



介绍LLM定制
近年来,人工智能的快速发展导致了大型语言模型(LLMs)的开发,彻底改变了自然语言处理(NLP)领域。这些强大的模型,如ChatGPT、Llama、Mistral、Zephyr等,已展示出在理解和生成类似人类语言方面的卓越能力。
然而,这些LLMs也有局限性。它们是在具有特定截止日期的大量数据上训练的,这意味着如果我们使用它们生成需要比训练数据更新的知识的答案,我们就有可能得到不准确的响应。因此,将这些模型定制到我们特定的任务和领域以释放它们的全部潜力至关重要。这就是LLM定制发挥作用的地方。
在最近一次西雅图的Zilliz非结构化数据聚会中,OSS4AI的首席执行官和Zilliz的前高级开发者倡导者Yujian Tang讨论了几种定制LLMs以提高它们在特定任务上的表现的选项。在讨论LLM的不同定制选项之前,让我们简要探索LLM的历史。
 109.1.PNG
109.1.PNG
观看Yujian演讲的回放
LLM的简史
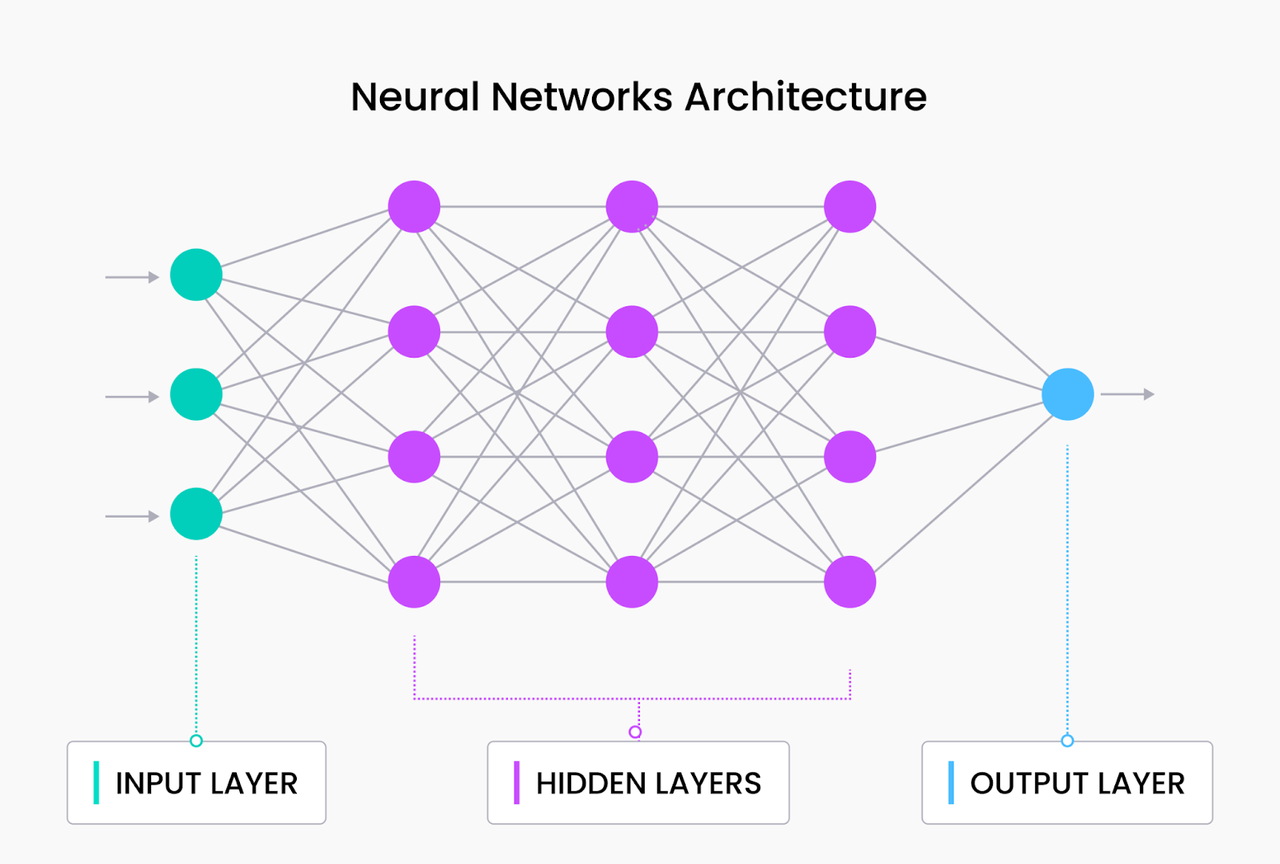
导致LLM诞生的研究已经走过了很长的路,从基本的神经网络架构开始。基本的神经网络层由输入层、一个或多个隐藏层和输出层组成,如下图所示。
 109.2.PNG
109.2.PNG
神经网络架构
