向量搜索背后的流行机器学习算法
向量搜索是现代数据检索和相似性查询的基础部分。想象一下,面部识别技术在机场或体育场等高流量地点自动化安全监控。每张脸被转换成一个高维向量,代表独特的面部特征。然后,这个向量与存储在像 Milvus 这样的向量数据库中的数据进行比较,使用向量相似性搜索来识别潜在风险并及时预防安全问题。
向量搜索就像拥有一个超级智能助手,它理解你查询的本质,并在大量数据中快速找到最佳匹配项。无论你是在网上寻找产品、在流媒体服务上探索推荐内容,还是分析复杂数据集,向量搜索都能快速实现。
在本文中,我们将探讨向量搜索的本质以及一些流行的机器学习算法,这些算法为高效的向量搜索提供动力,例如 K-最近邻 (ANN) 和近似最近邻 (ANN)。
向量搜索的本质
向量搜索,也称为向量相似性搜索或最近邻搜索,是一种信息检索系统技术,旨在识别与特定查询向量紧密对齐的数据点。这种方法将非结构化数据如图像、文本和音频表示为高维空间中的向量,旨在有效定位和检索与查询向量紧密匹配的向量。
通常使用距离度量(如欧几里得距离或余弦相似性)来评估向量之间的相似性,向量空间中的接近程度表示接近性。为了便于有效的组织和检索,向量搜索算法采用索引结构如基于树的结构或哈希技术。
随着 AI 驱动应用的发展,向量搜索的发展已经取得了进步,从根本上改变了数据处理和分析。从驱动推荐系统到促进自然语言处理,向量搜索引擎在 AI 应用中扮演着关键组件的角色,这些应用涵盖了电子商务、医疗保健和金融等多个领域。随着这些技术的进步,向量搜索有望发挥越来越具有变革性的作用,重塑我们在数字时代与复杂数据集的互动和理解方式。
两种流行的机器学习算法为高效的向量搜索提供动力:K-最近邻 (KNN) 算法和近似最近邻 (ANN) 算法。在以下部分中,我们将探讨它们是什么以及它们如何工作来为向量搜索提供动力。
什么是 K-最近邻 (KNN) 算法?
K-最近邻 (KNN) 算法是一种广泛使用的机器学习方法,用于分类和回归任务。该算法基于这样一个原理:相似的数据点在高维空间中聚集在一起,这使得数据中的模式识别逻辑和直观。
在其数据训练阶段,KNN 不构建传统模型,而是保留整个数据集以供参考。在进行预测时,它使用选定的距离度量(如欧几里得或余弦距离)测量新输入数据点与训练数据集中所有现有点之间的距离。然后,算法确定 K 个最接近的训练示例或“邻居”到新数据点。在分类任务中,KNN 将这些 K 个邻居中最常出现的类别标签分配给新数据点。在回归任务中,算法基于这些邻居的值的平均值或加权平均值预测一个值。
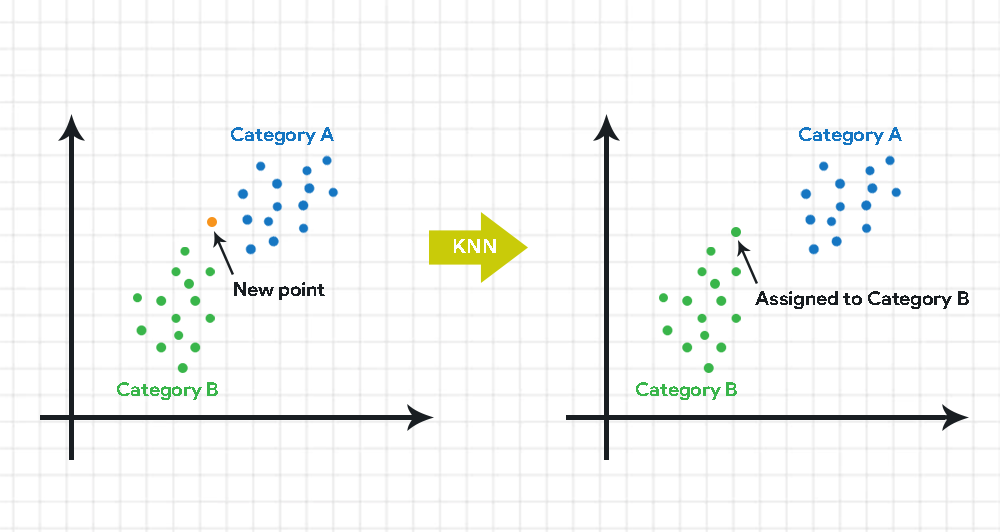
下面的图表显示了 KNN 算法的工作原理。为了对新数据点进行分类,KNN 计算该点与每个类别(如类别 A 和类别 B)的 K 个最近邻居之间的距离。在确定距离后,算法根据这些计算出的距离,将数据点分配给其 K 个最近邻居中最普遍的类别。在这个例子中,新点被分配给类别 B。
 65.png
65.png
K-最近邻 (KNN) 算法的工作原理
KNN 算法的有效性将受到 K(考虑的最近邻居数量)和使用的距离度量的选择的影响。因此,调整这些参数对于实现最佳性能至关重要。
有关 ANN 算法的更多信息,请参考我们的博客:机器学习中的 K-最近邻 (KNN) 算法是什么?
