深度 | 如何理解AI时代的企业级Large Search,又该如何实现?
在过去十几年的古典互联网时代,搜索的负载模型很好预测:用户输入几个关键词,浏览一页结果,一次查询就结束。
这套模型的真正瓶颈,从来都不是后端的吞吐能力,而是人类的物理限制。一个人一次能想到的关键词、能双手输入的文本长度,构成了一个极其狭窄的“输入带宽”。整个搜索市场的总量,被死死限制在人类大脑与手指的物理上限之内。
大语言模型(LLM)的到来,将这个长达数十年的前提条件推翻了。
用户不再需要把需求压缩成几个干瘪的关键词。一句模糊的"按最新判例分析这份合同的风险",大模型能解析出背后真实的检索意图,并代为拆解成几十次、上百次检索、召回、比对和过滤。
由此带来两个变化:一是使用门槛大幅降低,用户用自然语言表达需求即可,不必懂得如何拆解关键词;二是模型理解意图后,会主动、反复地发起检索。
巨大的长尾检索需求随之被释放。结果就是,今天的搜索请求里,已有相当一部分不再由人类逐字输入,而是由机器代为发起。单个用户背后的搜索量,在瞬间被放大了一到两个数量级。
搜索量能指数级放大,还有一个原因:在 AI 的用法下,按语义去搜变得便宜了。
这里需要厘清一个技术误区:按语义去搜变得“便宜”了,并不是指向量检索的单次计算比传统关键词匹配更省。它的便宜,是相对于“让大模型逐条去读文本、去比对语义”这条昂贵的路径而言。
真要按语义找东西,最朴素的办法是把候选内容一份份喂给大模型判断,token 成本根本扛不住;而向量检索把语义压进向量,用很低的成本就能在巨大的空间里按语义快速收敛出一个小集合,再把这一小撮交给大模型细看——大规模的语义检索,这才第一次算得起。至于传统全文检索,走的还是关键词匹配那套;在它之上叠一层语义向量检索如今也不难,两者结合就是 hybrid search,语义和关键词各补一头。
这种由大模型驱动的需求放大,与语义化混合检索(Hybrid Search)形态的叠加,就是我们定义的 Large Search(大搜索)。
而当搜索的量级和形态发生本质改变时,技术关注的焦点也随之发生了跃迁。古典时代关注的是“能不能搜到”; Large Search 时代,核心命题变成了:当搜索量被推到如此恐怖的量级,系统能否以绝对的稳定性、极致的低成本,优雅地将其服务好。
这就是 LSS 要回答的问题。三个字母分别是:
| - L = Large Search:AI 时代用户的"大",到底大在哪几层。 - S = Scale:资源怎么跟着容量和流量自动调整。 - S = Serving:这些能力怎么变成一个企业可以长期依赖的在线服务。 |
|---|
接下来,我们将沿着 Large Search(重构大)、Scale(弹性哲学) 与 Serving(企业交付) 这三大纵深谱系,拆解全托管向量数据库的应该如何打造。
L = Large Search:重新定义“大”的四个象限
Large Search 常被简单理解成数据量大。但数据量只是其中一个维度,不同类型的"大"对系统提出的要求并不相同,放在一起讨论容易失焦。
我习惯把它拆成两类来看:大数据和大请求。大数据看的是数据怎么分布,决定如何隔离、如何缓存;大请求看的是请求和写入怎么进来,决定往哪个方向扩。
大数据:数据怎么分布
同样是海量数据,"一千万个用户各管自己一小份"和"一份巨型数据所有人共用",是两个完全不同的工程问题。
多租户型。 Cursor 是最典型的例子。它的数据不是一个公共大库,而是散在海量用户、组织、project、workspace 里的私有数据。单个用户的数据量并不大,几十万条代码片段、文档、commit、对话上下文而已,但用户基数极大——假设全球上亿程序员、千万级活跃,每人几十万条要被 Agent 检索的上下文,乘起来就是一个巨型的多租户搜索问题。
