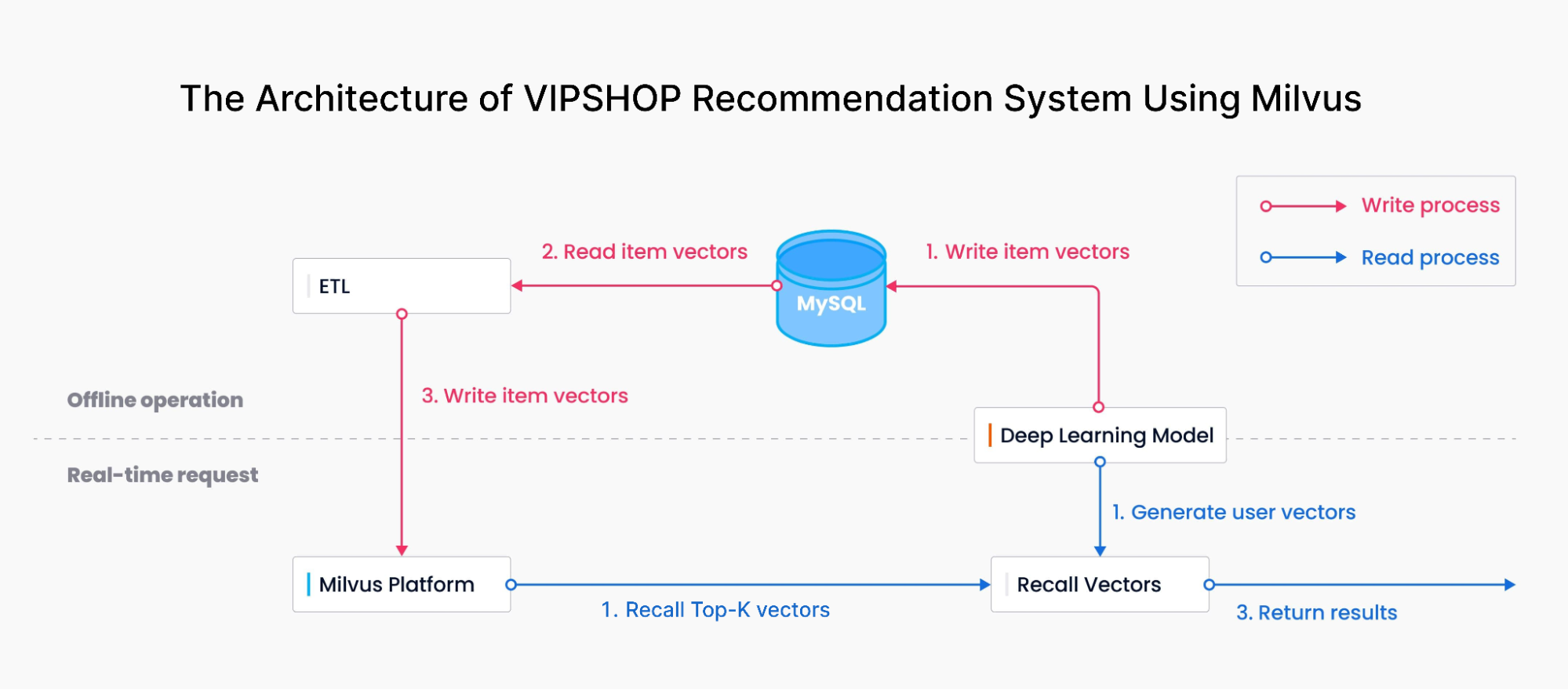
如图所示,整体架构主要分为两部分:
- 写入流程:将深度学习模型产生的 item 向量归一化后写入到 MySQL 中,数据同步工具(ETL)读取 MySQL 中的 item 向量并导入向量数据库 Milvus。
- 读取流程:搜索服务根据用户查询关键词和用户画像获取 user 向量,在 Milvus 中查询相似向量并召回 TopK 个 item 向量。
Milvus 实现细节:数据更新和召回
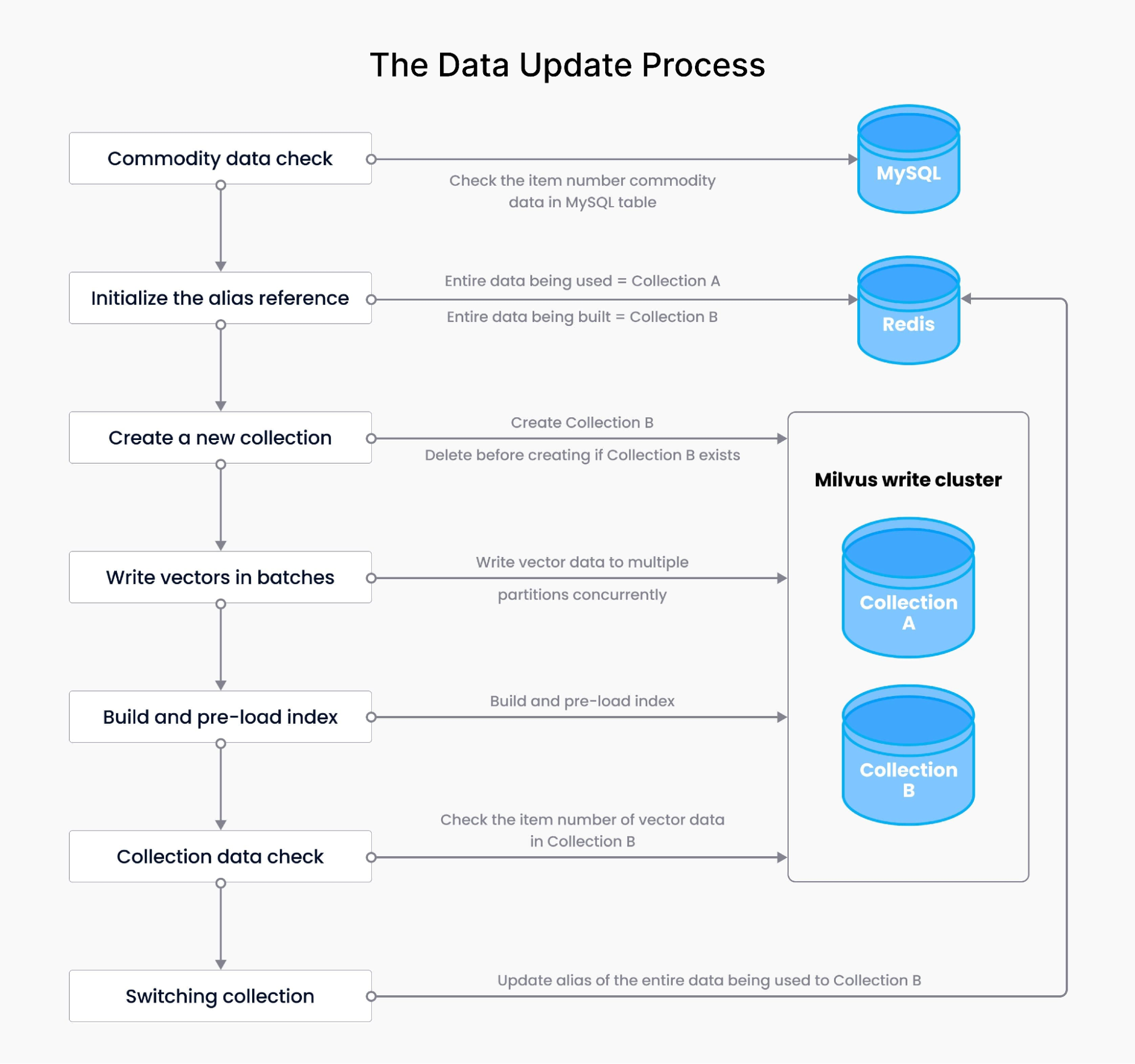
数据更新和召回是推荐系统中最重要的两个环节。
数据更新服务不仅包括写入向量数据,还包括向量的数据量检测、索引构建、查询预热(将索引文件加载到内存)、别名控制等。整体流程如下:
- 假设构建全量数据前,由集合 CollectionA 对外提供数据服务,正在使用的全量数据指向 CollectionA(
redis key1 = CollectionA)。构建全量数据的目的是创建一个新的集合 CollectionB。 - 商品数据校验——检验数据库表内商品数据的条数,对比现有 CollectionA 的数据,可基于数量、百分比设置告警。如未达到设定数量(百分比),则不构建全量数据,视为本次构建失败,告警提醒;一旦达到设定数量(百分比),则启动全量构建步骤。
- 开始构建全量——初始化正在构建的全量数据的别名,更新 Redis(更新后,正在构建的全量数据的别名指向 CollectionB:
redis key2 = CollectionB)。 - 创建新的全量 collection——判断 CollectionB 是否存在。假如存在,先删除再创建。
