什么是计算机视觉?
引言
计算机视觉是人工智能的一个领域,它使机器能够像人类一样捕获和解释来自世界的视觉信息。计算机视觉的目标是自动化人类视觉系统,以识别对象,理解场景,并在分析视觉数据后做出判断。
在过去的二十年中,由于相机技术的进步,计算资源的增加,以及大量数据的可用性,计算机视觉应用急剧增加。在医疗保健领域,计算机视觉有助于早期发现脑肿瘤或乳腺癌等致命疾病。在汽车行业,它为自动驾驶汽车提供动力,以识别对象和理解道路条件。制造业从自动化质量控制中受益,而零售业则使用计算机视觉进行库存管理和个性化购物体验。计算机视觉的多样化应用正在提高效率,并在各个领域推动创新,为世界带来显著益处。
什么是计算机视觉?
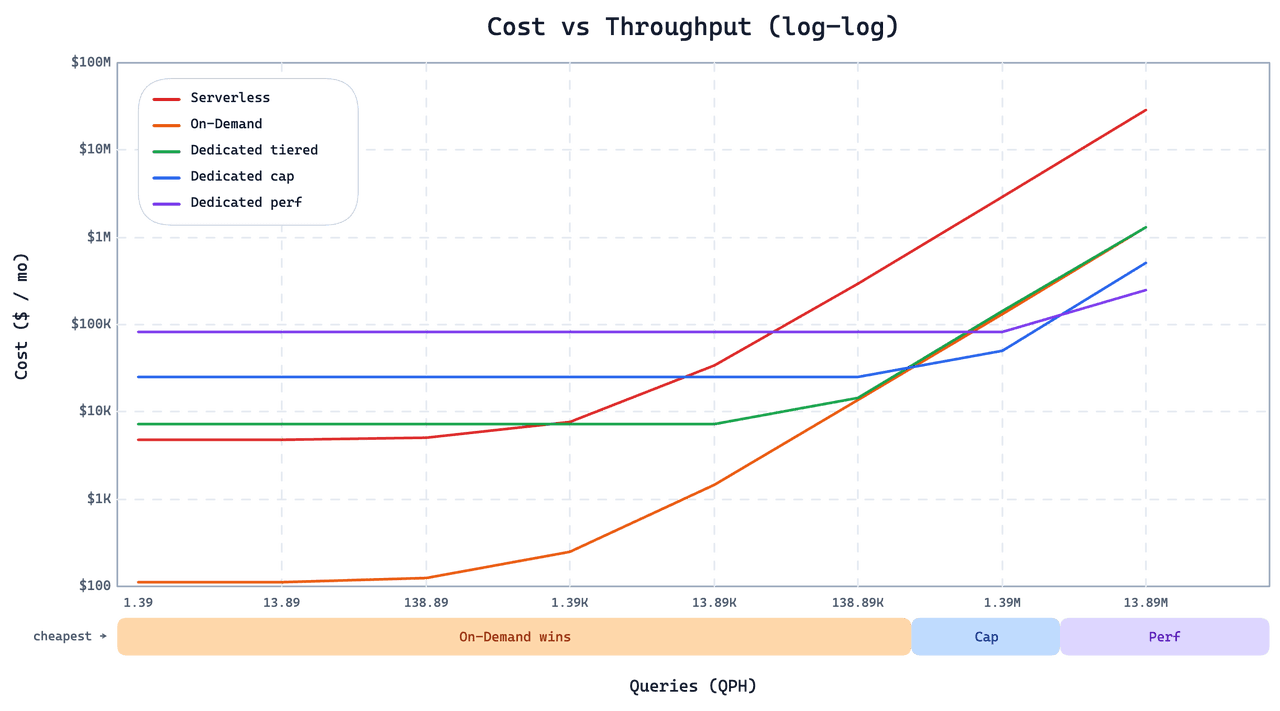
计算机视觉赋予计算机人类在现实世界中看到、分析和解释视觉的能力。想象一下教计算机识别对象,例如识别照片中是否包含狗或猫,或者从视频中识别正在玩的运动是曲棍球还是板球。听起来很有趣,对吧?