这里真正的难点不在查询性能,而在隔离:每个用户的数据、上下文、权限边界必须清晰分开,不能互相串;活跃用户和沉默用户的访问冷热差异巨大;而这千万个租户如果各占一份固定资源,成本会立刻失控。它本质上是一千万个小库同时在线,而不是一张大表。系统侧对应的是数据分区和租户隔离。
共享数据型。 Exa、Filevine 这类大规模共享数据场景是另一种类型。数据是一份(或高度重合的一份)巨型共享集——网页、企业知识库、商品库、图文视频向量混在一起,所有人搜的是同一套。
规模有多大? 我们的POC经验是,近百亿条数据 、百亿TB 存储、一千多CU。
这类数据有个特点:访问极度不均,少量热点被反复检索,大量长尾几乎无人访问,但又不能丢弃,必须随时可检索、可更新。所以既无法全部放进内存,也不能每次都从冷存储读取。这正是后面冷热分层要解决的问题。
此外,对 OpenEvidence 这样的严肃专业(医疗、法律)领域,还要海量数据、相关性的基础上叠加一层准确性与实时写入(Real-time Ingestion)的时效性约束。系统侧对应的不是新的资源模型,而是混合检索的召回质量、metadata 过滤与溯源,以及靠实时写入保证的时效。
大请求:请求和写入怎么进来
数据分布决定怎么存、怎么隔离;请求和写入怎么进来,决定往哪个方向弹性扩展。
在线高 QPS。 Agent 产品、搜索入口、推荐召回、代码补全,共同点是请求实时发生、且会突然升高:一次 Agent 任务可能在几秒内打出几十个并发检索,一次热点事件可能让 QPS 翻几倍。传统互联网DoorDash 这类实时在线业务是典型——在线 QPS 高,对延迟敏感,因为延迟会沿 Agent 的调用链逐层放大。它的痛点不在"装不装得下",而在"能不能同时服务过来"。系统侧对应的是加 replica 扩展吞吐。
批量写入。 这一类最容易被忽略:查询大,数据写进来的过程同样大。AI 时代的数据不是导入一次就结束——知识库、代码库、网页、专业文献都在持续更新,Agent 自己也在不断产生新的上下文、日志、记忆。这些数据大多是批量进入的:一次性导入、周期性抓取、定期重建索引。痛点在于,客户不该为了应付偶尔的批量高峰,长期保留一组闲置的计算集群。系统侧对应的是 batch compute(Lakebase)——需要计算时临时拉起,计算完成后回收。Minimax 模型训练、自动驾驶就是典型:批量处理完,资源即释放。
大数据 + 大请求,四类大
归纳一下:大数据这边有多租户型(要隔离)和共享数据型(要冷热分层,专业场景再叠加可信和时效);大请求这边有在线高 QPS(加 replica)和批量写入(batch compute)。再加上一条贯穿所有场景的约束——成本。
用户侧的每一类"大",系统侧都有一个明确的能力对应。下面看 Milvus 具体怎么做。
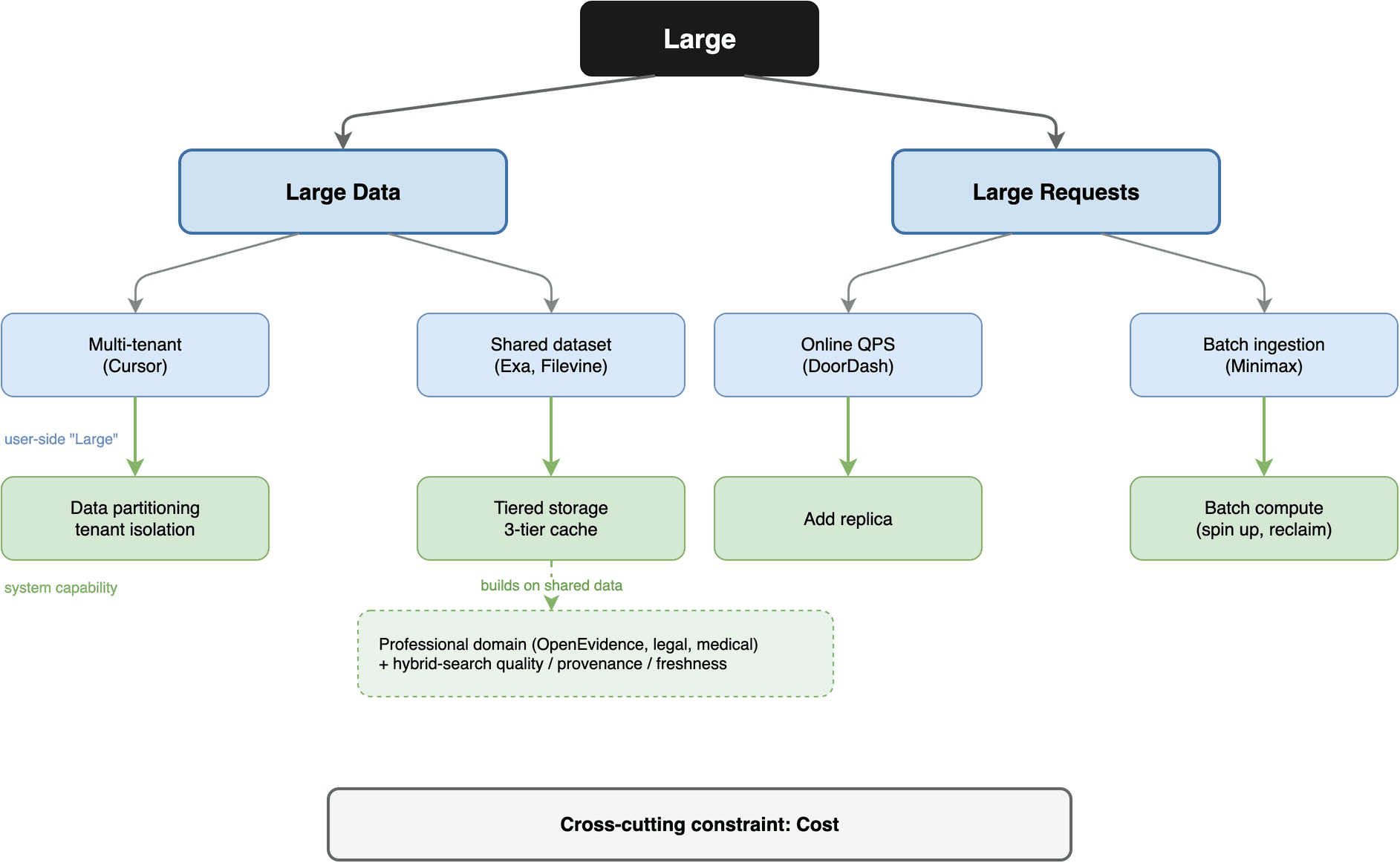
Large 拆成大数据和大请求:四类大与各自对应的系统能力
Milvus 怎么支撑这些"大"
Milvus 要支撑 Large Search,前提是超大数据、超高 QPS、低延迟和租户隔离同时成立。沿着大数据和大请求这两类,它的支撑能力主要落在三块:冷热分层存储、自研向量索引、租户级数据分区,再加上针对不同 workload 的实例形态。
冷热分层与三级缓存
这一块对应共享数据型和容量问题。Milvus 不假设所有数据都是热的,因为现实中数据的冷热分布很明显。它把不同温度的数据放到不同介质上,串成一条链路:
| 层级 | 介质 | 角色 | 特点 |
|---|---|---|---|
| 内存 | Memory | 服务最热查询路径,支撑低延迟在线检索 | 最快,容量小、成本高 |
| 本地磁盘 | Local Disk | 缓存热点数据与索引,屏蔽 S3 延迟 | 较快,容量中等 |
| 对象存储 | S3 | 承载全量数据、持久化兜底 | 最慢,近乎无限、成本最低 |
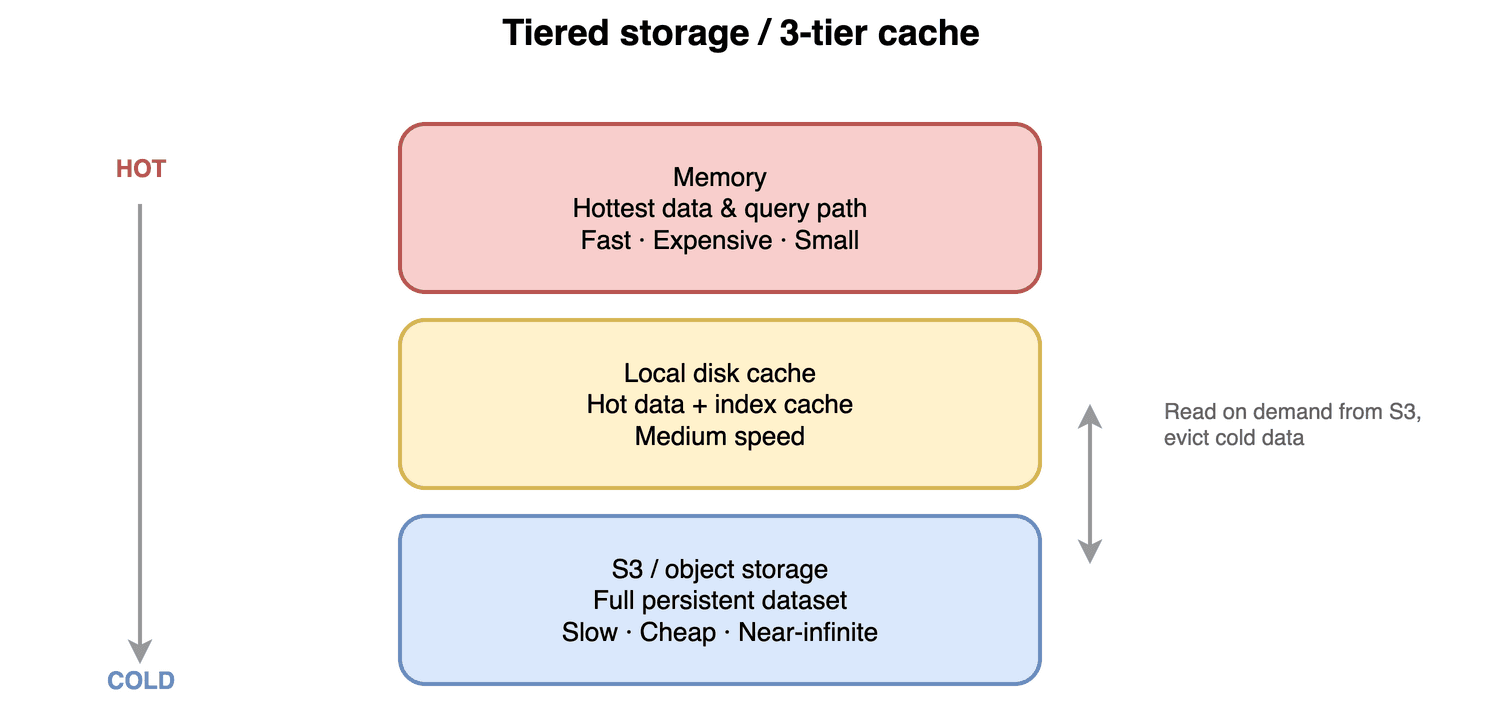