基本的神经网络架构对分类任务非常强大,并且可以处理如文本和图像等非结构化数据。然而,它对于需要长期依赖性或序列处理的任务是无效的,这对于自然语言任务至关重要。在基本神经网络中,每个输入独立处理,输出仅基于当前输入生成。这意味着神经网络不考虑整个序列的输入顺序或上下文。
没有处理长期依赖性的能力,神经网络无法推断整个输入序列或文本的语义含义——递归神经网络(RNNs)的诞生旨在解决这个问题。
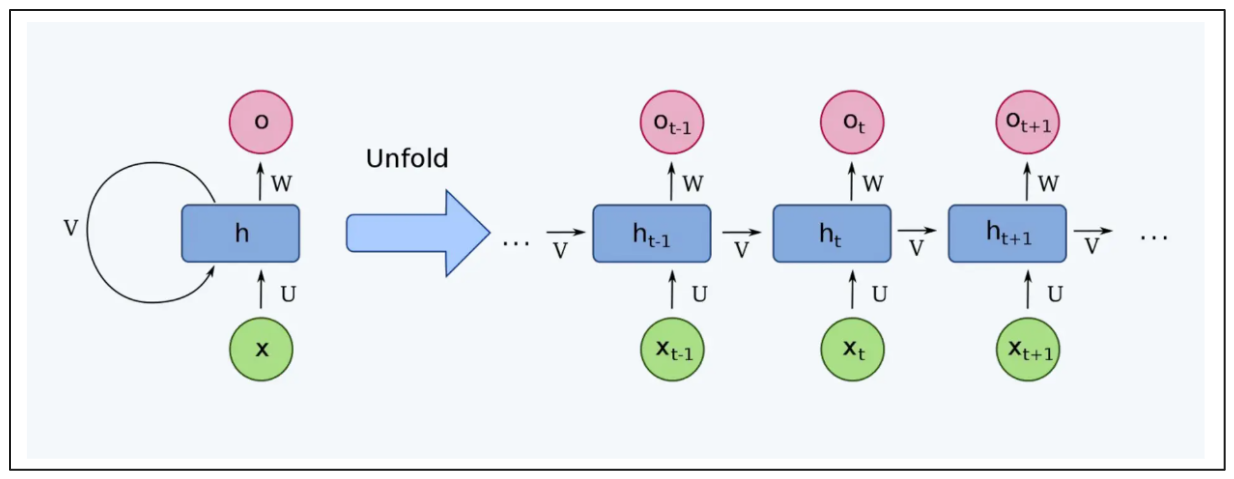
RNN通过引入隐藏状态来解决这个问题,隐藏状态充当记忆,捕捉网络以前看到的信息。这个隐藏状态从一个时间步骤传递到下一个,允许网络保持序列的表示。添加隐藏状态使RNN能够选择性地记住或忘记输入序列中的信息,使它们比基本神经网络更有效地处理输入序列依赖性。
 109.3.PNG
109.3.PNG
RNN架构
然而,RNN也有一些限制,例如:
#梯度消失问题:RNNs遭受梯度消失问题的困扰,训练期间用于更新模型参数的梯度在通过时间反向传播时变得越来越小。这个问题使得RNN难以学习序列中的长期依赖性。
#序列处理:RNNs按顺序处理序列,限制了它们并行计算的能力,使它们在计算上效率较低。
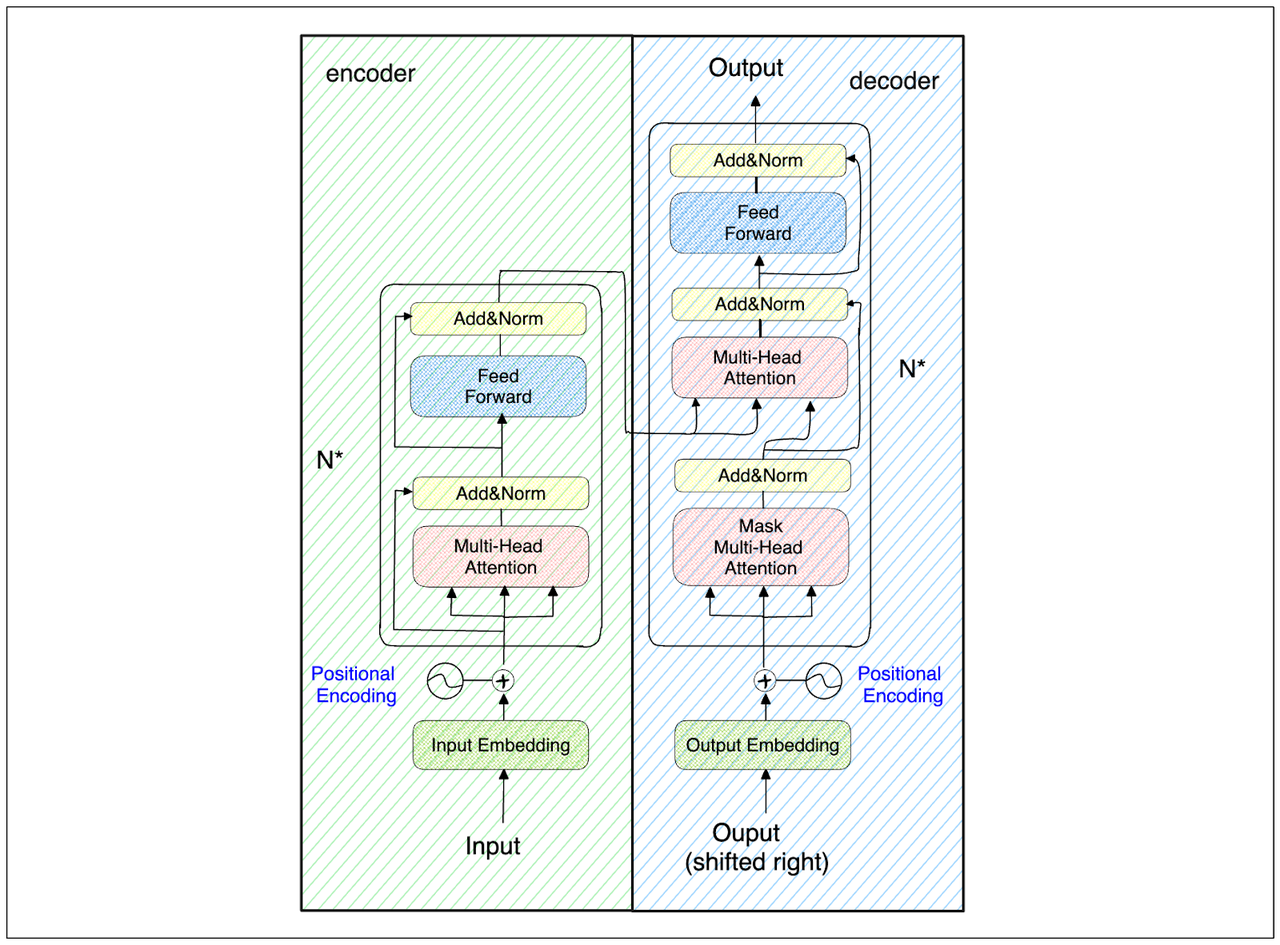
这些RNN的限制导致了Transformer的开发,它使用自注意力机制并行处理输入序列并避免梯度消失问题。
 109.4.png
109.4.png