- 批量写入——对商品数据的 ID 取模,算出其所在分区的
partitionId,分批将多个分区数据写入新创建的 collection。 - 构建索引和预热——为新 collection 创建索引
createIndex(),索引文件存放在分布式存储服务器 GlusterFS。自动模拟请求查询新 collection,将索引内容加载到内存,实现索引预热。 - Collection 数据检验——检验新 collection 的数据,对比现有 collection 的数据,可基于数量、百分比设置告警。如未达到设定数量(百分比),则不切换 collection,视为本次构建失败,告警提醒。
- 切换 collection——别名控制。更新 Redis 后,正在使用的全量别名指向 CollectionB(r
edis key1 = CollectionB),同时删除 Redis key2,构建完成。
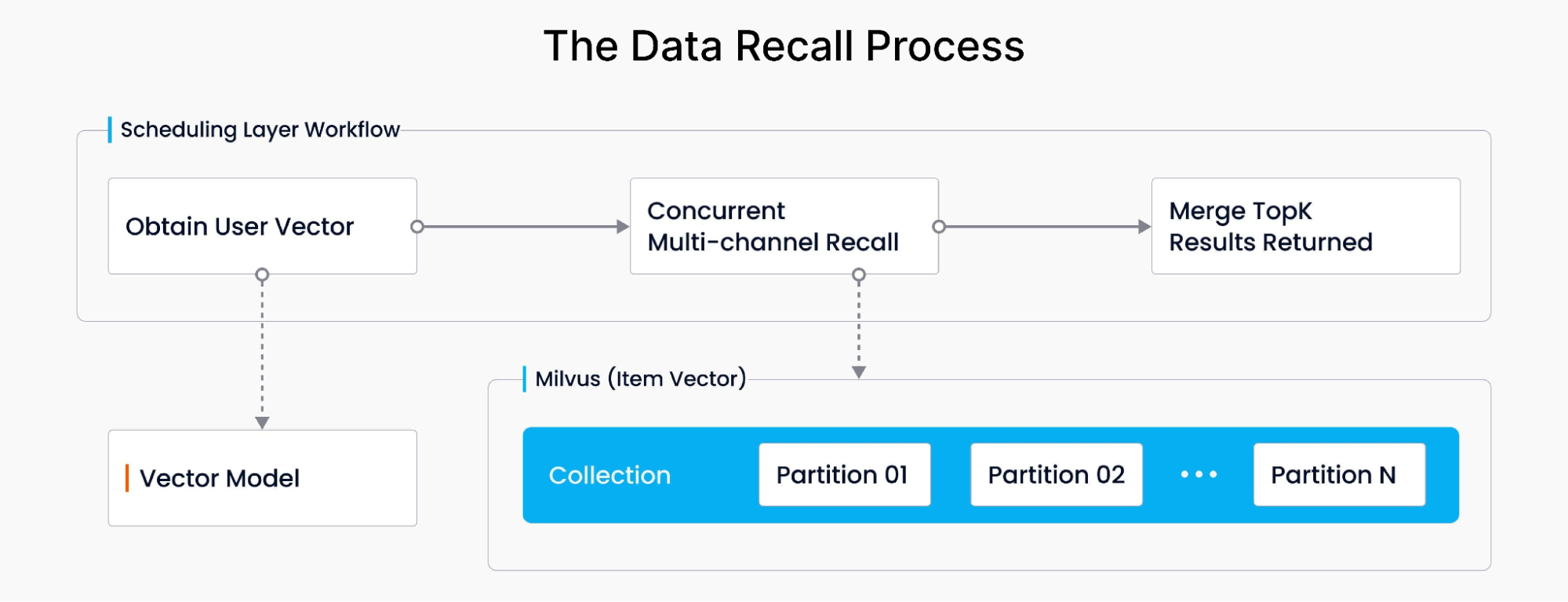
根据用户查询关键词和用户画像获取 user 向量,多次调用 Milvus partition 的数据并计算 user 向量和 item 向量的相似度,汇总后返回 TopK 个 item 向量。整体示意图如下:
下表列出了这一流程涉及到的几个主要服务。可以看出,召回 TopK 个向量的平均延时约 30 ms。
| 服务 | 作用 | 入参 | 出参 | 响应延时 |
|---|---|---|---|---|
| 获取用户向量 | 获取 user 向量 | user info + query | user 向量 | 10 毫秒 |