三级缓存:内存 / 本地磁盘 / S3 的冷热、成本与延迟
这条路并非凭空设计。ClickHouse 在走向云原生时公开过几乎相同的演进:对象存储兜底,本地 SSD filesystem cache 把热点拉近,内存 page cache 负责最快的执行;后来又把本地缓存做成分布式缓存,让弹性扩缩的计算节点之间共享热数据,省掉扩容后的冷启动(参见 ClickHouse 的 Building a Distributed Cache for S3 和 Stateless Compute)。
我们内部对 Tiered 形态有一句概括:tiered 本质是把对内存的需求转嫁成对磁盘的需求,磁盘后面再按需从 S3 读取和淘汰; 数据再大,通过小 CU也能慢慢算出来。这解释了为什么分层既能装下 PB 级数据、又不必把成本全压在内存上。
具体靠两个机制落地:mmap(内存映射)把索引和数据文件映射到本地磁盘,操作系统按访问把真正用到的页调进内存,不必一次性全量加载;lazy load(按需加载)让数据在被查到时才从下层调上来,而不是预先全部 load。再配合冷数据自动淘汰回 S3,热的留内存、温的留磁盘、冷的回对象存储,三级之间按访问热度自动流动。对客户来说:同一份大数据,分层存储型实例用远小于全内存方案的内存就能扛住,成本随之大幅下降,代价只是冷数据首次访问稍慢。
自研向量索引(含优化版 RaBitQ 量化)
向量搜索的瓶颈在索引。ANN(近似最近邻)的整条主线就一句话:尽量少做那些昂贵的距离计算。Milvus 围绕向量检索自研和优化索引,本质是在三个互相打架的目标之间找平衡——召回、性能、内存/存储成本。这一块直接决定:数据涨上去之后,查询还能不能快、省不省内存、带条件过滤准不准。
索引结构:从分桶到图。 早期主流是 IVF(倒排文件):用 k-means 把向量聚成 nlist 个簇,查询时先比质心、只在最近的 nprobe 个簇里精算,先粗筛再细算。更快的是图索引:HNSW 用分层图做"快速跳转",DiskANN 则把图放到磁盘、以更低内存换取规模。Zilliz Cloud 线上主用图索引,实际性能强于 IVF。
量化压缩:用精度换内存和速度。 把向量压缩能大幅省内存、加速计算,但有损。常见的 SQ8 做 4:1 压缩,PQ(乘积量化)能做到约 64:1,各有取舍。Milvus 自研的 RaBitQ 把这件事做得更好:拆成 Search Quant(查询路径上用小 bit 量化,低存储、高频访问)和 Refine Quant(从候选里精排出 topK,保精度)。
三者对比见下表。线上 Performance 实例采用 Search(RBQ4)+Refine(RBQ8),实测容量提升 30~40%、recall 提升 1~2%。对 Large Search 来说这很实在:数据越大,省下的内存就是省下的钱,而召回还能往上走。
| 方案 | 压缩率 | 精度 | 性能 / 容量 |
|---|---|---|---|
| SQ8 | 4:1 | 较低 | — |
| PQ(乘积量化) | 约 64:1 | 中等(基准) | 基准 |
| RaBitQ(自研) | 高 | 略高于同压缩率 PQ、显著优于 SQ | 性能比 PQ 高一个数量级,容量相当 |
带标量过滤的向量检索。 真实业务几乎都是"向量相似 + metadata 条件"一起搜——专业领域和多租户场景尤其如此(按租户、按权限、按时间过滤)。post-filter 是搜完再过滤,容易不够 k 个、得反复试探,已被主流抛弃;Milvus 走 pre-filter,在图搜过程中结合过滤条件、绕行直到凑齐 k 个结果,保证带过滤时的召回和效率。
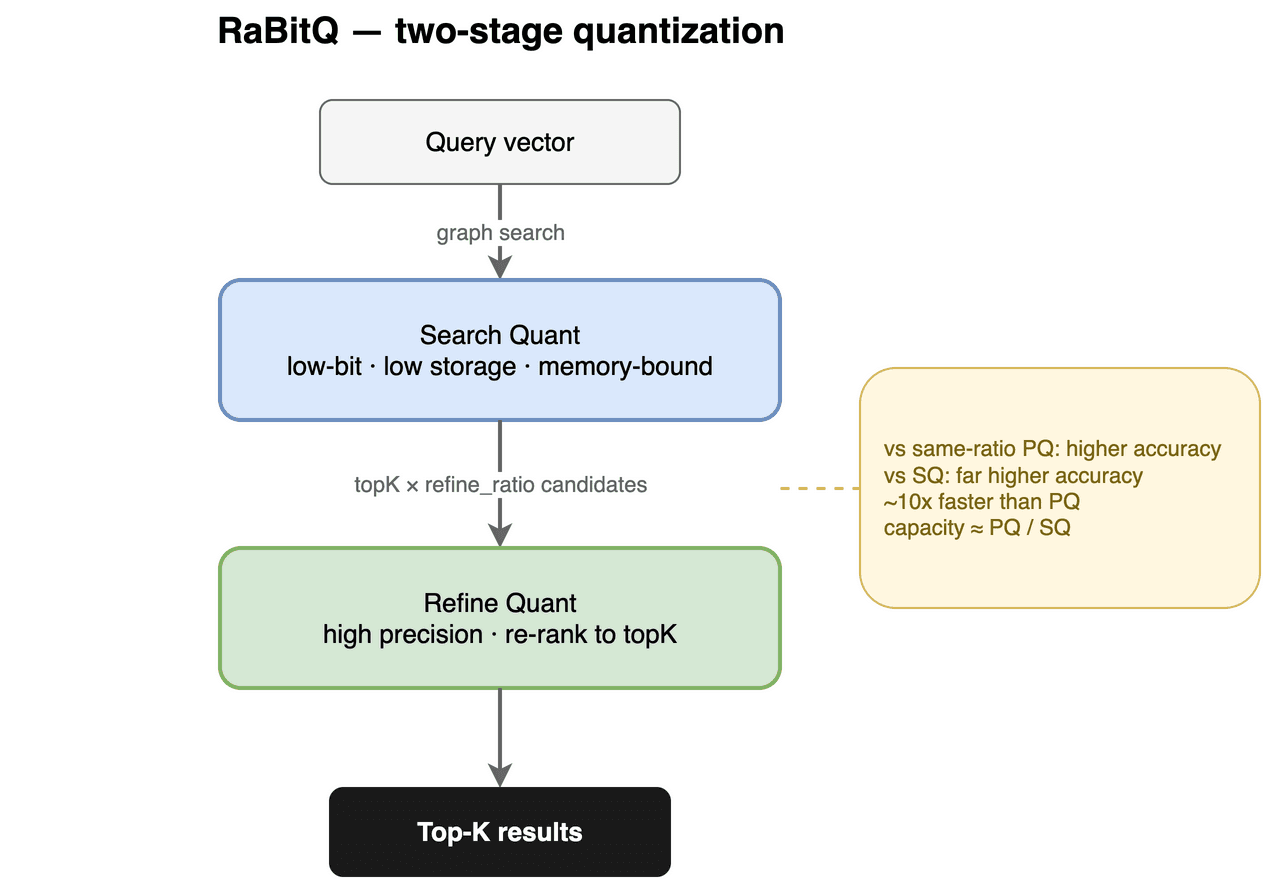
RaBitQ 两段式量化:Search Quant 粗筛,Refine Quant 精排
Hybrid Search:向量召回 + 全文精排