 1.png
1.png
什么是计算机视觉?(来源)
在我们的日常生活中,我们经常使用由计算机视觉驱动的应用程序。其中之一是我们智能手机中的面部ID识别。在设置面部ID时扫描您的面部后,算法检测您面部的关键点,并将信息存储以供将来使用。另一个例子是Snapchat滤镜,它让您在面部添加狗耳朵或有趣的帽子。此外,使用视觉搜索时,用户可以在电子商务网站上上传他们喜欢的产品照片,系统会找到类似的产品。因此,计算机视觉已经在我们的日常任务中扮演了不可或缺的角色。
计算机视觉的工作原理
计算机视觉算法的基本工作涉及几个阶段,如下所述。
- 图像采集 - 第一步是通过相机或传感器等设备捕获图像或视频。这些数据是原始的,作为下一个预处理步骤的输入。
- 数据预处理 - 原始数据经过预处理以去除不需要的噪声并增强图像质量,使其适合进一步分析。
- 特征提取 - 处理后的数据随后传递给计算机视觉算法以从图像中提取特征(模式)。一些初始特征是边缘、形状和纹理。随着算法的进一步迭代,它可以检测到更高级的特征。
- 高层理解 - 过程的最后阶段是高层理解。在这里,提取的特征被用于推理以解释图像。输出基于执行的具体任务,如分类、检测等。
计算机视觉任务
- 图像分类 - 图像分类将图像归类为几个预定义的类别/类。这是一个监督任务,因为模型输入图像及其标签。例如,训练有素的图像分类算法可以识别花朵,并将图像分类为“向日葵”、“三色堇”或“水仙花”。
 3.png
3.png
