



如何理解On-demand,为什么每个做大数据语义分析、挖掘、回归的团队都需要它?
今年年初,我们一个自动驾驶客户提出了一个新需求。他们的数据分析团队希望在超过 1B 的向量数据集上做数据分析、corner case挖掘。另外,这份底库平时会由线上检索服务和模型训练团队共用,数据分析只是新接入的一类工作负载。
单看数据规模和搜索方式,这并不是一个罕见场景。比较棘手的,是这个新增数据分析负载的访问频率以及计费模式。
数据分析团队只会在某个任务出现后一些很低频的迭代式的搜索。也就是说,计算压力会在短时间内出现,一个月真正需要搜索的时间只有两三个小时。
按照已有的用例,在一个Zilliz Cloud Tiered cluster上,一个月24CU ,账单在$7K上下。
搜三个小时,花$7K,这真的合理吗?
账单是合理的,Dedicated Cluster 出发点是长期在线服务:通过资源提前准备好,数据提前加载好,让服务持续可用。它是按峰值规格,以在线服务的模式持续计费的。但分析任务,服务时间短、峰值还高,就导致一个月大约 720 小时,有 717 小时左右,让大量算力空转,致使闲置成本接近总开销的 99.6%。
后来,团队的第一反应是换成 按查询付费的Serverless。产品体验上,Serverless 隐藏了计算资源,用户不需要选机器、不需要管节点、不需要提前预留容量。对于轻量查询、早期应用、流量不可预测的业务,这种模式通常很有吸引力。可一旦底库很大、写入数据较多、周期性高频查询也存在,Serverless 的溢价会被放大。
对这个客户来说,问题就在于底库不是只给分析团队用。模型训练团队还会周期性跑回归任务,从同一份底库里连续拉取场景数据。这个任务每两周一次,每次大约 100 QPS,持续 3 小时。这种任务已经不属于Serverless面向的少量偶发查询,而是非常典型的短时间高吞吐访问。仅仅这部分训练回归负载,Serverless 查询费用就接近 $6K。
更麻烦的是存储和写入。这个场景下,Serverless 存储费用约 $1.7K,写入费用约 $3K。加上查询费用后,整体账单来到 $10.7K 左右,甚至还高于 Dedicated Cluster。
这种两难在生产中其实很常见,那么有没有一种方式,能让账单只跟真实消耗的算力走,不同团队各自选择合适的定价与资源?
这就是我们将Zilliz Cloud从Vector Database升级为Zilliz Vector Lakebase,并推出On-demand模式的原因。