Large Search 里的搜,在 AI 时代基本都是 hybrid search——向量检索和全文检索一起上。要讲清为什么,得先分清这两种检索各自擅长什么。
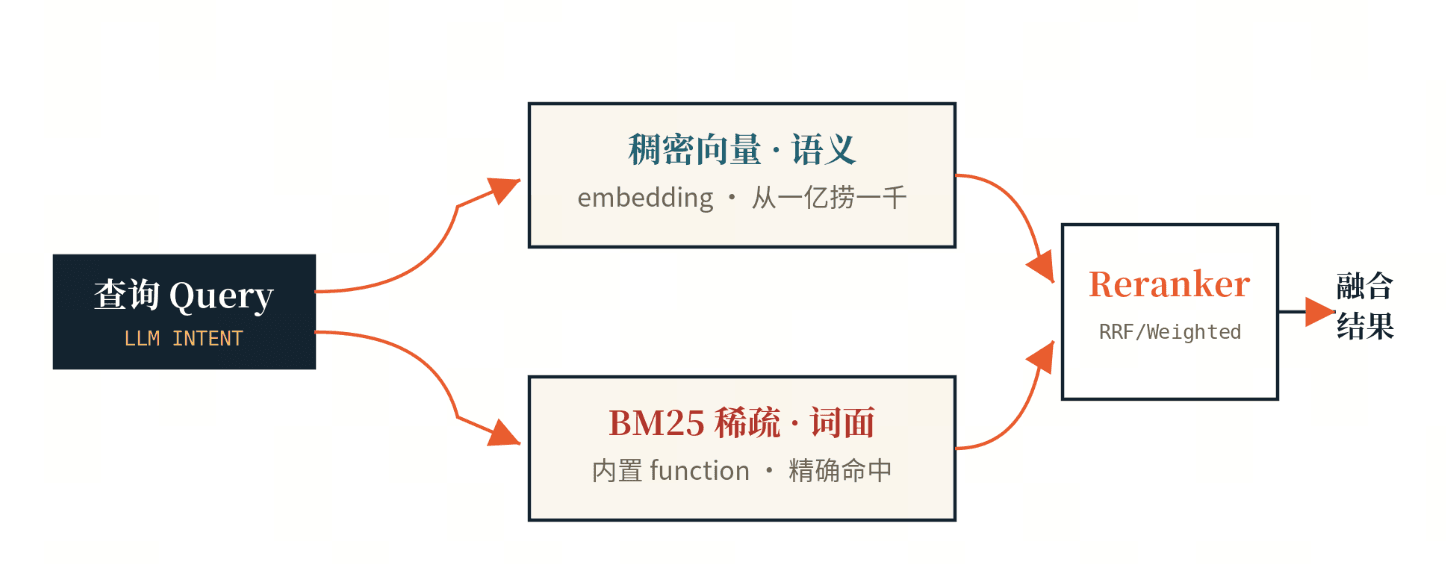
全文检索(text search) 走的是 BM25。在 Milvus 里它是内置 function:你只存一个文本字段,库内用分析器分词、按 TF/IDF 和文档长度归一打分,把文本转成稀疏向量来检索,全程不需要额外的模型推理或外部集成。词面命中又快又准——搜索范围不大,或者要的就是精确关键词、专有名词、ID 时,全文检索最舒服。和传统 ES 关键词搜索相比还更进一步:大模型本身懂语义,能把到底想搜什么理解到位。
向量检索(vector search) 是把文本、图片等编码成向量,比的是语义相似而不是字面。它最关键的作用是低成本地缩小范围:大模型不可能逐篇去读全部文档,token 成本扛不住;但可以先用便宜的语义检索,从海量文档里粗筛出一个相关的小集合,再交给后续精排或大模型细看,节约token 和算力。
Hybrid 把两者合起来。 同一个 collection 里,稠密向量(语义,需要 embedding 模型)和 BM25 稀疏向量(词面,内置、文本进稀疏出)各建一个字段;一次查询分别召回,再用 reranker 融合排序,常见 RRF(互惠排序融合)和 Weighted(加权评分)。稠密保证"语义相关的没漏",BM25 保证"关键词精确命中的没跑偏"。这正是 Large Search 区别于"单一向量检索"的地方:真实业务要的既不是纯语义、也不是纯关键词,而是两者融合的结果,并且要在海量数据上又便宜又准地拿到。
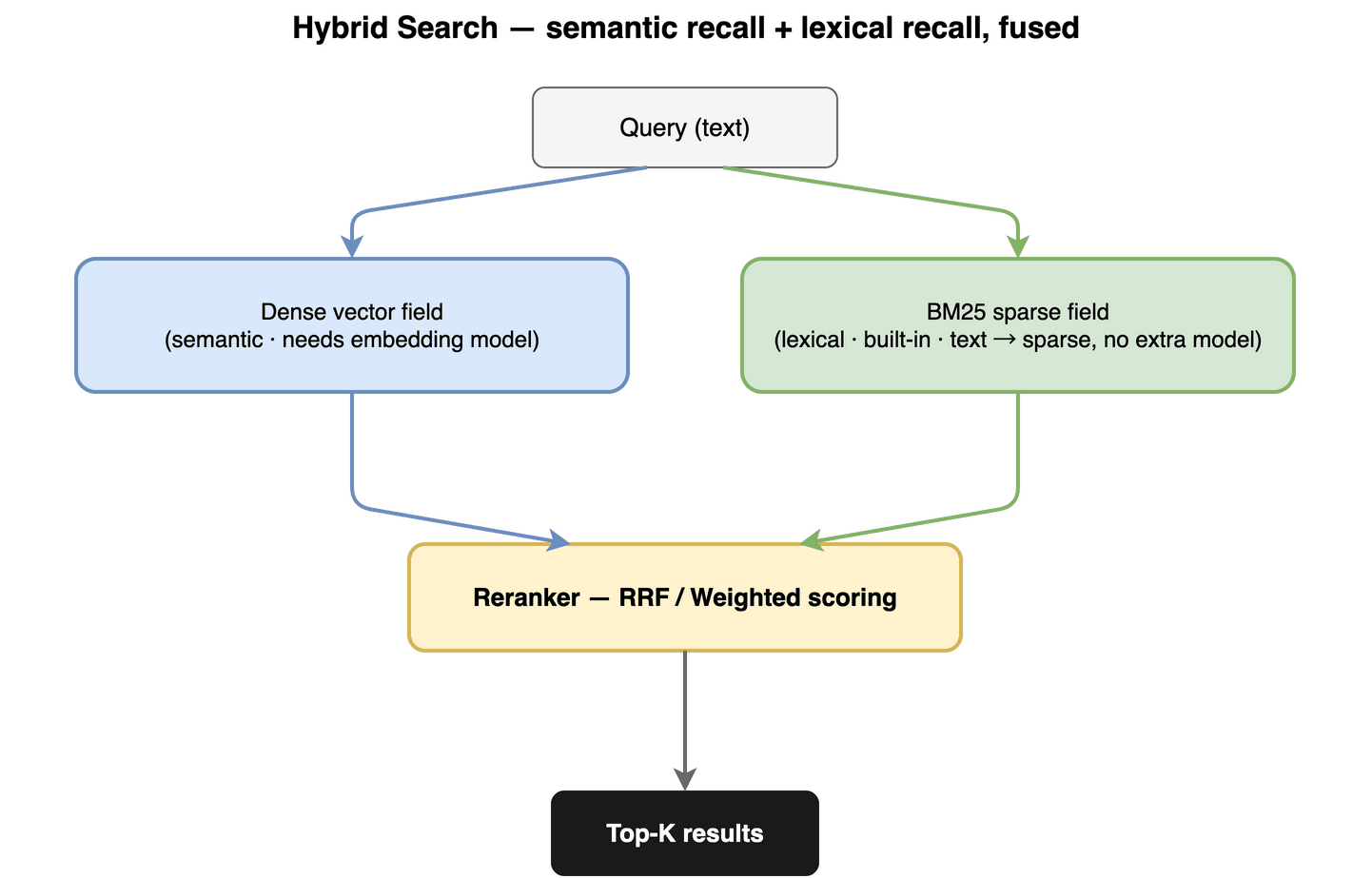
Hybrid Search:稠密向量 + BM25 稀疏,reranker 融合
租户级数据分区
回到多租户型场景(Cursor 那种):上千万个租户,每个数据量不大,但必须互相隔离,又不能为每个租户单独开一个实例——那样成本和运维都撑不住。Milvus 的做法是在一个 collection 内用 Partition Key 承载租户身份,把海量租户的数据分区组织在一起,而不是"一租户一库"。

光分区还不够,关键是让一个租户的查询不被其他租户的数据拖慢。这里有两层优化:
- Clustering compaction(按租户聚簇):把相同 Partition Key 的数据尽量压到更少的 segment 里。查询某个租户时,系统能根据过滤条件直接剪掉大量无关 segment,不必全扫。
- Partition Key Isolation(按租户隔离索引):向量索引内部按租户拆分数据布局,可以按租户加载、按租户构建子图。查询时只在该租户自己的数据上走图,冷加载和热查询都能保持快——哪怕租户数量极大。
在这套机制上,单集群能支撑很大的多租户规模(10 万级 collection、百万级 partition、千万级 segment),并支持按租户删除、租户级权限(RBAC)和租户级统计。这样,"上千万个小宇宙同时在线"才真正落得下来:每个租户逻辑清晰隔离,又共享同一套底层平台,成本可控。

多租户:Partition Key 分区 + Clustering compaction + Partition Key Isolation
一种规格覆盖不了所有大
最后这点是前面内容的落点:Large Search 不是单一 workload,所以底层不能只有一种资源模型。同样是规模问题,有的瓶颈在 QPS,有的在容量,有的在隔离。
- 瓶颈在 QPS 的,加 replica:同一份数据加载到多个查询单元,请求分发过去,QPS 随副本数接近线性增长。
- 瓶颈在容量的,用冷热分层和三级缓存。
- 瓶颈在隔离和成本的,靠数据分区加合适的实例类型。
