



优化人工智能:稳定扩散与高效缓存策略指南
引言
人工智能行业正以闪电般的速度发展。模型和应用程序变得越来越复杂,不断推动可能的边界。如OpenAI的DALLE-2、稳定扩散、Midjourney等文本到图像的生成模型,能够在几秒钟内创造出高度逼真和多样化的图像。
扩散模型的影响不仅限于生成视觉上吸引人的图像。它们有潜力通过实现个性化和引人入胜的视觉内容的创造,彻底改变各个行业。例如,扩散模型可以生成定制产品,创建沉浸式虚拟体验,甚至协助开发视频游戏和动画。
然而,随着这些模型在复杂性和性能上的增长,它们也需要更多的计算能力来高效运行。这就是为什么优化对人工智能模型至关重要。
本文将探讨各种缓存策略,以优化稳定扩散模型。
理解稳定扩散
稳定扩散是一个开源的深度学习模型,它能够根据文本描述生成高质量的图像。它只需要一个体面的GPU或GPU服务器,这些可以每小时以几分钱的价格租用。
模型是在大量的图像-文本对数据集上训练的,学习生成与给定文本描述相匹配的图像。它使您可以仅使用文本来修改图像,使其成为各种应用中非常通用的工具。
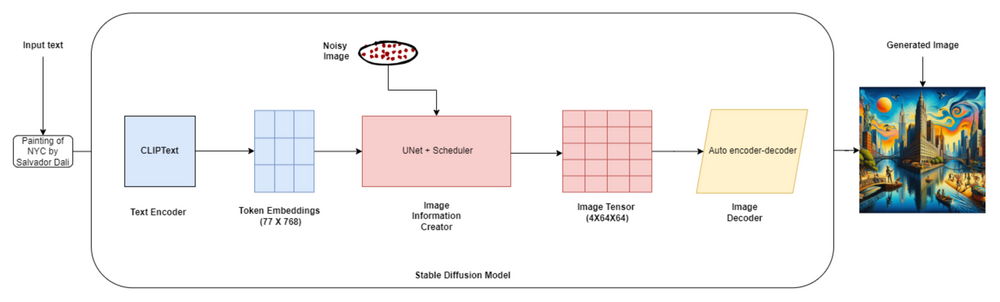
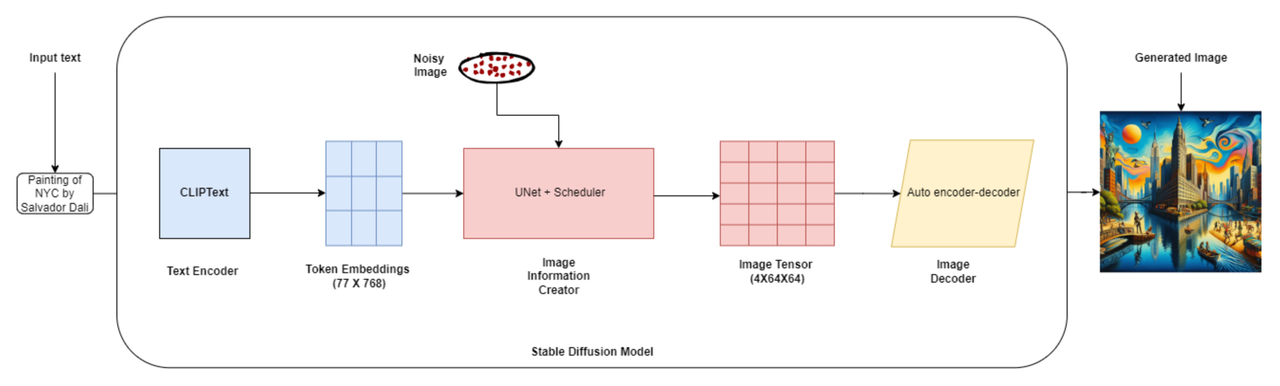
它是如何工作的?稳定扩散结合了扩散模型的概念和潜在表示学习,创建视觉连贯且详细的图像,这些图像与给定的文本输入非常接近。
一般来说,扩散模型的训练过程涉及在不同尺度上用高斯噪声破坏输入图像,然后通过预测每个步骤中需要移除的噪声来学习逆转这个过程。模型通过逐步去噪图像,逐渐生成与给定提示相匹配的清晰、高质量的图像。
 32.1.png
32.1.png
稳定扩散架构
稳定扩散的架构由三个关键组件组成:
文本编码器(OpenAI的CLIP):文本编码器将输入文本描述映射到潜在空间,可以用来在图像生成过程中调节U-Net。
变分自编码器(VAE):VAE负责将图像编码成潜在表示,并将它们解码回原始图像空间。
噪声估计网络(U-Net):U-Net是一个卷积神经网络,它预测每个去噪步骤中需要移除的噪声,引导生成过程朝着所需的输出图像。
以下是整个过程的简化分解:
文本编码:假设您想生成“一个在花园里玩耍的可爱的小狗”的图像。文本编码器采用这个提示并将其转换为数值表示。
潜在空间初始化:想象一下,您想生成一个256x256像素的图像。潜在空间初始化将创建一个形状为(1, 256, 256, 3)的随机噪声张量作为起点。
扩散过程:扩散过程逐步细化潜在表示。在每一步中,U-Net将带噪声的潜在表示和编码文本提示作为输入,并预测需要移除的噪声。
迭代细化:假设扩散过程包括1000个时间步。在每个时间步,U-Net细化潜在表示,使其更少噪声、更连贯。
图像解码:在扩散过程之后,最终的潜在表示通过解码器网络传递以生成输出图像。解码器将潜在表示转换为像素值。
为什么需要优化?