KNN 在向量搜索中的应用
在向量搜索应用中,每个数据点都表示为一个高维向量,KNN 算法可以有效地检索与特定查询相似的向量。该算法计算查询向量与数据集中每个其他向量之间的距离,然后根据这些计算出的距离选择 Top-K 最近向量。
调整 'K' 的值提供了优化向量搜索精度和效率之间平衡的灵活性。这种灵活性使 KNN 算法在推荐系统、图像检索和文本语义搜索等各种领域中极具价值,这些领域中快速识别相似向量至关重要。
什么是近似最近邻 (ANN) 算法?
近似最近邻 (ANN) 算法是一种流行的机器学习和数据科学技术,用于在像 Zilliz Cloud 这样的高性能向量数据库中高效地进行最近邻搜索。
您可以将 ANN 视为 K-最近邻 (KNN) 算法的优化版本。与对数据集中的每个数据点进行全面搜索不同,ANN 算法以高概率识别近似最近邻,显著降低计算成本。这种优化使 ANN 非常适合需要快速查询响应的应用,即使是在庞大的数据集中也是如此。
ANN 在向量搜索中的应用
ANN 算法通过在索引阶段构建专门的索引结构来简化向量搜索,就像绘制一个地图,标明可能包含相似向量的区域。这种映射允许 ANN 在查询阶段有效地缩小潜在邻居的范围,而无需单独评估每个向量。相反,它使用这些预先构建的地图来对最近邻居进行有根据的估计。
虽然这些预测可能并不总是达到 100% 的准确性,但它们对于许多应用来说已经足够精确,提供了显著的速度优势。这种效率对于管理大型数据集和导航高维空间至关重要,使 ANN 在推荐系统和图像搜索等领域中不可或缺,这些领域中快速有效的查询至关重要。
有关 ANN 的更多信息,请参见我们的页面:什么是近似最近邻搜索 (ANNS)?
KNN 与 ANN 搜索
ANN 搜索与 KNN 搜索的关键区别在于搜索结果的精度以及速度和计算资源需求方面的性能。
精度和准确性
KNN 搜索:这种算法在数据集中找到查询点的确切 k 个最近邻居。它通过评估所有可能的邻居来保证准确性,根据指定的距离度量确定最近的邻居。
ANN 搜索:与 KNN 不同,ANN 搜索旨在找到近似最近邻居。这种方法为了提高速度和效率而牺牲了一些准确性。这种方法并不总是保证确切的最近邻居,但提供的结果足够接近,对于许多实际应用来说是足够的。
性能(速度和资源使用)
KNN 搜索:虽然极其准确,但 KNN 可能计算成本高昂且速度慢,特别是对于大型数据集,因为它需要比较每一个点。这也可能导致显著的内存和处理能力需求。
ANN 搜索:通过专注于近似结果,ANN 搜索算法如局部敏感哈希(LSH)、树或基于图的方法可以快速检索结果,减少计算开销。这些方法在处理大型数据集或实时应用中特别有益,其中速度至关重要。
范围搜索:提高向量搜索精度
虽然 KNN 和 ANN 是向量搜索的高效算法,但它们仅限于返回预定数量的最近邻居。这可能导致结果的冗余。例如,使用 KNN 或 ANN 驱动的向量搜索,体育新闻聚合器可能会因为一次初始阅读而重复推荐有关同一场足球比赛的文章。这种限制可能会降低内容多样性和用户参与度。此外,包括向量数据库在内的向量搜索技术有一个 Top-K 约束,因此对数百万或数十亿数据点的数据集的查询可能会潜在地忽略数千个相关结果,通过处理和传输大量数据量来增加系统资源的负担。
Milvus 向量数据库引入了 Range Search 功能,这是一种在 KNN 和 ANN 算法之上优化的搜索方法。这种方法通过在查询期间指定输入向量和数据库向量之间的距离范围,允许更平衡的检索。这种精度对于需要对搜索结果进行细致控制的应用特别有利,例如数据去重或版权侵权检测,确保没有遗漏相似候选。
以下是如何使用 Range Search 功能定义搜索距离参数的方法:
#
在这段代码中,搜索被配置为返回与输入向量距离在 10 到 20 单位之间的向量,提供精确的结果子集。
总之,向量搜索的本质在于在各种应用中高效地处理和检索高维数据向量。KNN(K-最近邻)通过分析高维空间中数据点的接近程度来确保精确的数据分类,这使得它对于需要高准确性的任务非常有价值。另一方面,ANN(近似最近邻)通过近似最近邻为大型数据集提供了一种速度高效的解决方案,从而平衡了性能和计算效率。这两种算法都在改变安全、电子商务、医疗等领域中发挥着重要作用,它们增强了机器学习系统分析和解释大量数据集的能力。 尽管 ANN 和 KNN 算法在向量搜索中都很有效,但它们也有局限性,并且有改进性能的空间。Milvus 向量数据库提供了一个范围搜索功能,允许用户在查询期间指定输入向量和存储在 Milvus 中的向量之间的距离,从而获得更准确和平衡的检索结果。
了解更多:深入研究和资源
这些资源将帮助您理解向量搜索技术及其在各个领域的应用。
学术论文
[1603.09320] 使用层次化可导航小世界图的高效和鲁棒近似最近邻搜索,作者:Yu. A. Malkov 和 D. A. Yashunin。
[2204.07922] 神经嵌入上相似性查询高效处理的综述,作者:Yifan Wang。
[1806.09823] 高维近似最近邻搜索,作者:Alexandr Andoni, Piotr Indyk, Ilya Razenshteyn。
教程和博客
Milvus 2.3.4:更快的搜索、扩展的数据支持、改进的监控等。
比较向量数据库、向量搜索库和插件。
 Fendy Feng
Fendy FengFendy Feng is the Product Marketing Manager at Zilliz.
 Samin Chandeepa
Samin ChandeepaFreelance Technical Writer