我们为什么要推出 On-demand
On-demand 是 Zilliz Cloud 上新的计算形态。它不要求用户预留算力,也不要求用户手动预热。查询到来时,系统能秒级拉起计算节点;查询结束后,节点自动释放;计费按计算节点的真实在线时间计算,精确到分钟。
同一份数据上,还可以挂载多个 On-demand session,分析、回归、批量挖掘各自使用独立计算资源,不互相抢占。
在开头那个客户场景里,账单可以从 Dedicated 的约 $7K、Serverless 的约 $10.7K,降到 $500 以下。
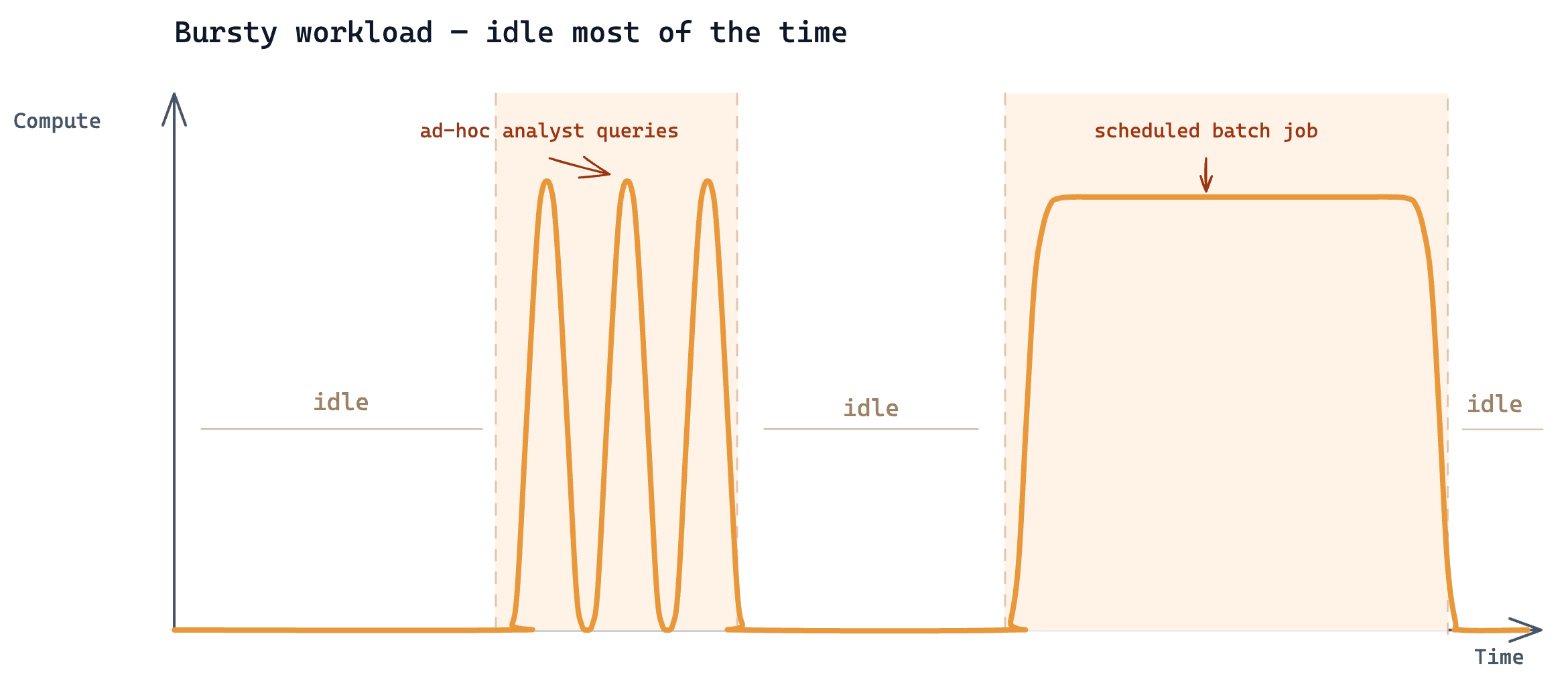
On-demand 不是把 Dedicated 做成自动开关,也不是把 Serverless 换一张价格表。它要解决的是大数据集上的短时计算问题。
要让这个模型成立,系统必须同时处理三件事:冷启动不能依赖全量加载,计算资源必须由平台自动拉起和释放,存储与写入不能继续承担 Serverless 风险溢价。
两条老路都走不通:为什么 Dedicated 和 Serverless 都不够
Dedicated Cluster 的边界
Dedicated Cluster 擅长持续 QPS、低延迟和可预测在线服务。它的设计前提是资源长期在线,数据提前加载,服务状态持续维护。在线检索、推荐召回这类业务需要这种稳定性,因为任何一次冷启动、抖动或资源不足都可能影响用户请求。
但同样的设计放到分析负载以及波段型业务上,就会产生大量空转。
- 为不需要的算力付费: 正如开篇说到的这个场景,无论是偶发的分析场景还是小段持续的波段场景,他们的算力使用时间都只占用了整体的一部分,为了这部分时间的稳定运行支付大量无用算力显然不是一个很好的选择。
- 冷启动又慢又重: 除了产品计费模式外,从技术侧也有问题。Dedicated 的模式往往是把所有需要的数据全部预加载再进行搜索,可一次分析查询只关心全量数据中的一小部分,导致加载的数据量往往是最初冷查询所需的几十甚至百倍。结果是 IO 被浪费,启动时间也被拉长。在 1B 级数据集上,冷启动达到 10 分钟级并不奇怪。对于交互式分析,10 分钟等待会直接打断分析师的工作流。此外,Dedicated 的模式除了为这次查询准备数据外,还需要为别的负载类型提供状态准备,比如DDL、删除等,同样会引入较多无用的overhead。
- 手动管理: 为了缓解这个问题,有的用户会手动启停,非常麻烦。除了使用不方便以外,由于上边说到的冷启动的问题,计费往往也是以小时为粒度,对于偶发一两个查询的场景性价比极低。
