



用户案例|Shopee 在多媒体理解业务的向量检索系统实践
Shopee 是一家全球性的电商平台,业务范围辐射东南亚、拉美等多个地区。多媒体理解(Multimedia Understanding,下文简称 MMU)团队是 Shopee 内专注于提供多媒体内容理解服务的团队,为电商、直播、短视频等业务提供支持。
MMU 团队需要支持公司不同业务场景对多媒体理解的需求。以向量检索为例,可能会有如下业务场景:
实时推荐,如视频召回系统
视频供给,如视频原创系统
视频去重,如视频指纹系统
因此在 MMU 团队的向量检索场景下,需要同时具备向量召回基础引擎能力以及不同业务场景下的业务架构能力。由于不同业务场景对基础引擎和业务架构的需求不同,并且在业务落地时还需要结合人力、时间等各类因素综合考虑,这给团队完成相应系统建设带来了多方面挑战。
本文内容将基于以上背景,分享 Shopee MMU 团队基于 Milvus 引擎在检索业务系统以及平台化建设的相关实践。
01.Milvus 实践
1.1 向量检索引擎
随着越来越多的向量检索需求出现,例如基于视频内容的召回、去重等,团队需要一种通用向量检索引擎方案,来保障团队效率及系统稳定性,从而为业务提供更好支持。
根据对业界开源向量检索引擎的调研结论,Milvus 引擎具备的优势比较切合团队的需要。其中 Milvus 的云原生架构较为契合 Shopee 内部云原生生态,能够快速支撑检索系统从 0 到 1 的搭建;另外 Milvus 具有丰富特性,包括分布式、GPU、增量更新、标量等,都能对业务场景的高效落地提供有效帮助。
综合考量后,团队选择了 Milvus 作为从头搭建检索业务系统的底层检索引擎。本章将整体介绍向量检索引擎的落地实践。
- Milvus 1.x
第一个需求发生在 Milvus 2.x 发布前。由于数据已经具备一定规模,单节点的Milvus无法满足需求,因此采用了 Milvus 1.1 + Mishards 的分布式解决方案。