花朵的图像分类(来源)
- 目标检测 - 目标检测识别并定位图像中的对象。模型需要输入图像以及要检测的对象类型(类别)及其坐标。因此,它不仅仅简单地说图像包含狗和猫,目标检测显示它们在图像中的位置。该算法还可以同时检测多个对象。
 4.png
4.png
动物的目标检测(来源)
- 语义分割 - 语义分割用特定类别为图像中的每个像素标记。与关注对象周围的边界框的目标检测不同,语义分割提供了对场景的详细理解。例如,在自动驾驶的情况下,仅仅给出车道、人行道和障碍物的边界框可能不够;相反,我们希望有清晰的标记,可以精细地区分对象的边界。
 5.png
5.png
自动驾驶的语义分割(来源)
- 实例分割 - 实例分割是语义分割的扩展,它区分同一类别的多个实例。例如,在一张有好几辆车的图像中,实例分割不仅标记所有车辆,还区分个别车辆,为每辆车分配一个独特的标签。
 6.png
6.png
汽车的实例分割(来源)
- 关键点检测 - 关键点检测识别对象内的兴趣点,如盒子的角落或人体的关节。这种技术通常用于面部识别等应用中,需要检测眼睛、鼻子和嘴巴等关键面部特征以准确识别。这种技术也可用于对象跟踪,在这种情况下,关键点定义了对象,并且可以监控它们的轨迹,如在动作识别应用中。
 7.png
7.png
面部识别的关键点检测(来源)
计算机视觉技术和模型
在深度学习的背景下,计算机视觉模型是设计用来处理和分析视觉数据(如图像或视频)的算法。它们需要大量的训练数据、用于特征提取的架构以及推理管道,以便在新数据上解决图像分类、目标检测等计算机视觉问题。让我们探索一些最受欢迎的计算机视觉模型。
