



解码LLM幻觉:深入探究语言模型错误
随着公司和大型科技公司利用大型语言模型(LLMs)创造更好的产品,了解它们在提供可靠解决方案方面的责任变得至关重要。一个重要问题是,这些模型有时会生成自信但错误的信息,导致用户错误地相信输出是准确的。这个问题被称为“幻觉”。
数据科学家Morena在Zilliz主办的最近一次非结构化数据聚会上,就LLM幻觉进行了一次富有洞见的演讲,深入解释了幻觉的概念、幻觉的类型、它们可能造成的危害、产生的原因,以及最重要的是,我们如何检测这些幻觉。
什么是幻觉?
幻觉是由任何形式的语言模型生成的虚假或矛盾的输出。简单来说,就是事实上不正确、荒谬或不符合输入上下文的内容。
例如,让我们向Llama3提出一个复杂的问题:State Software的联合创始人在讨论JSON时还考虑了哪些其他名称?
Llama3的回答如下所示:
Llama3对示例问题的回答
而实际的讨论有些不同:
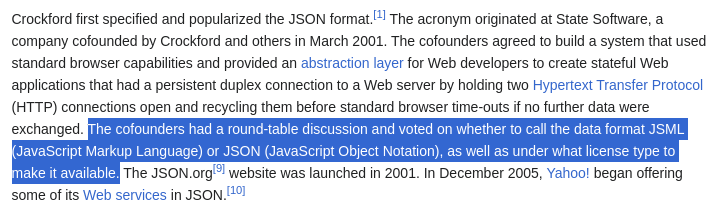 110.1.PNG
110.1.PNG
维基百科页面上关于JSON的答案
Llama 3-8B展示了一个典型的幻觉例子。让我们检查一下语言模型可能给出的不同类型幻觉。
不同类型的幻觉
幻觉主要分为两大类:内在幻觉和外在幻觉。
内在幻觉
内在幻觉倾向于与提供给它们的源信息形成对比。想象一下,你急于解决一个庞大且复杂的理解测试中的问题。你可能会弄错信息,错误地回答一些问题。类似地,当数据高度非结构化时,比如一个广泛的文本语料库,LLMs倾向于频繁产生幻觉。
外在幻觉
当LLMs生成无法根据提供的源数据验证的信息时,就会发生外在幻觉,通常导致编造细节。为了有效管理外在幻觉,提示LLM仅使用给定的信息完成任务。这种方法在检索增强生成(RAG)流程和摘要等任务中特别有益。Laurie Voss在Zilliz非结构化数据聚会上强调了这种做法的重要性,突出了它在保持准确性方面的作用。
下面是一个解决外在幻觉的提示示例。
提示 = f"""只使用提供给您的上下文,而不是任何外部知识,回答用户查询。
上下文:{Wikipedia_Page_Content}
查询:给我总结这一页""" #而不是只是提示 = f"""给我总结这一页
{Wikipedia_Page_Content}"""
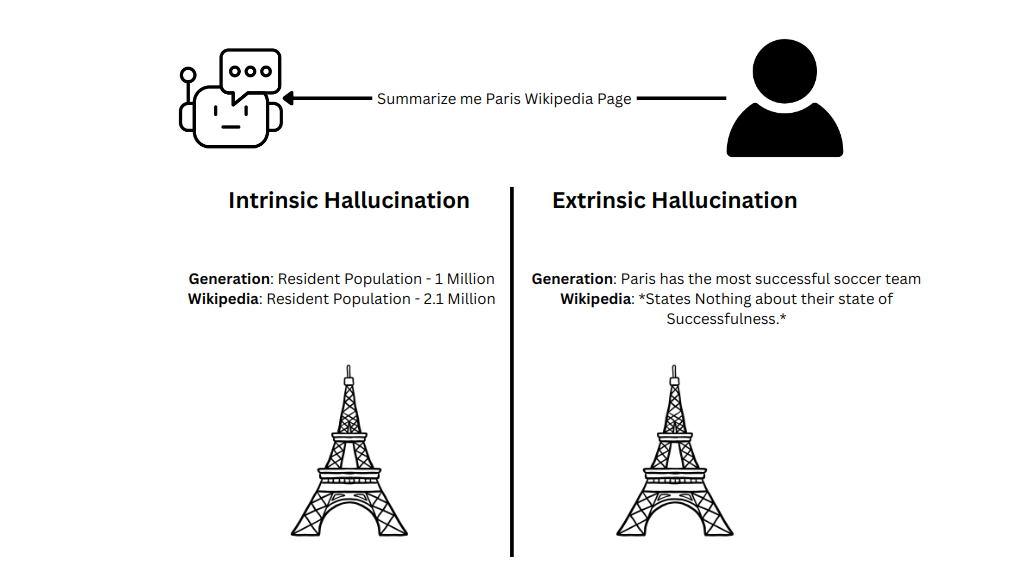 110.3.PNG
110.3.PNG
内在幻觉与外在幻觉的示例
LLM幻觉的问题
最初可能看起来无害甚至有趣的幻觉,在将LLMs部署在法律和医疗保健等行业时,会带来重大挑战。在这些领域,由生成性AI模型生成的信息的准确性对于确保积极结果至关重要。当这些模型产生不准确的输出时,可能会导致严重后果,如错误的法律决定或损害的病人护理,可能危及生命。
此外,除了对特定行业的影响外,LLMs产生的幻觉还可能产生深远的社会影响。它们破坏了对可靠信息来源的信任,并在公众中造成广泛的混乱和不信任。这种信任的侵蚀在选举等关键时刻可能特别有害。
例如,在选举期间,LLMs传播的关于候选人、投票程序或选举结果的错误信息可以显著影响民主进程。虚假信息可能会误导选民关于投票地点和时间,可能抑制选民投票率并影响选举结果。此外,错误信息可能会加剧紧张局势,导致社会动荡甚至暴力,如在选举舞弊的无根据的声称引发抗议和对抗的情况下。
为什么LLMs会产生幻觉?