| Milvus 搜索 | 计算向量相似度,并返回 Top-k 个结果 | user 向量 | item 向量 | 10 毫秒 |
| 调度逻辑 | 并发召回与合并 | N 路召回的商品与分数 | Top-K 商品 | 10 毫秒 |
结果:更出色的系统性能和绝佳的用户体验
使用 Milvus 后,唯品会推荐系统性能得到了极大提升。
查询速度提升 10 倍
使用 Milvus 后,系统查询和响应时间减少到了 30 毫秒以下,比之前使用的 Elasticsearch 解决方案快 10 倍。
系统扩展性更强
分布式 Milvus 支持水平扩展,允许推荐系统在不影响性能的前提下,轻松应对和处理快速增长的数据量和用户查询量。
提升用户体验
Milvus 优化了推荐过程,根据用户偏好和搜索意图提供定制化的产品建议,提高了用户满意度和参与度。
降低运维成本
Milvus 高效处理向量数据并简化了查询机制,降低了推荐系统的总体维护成本。
经验教训与最佳实践
- 对于读操作为主的应用,读写分离部署可大幅增加机器的处理能力,提高性能。
- Milvus Java 客户端没有重连机制,因为召回服务使用的 Milvus 客户端是常驻内存,需要自行建立连接池,通过心跳测试保证 Java 客户端与服务端的连接可用性。
- Milvus 偶尔出现慢查询的情况。经排查,这是由于新 collection 预热不充分。通过模拟请求参数查询新 collection,将索引内容加载到 cache 里以达到索引预热的效果。
- nlist 是建索引参数,nprobe 是查询参数。需要根据自己的业务场景通过压测实验得到合理的阈值,平衡检索系统性能和检索准确率。
- 对于静态数据的场景,先将所有数据导入 collection、后构建索引的做法更高效。