因此 Zilliz Cloud 提供几种实例形态来匹配:
| 实例形态 | 侧重 | 适用场景 |
|---|---|---|
| Performance | 高 QPS、低延迟 | 在线实时检索 |
| Capacity | 更大数据容量 | 大库,容量优先 |
| Tiered | 冷热分层,容量与成本平衡 | 超大数据、成本敏感 |
| Lakebase | 批量写入 / 跑批,用完回收 | 离线批处理、周期重建索引 |
Lakebase 临时拉起、用完回收,让在线 serving 和离线 batch 的资源彻底解耦,成本才可控。
L 到此为止。接下来两件事:能不能跟着业务自动调整(Scale),以及能不能稳定交付(Serving)。
Scale
实例进入生产后,第一个现实问题是业务一直在变、系统得跟上。我们同事武云峰有一个判断我很认同:scale 是 LSS 的核心竞争力之一,因为它同时关系到两件事——业务峰值能不能扛住,以及成本是否合理。
规模变化有两个方向,对应两种完全不同的动作,两者不能混。
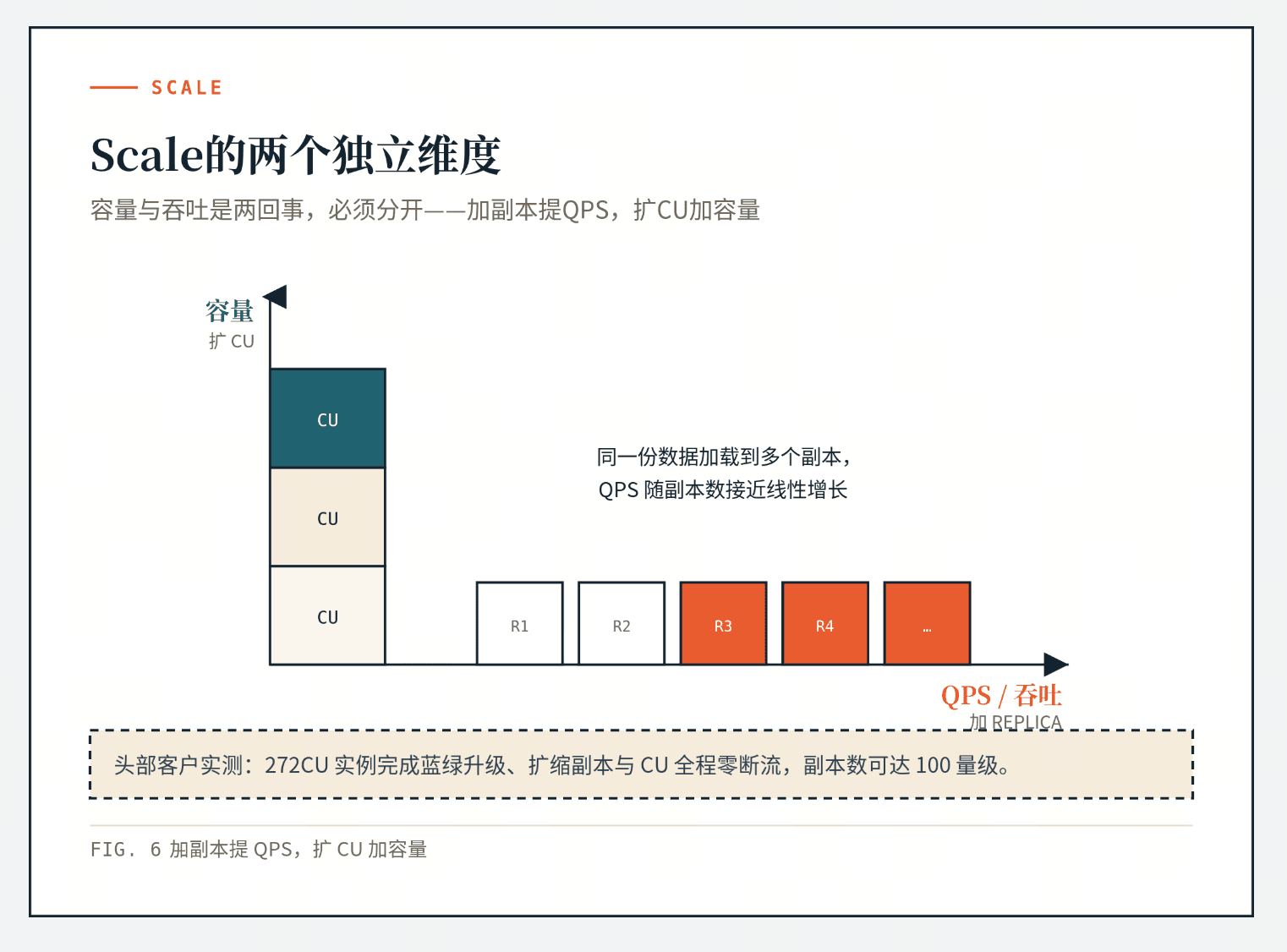
容量扩 CU,QPS 扩 replica
数据涨了,需要的是更多存储、内存、算力,这通过调整 CU 规格来给(CU 是 Zilliz Cloud 的计算单元,可以理解成一份打包好的算力加内存)。规格上去,能装的数据、能加载的索引就上去。
流量涨了、或者延迟无法满足要求,需要的是查询吞吐,这和容量是两回事,通过加 replica 来给。同一份数据由多个副本一起服务,请求分发到不同副本上,QPS 随副本数增长。
这两件事必须分开,我们在做Auto Replica 设计文档的时候就反复强调:加 CU 是为了装更多数据,加 replica 是为了提升 QPS、降低延迟;replica 对 QPS 的提升接近线性;而且高 QPS 场景下加 replica 通常比加 query CU 快,因为加 query CU 往往要触发数据 rebalance 或 rolling upgrade,加副本只是把同一份数据再加载一遍。
这套能力在头部客户上验证过极限:一个 272CU 的实例,我们做过蓝绿升级、扩副本、扩 CU、缩 CU、缩副本,全程业务零断流;副本数已经能做到 100 这个量级。
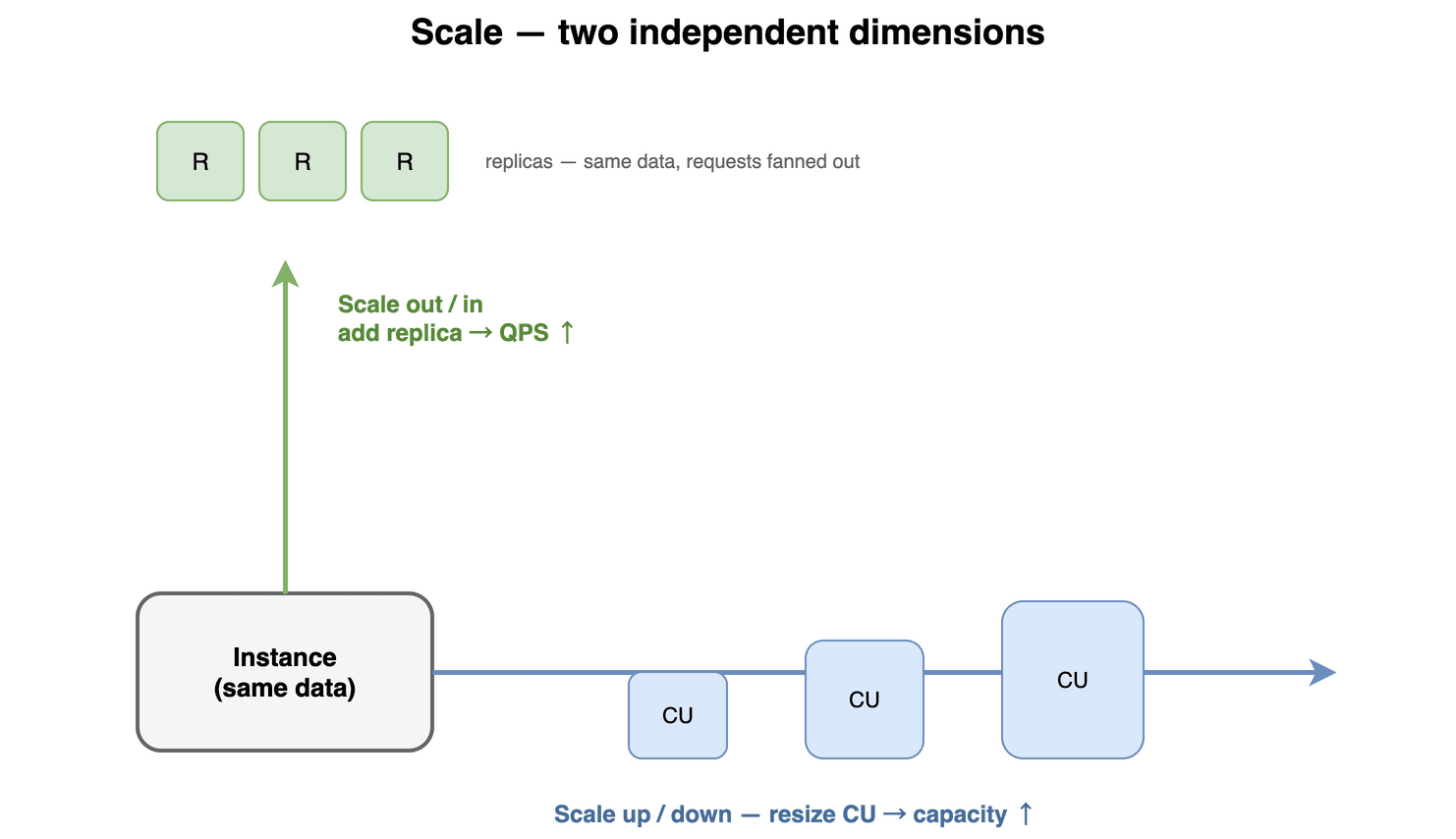
Scale 两个独立维度:加副本提 QPS,扩 CU 加容量
Auto Scale:把判断交给更懂负载的一方
手动扩缩的麻烦在于客户难以判断时机,等发现延迟升高时,业务已经受影响。所以云上把 Scale 做成了 Auto Scale:Zilliz Cloud 监控 CU Capacity、CU Computation、proxy 队列最大等待时间、当前副本数和规格,以及历史使用 pattern,按实时负载自动扩缩——流量来得快就扩得快,负载下来就回收资源、降低成本。
Auto Scale的V2 版本相比早期改了两个关键点:从只能扩容变成也能自动缩容(对Filevine 这类客户流量潮汐明显的客户来说,他们尤其看重缩容带来的成本节省),以及阈值不再由用户自己配置、策略改为平台托管。这件事更适合由云来做,因为提供数据库服务的一方最清楚利用率和扩缩之间的关系。
Target Tracking 是怎么算的
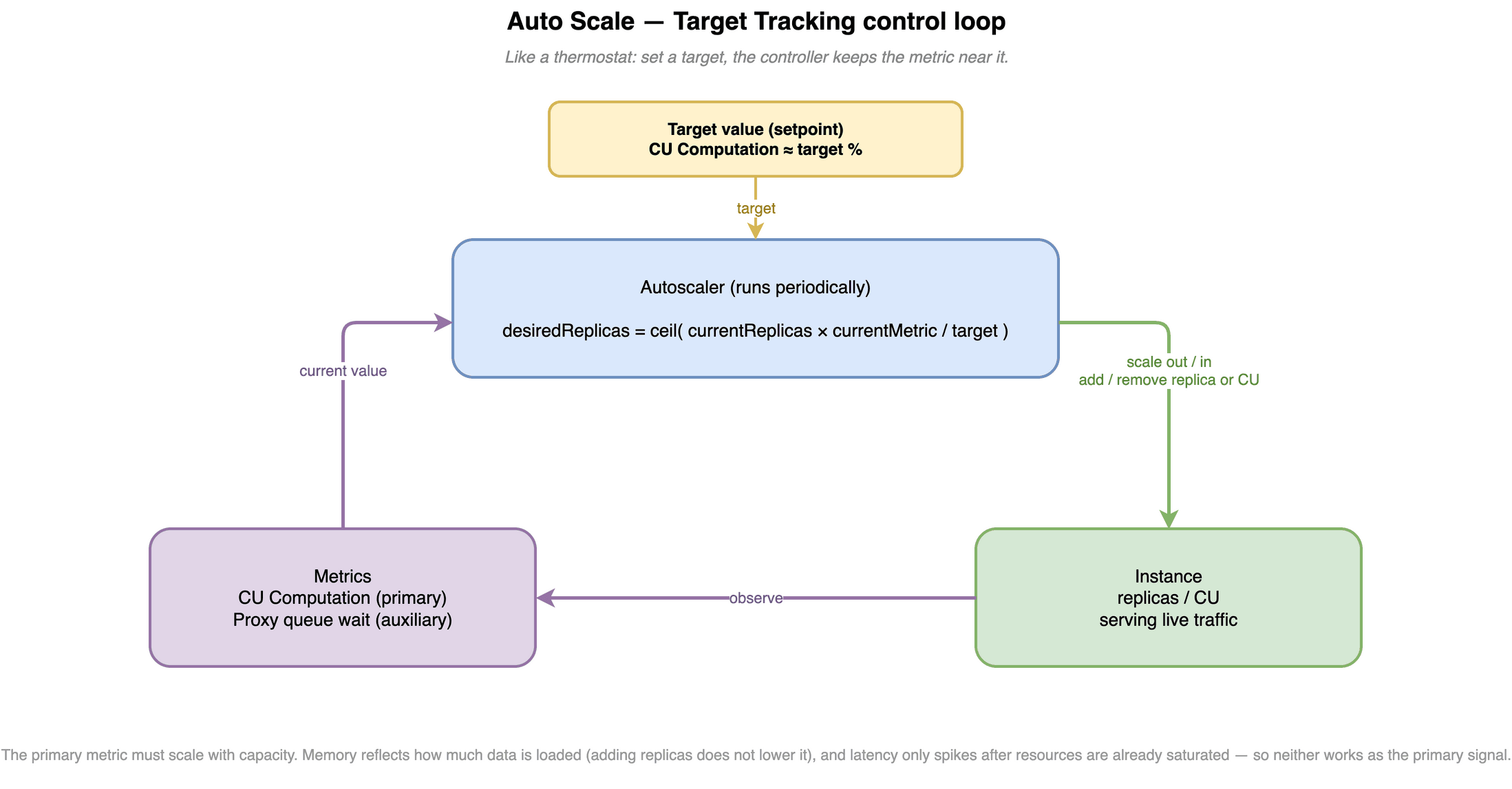
Auto Scale 背后的算法是 Target Tracking,思路并不复杂:选一个关键指标,设一个目标值,autoscaler 不断调整资源,把指标维持在目标附近。
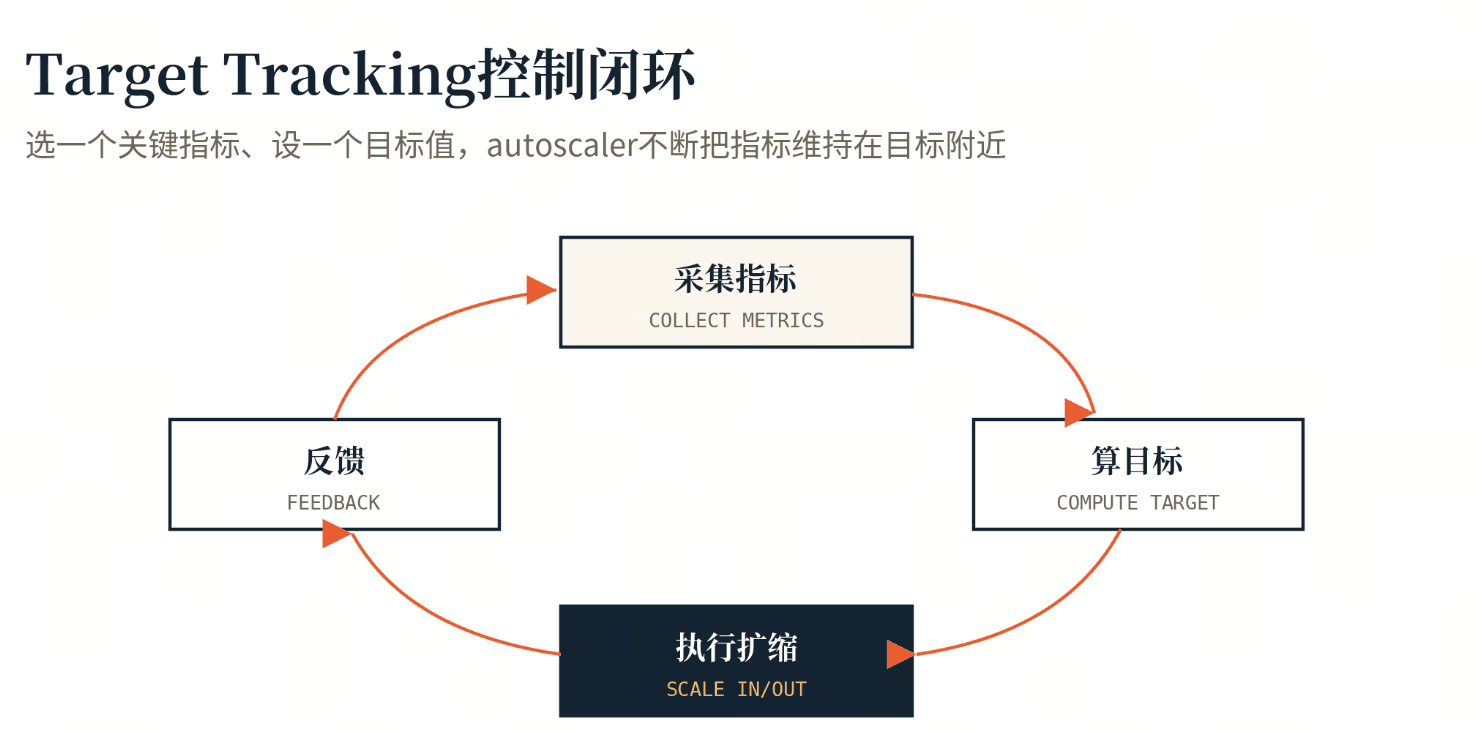
副本数的算法是:
targetReplicas = ceil(currentReplicas * (currentMetricValue / targetMetricValue))