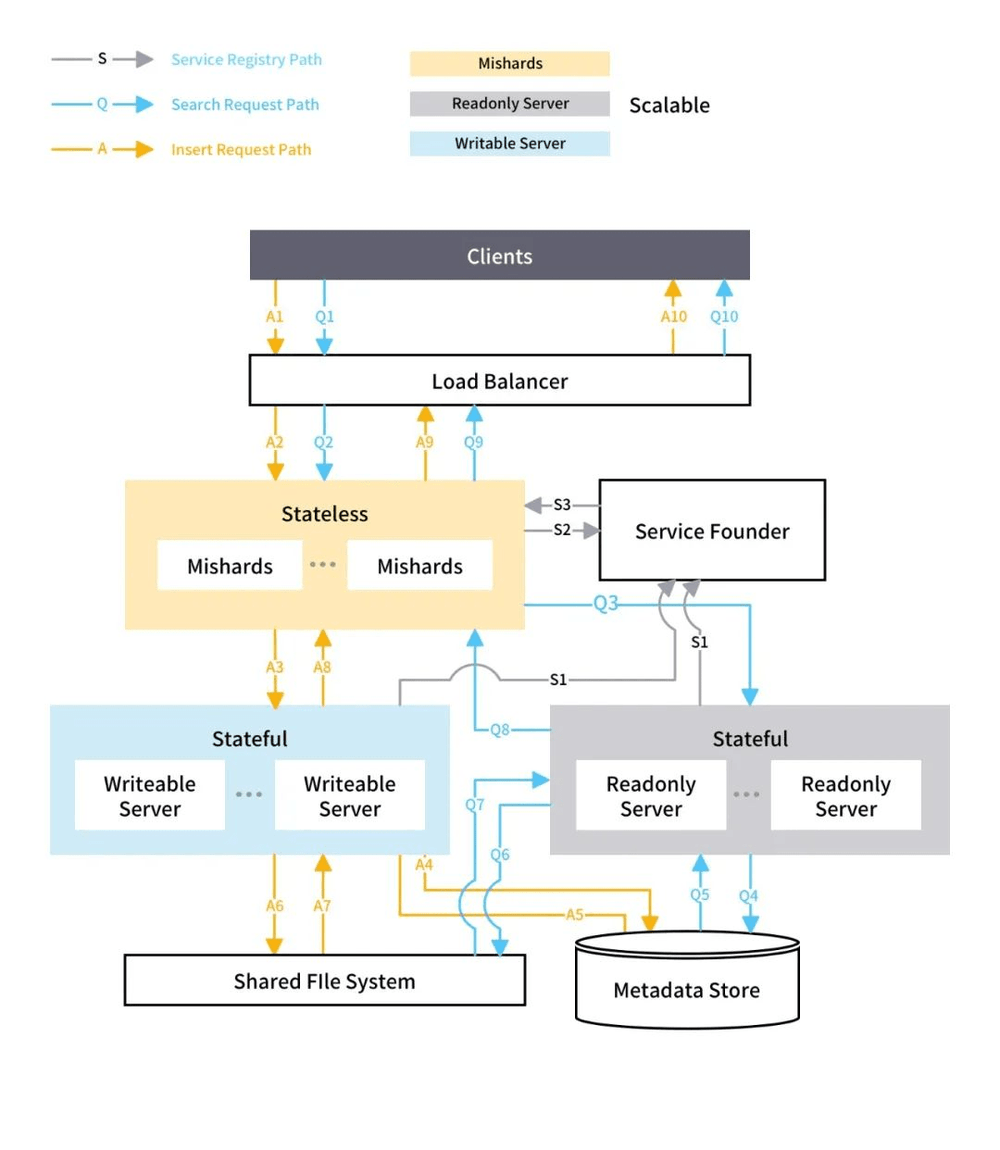 图1:Milvus 1.x + Mishards 架构
图1:Milvus 1.x + Mishards 架构
然而在实际业务场景中,随着数据规模和请求量的增加,检索性能和吞吐到达了一定瓶颈,无法随着 readonly 节点的增多而扩展。
MMU 团队分析后发现以下两点原因:
- Mishards 默认的分片策略在某些情况下会导致 readonly 节点分到的 segment 数量不均衡。
- 随着 readonly 节点的增多,每个节点都需要检索出 Top K,Mishards 在进行 Reduce 时的数据量会急剧增多,导致时延变得较高。
缓解方案是部署多套 Mishards 集群,共用相同的数据库和 S3 bucket,但这种方案的部署和维护成本都较大,长期还需要寻找更合适的部署方案。
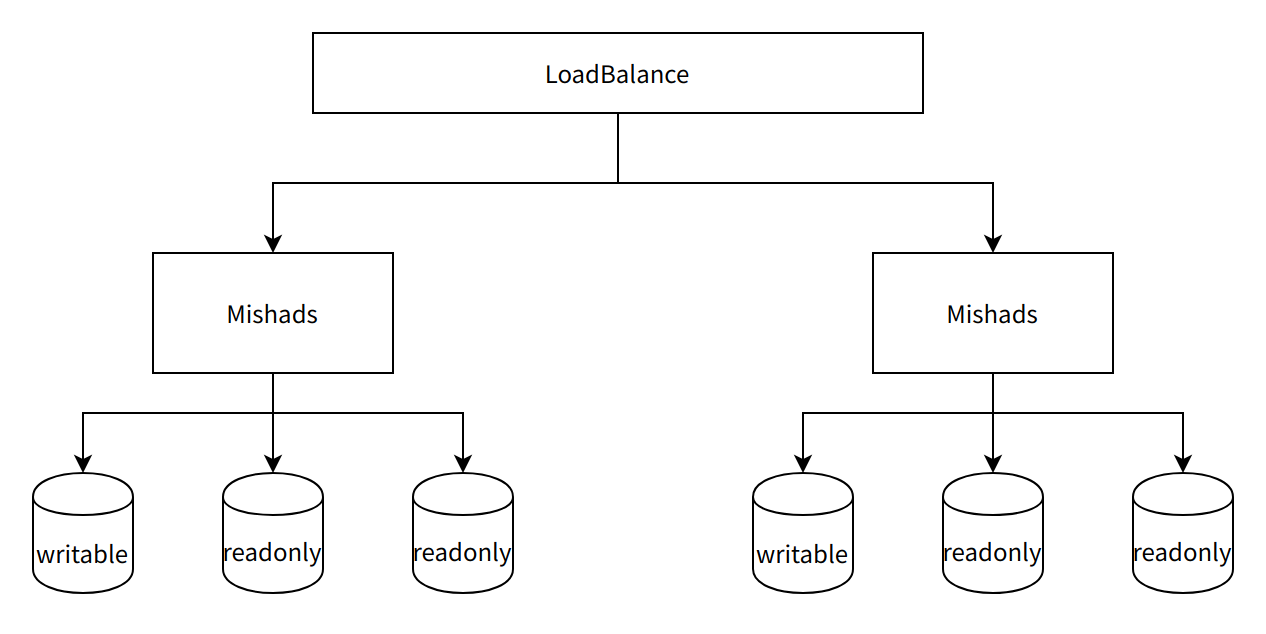 图2:Mishards多集群方案
图2:Mishards多集群方案
- Milvus 2.x
Milvus 2.x 发布后,各业务场景逐步对 Milvus 引擎进行了升级。从实际效果看,Milvus 2.x 的稳定性和可扩展性相比 Mishards 集群都有了极高的提升。尤其在Milvus 2.1 发布后,其多副本能力进一步提高了集群整体的性能,基本能满足各类业务场景。另外,基于 Milvus 2.x 的云原生架构,其日志和监控的引入成本很低,也更加友好和完善。
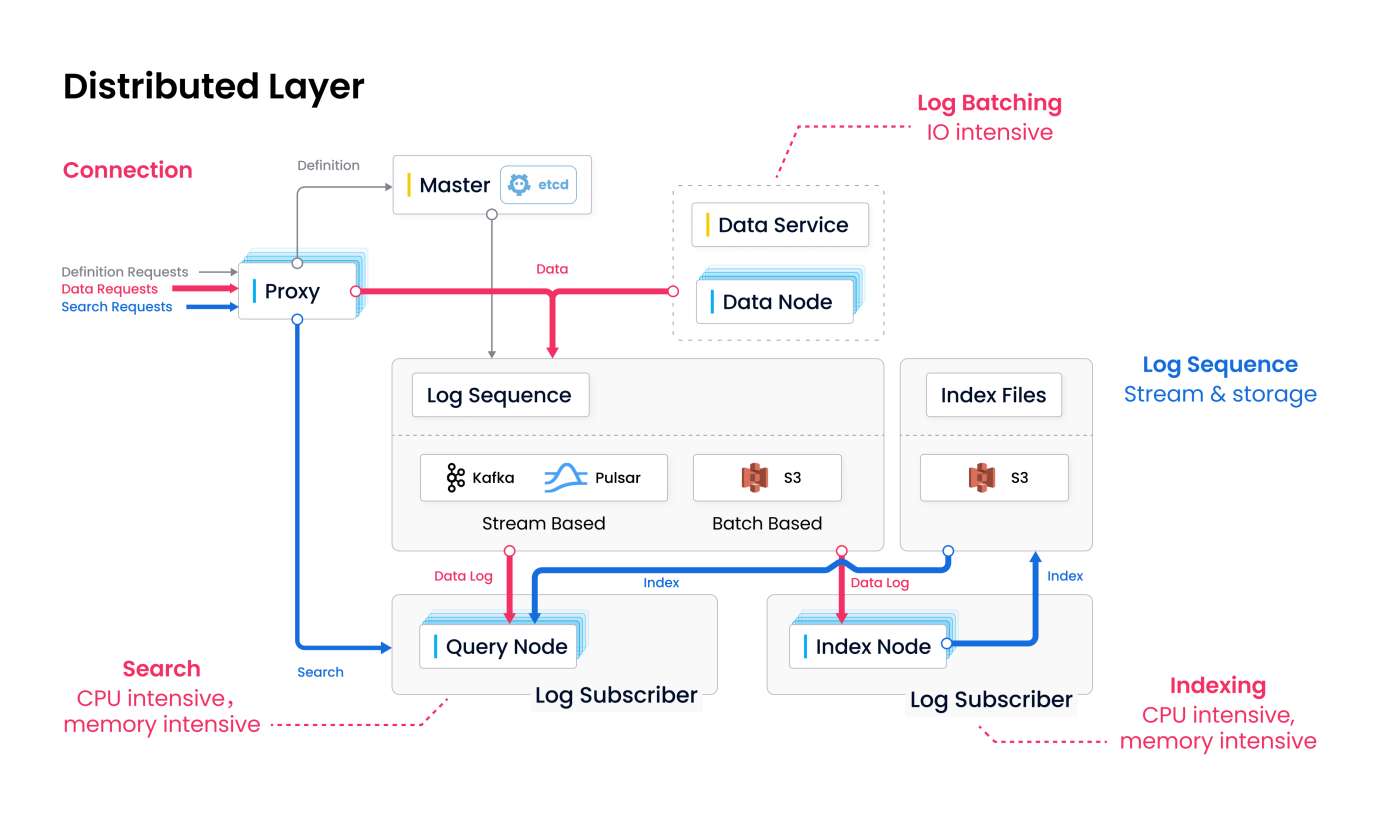 图3:Milvus 2.x 架构
图3:Milvus 2.x 架构
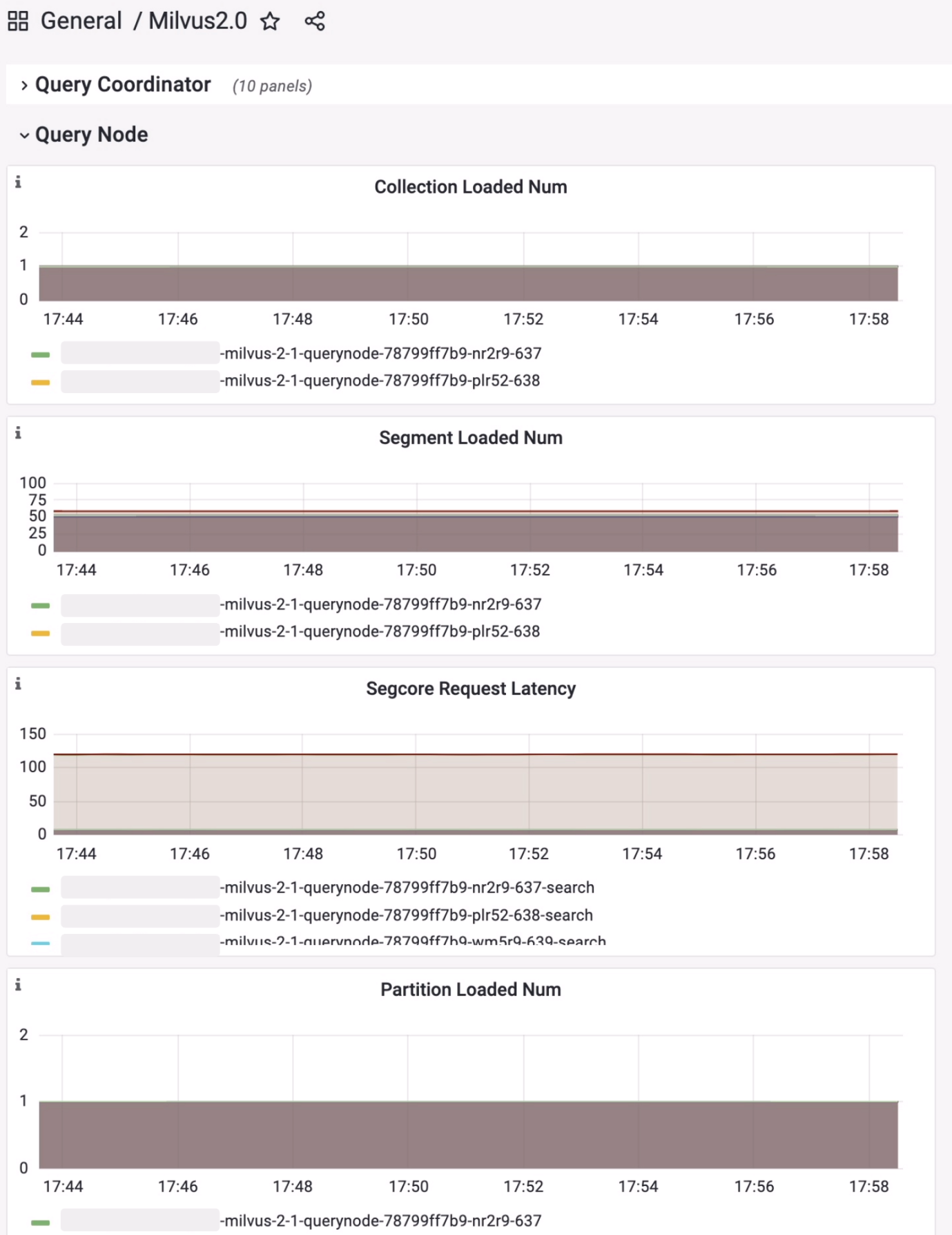 图4:Milvus 2.x 监控(部分指标)
图4:Milvus 2.x 监控(部分指标)
1.2 Milvus 部署方案
- GitOps