Transformer架构
Transformer架构由几个编码器和解码器块组成。每个编码器和解码器块包含一个特殊的层,称为注意力层。这层在确定每个标记相对于整个输入序列的语义含义方面起着至关重要的作用。例如,考虑以下三个句子:
苹果在2023年实现了970亿美元的利润
我喜欢在2023年吃苹果派来获利
苹果的底线在2023年以创纪录的数字增加
如果我们仅使用传统方法,如基于关键词的方法,前两个句子将是最具相似性的一对。我们在这两个句子中找到了三个相似的关键词:苹果、2023和利润。
然而,我们知道第一和第三个句子是最具语义相似性的一对。Transformer架构内的注意力层可以捕捉到这种上下文,并返回第一和第三作为最具语义相似性的一对。
Transformers模型的强大性能和多功能性导致了AI在不同领域的快速发展,从计算机视觉到NLP和多模态任务。
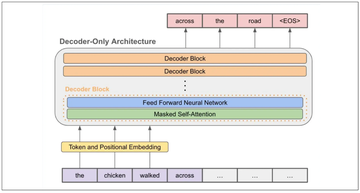
在Transformers大获成功后引入的模型之一是生成预训练Transformers(GPT)模型。这个模型使用Transformer架构的解码器部分来预测输入序列中的下一个标记,并被用作许多我们迄今为止所知道的LLMs的主干,如ChatGPT和Llama。
 109.5.png
109.5.png
GPT架构