Serverless 的边界
Serverless 解决了 Dedicated 的预留问题,但引入了另一种成本错配。从技术上,Serverless 意味着无状态,因此稳定且轻量,在产品上,它往往意味着无需指定算力规模,按需付费。这些点几乎完美地解决了 Dedicated 场景的痛点。麻烦在于,目前在向量数据库领域赢得 mindshare 的 Serverless 版本,把这些优点和另外一条逻辑上不必绑的东西捆在了一起:按照数据size的计费模型。
为什么查询很贵? 对于用户来说,整个 Serverless 服务是无状态的。但在平台眼里,数据始终是要加载到具体的机器上执行的。因此对于平台来说,查询是有冷热之分的,并且热查询由于不需要拉取对象存储,不用付出加载overhead,在成本上是更加便宜的。同时 Serverless 服务往往为了覆盖频繁冷查的成本,在单位查询的定价上几乎都是收取了额外的溢价的。
为什么存储和写很贵? 写入和存储本身是需要付出资源成本的,但是在 Dedicated 场景,这部分价格被合入了计算的机时费中,因此并不明显感知。在serverless场景,少了机时费兜底,为了应对只存不查的情况,平台侧往往要对存储收费,同时为了避免用户高频更新,只产生大量写入成本却不增加存储,平台只能把写入单独计费。而平台侧需要保持随时可查,因此不能使用非常冷的存储方式,且需要维护额外的状态,这些成本只能强摊到 storage size 和 write operation 这种和真实消耗对不上的单位上。结果就是这两项的单价远超它们的真实边际成本。
其实两个问题的根因是同一个:Serverless 把"计算资源"这层抽象从用户面前藏掉了。用户只看到一个无状态接口,平台却要在背后为不可预测的访问模式买单——冷热数据无法预约、突发流量要预备容量、储而不查的存储要兜底——这些隐藏成本没办法精确归因到具体用户,只能均摊到查询、存储、写入这些可计费动作的单价里,每一项都比真实边际成本贵一截。这种“风险均摊"的模式对真正连续高频的热查最不友好——单价里摊着别人冷查、突发、储而不查的成本,越是稳定的高频查询,溢价占比越高。
On-demand 怎么改资源模型
On-demand 的核心判断是:这类场景最合理的计费单位应该是计算资源在线时间。用户需要在某个任务期间拉起计算,任务结束后释放计算。数据仍然保留,索引仍然可用,但计算不必常驻。
为此,我们做了三大优化:
优化一,数据分块:只加载查询需要的部分