早前,Milvus 集群的部署通过手动使用 helm 命令完成(https://milvus.io/docs/v2.2.x/install_cluster-helm.md)。为了满足资源的隔离性,不同业务需要部署独立的Milvus集群。随着业务不断增加,部署集群的维护成了新的挑战。
为了解决这个问题,MMU 团队把每个业务的 Chart 目录都存储在同一个 Git 上,使用 Jenkins/ArgoCD 等工具发布到线上 K8S 集群。
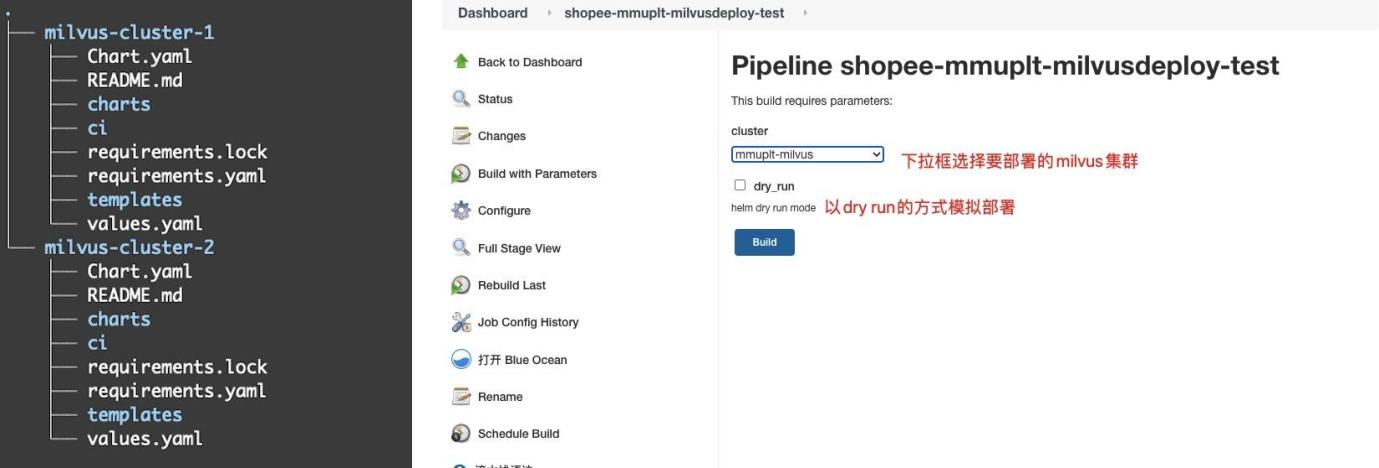 图5:Milvus 2.x GitOps
图5:Milvus 2.x GitOps
目前,Milvus Operator(Install Milvus Cluster with Milvus Operator)已发布,可以进一步减少 Git 中存储的文件内容并精简配置,减少配置成本。
- 负载均衡
Milvus 集群部署完成后,集群对外的流量入口是 Milvus Proxy 节点。如果直接访问 Proxy,会出现 Proxy 单点问题,需要在前面增加一个支持 GRPC 协议的七层负载均衡组件,比如 Nginx 等(Milvus SDK 使用单长连接方案,所以不能使用四层负载均衡)。
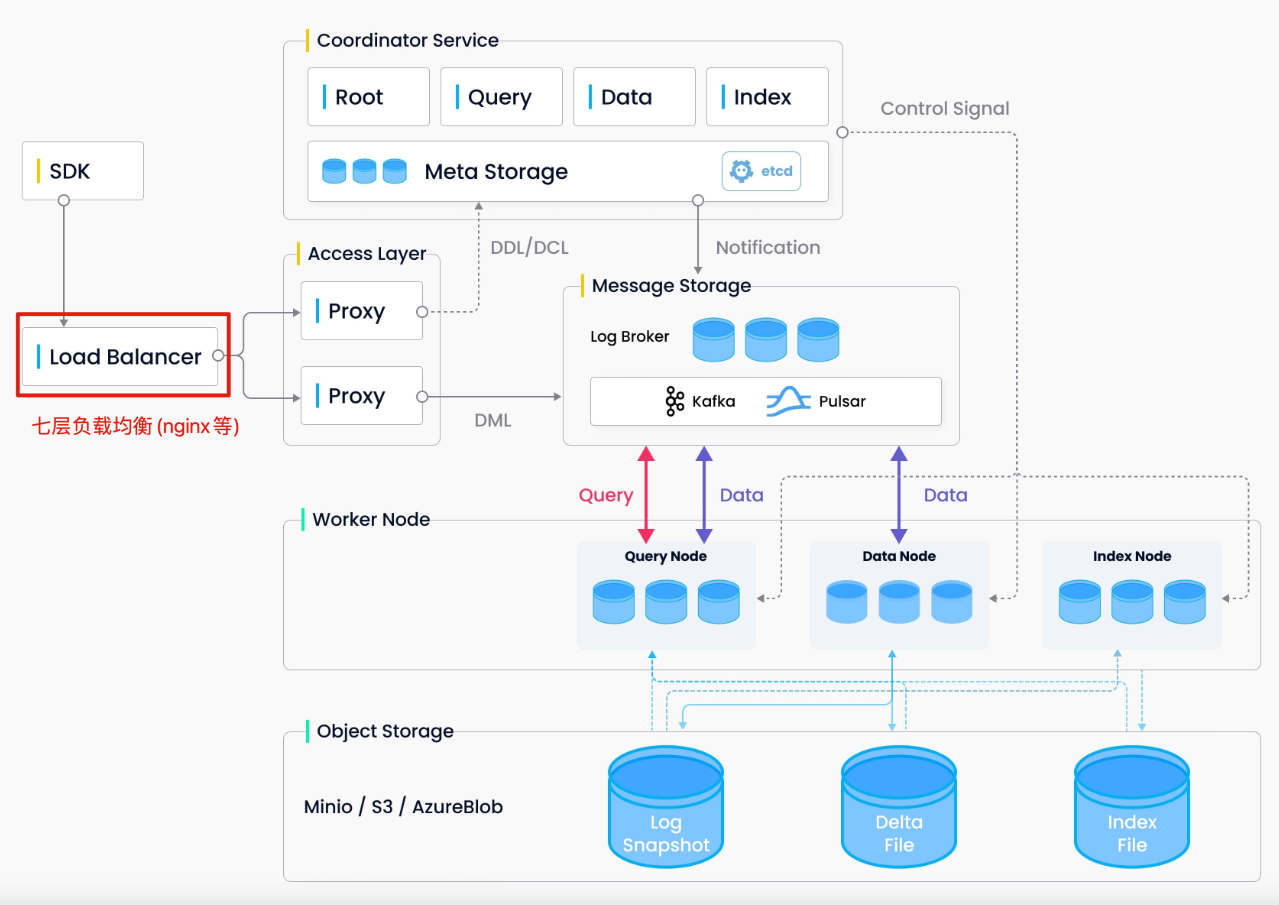 图6:Milvus 2.x 架构(引用自 Milvus 官方文档)
图6:Milvus 2.x 架构(引用自 Milvus 官方文档)
以上是 MMU 团队在 Milvus 应用实践的部分介绍,仅供大家参考,本文接下来将简要介绍团队基于 Milvus 引擎搭建的业务架构。
02.业务架构
2.1 实时检索业务
实时检索业务服务于实时在线请求,系统实时返回检索结果,如推荐召回系统。其主要特点是对可用率和时延要求高。
2.1.1 视频召回
视频召回系统是 MMU 团队为业务提供的基于视频内容的召回能力,作为视频推荐系统的其中一路召回。业务请求通过检索 Milvus 获取 Top K 候选,经过精排逻辑之后返回召回结果。
- 基于 Milvus 1.x 架构
