1bit压缩+高召回,RaBitQ如何成为AI infra的embedding 量化最优解
Milvus2.6 版本更新的诸多功能中, RaBitQ 1-bit Quantization(以下简称 RaBitQ)无疑是最耀眼的亮点。
它将向量量化压缩推向极致,实现 FP32 向量压缩至 1:32 的极致比率,同时保持高召回率,帮助开发者在模型训练为代表的海量数据场景下显著降低资源消耗。
本文将深入剖析 RaBitQ 的技术细节与实际应用,并通过一个上手案例,让你快速感受到其魅力。
如果你正为向量数据库的内存瓶颈烦恼,这篇文章将为你带来实用启发。
01
RaBitQ 1-bit Quantization 的具体介绍
RaBitQ 源于论文《RaBitQ: Quantizing High-Dimensional Vectors with a Theoretical Error Bound for Approximate Nearest Neighbor Search》https://arxiv.org/abs/2405.12497。它专为高维向量设计,通过将 FP32(32 位浮点数)向量压缩为二进制表示(每个维度仅 1 bit),实现极端存储优化,同时借助理论误差界限保证搜索准确性。
核心原理
高维空间的几何特性利用:传统量化方法(如 PQ 或 SQ)往往在压缩时丢失过多信息,导致召回率下降。RaBitQ 则巧妙利用“浓度度量”(Concentration of Measure)现象:在高维空间(例如 1000维以上),向量坐标值趋于围绕零点集中。这使得简单二进制编码就足以捕捉关键信息,而非精确的空间坐标。
角度信息编码:不同于传统空间编码,RaBitQ 通过向量归一化(normalization)聚焦于角度信息(angular information)。具体来说,在 IVF(Inverted File)聚类框架下,向量相对于最近的 IVF 质心(centroid)进行归一化量化。这种方法增强了量化精度,避免了传统 1-bit 方法的精度损失。
智能精炼机制:RaBitQ 结合 IVF 聚类和可选精炼(refinement)策略,形成 IVF_RABITQ 索引。粗搜索阶段使用二进制索引快速过滤候选,精炼阶段则恢复部分原始信息,确保最终召回率接近基线(无压缩)。
与 Milvus 的集成
在 Milvus 2.6 中,RaBitQ 通过新索引类型 IVF_RABITQ 实现,支持高度可配置的压缩比(默认 1:32)。
索引类型:IVF_RABITQ
度量:L2、COSINE、IP
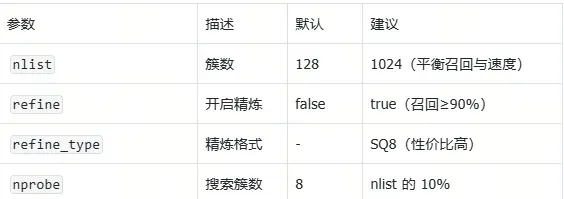
关键参数:
 640.webp
640.webp
搜索时可调 rbq_query_bits(查询量化,0=无) 和 refine_k(精炼倍数)。
相比传统方法,RaBitQ 的优势在于“零精度损失”:基准测试显示,它在 SIFT1M 数据集上实现 72% 内存减少,同时 QPS 提升 4 倍,且召回率保持在 95% 以上。 这让它成为生产环境的首选量化工具。
02
引入 RaBitQ 的意义和应用场景
引入意义
Milvus 2.6 的 RaBitQ 并非简单的技术迭代,而是针对 AI 基础设施痛点的战略回应。随着数据规模从亿级跃升至万亿级,内存消耗已成为向量数据库的“阿喀琉斯之踵”。传统量化虽能节省空间,但往往以牺牲搜索质量为代价,导致应用效果打折。
传统 FP32 存储内存爆炸(1B 向量 ≈ 3TB),PQ/SQ 虽压缩但召回低。RaBitQ 首次让 1-bit 量化实用化:
- 32× 压缩:1 bit/维度,内存降至原 1/32。
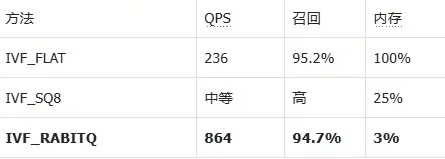
- 3× QPS:基准测试中,IVF_RABITQ 达 864 QPS(94.7% 召回),碾压 IVF_FLAT 的 236 QPS。
- 硬件加速:AVX-512 VPOPCNTDQ(Intel Ice Lake+ / AMD Zen4)下,位运算飞起。
对比:
 640 (1).webp
640 (1).webp
作为开源项目,RaBitQ 与 Zilliz Cloud 集成,提供自动化配置 profile,根据负载动态调整参数。这不仅降低了运维门槛,还推动 AI 民主化,让中小团队也能处理亿级向量。
应用场景
RaBitQ 适用于资源敏感的高负载场景:
- 推荐系统:在电商或内容平台中,处理亿级用户嵌入向量。RaBitQ 压缩后,可在低成本服务器上支持实时推荐,提升点击率而无需扩容。
- 语义搜索:如 RAG(Retrieval-Augmented Generation)管道中,压缩文档嵌入库,加速 LLM 查询响应,同时保持语义准确性。
- 多模态 AI:图像/视频检索应用中,量化高维特征向量,适用于边缘设备或移动端,减少传输延迟。
- 边缘计算:IoT 或 AR/VR 场景下,部署在内存受限的设备上,实现本地向量搜索。
03
手把手教程:快速上手 RaBitQ
为了让你快速上手,我们用一个 Python 示例演示 RaBitQ 在 Milvus 中的应用。场景:插入 1000 个随机 128D 向量,创建 IVF_RABITQ 索引,进行 ANN 搜索。
from pymilvus import MilvusClient, DataType