要让这个模型成立,第一步是解决冷启动。如果一次查询启动要 10 分钟,分钟级计费没有意义,用户会为等待付费,分析体验也会崩掉。因此 On-demand 不能沿用全量加载思路,必须把数据加载改成按查询读取。
看上去一句话能讲完,实际要在三层同时重新设计——决定读什么、决定放哪儿、决定怎么读上来。
索引优化:只读真正需要的部分
每次查询,无论是标量过滤还是向量搜索,实际上只关心数据的一小部分。这套机制在很多引擎上已经稀松平常,它能在标量侧大幅降低需要拉取的数据量;要让向量侧也具备类似的"读子集"能力,索引结构本身必须支持按需加载。
标量侧采用倒排索引,每条倒排链以 block 为最小加载单元,链上额外提供 minmax 这类简单统计支持下推。向量侧采用 IVF 家族索引,通过聚类把数据切成多个 bucket,搜索时只拉取距离最近的几个。
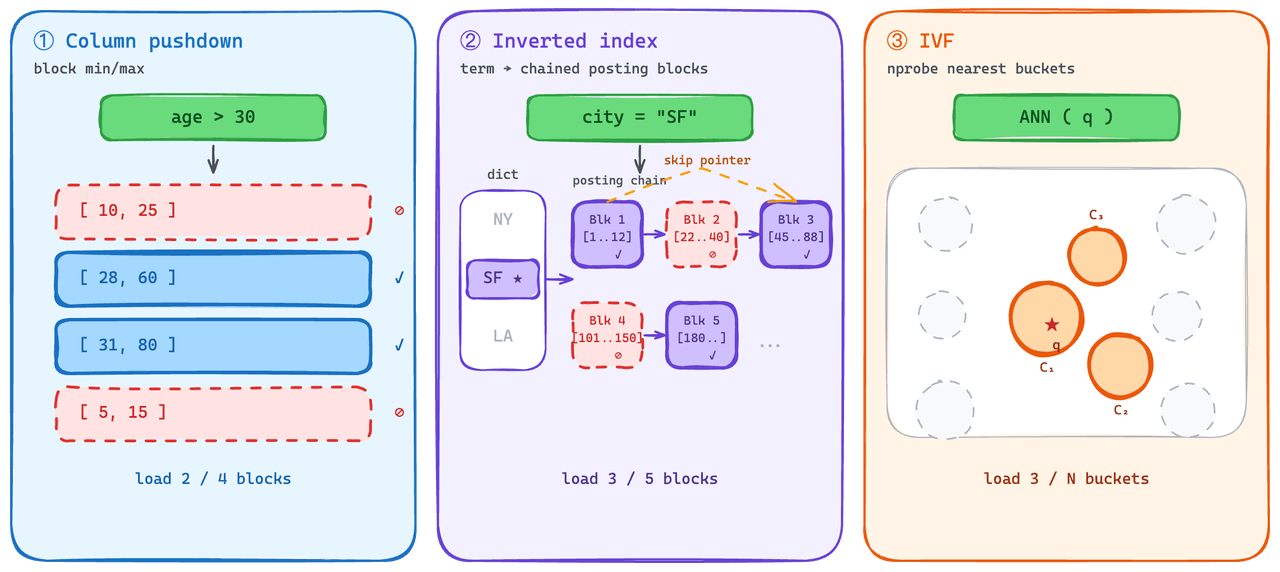
分层缓存:让冷查搬更少的数据
通过把数据切分成更小的粒度,冷查询需要拉取的数据量能够压缩到全量数据的1%-2%以下。这些小粒度的数据能在S3、磁盘、内存里自由流转,可以被缓存和驱逐,查询之间可以按照这个粒度管理缓存的生命周期,让各种查询都更加平稳可控。
工程优化:避免随机 IO 和带宽浪费
小粒度读取也带来新的工程问题。如果只是把数据切小,却没有重新设计布局,就会出现请求放大、随机 IO 和带宽浪费。On-demand 在对象存储和本地磁盘上采用不同的数据组织粒度,让读取方式匹配介质特性。整条 IO 链路采用异步执行,计算和读取流水线化,减少 CPU 与 IO 互相等待,充分利用节点资源。
优化二,资源管控:从集群思维切到 session 思维
为了做到按需的节点拉起,我们给数据库引入了资源管控能力,能拉起释放节点。同时做了备用节点池,作为缓冲规避镜像拉取影响到节点的启停。在又把冷启动压到秒级之后,"按需启停"这件事在产品上才真的成立。query 来了,系统拉起算力、秒级响应;分析师离开或者查询脉冲过去、TTL 到期,算力自动释放。整个生命周期由平台调度,对用户透明,不需要任何人工运维。
同时得益于轻量的拉起和释放,我们能把查询的计费粒度压缩到分钟级,规避了为一个查询付费一小时的困境 (同时还得加载 10+ 分钟)。在写入计费侧,我们同样以分钟为粒度精确计量真实的资源使用,按需收费。因此, On-demand 模式能够精确计算成本,从而不必再在存储上添加溢价,收费标准按照 Dedicated 标准走,存储价格几乎是常规 Serverless 的 1/10.
