



点击查看 Milvus 社区十大关键词(上)
GitHub Star 突破 25,000、集众多特性于一体的 2.3.0 版本重磅发布、Docker Hub Milvus 镜像下载量突破 1000 万……过去一年,Milvus 社区取得了很多激动人心的进展,而 Milvus 技术交流群作为众多开发者交流分享的重要阵地,今年的规模也突破了 5000 人。
我们将 2023 年所有 Milvus 技术交流群的聊天历史做了整理分析,得到了如下的一张词云图:

按照热度,排名前十的关键词依次为:版本、查询、内存、插入、配置、日志、集群、文档、 部署、删除。今天,我们先来扒一扒前五大关键词!
01.「版本」:AIGC 需求的快速变化,催生了向量数据库的超高速迭代
对于“版本”成为热度排名第一的关键词,我开始是有点意外的,仔细一想似乎也在情理之中。2023年,是 AIGC 大爆发的一年,LLM 展现出了强大的分析、推理、归纳、总结能力。但是,由于缺乏最新的和特定领域的训练数据,大模型“幻觉”成为困扰 AIGC 开发者的一大难题。随着 RAG 技术的发展,LLM 和向量数据库这对黄金搭档开始走到一起,成为幻觉问题的通用处理范式。
Milvus 作为全球最流行的开源向量数据库,大量 AIGC 开发者涌入 Milvus 社区,给 Milvus 提出了诸多新的需求。在无数开发者的期盼下,Milvus 去年一共发布了 20 个版本,支持了 partition key、Dynamic Schema、Array Data Type 等大量 AIGC开发者需要的功能,关于版本的讨论几乎一整年没有停过。搜索“版本”这个关键词,常见的讨论有:
“Milvus后面有版本可以无限创建 collection 么”
“新版本的 Milvus 里的一个 collection 支持多个 vector 嘛?”
“新版本我记得好像可以单独 load partion 到内存里,不需要 load collection”
大家对于版本的讨论,主要集中在 Milvus 各个版本的 feature 和 bugfix 情况。Milvus 的小版本平均 2 周发布一个,大版本平均半年发布一个。单 2.2.x 系列的版本,目前已经有 16 个了,所以完全记下每个版本的 feature 和 bugfix 几乎不太可能。但是,所有版本的发布信息都会在 Milvus 官网的 Releases 页面(https://milvus.io/docs/release_notes.md)非常清晰地展示,包括大家最关心的 feature、bugfix,同时还有一些 improvement 以及 breaking change。如果你关心这些 feature 或者 bugfix 的实现,还可以去看背后的 pr。强烈建议,大家有任何关于版本的疑问,都可以去 Releases 页面寻找所需信息。
除了常见的 feature 和 bugfix 讨论外,针对“版本”这个关键词,我们也经常遇到如下提问:
“请问现在哪个版本最好用?”
“这个版本大概什么时候发布呢?”
关于版本选择,Milvus 目前仍处于快速迭代的阶段,建议大家尽量使用最新的版本。因为新版本不仅包含了之前所有已知问题的 bugfix,还拥有最全的功能、最好的性能。很多问题,尤其是 Milvus 早期的 bug,都可以通过升级到最新版本解决。
至于新版本的发布时间,则取决于 Milvus 的功能研发和测试进度,比较难给出准确时间,可以参考 Milvus 官网的 Roadmap 页面。
02.「查询」:始于向量,不止于向量
Milvus 作为一个向量数据库,查询是用户使用频率最高的操作。最早的时候,Milvus 只支持纯向量的 Top-K 近似查询,随着社区的壮大,用户对于查询能力的需求也逐渐增多。
目前,Milvus 最新版本(v2.3.4)已经支持了非常丰富的查询能力,Top-K 近似查询、表达式过滤近似查询、RANGE 近似查询。在火热的 RAG 应用浪潮中,不少开发者还提出让 Milvus 支持关键词检索的需求,在这里也给大家剧透一下,这个功能将在 Milvus 的下一个大版本(v2.4.0)上线。
对于“查询”这一关键词,大家讨论的话题比较多样化,例如:
“200 万特征用的是 FLAT,查询 Top100 大概每次耗时 500 多毫秒,这个性能正常么?”
“Milvus 在查询之前怎么实现属性过滤呢?”