由于 Milvus 1.x 主要面向数据分析场景,未针对低延迟的实时召回做针对性优化,所以在向量库和请求量到达一定规模之后,延迟会有一定下降。因此在 Milvus 1.x 架构下的某些场景采用了缓存 TopK+ 后台更新的方式:通过缓存提供实时查询接口,并在后台的更新数据流中完成 TopK 的更新。
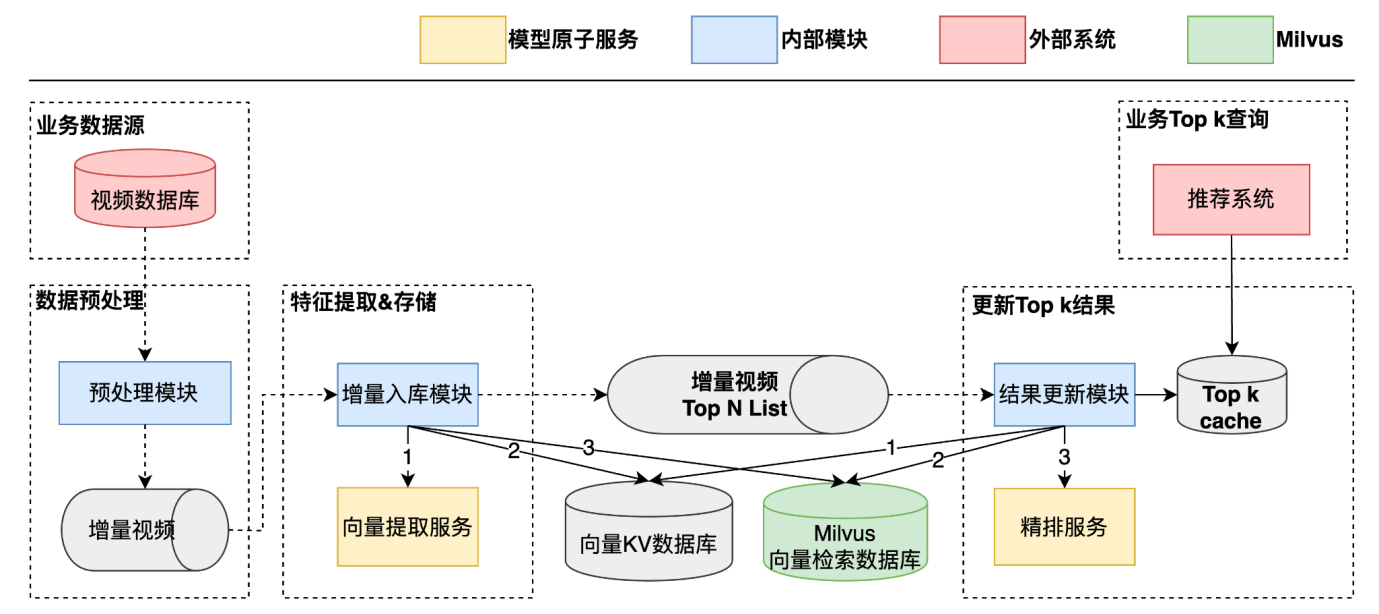 图7:相似视频召回系统(Milvus 1.x 架构)
图7:相似视频召回系统(Milvus 1.x 架构)
基于 Milvus 1.x 架构的核心流程如下:
- 预处理模块
○ 监听视频数据库,过滤出系统需要的视频增量数据交给增量入库模块
- 增量入库模块
○ 对增量视频提取特征,将特征加入 KV 数据库和向量检索数据库
○ 用增量视频查询向量数据库,将检索出的 Top N List,发送给结果更新模块(Top N List 在后续流程中将更新各自的 TopK 结果缓存)
- 结果更新模块
○ 对 Top N List 中的每个视频执行完整召回逻辑(特征提取、向量检索、精排),将结果输出至 TopK 缓存
- 基于 Milvus 2.x 的架构
Milvus 2.x 发布后,由于其强大的分布式能力和系统性能,系统得以通过 Milvus 2.x的查询接口直接提供 TopK 召回能力。
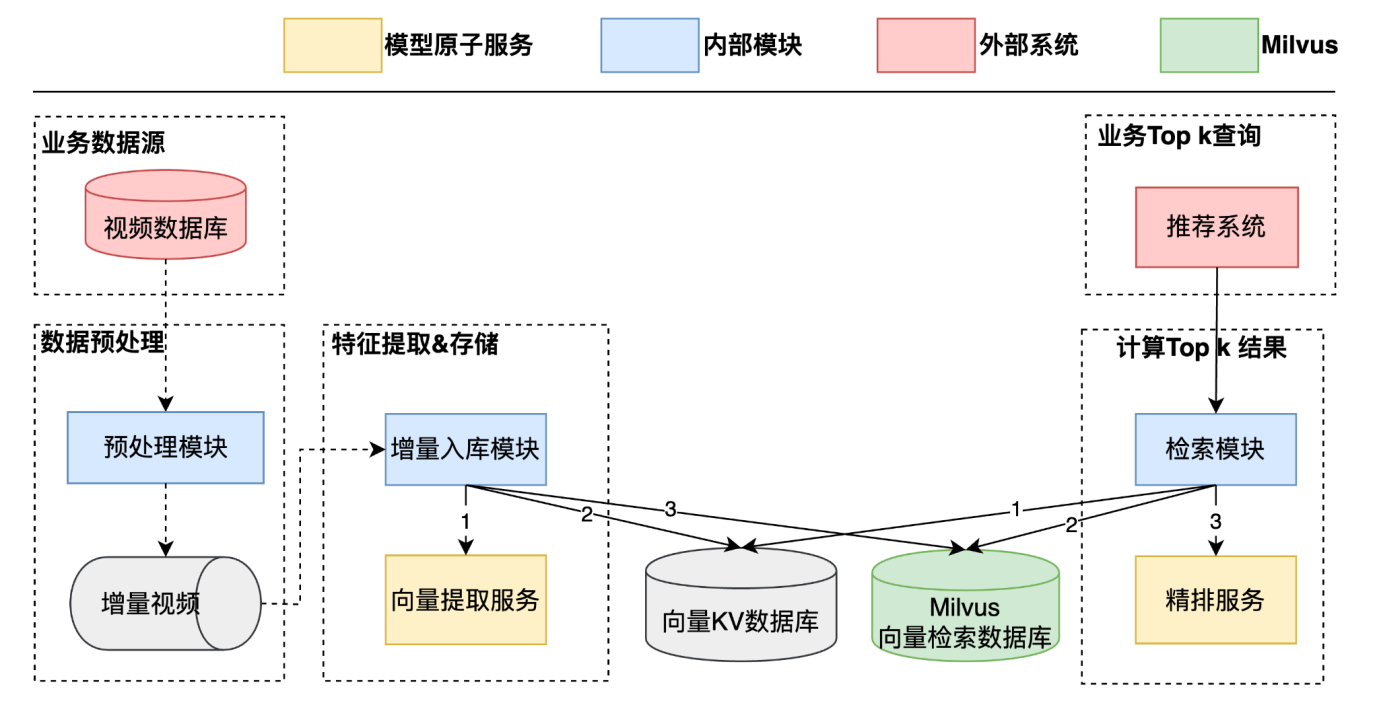 图8:相似视频召回系统(Milvus 2.x 架构)
图8:相似视频召回系统(Milvus 2.x 架构)
2.2 离线检索业务
离线检索业务基于旁路流量进行检索,将最终结果作为特征写入存储,方便不同业务根据各自场景使用,如视频指纹系统和视频原创系统。
2.2.1 视频原创
为了构建良好的内容生态,平台希望通过一定机制鼓励用户产出原创内容。为了让这些机制更好运行,系统需要对视频内容进行识别,判断其是否属于原创作品。
视频原创系统为以上需求而设计。系统通过一定的处理流程识别视频的原创性,提供给业务方进行后续处理。
- 系统架构