优化三,资源隔离:存算分离,更适合多team协作
在自动驾驶、机器人、金融风控、内容理解等场景里,一份底库往往会同时服务多种任务。线上服务关心低延迟和稳定性,训练团队关心周期性高吞吐,分析团队关心交互式探索,批处理任务关心大规模扫描和挖掘。如果这些负载放在同一个集群里,很容易互相抢占资源;如果拆成多个集群,又会带来数据复制、索引重复构建、成本上升和治理复杂度。
On-demand 通过践行存算分离为多team多场景协同合作提供便利。让同一份 collection、同一组 index、同一套 metadata 挂载不同计算 session。一份数据可以通过新建或者复用session来隔离出一个新的计算资源组或者复用老的资源组。不同的pattern,不同的工作时间得以轻松共存。
On-demand 能节约多少资源成本,谁适合它
回到开头的客户。Dedicated Cluster 每月约 $7,165,主要成本来自长期空置。Serverless 每月约 $10,784,因为查询、存储和写入都包含平台风险溢价。On-demand 按计算在线时间收费,存储按实际占用收费,最终账单不到 Serverless 的 1/20。
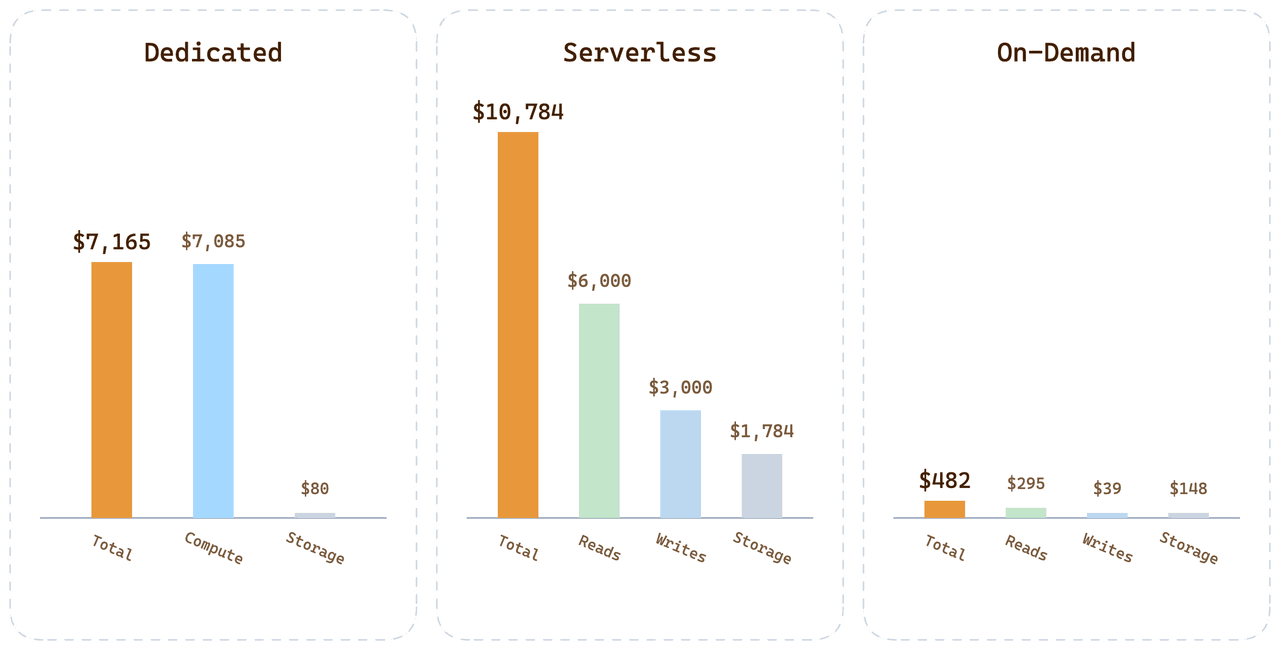
当然,这组数字不说明 On-demand 对所有场景都便宜。
产品形态必须匹配访问模式。持续在线、低延迟、高 QPS 的主路径服务仍然适合 Dedicated。轻量接入、早期验证、流量不可预测的应用适合 Serverless。大数据集上的短时分析、周期性回归和批量挖掘,应该使用 On-demand。