API成本:通过提高推理速度、减少内存消耗并实现有效资源利用,优化稳定扩散模型可以降低API成本。
速度需求:在许多实际应用中,如交互式图像编辑工具或实时图像生成系统,快速推理速度对于提供无缝用户体验至关重要。优化显著减少了推理时间。
可扩展性:优化后的模型可以处理更高数量的请求,并能够扩展以满足不断增长的需求。
资源效率:AI优化技术减少了内存占用和计算需求,允许成本效益高的部署。
部署灵活性:优化后的模型可以部署在各种硬件平台上,包括资源受限的设备,扩大了它们的适用性。
现在,让我们看看缓存如何改善这个过程。
缓存在AI模型中的作用
缓存是一种基本技术,涉及将经常使用的数据 - 或在生成AI模型的情况下:之前计算的结果 - 存储在快速访问的内存位置,以便重用。
概念很简单:当用户提示模型时,我们可以将该请求保存到数据库中,下次用户发出相同或类似的提示时,模型可以使用一些保存的数据来响应。
鉴于顺序去噪过程和庞大的模型尺寸,稳定扩散可能导致显著的计算成本。然而,对于这种资源密集型的模型,缓存可能是一个改变游戏规则的因素,有效地存储和检索推理过程中生成的中间激活和嵌入。
各种缓存策略可以提高计算效率:
向量数据库:这些专门构建的数据库能够存储高维数据作为向量,可以快速检索从广泛的机器学习模型生成的潜在表示和向量嵌入。为最常见的查询设置向量数据库可以减少重新计算的需求,并提高模型推理速度,使它们成为您缓存策略武器库中的多功能工具。
记忆化:记忆化是一种有效的缓存技术,它存储昂贵函数调用的结果,并在再次遇到相同的输入时检索缓存的结果。这种策略优化了递归算法和具有重复计算的函数,消除了冗余计算并提高了执行速度。
潜在缓存:模型缓存了先前处理输入的潜在表示。当遇到相似的输入时,可以检索缓存的潜在表示,绕过重新计算的需要。
时间基缓存:时间基缓存为缓存中的每个项分配一个到期时间或生存时间(TTL)值。当指定的到期时间到达时,该项将被删除或标记为无效,需要从原始源重新获取以确保数据的相关性和有效性。
缓存驱逐策略:当缓存达到其容量时,缓存驱逐策略决定从缓存中移除哪些项。常见的驱逐策略包括先进先出(FIFO)、后进先出(LIFO)、最近最少使用(LRU)、最少频繁使用(LFU)和随机替换,每种策略都使用不同的标准来选择要移除的项。
还有一些特别的新型缓存策略是专门为像稳定扩散这样的扩散模型开发的:
DeepCache:DeepCache无需额外训练即可加速扩散模型。它通过缓存和检索去噪阶段之间的特征来施展魔法,消除了冗余计算。通过巧妙地重用高级特征和高效更新低级特征,DeepCache实现了令人印象深刻的速度提升,同时保持了一流的图像质量。
近似缓存:近似缓存巧妙地重用先前图像生成的中间噪声状态,减少新提示所需的去噪步骤数。这种技术可以通过利用提示之间的相似性跳过初始步骤,节省宝贵的计算时间。它与一个智能缓存管理策略LCBFU配对,以确保模型效率。
块缓存:块缓存利用层输出随时间平滑变化的优势,根据它们在网络中的位置识别出不同的模式。通过重用前几步的输出,它避免了冗余计算。借助巧妙的尺度偏移对齐技巧和自动调度,块缓存保持了性能的峰值并避免了伪影。
在稳定扩散中实现缓存
稳定扩散中的缓存旨在存储和重用中间计算,避免冗余计算并加速图像生成过程。
关键思想是在模型的前向传递过程中识别和缓存频繁使用或计算密集型的中间结果,如潜在表示或注意力图。
以下是如何在稳定扩散中使用向量数据库实现缓存策略:
确定缓存可以提供显著性能提升的层或模块,如自注意力层或绕过U-net过程。
实现一个缓存机制,以在前向传递过程中存储这些层的中间结果。在稳定扩散模式的前向传递期间,将中间潜在表示和嵌入存储在向量数据库中。
在随后的前向传递过程中,检查向量数据库中是否有可用(且对当前输入有效)的缓存结果。如果找到接近的匹配项,检索缓存的结果而不是重新计算它们(这减少了所需的去噪步骤数),并将其用作扩散过程的起点。
在必要时更新或使向量数据库中的缓存失效,例如当输入或模型参数更改时。
伪代码示例:
import faiss
class StableDiffusion:
def __init__(self, autoencoder, unet, conditioning_model):
self.autoencoder = autoencoder
self.unet = unet
self.conditioning_model = conditioning_model
self.vector_db = faiss.IndexFlatL2(latent_dim) # Initialize vector database