卷积神经网络(CNN)
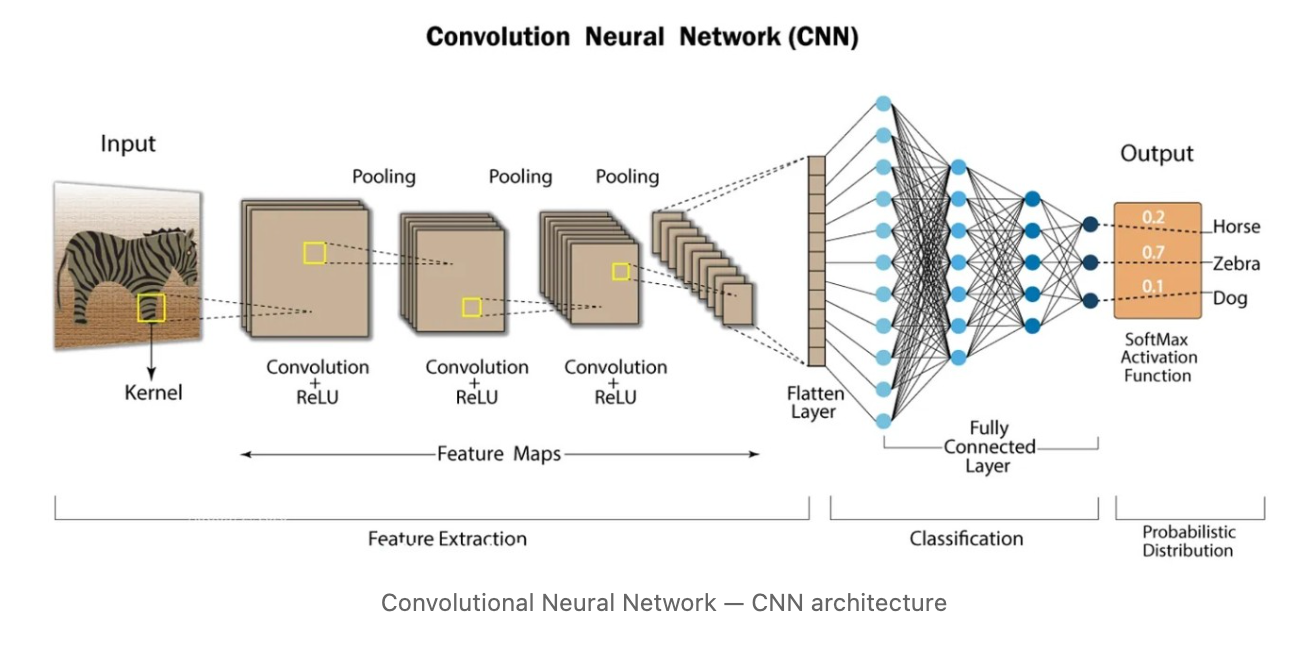
卷积神经网络(CNN)在90年代末发布,是深度学习中最流行的计算机视觉模型之一,彻底改变了图像分类和特征提取。它们通过对输入图像应用卷积滤波器来工作,这有助于从早期层的简单特征(如颜色和边缘)到后续层的更大元素进行层次化的特征提取,最终识别目标对象。
 8.png
8.png
卷积神经网络架构(来源)
目标检测模型
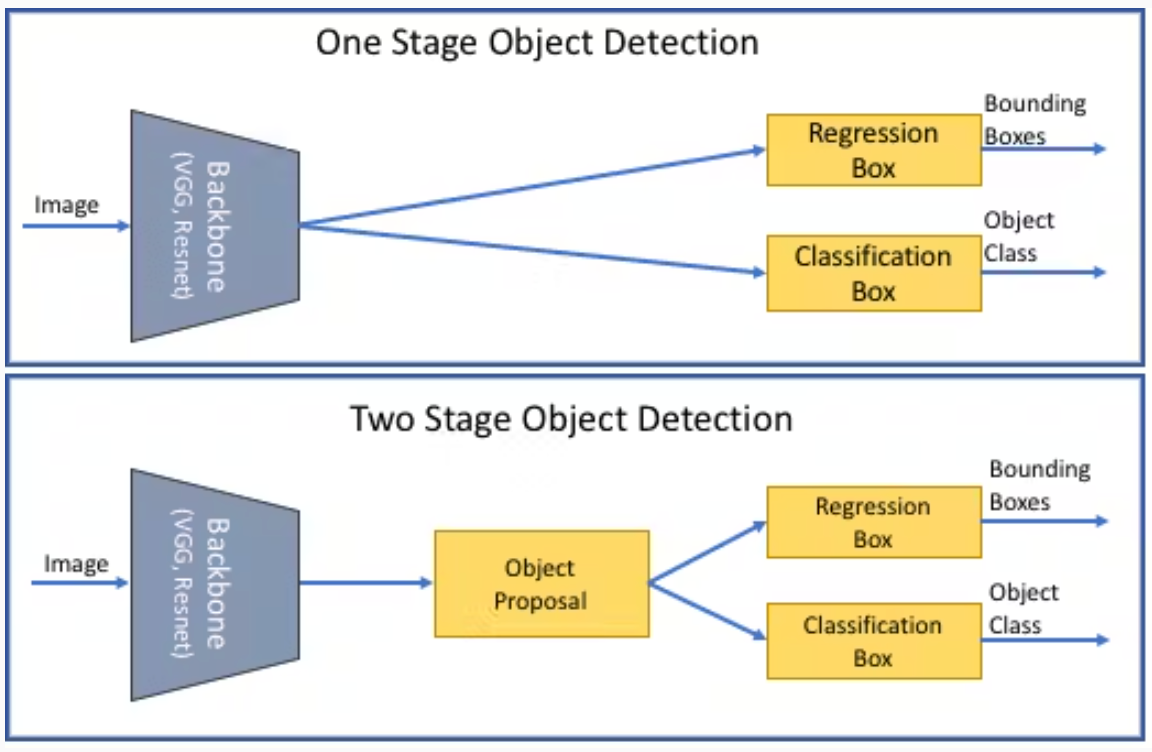
市场上有各种目标检测模型,但它们在计算效率、实时分析和准确性方面有所不同。以下是最常用的几种。
 9.png
9.png
单阶段和双阶段目标检测之间的区别(来源)
YOLO(You Only Look Once)- YOLO在单次传递中处理整个图像,同时预测边界框和类别概率。这种方法使YOLO异常快速,适合自动驾驶等实时应用。然而,它的速度可能以牺牲准确性为代价,特别是对于小的或密集包装的对象。
Faster R-CNN - Faster R-CNN是一个双阶段检测器,它生成区域建议,然后细化这些建议以分类和定位对象。由于两阶段过程,这个模型比YOLO慢,但它在复杂场景中实现了高准确性。Faster R-CNN适用于精度比速度更重要的应用。