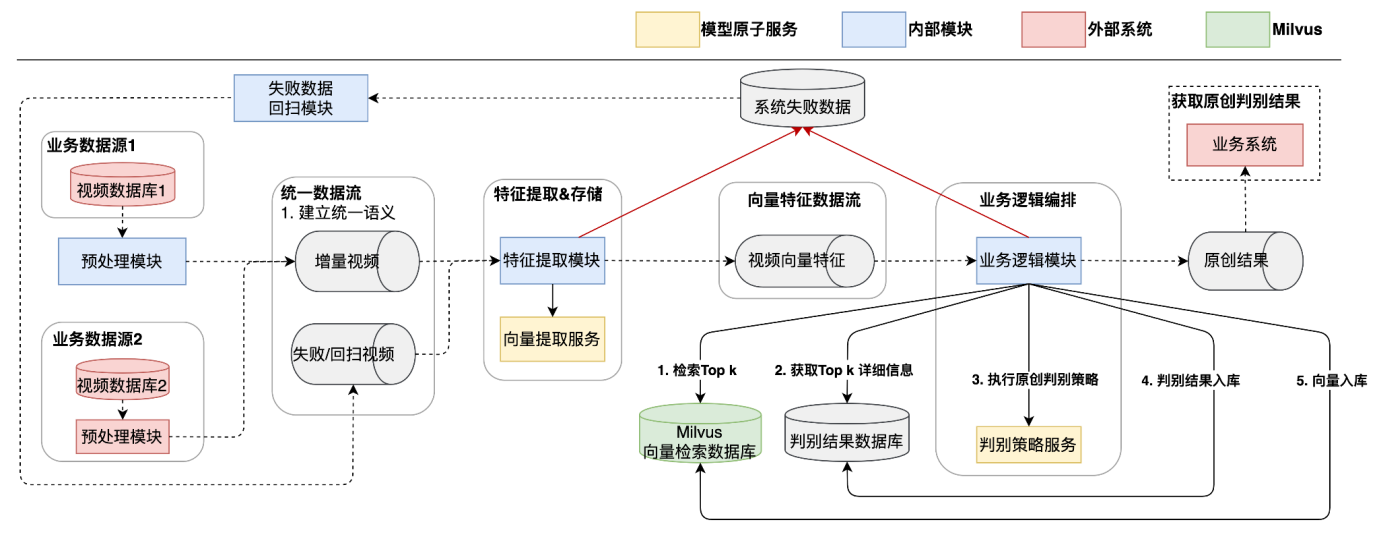 图9:视频原创系统架构
图9:视频原创系统架构
- 核心流程
- 预处理模块
○ 筛选出系统所需视频,拼接核心视频信息并输出给特征提取模块
- 特征提取模块
○ 为视频提取特征并输出给业务逻辑模块
- 业务逻辑模块
○ 为视频执行 TopK 检索和原创逻辑
○ 结果入库并输出给业务
- 回扫模块
○ 旁路流程,为各环节处理失败的数据执行兜底策略
2.2.2 视频指纹
相似视频缺乏新鲜感,无法给用户带来有价值的消费体验,由此催生了对视频的去重需求,即需要识别视频是否为重复视频,从而为各业务场景提供去重能力。
视频指纹系统为以上需求而设计。指纹系统为每个视频分配一个指纹 ID(指纹ID作为该视频的标识,ID 相同的视频视作重复视频)并输出,供各业务方使用。
- 系统架构
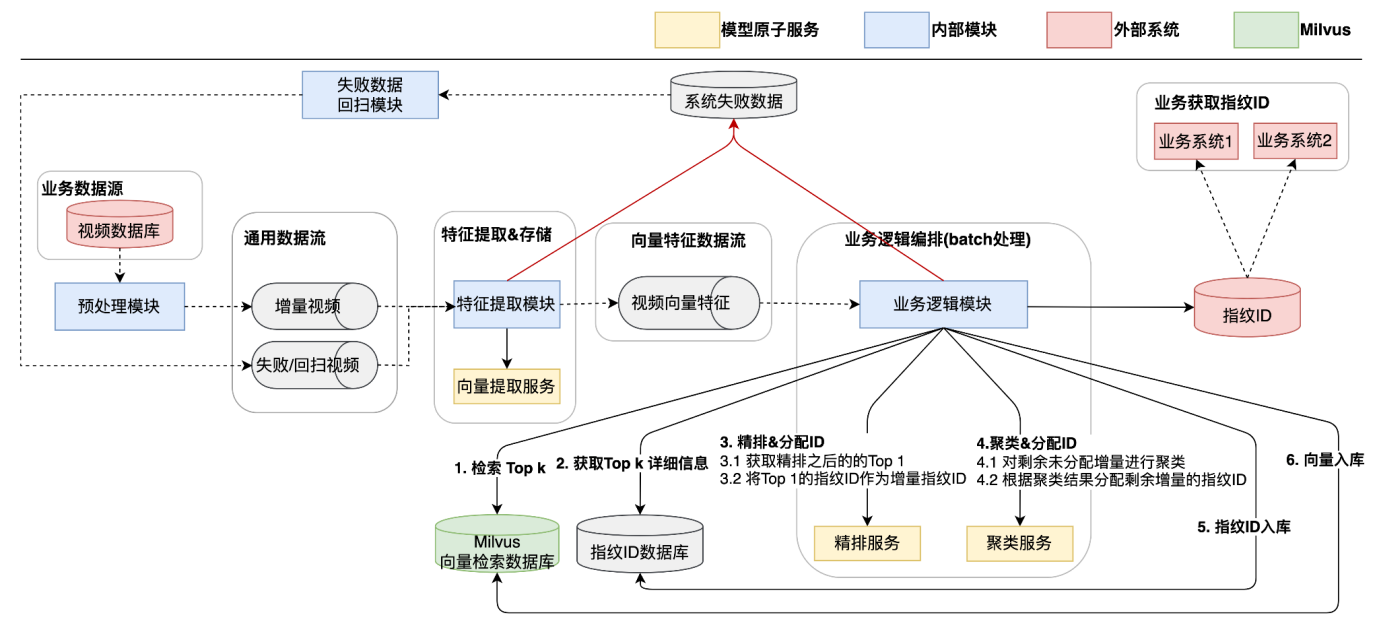 图10:视频指纹系统架构
图10:视频指纹系统架构
- 核心流程
指纹系统的核心流程与原创系统类似,区别主要在于业务逻辑模块。
- 业务逻辑模块
○ 批量处理视频,执行 TopK 检索、精排、聚类并分配指纹 ID
○ 将结果入库并输出给业务
2.2.3 整体设计
- 统一数据流
统一接入协议 - 汇总各方数据源输入,提供统一的数据流
统一预处理 - 聚合并维护视频可用状态,降低后续系统处理复杂度
构建增删改语义 - 满足不同业务场景的精细化需求
- 柔性事务
重试+幂等更新机制,保证输出数据符合业务预期
分区路由+本地锁,提升并发效率,保证数据准确性
- 兜底策略
本地重试策略配置
失败数据定期回扫
- 逻辑编排引擎
开发通用的逻辑编排引擎,标准化输入输出、中间件调用、AI服务调用等组件,提升策略逻辑开发效率
以上是 Shopee MMU 团队在向量检索系统方面的一些工程实践介绍。随着业务不断发展,团队对研发效率、系统质量和开发者体验的要求愈加强烈。为了提升这些方面,团队发起了相应的平台建设项目。本文接下来将简要介绍团队在发展过程中的平台化实践。