这些LLMs在生成类似人类的响应方面非常强大,因为它们已经在大量数据上进行了训练。然而,正如你可能已经知道的,训练数据有一个截止日期,这意味着如果我们询问比训练数据更新的信息,我们将无法从我们的LLMs获得准确的响应。这就是我们需要定制我们的LLMs的地方。
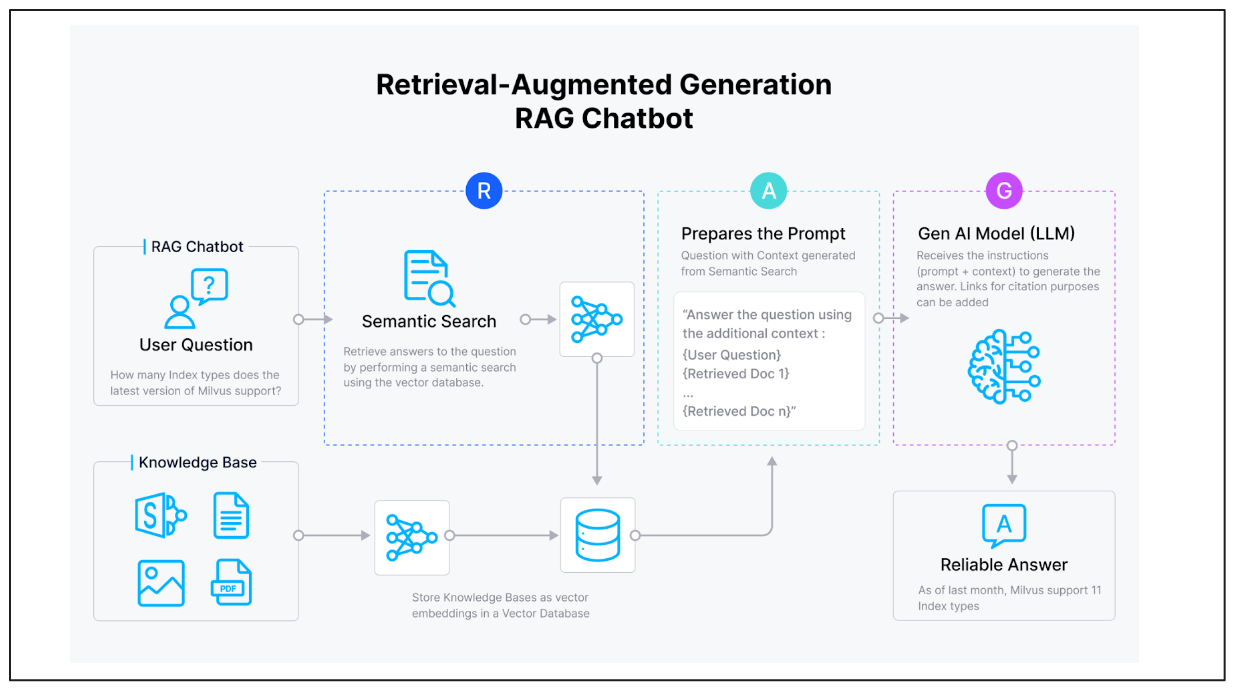
检索增强生成(RAG)
我们可以通过RAG来定制我们的LLM,其概念相当直接。我们为LLMs提供查询和相关上下文作为输入,使它们能够通过利用提供的上下文生成上下文和准确的响应。
 109.7.png
109.7.png
向量嵌入数据及其元数据的示例
元数据在执行各种过滤器期间非常有用,以便在向量搜索操作中为我们的LLMs提供更精确的上下文。例如,您可能想要获取来自特定出版物的上下文或在特定日期之后发布的上下文(例如,2020年)。
一旦我们有了查询并知道我们想要过滤的特定元数据,像Milvus这样的向量数据库将执行其工作。它将执行向量搜索,以找到最符合我们查询的语义相似的上下文,满足元数据过滤条件。
微调
通过微调定制LLMs的另一种方法是微调。概念很简单:我们在自己的数据上训练预训练的LLM,从而获得针对我们数据领域特定任务的新权重模型。
有几种方法可以微调LLMs:
完全微调:这种方法修改原始LLM内所有参数的权重。然而,它涉及昂贵的计算过程。
LORA:这种方法在LLM架构内引入低秩适配器。在微调期间冻结原始权重,并且只更新适配器的权重。