SSD(Singleshot Multibox Detector)- 像YOLO一样,SSD在单次传递中处理图像,但使用不同尺度的多个特征图来检测各种大小的对象。SSD比Faster R-CNN快,但通常比YOLO更准确,使其适合需要效率和可靠性的场景。
RetinaNet- RetinaNet是一个像YOLO和SSD这样的单阶段检测器,但它通过一个新颖的焦点损失函数解决了类别不平衡挑战。这种方法使其特别适合在复杂环境中检测小对象。RetinaNet在速度和准确性之间提供了良好的平衡。
图像分割模型
图像分割模型将图像划分为段,每个段对应于图像中要预测的给定对象类别。图像分割模型主要分为三种类型。
- 语义分割 - 为图像中的每个像素分配一个类别标签。
- 实例分割 - 它标记每个像素,并区分同一类别的不同实例。
- 全景分割 - 这种技术结合了语义分割和实例分割。它提供了一个统一的输出,在该输出中,每个像素都被分类,如果适用,还会被分配一个实例ID。
一些流行的图像分割模型包括U-Net、FCNs、Mask R-CNN和DeepLab。
生成模型
与基于输入数据预测标签或类别的判别模型不同,生成模型旨在理解和捕获数据的底层分布,允许它们创建与原始数据相似的新样本。一些常见的生成模型包括生成对抗网络(GANs)、变分自编码器(VAEs)、自回归模型和基于流的模型。这些模型可以应用于图像合成(创建逼真的图像)、超分辨率(增强图像质量)、风格迁移(将艺术风格应用到图像上)和数据增强(生成额外的训练数据)。