举例,当前 4 个副本,指标 80%,目标 50%:
targetReplicas = ceil(4 * 80 / 50) = 7
扩到 7 个,把指标拉回 50% 附近。
真正讲究的是选哪个指标当 target。这里直接说结论:
| 指标 | 作用 | 说明 |
|---|---|---|
| CPU / CU Computation | 主指标 | 与副本数成比例:加副本后平均 CPU 下降,公式才成立 |
| Memory | 不适合 | 主要反映加载的数据量,加副本不降低单副本负载,不成比例 |
| Latency | 不当主指标 | 资源耗尽后才突然升高,作为触发信号太滞后 |
| proxy 队列等待时间 | 辅助信号 | 超过阈值说明实例已严重过载,需立即扩容 |
| CU Capacity | 需平滑 | 毛刺不能直接触发,避免抖动引发无意义的扩缩 |
Target Tracking 控制闭环:采集指标→算目标→执行扩缩→反馈
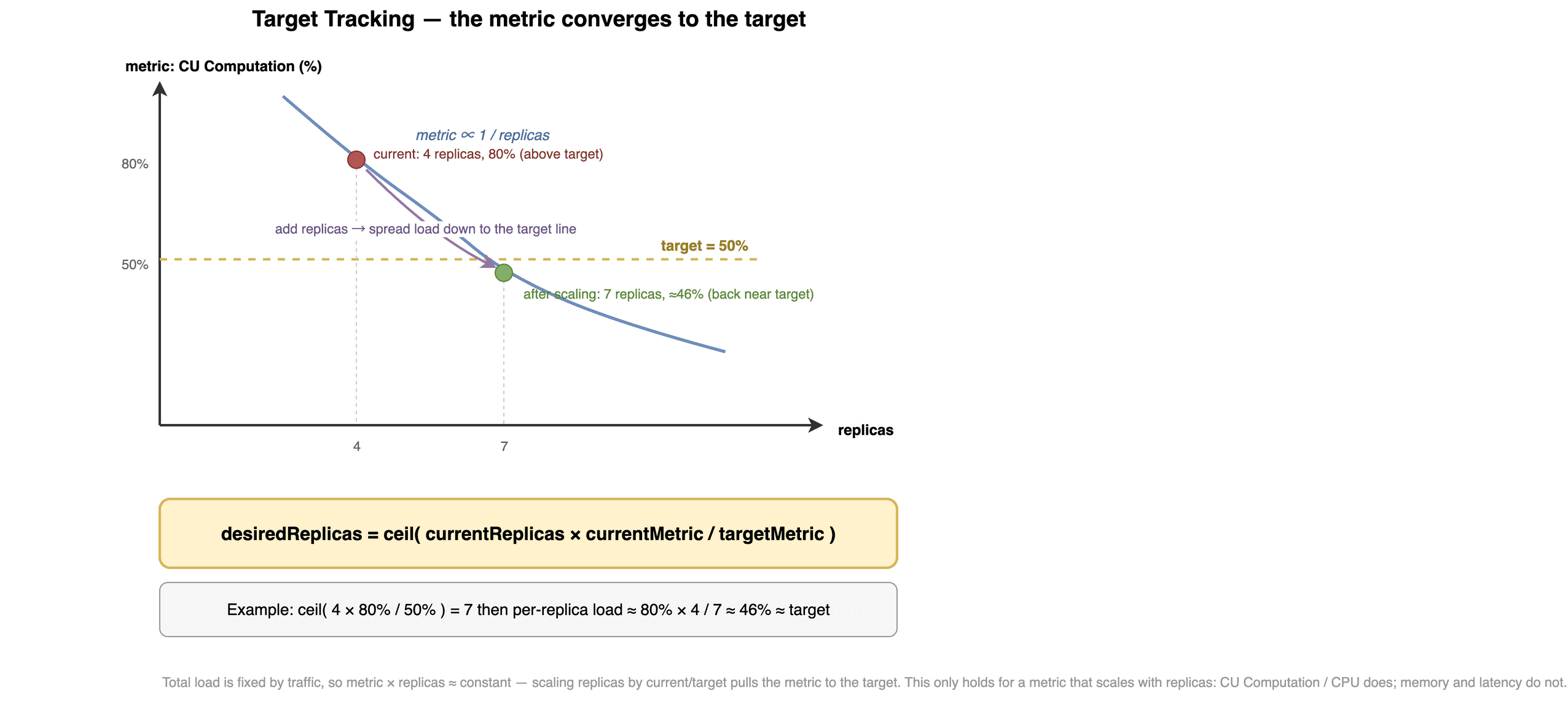
Target Tracking 原理:指标随副本数成反比,加副本把负载摊到目标线
Reactive 与 Time-based 的分工
两种触发方式不冲突,而是分工。Reactive 看实时指标自动反应,适合由云来做,因为云最了解负载。Time-based 由客户自己排计划——客户如果清楚自己的节奏(白天高、夜里低,大促前后,固定时段有批任务),就提前定好何时扩、何时缩。这一类依赖客户对自身业务的了解,更适合交给客户配置。
这两层之上,还可以把策略抽象成三档供客户一键选择:Economy 偏成本、Balanced 居中、Turbo 偏性能。
总之,资源用量不该是客户每天要盯着的事。容量涨就扩规格,流量涨就加副本,其余交给 Target Tracking。
Serving
实例进入生产后,搜索就不再是一个偶尔被查询的引擎,而是客户业务主链路里的核心服务,直接面对 Agent、应用、终端用户和真实流量。Serving 要解决的,就是怎么把它作为这样一个服务长期交付下去,归结起来是三件事:稳、易用、安全。
Stability:稳定,且变更无感、故障能兜
大客户真正关心的不仅仅是系统能不能跑起来,还有两件事:出故障时能不能兜住、数据丢不丢;以及升级、扩缩、变配这些日常动作,会不会让业务有感知。前者靠架构和容灾,后者靠一套"先建后切"的变更机制。
数据不丢、故障能兜
稳定的地基是存算分离。Milvus 把数据和计算彻底拆开:向量、索引、标量数据都持久化在对象存储(S3)上,查询节点只是无状态的计算单元,按需从对象存储加载数据做检索。计算节点崩溃、被替换、被销毁,都不会动到数据本身——数据的唯一真相在对象存储里,节点恢复不过是重新加载一次。所以"数据不丢"是架构层面保证的,不靠运维小心。
在这之上是备份恢复。除了对象存储本身的持久化,Zilliz Cloud 还提供实例级和 collection 级备份,可以手动触发,也可以按策略自动定时——设定频率、时间窗和保留周期,平台按计划自动留存。需要时,既能把整个实例恢复到一个新集群,也能只恢复指定的库或 collection。备份还能跨 Region 复制一份,万一整个区域出问题,数据在异地依然完好、恢复也更快。误删、误改、损坏、升级迁移出意外,都能回到可用状态。
再往上是容灾。同一个 Region 内,副本默认跨多个可用区(AZ)分布,加上数据本就在对象存储上,单个可用区出问题时服务能继续,不会因为一个机房而中断。跨地域这一层由 Global Cluster 承担:支持多地域部署、跨区访问,把服务放到离用户更近的地方,并在区域级故障时具备恢复能力。
这些能力还需要被"看见"才有意义。平台对 Region 级故障做自动检测,并通过 Status 页面主动告知受影响的范围,争取在客户之前发现问题;扩缩、迁移、升级、恢复的每一步也都有指标和快照可查。