QLORA:这种方法引入了原始LORA方法的量化,降低了计算成本和资源,同时保持合理的性能。
 109.8.png
109.8.png
完全微调与LORA
现在我们知道了不同的微调方法,让我们讨论不同的微调技术:
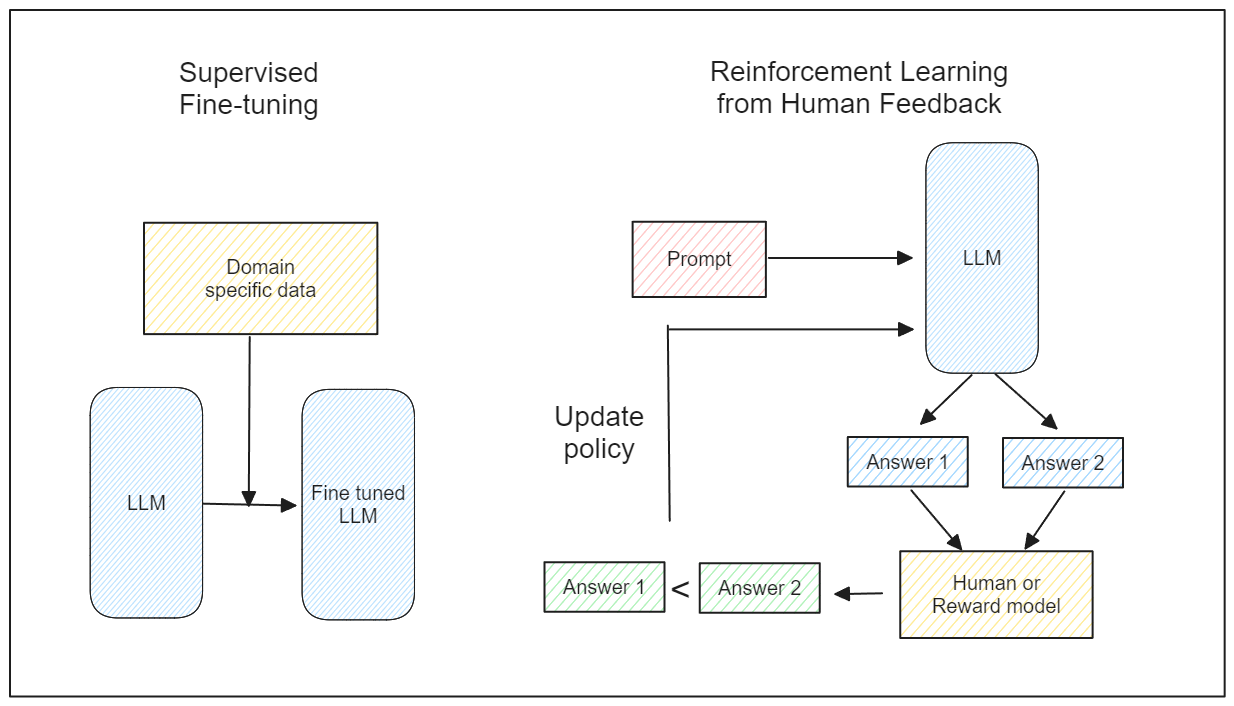
监督微调:这种方法中,我们为我们的LLMs提供我们自己的训练数据和相应的标签。然后我们像任何监督机器学习模型一样训练我们的LLMs。
人类反馈的强化学习(RLHF):这种方法结合了强化学习理论。我们根据查询收集LLM的各种响应,然后评估每个响应的质量。随着时间的推移,我们的LLMs产生与我们偏好一致的响应。
 109.9.png
109.9.png
监督微调与人类反馈的强化学习
由于监督微调是直接的,让我们更详细地讨论RLHF。原生RLHF的一个缺点是需要人类评估LLMs生成的响应的质量。这种方法成本高昂且耗时。
数据科学家引入了近端策略优化(PPO)来缓解这个问题。PPO引入了一个奖励模型来替代人类评估。然而,这个奖励模型需要单独训练,使得PPO应用变得繁琐。此外,每次添加新数据时都需要重新训练奖励模型。
为了解决这些问题,引入了直接偏好优化(DPO)。DPO使用人类偏好数据上的负对数似然损失函数来优化LLM的策略。使用DPO进行微调的数据集包括提示、首选响应和不首选响应:
使用DPO微调LLMs的数据格式示例