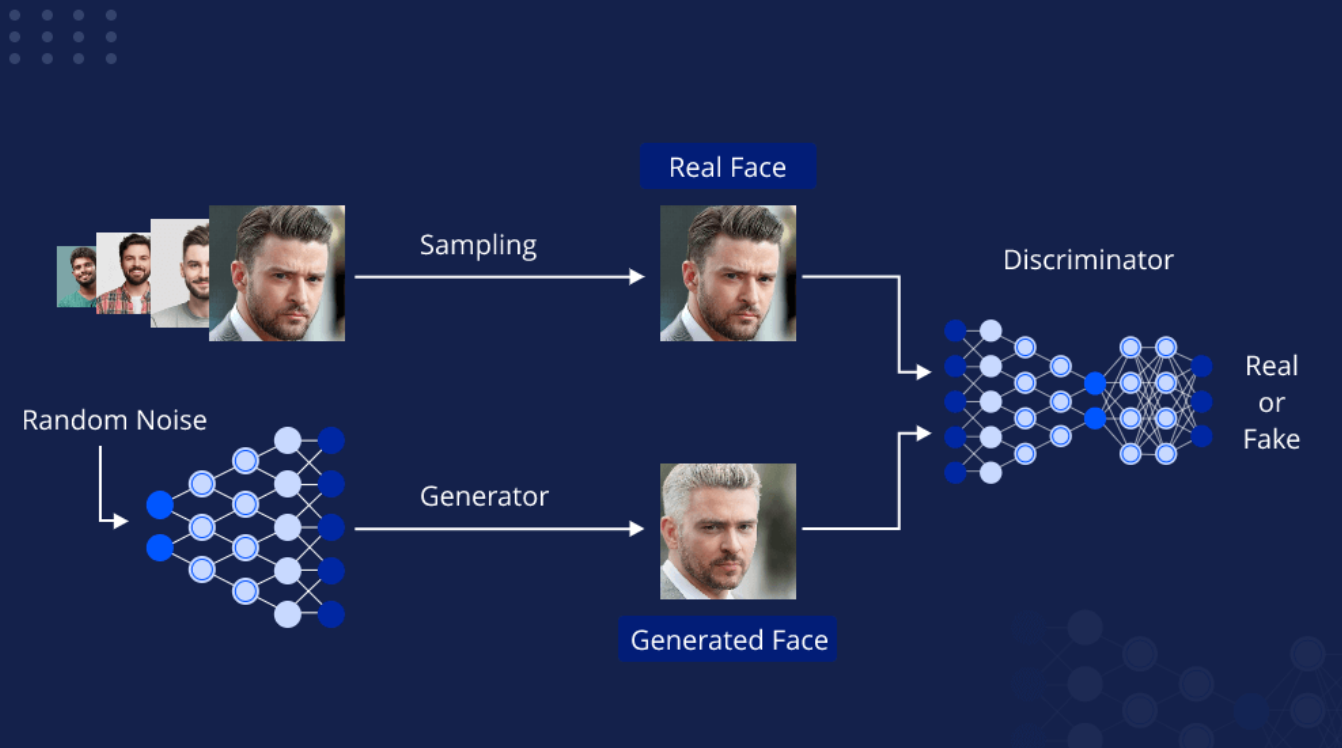 10.png
10.png
GAN的基本管道(来源)
特征提取模型
特征提取模型是任何计算机视觉管道的骨干。这些模型捕获输入数据的基本特征(特征),以便后续的计算机视觉任务处理。它们有助于降低输入数据的维度,增强相关信息,并使系统更加健壮。一些流行的传统特征提取方法包括SIFT(尺度不变特征变换)、SURF(加速稳健特征)和HOG(方向梯度直方图)。虽然这些模型需要手动调整,并且无法捕获复杂模式,但像CNNs这样的深度学习模型来救援。目前,要提取新任务的特征并且数据有限,可以利用预训练的CNN模型,如VGGNet、ResNet和Inception进行微调。
目标跟踪模型
目标跟踪模型监控并跟踪对象在视频帧中的移动。这些模型不断更新对象的位置,尽管外观、尺度或背景发生变化,但随着时间的推移保持其身份。它通常以目标检测阶段开始,在第一帧中识别对象。然后跟踪模型预测对象在后续帧中的位置,通常使用光流、卡尔曼滤波器或基于深度学习的跟踪器等技术。这些模型适用于监控、自动驾驶车辆、体育分析、增强现实等。
3D视觉模型
3D视觉模型是从二维图像或视频中解释和重建三维结构的算法。这些模型使机器能够感知深度、形状和空间关系,使它们能够以三维方式理解世界。它们使用立体视觉(结合两个或更多不同角度的图像)、从运动中推断结构(从视频中的运动线索中推断3D结构)和深度估计(预测对象与相机的距离)等技术。3D视觉模型的一些应用在自动驾驶车辆、机器人技术、增强现实和医学成像中。