升级与变配,用户无感(MBB)
日常运维里最容易伤到业务的,其实是变更本身:版本升级、改规格、扩缩副本。Zilliz Cloud 处理这类变更用的是蓝绿,也就是 MBB(Make-Before-Break)——先建好,再切断。

传统做法是"先拆后建":先停掉旧的、再起新的,中间必然有一段空窗。MBB 反过来——先把一整套新的拉起来、加载好数据、确认就绪,再把流量从旧的切到新的,最后才下线旧的。整个切换过程里新旧两套同时在线,集群容量不下降,流量平滑过渡,业务侧几乎无感。
能做到"先建后切",前提正是前面说的存算分离。因为数据在共享的对象存储上,新起的那套计算可以直接从 S3 加载同一份数据,不必搬运任何数据。如果是存算一体、数据绑在节点本地盘上,就得先把数据搬过去,根本没法先把新的建好——这正是很多系统升级要停服的原因。
无论是版本升级,还是改规格、改副本数的变配,走的都是这一套。所以一个 272CU 的实例,在扩副本、扩缩 CU、蓝绿升级的整个过程中业务零断流;DoorDash 的直连架构迁移、Exa 在全 Region 的灰度推进,也都是在线完成的。这套机制对"在线"有几条硬要求:迁移期间客户的读写和 DDL 照常,元数据在新旧之间保持同步,全程不丢数据,并且一旦出问题可以回滚。
反过来看传统分布式系统的扩容,就知道这条路有多省事:新节点得从现有节点之间 rebalance 数据,这个搬运随数据量增长要花上数小时,期间还会占用、干扰正在服务的节点,涉及的状态多、容易中途失败,一旦中断往往要从头再来——给 Kafka 加一个 broker、给 Elasticsearch 加一个节点,难的正是这件事。存算分离把"节点间搬数据"换成了"从 S3 加载",这才是变更能对用户无感的根本。
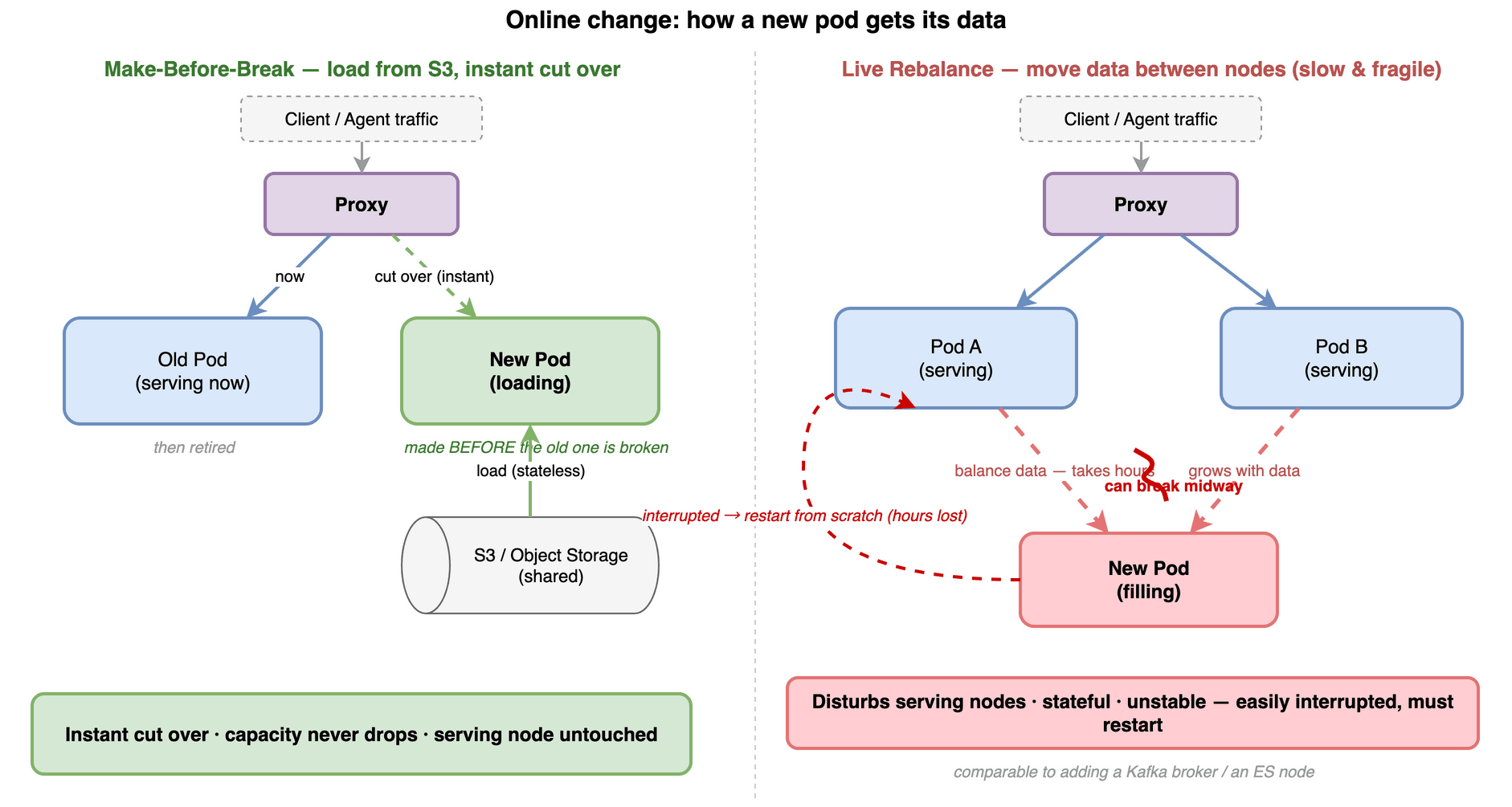
Make-Before-Break(从 S3 加载,切流一瞬间)对比 Live Rebalance(节点间搬数据,耗时且易中断)
Simplicity:复杂度留给平台,简单留给客户
自己跑一套向量检索,要操心的远不止"能不能搜"。开源 Milvus 是个分布式系统,光组件就有 Proxy、Query Node、Data Node、Streaming Node 好几种,背后还挂着消息队列、对象存储、元数据服务这些依赖——任何一处卡顿或抖动都会传导到线上。Zilliz Cloud 是全托管的,把这一整套复杂度挡在了客户视线之外。
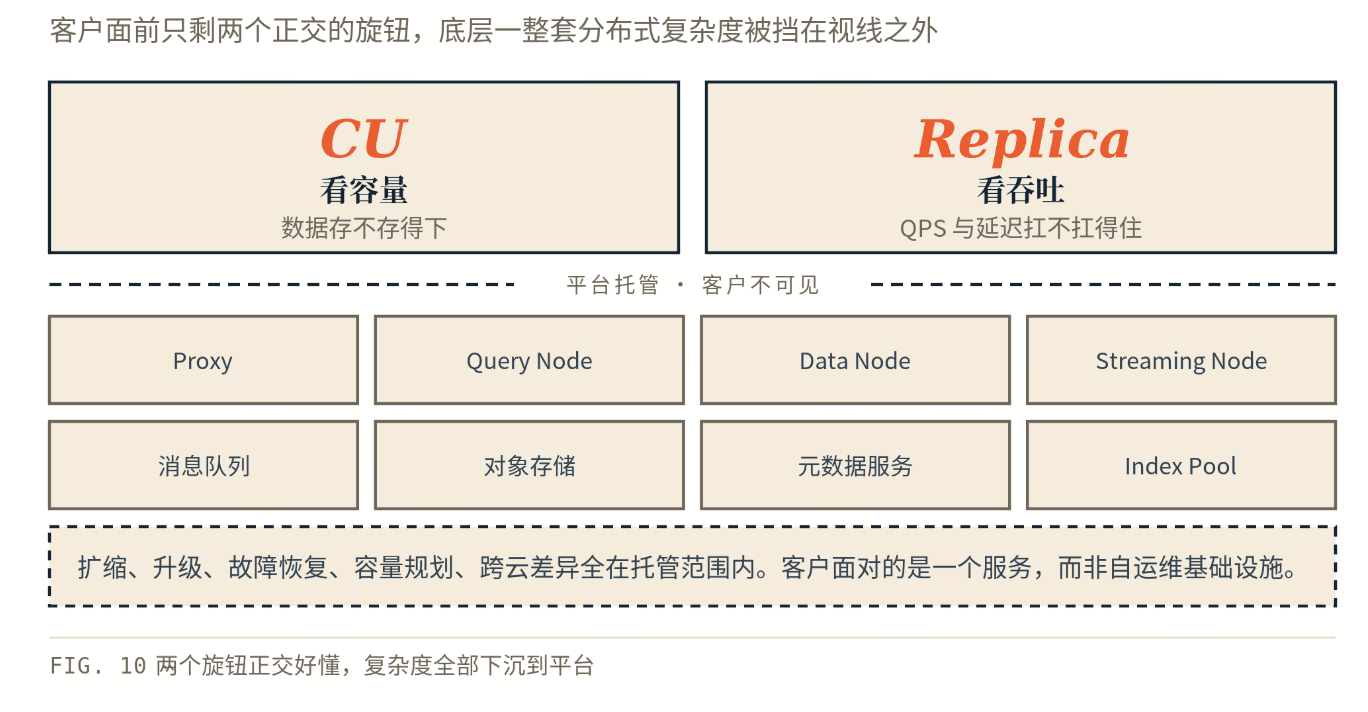
全托管:把系统复杂度挡在外面
- 组件与依赖:Proxy、Query Node、Data Node、Streaming Node,以及它们依赖的消息队列、对象存储、元数据服务,全部由平台部署、调度、监控和兜底。哪个组件该扩、依赖稳不稳,客户都不用管。
- 索引资源(Index Pool):构建索引是另一块容易被忽略的复杂度——它很吃计算、又是阵发的。平台用独立的 Index Pool 来承接:你只管把数据写进来,构建索引要调动多少计算资源、什么时候构建,由平台解决,既不占用、也不干扰你的在线查询资源。
扩缩、升级、故障恢复、容量规划、跨云差异,也都在托管范围内。客户面对的是一个服务,而不是一套要自己运维的基础设施。
一套干净的抽象:你只需要想两件事
正因为底层这些复杂度都被挡住,客户面前只剩两个旋钮,分别对应两个最朴素的业务问题:
- 数据存不存得下 → 看 CU(容量)
- QPS 和延迟扛不扛得住 → 看 Replica(吞吐)
一个管容量、一个管 QPS,正交、好懂。客户不必理解 query node、分片、内存水位、索引加载这些底层概念,只在这两个维度上表达业务需求。
连这两个旋钮都不用自己拧:Auto Scale