import numpy as np
import random
# 1. 连接 & 创建集合
client = MilvusClient("http://localhost:19530")
client.drop_collection("rabitq_col") # 清理
schema = client.create_schema(auto_id=False, enable_dynamic_field=False)
schema.add_field("id", DataType.INT64, is_primary=True)
schema.add_field("embedding", DataType.FLOAT_VECTOR, dim=768)
client.create_collection(collection_name="rabitq_col", schema=schema)
# 2. 插入 100k 随机向量
rows = []
for i in range(100000):
rows.append({"id": i, "embedding": np.random.random(768).tolist()})
insert(client, "rabitq_col", rows, 3)
# 3. 创建 IVF_RABITQ 索引
index_params = client.prepare_index_params()
index_params.add_index(
field_name="embedding",
index_type="IVF_RABITQ",
metric_type="L2", # 或 IP/COSINE
params={
"nlist": 1024,
"refine": True,
"refine_type": "SQ8" # 高召回
}
)
client.create_index("rabitq_col", index_params)
# 4. 加载集合
client.load_collection("rabitq_col")
print("Collection loaded")
# 5. 搜索(Top-10)
query_vectors = [np.random.random(768).tolist()]
search_params = {
# "metric_type": "L2",
"params": {
"nprobe": 128, # 搜索簇数
"rbq_query_bits": 0, # 无查询量化=最高召回
"refine_k": 2 # 精炼 2 倍
}
}
res = client.search(
collection_name="rabitq_col",
data=query_vectors,
anns_field="embedding",
search_params=search_params,
limit=10,
output_fields=["id"]
)
print(res)
为了提高批量插入数据的成功率,我们实现了一个带有重试机制的插入方法:
def insert(client, collection_name, data, max_retries):
"""批量插入数据,带重试机制"""
total = len(data)
batch_size = 20000
total_inserted = 0
failed_batches = []
for i in range(0, total, batch_size):
batch = data[i:i + batch_size]
batch_num = i // batch_size + 1
success = False
for attempt in range(max_retries):
try:
result = client.insert(collection_name, data=batch)
count = result.get('insert_count', len(batch))
total_inserted += count
print(f" Batch {batch_num}/{(total-1)//batch_size + 1}: "
f"{count} rows (Total: {total_inserted}/{total})")
success = True
break
except Exception as e:
if "larger than max" in str(e):
new_batch_size = batch_size // 2
if new_batch_size < 10:
print(f" Batch {batch_num} failed: batch too small to split")
failed_batches.append((i, batch))
break
print(f" Batch too large, reducing size to {new_batch_size}")
batch_size = new_batch_size
break
else:
print(f" Attempt {attempt + 1}/{max_retries} failed: {e}")
if attempt < max_retries - 1:
time.sleep(2 ** attempt)
if not success and batch not in [b[1] for b in failed_batches]:
failed_batches.append((i, batch))
return total_inserted, failed_batches
输出结果:
data: [[{'id': 3723, 'distance': 111.82170104980469, 'entity': {'id': 3723}}, {'id': 8974, 'distance': 112.3028793334961, 'entity': {'id': 8974}}, {'id': 6612, 'distance': 113.15422058105469, 'entity': {'id': 6612}}, {'id': 9513, 'distance': 113.48468780517578, 'entity': {'id': 9513}}, {'id': 1756, 'distance': 114.02412414550781, 'entity': {'id': 1756}}, {'id': 4104, 'distance': 114.40816497802734, 'entity': {'id': 4104}}, {'id': 681, 'distance': 114.434814453125, 'entity': {'id': 681}}, {'id': 6757, 'distance': 114.61549377441406, 'entity': {'id': 6757}}, {'id': 3454, 'distance': 115.34103393554688, 'entity': {'id': 3454}}, {'id': 5080, 'distance': 115.34539031982422, 'entity': {'id': 5080}}]]
运行说明:索引构建时间 < 1 秒,搜索延迟毫秒级。
调优Tips:
- 召回优先:refine=true, refine_k=5。
- 速度优先:rbq_query_bits=6。
接下来,让我们实测下启用RaBitQ之后,内存占用量减少情况。由于Milvus没有直接查看collection占用内存数据的方法,我们通过 milvus docker container 内存数据 来粗略对比下 collection 内存占用量。
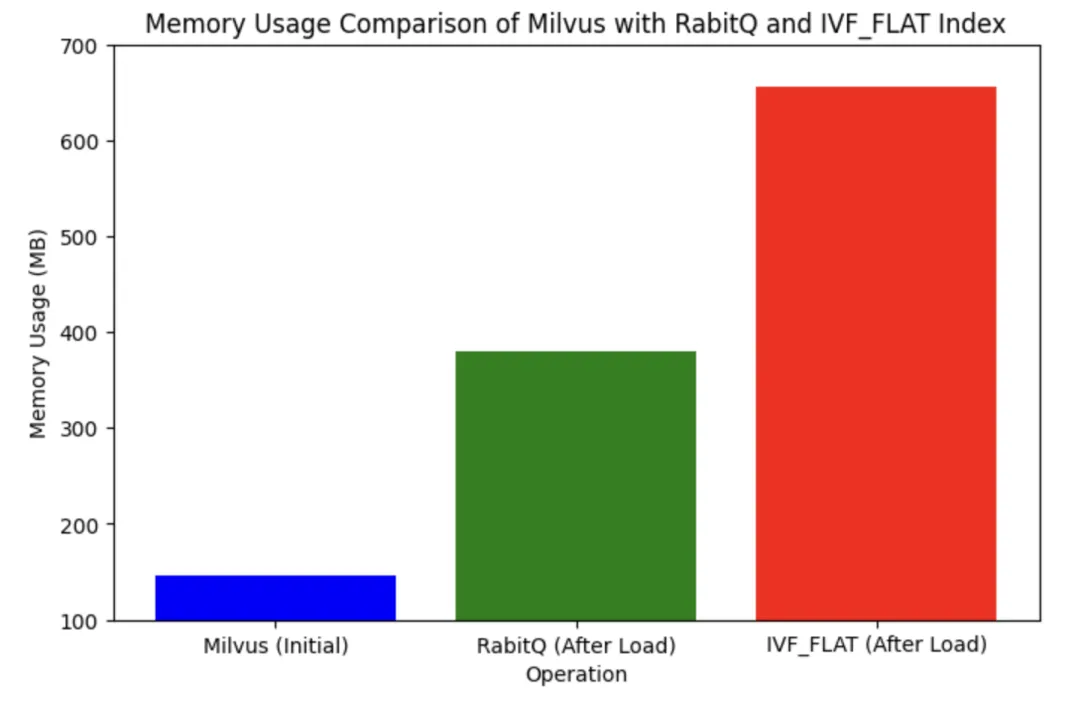
通过 docker stats milvus-standalone --no-stream 我们可以看到,milvus启动后,内存占用 146M
 640 (2).webp
640 (2).webp
在集合 rabitq_col load之后,内存是 380M
 640 (3).webp
640 (3).webp
对比测试集合采用 IVF_FLAT 索引,插入与集合 rabitq_col 相同的数据,对比下内存占用。
在此之前,我们先 release 下之前加载的集合 rabitq_col
client.release_collection(
collection_name="rabitq_col"
)
res = client.get_load_state(
collection_name="rabitq_col"
)
print(res)
测试集合采用 IVF_FLAT 索引,集合名字是 ivf_flat_col
schema = client.create_schema(auto_id=False, enable_dynamic_field=False)
schema.add_field("id", DataType.INT64, is_primary=True)
schema.add_field("embedding", DataType.FLOAT_VECTOR, dim=768)
client.create_collection(collection_name="ivf_flat_col", schema=schema)
# 插入相同 100k 数据
insert(client, "ivf_flat_col", rows, 3)
index_params_flat = client.prepare_index_params()
index_params_flat.add_index(
field_name="embedding",
index_type="IVF_FLAT",
metric_type="L2",
params={"nlist": 1024}
)
client.create_index("ivf_flat_col", index_params_flat)
# 加载集合
client.load_collection("ivf_flat_col")
print("Collection ivf_flat_col loaded")
集合加载完成之后,查看内存占用 655M
 640 (4).webp
640 (4).webp
总体来看,集合 ivf_flat_col 的内存使用量明显高于 rabitq_col,可见 RaBitQ 有效节约了内存。
 640 (5).webp
640 (5).webp
 臧伟
臧伟