03.平台化实践
3.1 早期研发模式
在业务和团队发展初期,以检索场景为例,整体的研发流程如下:
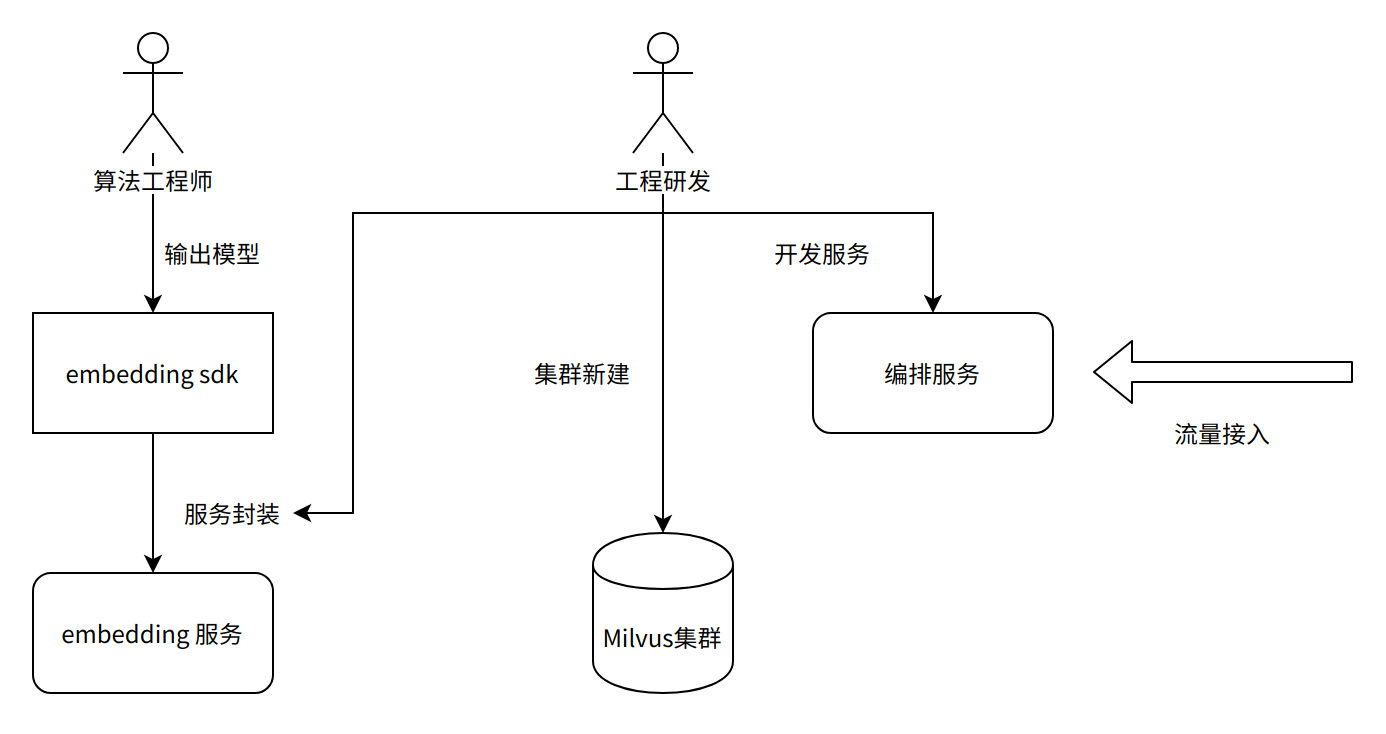 图11:早期研发模式
图11:早期研发模式
- 算法研发职责
结合业务特点训练模型
输出算法 SDK 作为交付
- 工程研发职责
部署 Milvus 集群
根据算法 SDK,开发和部署 AI 在线服务(如特征提取、精排、聚类等)
根据业务需要,开发和部署若干相关微服务(如特征存储、缓存服务等)
结合业务需求实现编排服务,串接整个业务流程
与业务方对接,如提供 API、联调、测试、接入等服务
随着业务快速发展,团队对迭代效率和质量要求不断增加,对传统模式发起了挑战。在早期的研发模式中,存在一些可优化的环节,如模型在线服务、业务逻辑编排、业务接入等。
3.2 模型服务平台
向量提取、精排、聚类等模式固定的AI模型原子服务,基于 MMU 场景的统一模型引擎和协议进行了标准化,在进行逻辑编排时,可结合业务特点选择所需的原子服务。
为了进一步提升原子服务的研发效率和开发者体验,模型服务研发平台建设应运而生。模型服务研发平台基于模型引擎和统一协议进行搭建,标准化了开发、部署、测试、运营等环节,为模型服务的整个研发周期提供了一站式、全流程的自服务功能。
在开发环节,平台以自服务的方式提供SDK开发能力,算法开发人员基于MMU场景的统一协议完成模型 SDK 的对接即可,屏蔽模型引擎的工程细节,降低了交互成本和认知负荷。
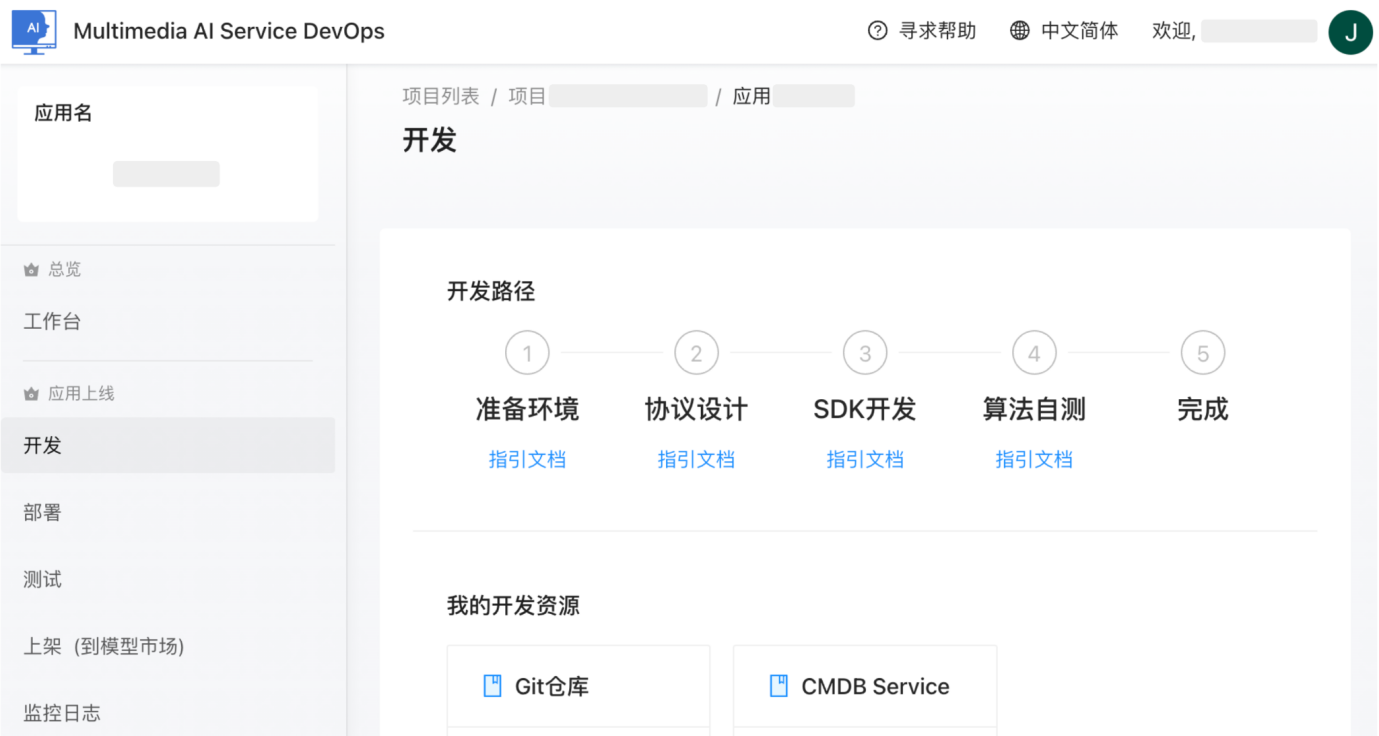 图12:模型服务平台(开发)
图12:模型服务平台(开发)
在部署环节,平台对接底层依赖的各项基础设施,屏蔽平台使用细节和依赖关系,统一 CPU 和 GPU 的部署平台差异,为用户提供统一的、一键式的部署功能和使用体验。
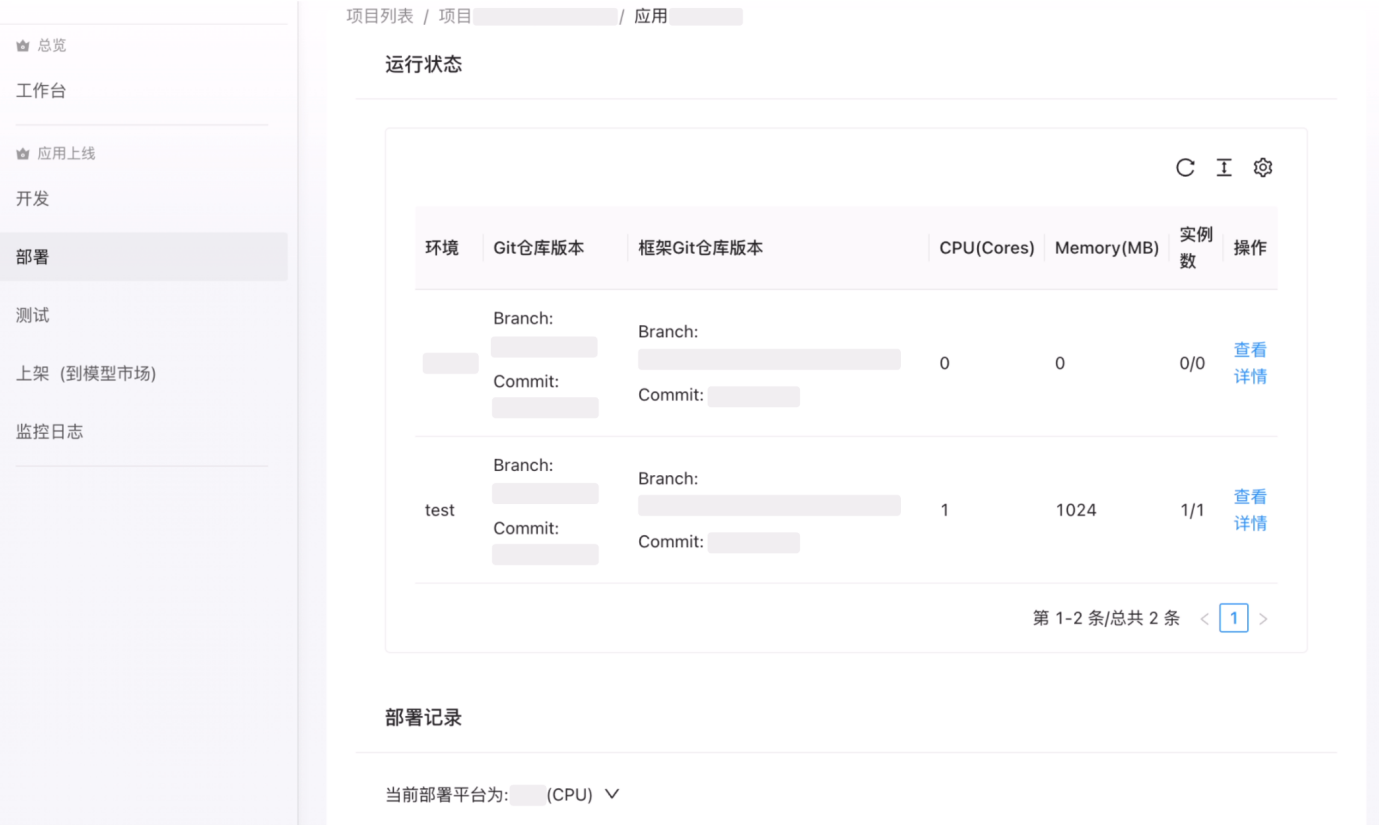 图13:模型服务平台(部署)
图13:模型服务平台(部署)