再进一步,连"什么时候调、调多少"都交给平台:Auto CU 跟着容量走、Auto Replica 跟着 QPS 走;Reactive 由 Target Tracking 全天候盯实时指标自动扩缩,Time-based 让清楚自己业务节奏的客户提前排期;负载下来自动回收,省成本。背后的算法和指标选择前面 Scale 一节已经讲过,这里不再展开。
在云上,你不用关心任何物理资源,把业务逻辑放心交给平台就行——这就是 Simplicity。
Security:隔离,按需要层层加码
企业级服务的安全,落到实处就是隔离——谁能进来、部署有多独立、数据握在谁手里。Zilliz Cloud 按客户对隔离强度的要求,提供三层,越往下越彻底。
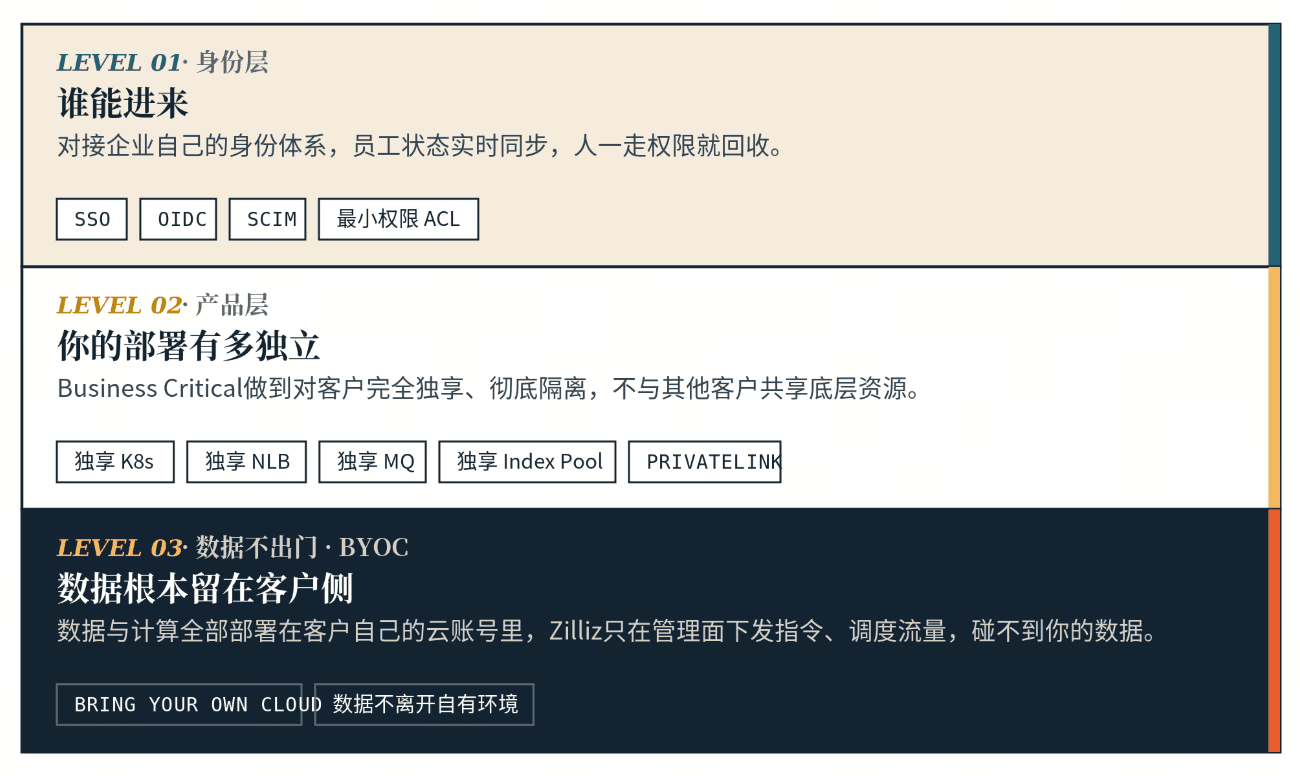
身份层:谁能进来
对接企业自己的身份体系,而不是让客户在外面另维护一套账号。支持 SSO、OIDC 单点登录,用 SCIM 把员工在企业里的状态实时同步过来——入职、离职、角色变更即时生效,人一走权限就回收;再配合基于最小权限的 ACL,把"谁能访问什么"控制到细粒度。
产品层:你的部署有多独立
为企业提供 Enterprise 和 Business Critical 两个专业版本,它们不只是性能档位的差别,安全等级也不同。其中 Business Critical 做到对客户完全独享、彻底隔离:
- 独享 K8s
- 独享网络入口 NLB
- 独享消息队列
- 独享 Index Pool
再加上 PrivateLink 私网接入、流量不经公网。这样你的实例不与任何其他客户共享底层资源,从计算、网络到数据通道都是自己的,互不打扰。
终极层:数据根本不出门(BYOC)
如果连独享都还不够——比如合规要求数据不能离开自己的环境——还有 BYOC(Bring Your Own Cloud):数据和计算资源全部部署在客户自己的云账号里,完全自主可控;Zilliz 只在管理面(control plane)下发指令、调度流量,碰不到你的数据。
从身份,到部署,再到数据彻底留在客户侧,隔离一层比一层深——这就是 Security。

Security:身份 / 部署独享 / BYOC 三级隔离,越往上越彻底
小结
| LSS 的核心判断:AI 时代企业级搜索的竞争力,越来越取决于能否把 Large Search 以可扩展的在线服务方式稳定交付,而不再取决于单点检索算法的优劣。 |
|---|
三个字母各自承担一段。L 面对用户侧多种形态的"大",由 Milvus 通过冷热分层与三级缓存、自研索引、RBQ 调度和租户分区来支撑;Scale 让容量和 QPS 两个维度各自弹性,由 Target Tracking 驱动的 Auto Scale 在性能与成本之间自动平衡;Serving 把这些能力交付成稳定、易用、安全的在线服务,对应武云峰给 LSS 定的 4S 里的 Stability、Simplicity、Security(第一个 S,Scalability,即前面的 Scale)。
这套能力来自 DoorDash、Exa、OpenEvidence、OKX 等客户的真实生产需求,而不是自上而下的架构设计。它最终回到产品最基本的原则:先解决客户最痛的问题,再把每个环节做到极致。
参考资料
ClickHouse: Building a Distributed Cache for S3: https://clickhouse.com/blog/building-a-distributed-cache-for-s3
ClickHouse: No more disks — stateless compute in ClickHouse Cloud: https://clickhouse.com/blog/clickhouse-cloud-stateless-compute
 Bill Chen
Bill Chen