“请问查询的索引能设置为阈值吗?例如,返回相似度大于等于 0.85 的结果。”
“Milvus 支持使用类似传统 Elasticsearch的BM25 查询算法吗?目前在 rag,单纯向量检索片段效果不好,想着增加传统的关键字检索。如果 Milvus 支持 bm25 的话,就不需要再单独建 es 了,也不需要数据写 2 份了.”
这些多样化的讨论,实际上可以总结为 3 类:查询性能、查询功能、查询原理。
性能问题,社区之前有一篇文章《浅谈如何优化 Milvus 性能》,已经讲了比较详尽的分析方法,八成的性能问题,都可以通过文章里的方法去优化。
功能方面,想要了解某项查询能力是否具备,最简单的方法就是打开 Milvus 官网的 User Guide —> Search and Query 页面寻找,上面有十分详尽的接口说明和代码示例。如果在官网上面没有搜到的查询功能,建议先去 Milvus 的 GiHub issue 里面搜索相应关键词,看一下社区里面有没有类似的需求,以及这类需求是否有其他解决方案。如果在 issue 里面也没有找到,不妨创建一个类别为 feature request 的 issue,把你想要的查询功能详细描述出来,并说明其对应的使用场景,说不定下个版本里面就有你要的功能了。
最后,一些小伙伴如果想更深入地了解 Milvus 里面某些查询功能的实现原理,以下三处一般会有你需要的内容:
Milvus Enhancement Proposals (MEPs)
Zilliz B 站视频
Zilliz 公众号 Milvus Tech Zone 专栏
03.「内存」:省一点,再省一点
“partition key 也是很多人在一个集合里吗?可不可以一个人一个人的释放占用的内存”
“因为我在插入数据到时候报错内存不足,所以我想算一下需要多少。”
“标量是不是不建议 load 内存中,感觉几十 G 的内存几下就用完了。”
“数据如果一直都有写入,那 load 后的集合会越来越占内存,不知道其他人有没有什么好的方案能在内存和查询速度上做出平衡?”
以上是关于“内存”关键词的相关讨论。向量作为一种新的数据类型,天然具有维度高的属性。为了获取优异性能,向量被读取到内存做计算也成了通用的做法。但是,随着数据规模的增加,内存余量逐渐见底,在全行业都在降本增效的时代,如何省更多内存成为了所有开发者的心声。当然,直至今日,Milvus 对于内存的优化也从未停止,社区的目标永远都是“省一点,再省一点”。
但是,作为一个数据库系统,不可能同时满足内存低、性能好、精度高的条件。一般都需要牺牲性能或者精度,来换取内存开销的降低。可以用下面这张图来表示目前常见降低内存使用的方法:
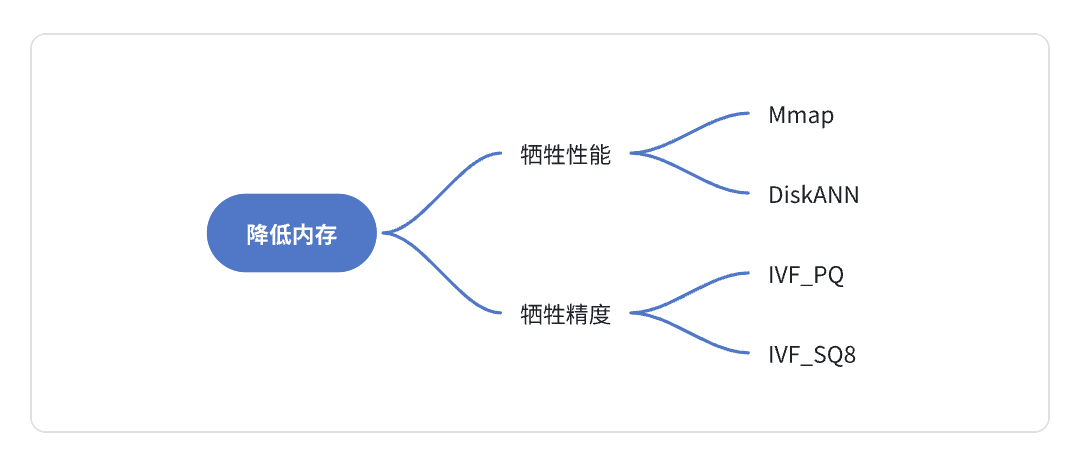
前文也提到,2023 是 AIGC 应用爆发的一年,在做 LLM 应用开发的过程中,大家能直观感受到大模型的响应时间是比较慢的,一般是几百毫秒到几秒。在这样的背景下,开发者对 Milvus 的性能要求一般不会特别苛刻,在几百毫秒内返回便能满足大多数场景。所以,MMap 和 DiskANN 是大多数 AIGC 开发者节省内存的更优选。
04.「插入」:丝滑入库是影响开发体验的第一步
除了查询之外,“插入”应该是使用最多的一个数据库操作,所有后续的工作也是建立在数据成功插入的基础上。丝滑的入库体验,是影响开发体验的第一步,也是至关重要的一步。
Milvus 社区对于“插入”的讨论,主要集中在数据插入的实践经验上:
“插入的速度怎么优化啊?”