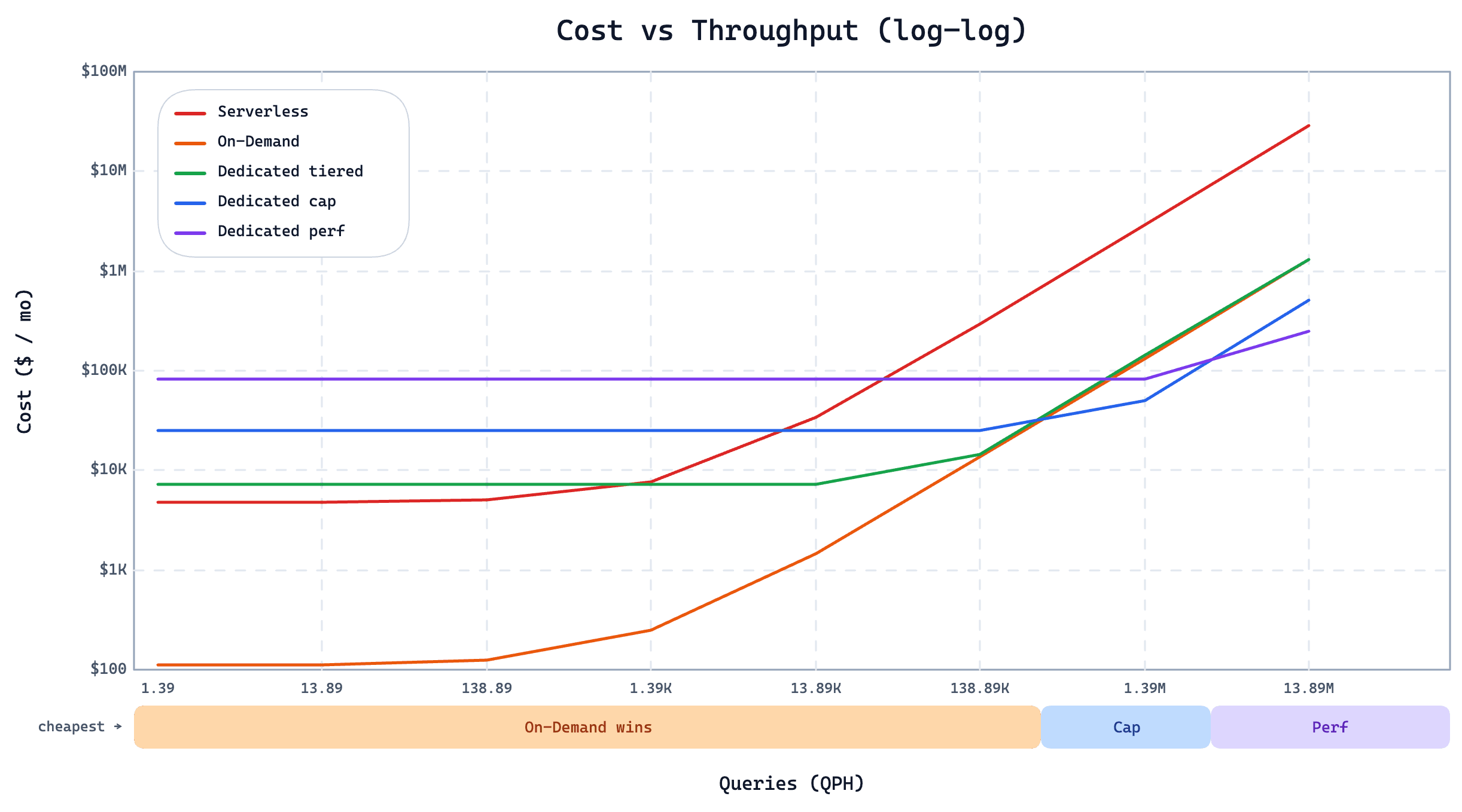
图中展示了同一客户用例在不同查询压力下三种方案的月费用。查询量较低时,On-demand 成本最低;当 QPS 上升到几十以上,Dedicated Cap / Perf 实例反而最优性价比。
这张图也很好地展示了选型的 best practice,揭露了 On-demand 的优缺点。
- 为了缓解冷查压力,On-demand 没有选择使用整体性能更强的图索引,因此在中高(>几十)QPS场景下, Dedicated 的 Cap 实例和 Perf 实例是更加合理的选择
- 图中没有表现的是 On-demand 由于冷热查的属性,它的性能稳定性相比 Serverless 和 Dedicated Tiered 会有差距。对于无法忍受秒级甚至分钟级延迟的场景,On-demand 的冷查会成为一个问题。
所以 On-demand 的定位很清楚:它服务大数据集上的稀疏访问、短时计算、分析探索和批量挖掘。它补上 Dedicated 和 Serverless 之间的空白,但不替代二者。
On-demand 是 Vector Lakebase 的一块拼图
On-demand 解决的是大数据集上的分析探索、周期性回归和批量挖掘。但解决"同一份数据需要被多种节奏访问"这件事,不能只靠On-demand 。
过去,向量数据库主要服务在线检索。数据写入,构建索引,提供 search。现在,向量数据同时服务在线应用、模型训练、数据分析、评测集构建和批处理 pipeline。如果每种负载都复制一份数据、重建一套索引、维护一个集群,成本和治理都会失控。
