



数据处理量翻倍! Milvus MMap 一触开启
作为 VectorDBBench 中最快的开源向量数据库,Milvus 可以很好地为有高性能需求的用户服务。与此同时,我们也注意到一些用户会将 Milvus 用在离线业务中,还有部分用户对性能需求并不敏感,这意味着在同规格的实例上,他们需要以更低的成本来处理更多的数据。
因此在 Milvus 2.3 中,Milvus 新增了 MMap 的功能,开启 MMap 后,能够保证相同规格的实例能够处理更大量的数据,同时对内存的大小要求会转移到磁盘上,从而大幅降低成本。
在 Milvus 2.3 中,可以通过修改 milvus.yaml 来启动 MMap 功能:在 queryNode配置项下新增 mmapDirPath 项,将其值设为任意合法路径即可:
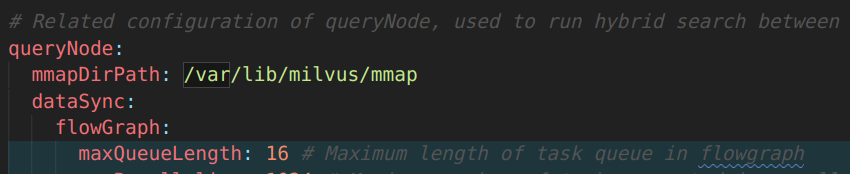
接下来,让我们深入了解一下 MMap。
01.MMap 是什么?
MMap(Memory-mapped files)是一种在操作系统中实现文件和内存之间映射的技术,通过 MMap 我们可以将一个文件的内容直接映射到进程的地址空间中,使得文件的内容在内存中可以被视为一段连续的内存区域,而不必进行显式的文件读取或写入操作。MMap 提供了一种高效、方便的文件访问方式,尤其在处理大型文件或需要随机访问文件内容的情况下非常有用。
一个简单的 C 语言例子如下:
void* map = mmap(NULL, size, PROT_READ, MAP_SHARED, fd, offset)
后续通过 map 指针读取数据时,会直接读取到 fd 所对应的文件的内容。如果读取的区域不在内存中,操作系统会将对应的 page 及相邻 page 缓存到 page cache 中,而不常访问的 page 可能会被换出。
在 Milvus 中开启 MMap 后,数据不会直接 load 到内存中,当发生查询时,数据会被动态地从磁盘加载到内存中,并且系统也会动态地将不常用的数据淘汰掉。由于 Milvus 查询集群中的数据都是 immutable 的,当数据被从内存中淘汰时,并不会发生写磁盘的操作。
02.性能,成本与系统的上限
由于需要存储向量数据,向量数据库对内存容量会有较高的要求。想要在有限的内存下处理更多数据,并且对性能不是非常敏感的用户就可以通过 MMap 功能实现。系统会根据负载和使用情况从内存中淘汰掉一些数据,从而可以在相同的内存容量下处理更多数据。
寻求空间与时间的平衡点
天下没有免费的午餐,而 MMap 的代价就是性能。根据我们的测试,在内存充足时,经过 warm up 后,数据都在内存中,此时系统的性能不会有明显的降级。而当数据量不断增加,性能则会随之逐渐下降。因此我们推荐只有那些对性能不敏感的用户去使用 MMap 功能。
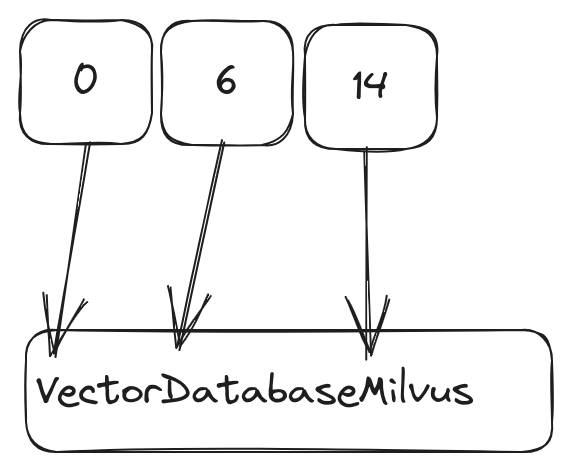
如大家所知,数据的访问模式会极大地影响性能。Milvus 的 MMap 功能也尽量考虑了局部性对性能的影响。对于数据部分,通常是在过滤与读取时会被访问,并且都是顺序访问,因此标量数据会被直接按顺序写入到磁盘。对于变长类型,我们做了更多的优化,如下图所示,3 个字符串分别是:
Vector
Database
Milvus
变长类型会经过扁平化,写入到连续的区域中,在内存中我们会维护一个 offsets 数组来索引数据。这样就能保证数据访问的局部性,同时也能消除单独存储每个变长数据的 overhead。
而对于向量索引,就需要更细致一些的优化了。以最常用的 HNSW 为例,HNSW 可以分为两个部分:
存储图中点之间连接关系的邻接表
原始向量数据
由于向量本身是比较大的,通常为连续的上百,或上千个 float32,因此访问单个向量本身就可以利用到局部性。而邻接表的访问模式在查询过程中则是较为随机的。向量数据通常会比邻接表要大得多,因此我们选择了只对向量数据做 MMap,而邻接表则保留在内存中,在节省大量内存的情况下保证性能不会下降太多。
Zero Copy
为了让 MMap 能够提高系统处理数据量的上限,我们首先需要保证,在整个数据加载流程中内存用量峰值一定是远低于实际数据量的。而 Milvus 在之前的版本中,QueryNode 加载数据时会将数据全量读入,数据在整个过程中会被复制。在 MMap 功能的开发过程中,我们将这一过程改为了流式的,并去掉了很多不必要的复制,大幅降低了数据加载过程中的内存开销。
经过这些优化,MMap 才能真正提升系统的能力上限,经测试,在 Milvus 2.3 中开启 MMap 后, Milvus 可以处理约 2 倍左右的数据量。
目前 MMap 功能还处于 Beta 的状态,后续我们会对整个系统的内存使用做更多优化,来实现在单个节点上支撑更大的数据量。同时也会在使用方式上做出更多迭代,支持更细粒度的控制,支持动态的更改 collection,甚至 field 的加载模式。
 岑洋
岑洋