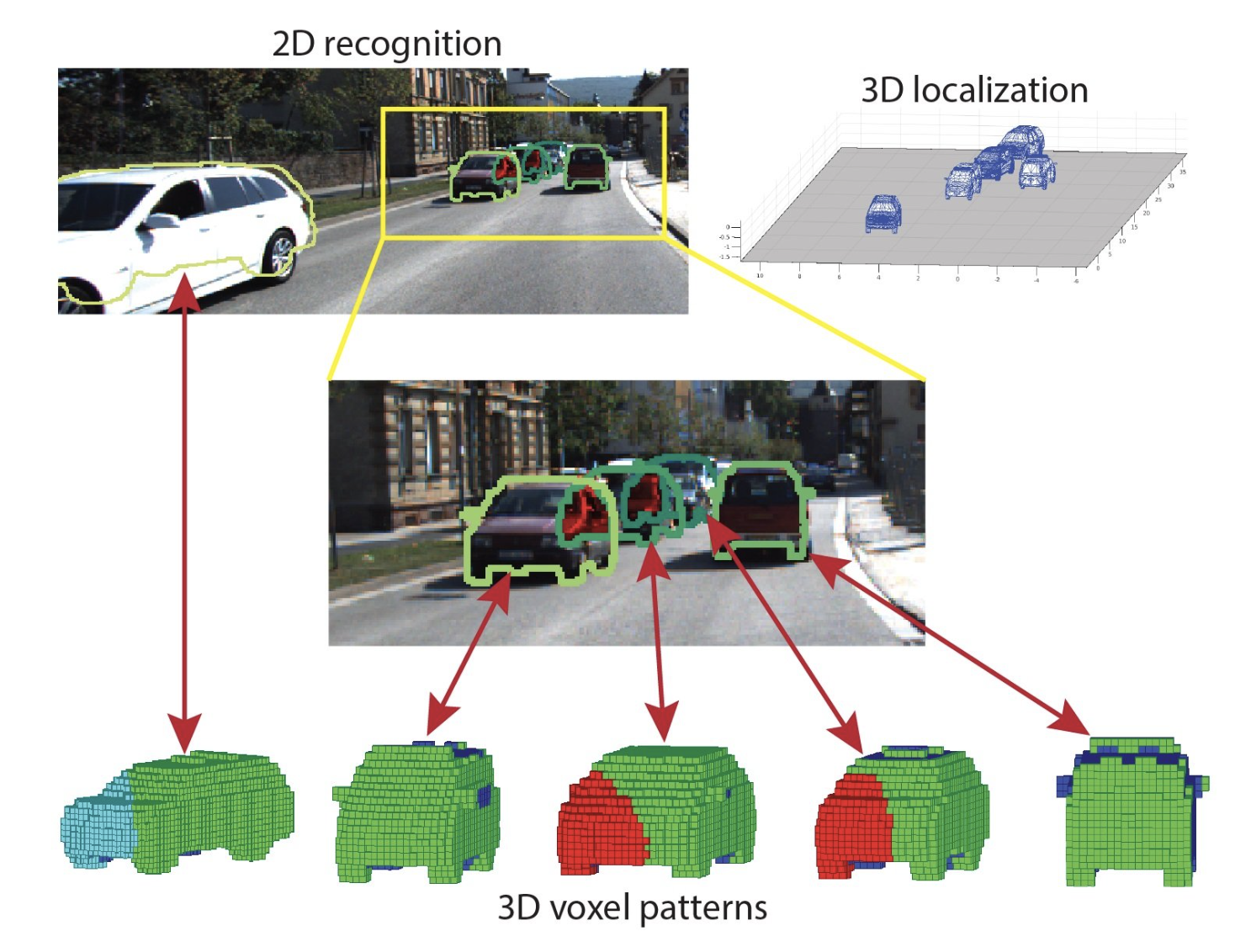 11.png
11.png
简单的3D视觉模型可视化(来源)
视觉变换器
视觉变换器(ViTs)将最初为自然语言处理(NLP)设计的变换器架构应用于图像分析。与传统的CNN不同,ViTs将图像处理为一系列补丁,将每个补丁类似于句子中的单词。它们将图像划分为固定大小的补丁,将它们展平,然后线性地将它们嵌入到向量中。这些向量,连同位置编码,被输入到标准变换器模型中。与CNN相比,ViT模型在计算机视觉任务中表现出色;因此,它们是目前最先进的模型。ViT模型主要分为三种类型:标准ViTs、混合模型(CNN和变换器组合)和DeiT(数据高效图像变换器),后者需要较少的训练数据即可实现高性能。
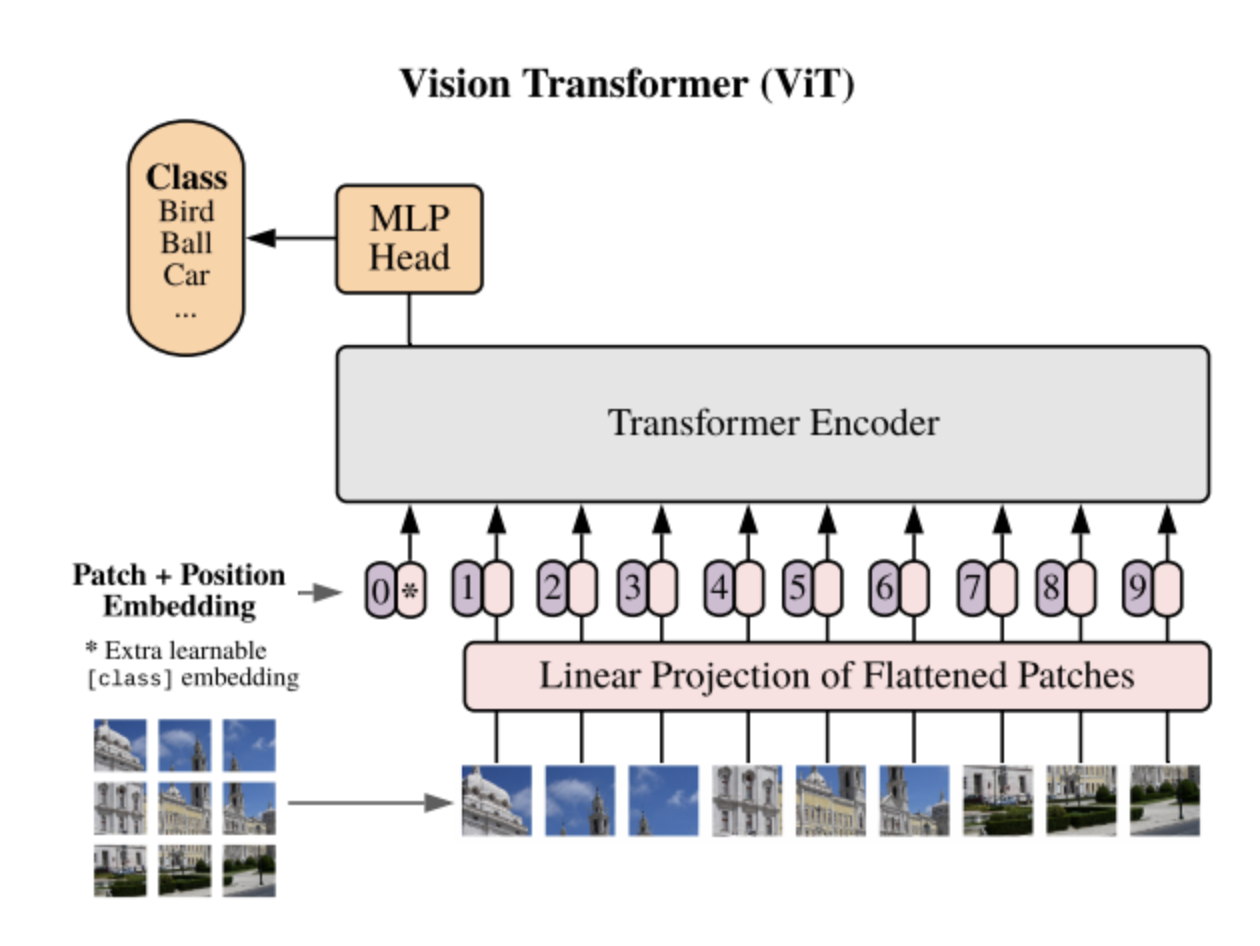 12.png
12.png
ViT架构(来源)
使用视觉变换器和向量数据库进行高效图像搜索
高效的图像搜索需要在庞大的数据集中找到与查询图像相似的图像,这一过程对于视觉搜索引擎、数字资产管理和内容推荐系统等应用至关重要。
向量数据库,如Milvus和Zilliz Cloud(完全管理的Milkus),在图像搜索过程中发挥关键作用,通过将图像存储为高维向量——使用先进的计算机视觉模型从图像中提取的特征的数值表示。这些向量捕获了图像的基本特征,使数据库能够通过比较高维空间中的向量距离高效检索相似图像。