“分批插入数据,是每一批 collection.flush(),还是最后再 collection.flush()?”
“这个设置成主键之后,为什么还可以继续重复插入相同的值?”
关于这一关键词,和大家分享 3 点关于数据插入的心得:
- 批量插入快于单条插入,文件导入(bulk_insert)快于批量插入(insert)。普通 insert 接口,数据入库需要经过 Proxy—>MQ—>DataNode—Object Storage 这样较长的一套流程。但是文件导入 bulk_insert 的入库流程仅为:Proxy—>DataNode—Object Storage,可以减少耗时较长的 MQ 环节。对于大批量(千万以上)的数据导入,强烈建议使用 bulk_insert 接口。
- 插入数据时,不要每一批都调用 flush()接口,Milvus 内部会定期调 flush() 接口,所有数据都插入完成之后,再调用一次 flush 即可。插入数据后,频繁调用 flush,会产生大量碎的 segment 文件,为系统带来较大的 compaction 压力。
- Milvus 用 insert 接口做数据插入时,不会做主键去重,如果希望主键去重,可以使用 upsert 接口。但是,由于 upsert 内部多做了一次 query 操作,插入性能会比 insert 更差。
05.「配置」:半数使用问题是配置问题
“Milvus 配置用户名密码进行校验,需要怎么开启呢?”
“这个服务通过 k8s 已经起来的,我在不想关闭他的情况下应该怎么修改配置文件呢?”
“ etcd 如果独立部署的话,这块儿的配置有推荐的参考值吗?”
Milvus 作为一个分布式向量数据库,除了自身有较多的功能模块,同时还依赖对象存储、消息队列、etcd 等第三方组件。为了保证 Milvus 集群在不同应用场景中均能发挥出最佳性能,Milvus 暴露了大量的配置参数。但是面对这些配置参数,“调哪个”“怎么调”“调多大” 成了很多用户所遇到的难题。可以说,如果把 Milvus 的配置参数调明白了,Milvus 一半的使用问题都解决了。
关于“调哪个”的问题,我认为是配置这三个问题中最难的,不同的使用场景下,要调的参数都是不同的。就拿性能优化这件事情来说,搜索性能优化的参数和插入性能优化的参数肯定是不一样的,这就比较依赖于实际使用的经验。Zilliz(Milvus 原厂)的官方公众号上,有很多 Milvus 的资深研发同学和 Milvus 深度用户写的技术文章,里面提到了很多配置调优经验,大家可以将这块的资源充分利用起来。
此外,Milvus 社区里会经常举办一些线上线下的交流活动,每次活动都会邀请一些社区大牛来做分享,这种当面直接的交流机会,大家也可以去把握一下。总之,社区的交流通道还是非常开放的,只要你主动一点,总是能找到解决方案的。
当我们知道“调哪个”以后,后面的问题就好办很多。关于“怎么调”,《稍作修改便能更丝滑?Milvus 的秘密藏不住了》里详细讲了对于不同的部署方式,如何去修改配置参数。同时补充一点,Milvus 从 2.3.0 版本开始,就开始支持动态调整参数,具体操作方法参考:https://milvus.io/docs/dynamic_config.md,以后再也不用担心改完配置需要重启才生效了。
最后,对于“调多大”,一般在解决“调哪个”问题的时候就会顺带知道“调多大”的答案。假使不知道也没关系,Milvus 官网的“Configure Milvus”章节花了大量篇幅介绍每个配置参数的含义,配合动态更新的能力,可以快速进行测试做一些验证,然后找出最佳的参数值。
未完待续……