在测试环节,平台基于模型引擎和统一协议,提供通用版 SDK 自测、功能测试、性能测试、服务调试等测试方面的功能。通过自动化、一键式的方式,可高效完成原子服务的各项测试。
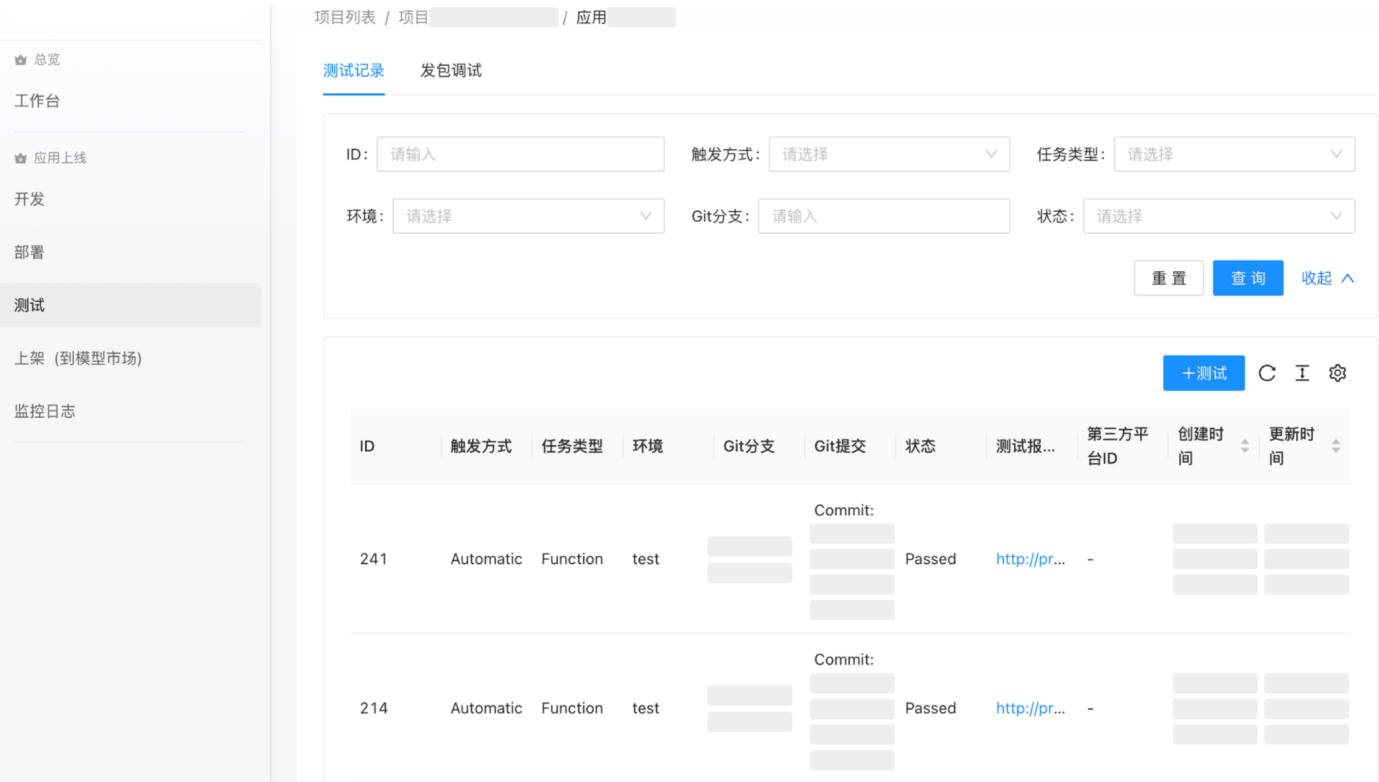 图14:模型服务平台(测试)
图14:模型服务平台(测试)
在运营环节,平台提供统一的日志、监控、告警机制,以无感方式将新增的原子服务纳入线上运营监控体系。
3.3 逻辑编排平台
MMU团队对接业务场景较多,不同业务场景存在各自定制化业务逻辑。比如离线检索业务需要定制化精排策略,整个流程需要调用较多外部接口来完成业务逻辑。此外在输入输出方面,一些系统和业务数据耦合紧密,数据输入输出形式比较多样化。
为避免在每个场景都需要编写定制化代码,MMU团队开发了逻辑编排引擎,抽象化了业务逻辑的通用步骤,比如向量数据库、模型原子服务、中间件、错误处理、输入输出等。
逻辑编排引擎使用若干个 yaml 文件描述整个业务流程:
kind: workflow
nodes:
- name: mq_datasource
node: { "ref": { "file": "datasource.yaml" } }
nexts:
- external_name: video_embedding
- name: video_embedding
nexts:
- external_name: milvus_search
value:
mms_vid: $.mq_datasource.video_id
node: {"ref": {"file": "video_emb.yaml"}}
- name: milvus_search
nexts:
- external_name: save_milvus_result
errorHandle: retry
图15:业务编排示例
从 MQ 数据源中接收 video 数据
对 video 数据进行 embedding
进行 Milvus 检索
将检索结构进行存储