109.9.png
然而,DPO倾向于快速过拟合偏好数据集。为了缓解这个问题,开发了身份偏好优化(IPO)。
IPO:IPO在DPO损失函数中引入了一个正则化项,以避免过拟合。它还使用附加到负对数似然(NLL)损失函数的对数比率项,允许LLM根据所需的风格进行微调,同时惩罚不首选的响应。
#结论
Yujian Tang在他的演讲中讨论了各种定制LLMs的方法,以便在我们特定的用例中最佳使用。演讲首先提供了导致LLMs开发AI进步的简要历史。这个话题之后是两种定制LLMs方法的解释:RAG和微调。
RAG通过在查询旁边注入相关上下文作为输入来增强LLMs生成的响应质量。像Milvus这样的向量数据库存储上下文嵌入并执行向量搜索以实现RAG。然后LLMs使用这些上下文生成适当的答案。
第二种方法是微调,有两种微调方法:
监督微调:这种方法涉及为我们的LLMs提供我们自己的训练数据和相应的标签,然后像任何监督机器学习模型一样训练它们。
人类反馈的强化学习(RLHF):这种方法结合了强化学习理论,我们收集基于查询的LLM的各种响应,然后评估每个响应的质量。随着时间的推移,我们的LLMs产生与我们偏好一致的响应。
有关LLM定制的更多详细信息,请观看Yujian演讲的回放。
 Ruben Winastwan
Ruben WinastwanFreelance Technical Writer