def generate_image(self, conditioning_input, timesteps):
latent = self.autoencoder.encode(conditioning_input)
# Query the vector database for similar latent representations
distances, indices = self.vector_db.search(latent, k=1)
if distances[0] < threshold:
# Retrieve cached latent representation
latent = self.vector_db.reconstruct(indices[0])
else:
for t in timesteps:
latent = self.diffusion_step(latent, t, conditioning_input)
# Add the new latent representation to the vector database
self.vector_db.add(latent)
image = self.autoencoder.decode(latent)
return image
用例和好处
使用高效的缓存策略优化稳定扩散模型在现实世界中有多种应用和好处。让我们探索一些用例:
数字艺术创作:艺术家和设计师可以利用优化后的稳定扩散模型高效地生成高质量的数字艺术。模型可以通过缓存经常使用的风格或模式快速生成变化或迭代,简化创作过程。
内容生成:媒体和娱乐公司可以利用优化后的稳定扩散模型大规模生成多样化和引人入胜的视觉内容。通过高效的缓存,模型可以快速生成基于相似文本输入的图像,实现快速内容创建和个性化。
产品可视化:电子商务平台可以采用优化后的稳定扩散模型为各种类别和风格的产品生成逼真的产品图像。缓存频繁访问的产品属性或风格可以显著加快图像生成过程,增强用户体验并降低计算成本。
挑战和考虑因素
虽然在稳定扩散中实施缓存提供了显著的好处,但也有一些挑战和需要考虑的因素:
内存管理:在缓存大小和可用内存之间取得平衡很重要。像缓存驱逐策略或压缩技术这样的策略可以帮助有效管理内存。
索引和搜索效率:随着向量数据库的大小增长,相似性搜索效率可能成为瓶颈。选择适当的向量索引策略,如分层可导航小世界(HNSW)图,以提高搜索性能和可扩展性。
缓存失效:随着模型的发展或新数据的引入,缓存的表示可能变得过时或无效。实施缓存失效策略,如基于时间的过期或版本控制,对于确保缓存数据的新鲜度和准确性至关重要。
可扩展性:在处理大规模应用或数据集时,缓存大小可能会显著增长。设计能够高效扩展的缓存策略,如分布式缓存或使用基于云的存储解决方案,是必不可少的。
缓存一致性:在分布式环境或多节点设置中,维护不同模型实例之间的缓存一致性可能是具有挑战性的。实施同步机制或使用分布式缓存框架可以帮助确保数据一致性。
延迟和吞吐量:查询向量数据库以获取相似输入会为图像生成过程引入额外的延迟。您必须在缓存命中率和延迟之间取得平衡,以保持快速性能。批量处理或异步更新等技术可以帮助提高吞吐量。
要应对这些挑战,定期监控缓存系统以帮助识别瓶颈并优化性能。
结论
通过利用向量数据库和潜在缓存、块缓存、近似缓存等缓存技术,您可以显著提高AI应用程序的性能、可扩展性和成本效益。
实施这些缓存策略确实带来了挑战。但不要被吓倒——通过利用缓存策略,您可以直接应对这些挑战,并找到适合您特定项目的解决方案。
有了优化后的稳定扩散模型在用户指尖,可能性是无限的。您有潜力创造出曾经无法想象的惊人创作。

Ankur Ashtikar
Freelance Technical Writer


技术干货
向量数据库发展迎里程碑时刻!Zilliz Cloud 全新升级:超高性价比,向量数据库唾手可得
升级后的 Zilliz Cloud 不仅新增了诸如支持 JSON 数据类型、动态 Schema 、Partition key 等新特性,而且在价格上给出了史无前例的优惠,例如推出人人可免费使用的 Serverless cluster 版本、上线经济型 CU 等。这意味着,更多的开发者可以在不考虑预算限制的情况下畅用云原生向量数据库。
2023-6-15
技术干货
如何在 Jupyter Notebook 用一行代码启动 Milvus?
本文将基于 Milvus Lite,为大家介绍如何在 Jupyter Notebook 中使用向量数据库。
2023-6-12
技术干货
GPTCache 悬赏令!寻找最佳捉虫猎手,豪华赏格等你来拿!
捉虫数量越多,奖品越丰厚!
2023-8-2