更合理的架构是让数据留在湖上,让不同计算形态挂载到同一份数据。在线服务负责实时检索,On-demand 负责分析探索和批量挖掘,Spark / Ray 负责数据 pipeline。这些计算资源可以独立伸缩、独立隔离、独立计费,但读写的是同一份 collection、同一组 index 和同一套 metadata。
这套架构我们叫 Vector Lakebase。On-demand 是其中一个能力。外表零拷贝接入湖数据、Spark 上的向量批处理、Schema 后台演化,更多相关的细节,我们会在下一篇展开。
附Zilliz Vector Lakebase 能力一览
当前阶段的Zilliz Vector Lakebase ,主要做了五方面的能力建设:
- 服务能力升级:推出分层服务方案,为极致性能、容量优化和低成本分层存储等不同场景提供对应选择。
- 按需搜索能力升级:推出按需搜索(On-Demand Search),让大规模低频检索、数据探索和离线分析不再需要长期维持闲置计算资源。
- 数据湖搜索能力升级:支持外部数据湖搜索(External Data Lake Search),可直接在已有数据湖上增加高性能索引和大规模搜索能力。
- 检索能力升级:在同一系统内支持向量搜索、全文搜索、JSON 查询、地理空间搜索、多向量搜索、多路径检索和重排序。
- 湖原生存储能力升级:同构统一的lake-Native Storage,基于 Vortex 开放格式,为在线服务和离线分析提供统一、高效、低成本的数据底座。与 Lance 和 Parquet 相比,它能提供更快、更便宜的随机读取,以及按列格式的灵活性和更广泛的数据建模能力。
 刘力
刘力