视觉变换器(ViTs)通过将图像划分为补丁并使用自注意力机制捕获这些补丁之间的全局关系来增强这一过程。处理后,ViTs输出代表整个图像的特征向量。当图像输入系统时,ViT生成其特征向量,然后存储在向量数据库中。
要检索相似图像,查询图像由ViT处理以生成其特征向量。然后向量数据库将此查询向量与所有存储图像的向量进行比较,根据它们在向量空间中的接近程度检索最相似的图像。这种方法确保了即使在大型数据集中,也能通过利用ViTs强大的特征提取能力实现高精度和高效的图像检索。
通过将ViTs与向量数据库结合,组织可以实现更快、更准确的图像搜索能力,显著提高各个行业基于图像的应用程序的性能。
总结
计算机视觉是一个变革性的领域,它使机器能够解释和理解来自世界的视觉信息。计算机视觉系统复制人类视觉功能,并通过执行图像分类、目标检测和图像分割等任务自动化各种过程。该领域已经取得了显著的发展,从CNN、Faster R-CNN和U-Net等基础模型开始。今天,像生成模型、3D视觉模型和视觉变换器(ViTs)这样的先进方法正在重塑视觉数据的处理和分析方式。此外,将像ViT这样的高级计算机视觉技术与向量数据库整合,可以解锁为各个行业带来好处的强大应用。
注:本文为AI翻译,查看原文
 Yesha Shastri
Yesha ShastriFreelance Technical Writer in AI/ML