为了进一步提升逻辑编排效率,团队将编排引擎进行简单平台化,通过 UI 拖拽的方式,统一管理各业务的编排逻辑。
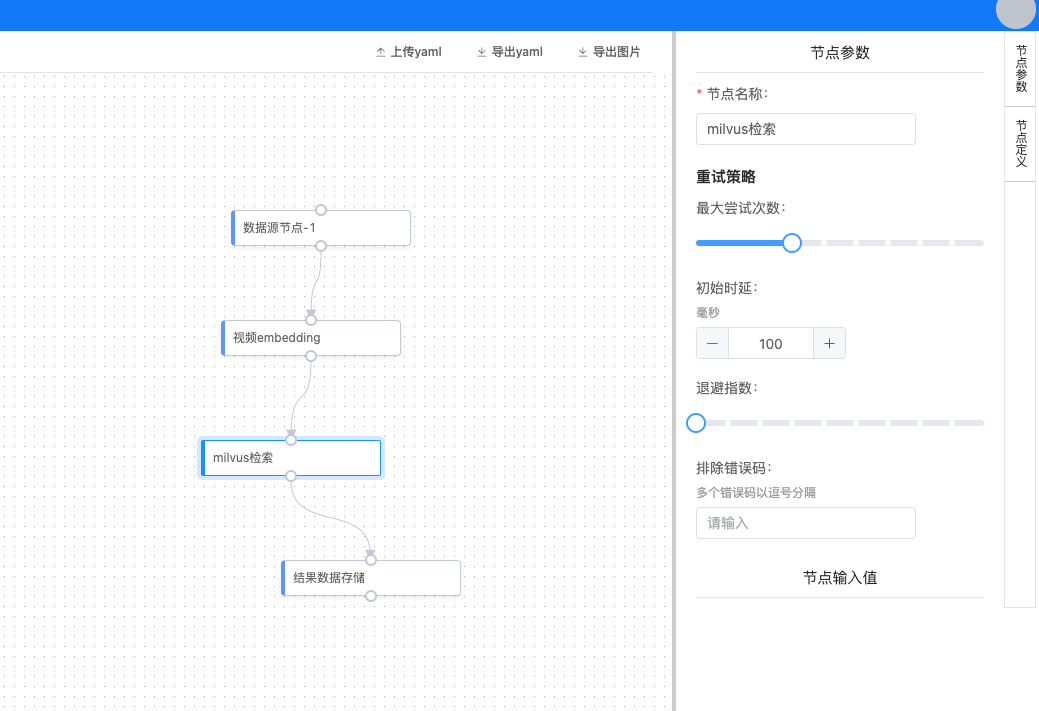 图16:逻辑编排平台
图16:逻辑编排平台
3.4 业务接入平台
业务接入平台主要定位是为业务方提供自助接入 MMU 服务的功能,包括浏览、体验、接入、运营等全流程,从而提升业务方接入效率和使用体验。
业务方可通过以上流程自助使用相关能力,确定满足业务需求后,可在平台上申请正式接入。
 图17:能力体验
图17:能力体验
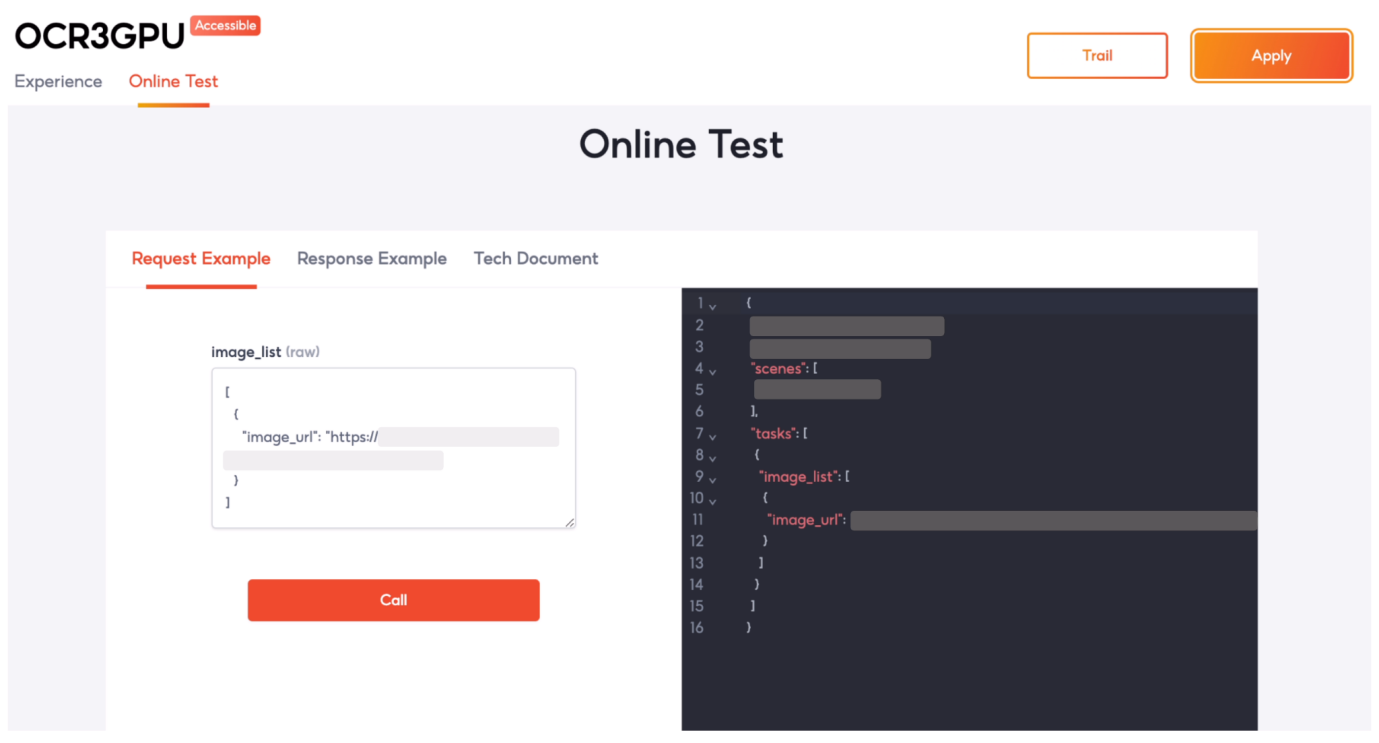 图18:自助调试
图18:自助调试
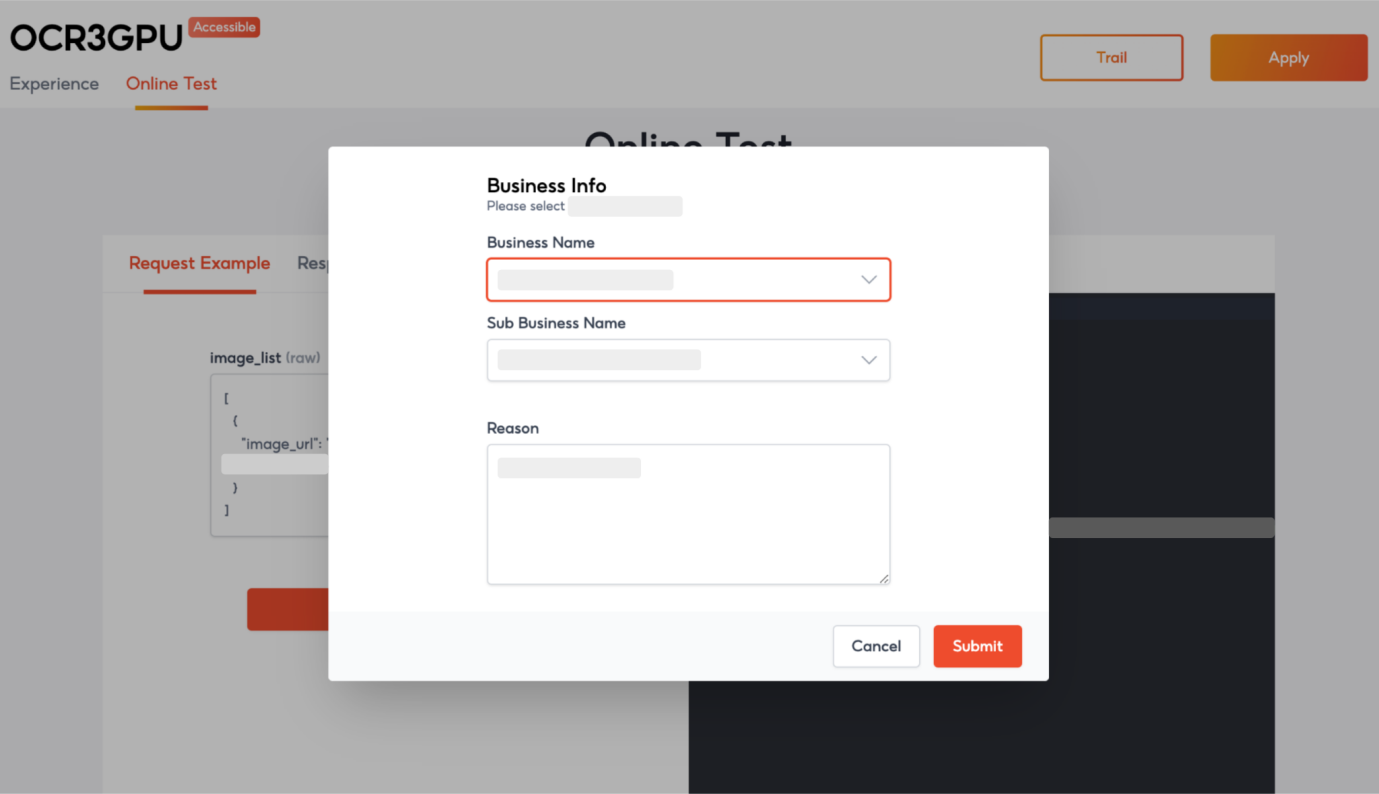 图19:接入申请
图19:接入申请
3.5. 平台化总结
通过对模型在线服务研发、业务逻辑研发、业务接入等三个关键环节的标准化和平台化,团队从能力研发到业务接入整个流程效率得到了较大提升,各角色也能专注于各自核心工作,提升整个大团队的综合人效。
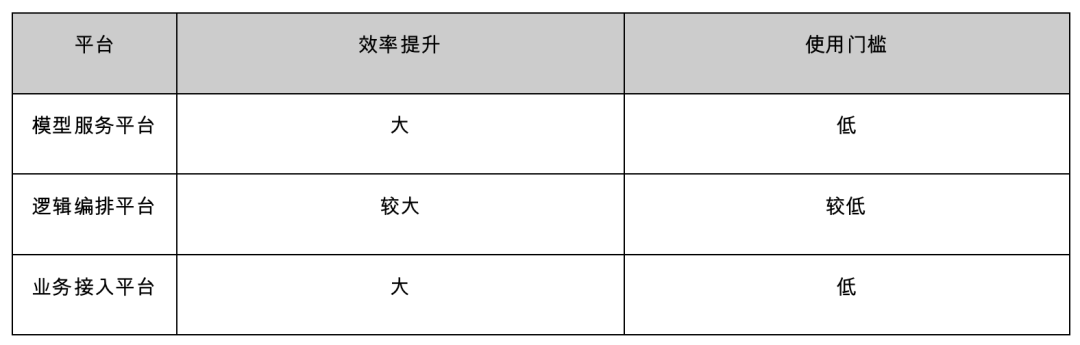 图20:平台化总结
图20:平台化总结
未来,MMU 团队计划继续完善现有平台,同时探索一些垂直场景。
04.总结
感谢 Milvus 向量数据库全体团队,其提供的稳定向量检索能力、多样化功能特性,为 MMU 团队在向量检索场景搭建业务系统时提供极大的便利,其可靠的分布式扩展能力有效支撑了日益增长的数据规模。
撰写本文期间,ChatGPT 引发了 AIGC 热潮,而 Milvus 所代表的向量数据库是 AIGC 非常重要的基础设施之一。OpenAI 关于 ChatGPT Retrieval Plugin 的介绍以及 NVIDIA 的发布会中都明确提到了 Milvus 向量数据库及其意义。期待 Milvus 在未来不断给用户提供更加多样化的功能,比如 GPU 支持、资源隔离等,也期待 Milvus 在 AI 时代散发更大光芒。
 Zilliz
Zilliz