LLMs缺乏真实概念;它们的输出是由复杂的数学运算决定的,如矩阵乘法和softmax函数,这些函数基于前面的标记为序列中的每个标记计算概率。这些概率决定了LLM生成的序列,但什么影响这些概率呢?
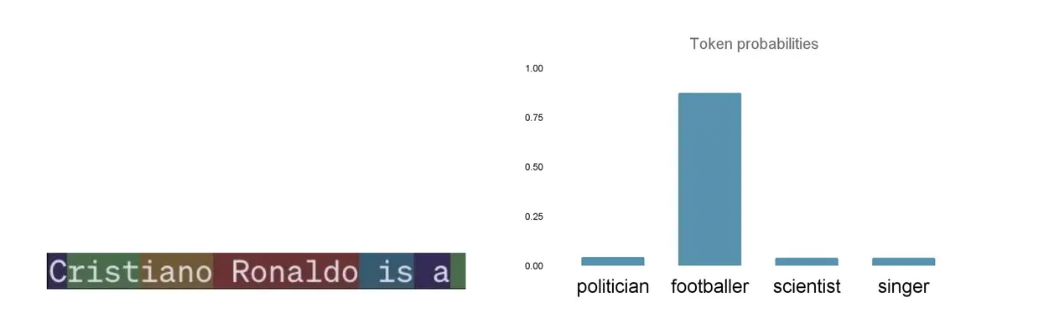 110.4.png
110.4.png
给定字符串的标记概率
训练数据中的矛盾或错误信息
基础模型是在大量非结构化数据上训练的,包括维基百科页面、subreddits、推文、Stack Overflow和MathOverflow线程、GitHub存储库以及许多其他互联网来源。这种训练的目的不是确保模型从一开始就产生有意义的输出;相反,它建立了作为张量存储的基础知识,并生成连贯的输出。
然而,并非所有在互联网上找到的数据都是准确的。特定subreddits或推文中的误导信息和错误信息在训练期间可能会影响模型。这个问题可能导致模型权重的不一致,并导致概率分布的扭曲,最终导致其输出中的幻觉。
任务的复杂性
任务的性质也影响LLM是否容易产生虚假或无意义的输出。像回答简单问题这样的简单任务不太可能导致幻觉。然而,当面对更复杂的任务时,例如总结广泛的文本段落或分析以markdown格式提供的表格数据,LLMs可能会产生高度无意义的输出。
 110.6.png
110.6.png
简单任务与复杂任务
检测幻觉
有几种方法用于检测LLM幻觉:自我评估、基于参考的检测、基于不确定性的检测和基于一致性的检测。让我们详细了解其中一些方法。
 110.7.png
110.7.png
幻觉检测方法
自我评估
自我评估是LLM评估其输出的过程,这可能最初看起来违反直觉,因为幻觉通常源于模型内部。然而,这种方法仍然有价值,因为评估响应的质量本质上比生成响应本身更容易。像回答评估这样的简单任务比生成对复杂查询的响应等更复杂任务更不容易受到幻觉的影响。这是因为LLM衡量响应的正确性和连贯性的能力比其准确生成全新信息的能力要小。
此外,将自我评估与其他检测方法(如基于参考或基于一致性的方法)结合起来,增强了LLM全面评估其输出的能力。这种综合方法加强了模型有效识别和减轻潜在幻觉的能力,从而提高了生成内容的整体可靠性和可信度。
 110.8.png
110.8.png
LLM自我评估的基本工作流程
基于参考的方法
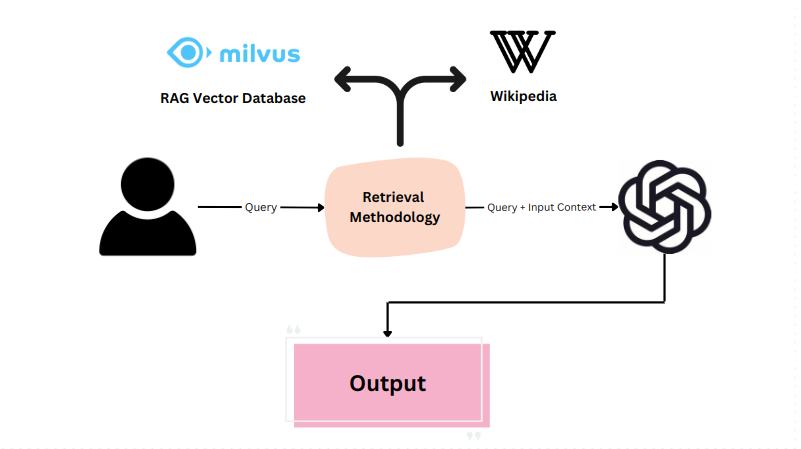
基于参考的方法通过评估生成输出与提供的参考的一致性,这在利用检索增强生成(RAG)和摘要等任务的生产环境中特别有用。
提供源知识作为参考,允许LLM生成与给定参考紧密对齐的输出。考虑总结有关巴黎的维基百科页面的任务。使用基于参考的方法,LLM可以生成与原始内容评估的摘要,以确保准确性和连贯性。
BERTScore或ROUGEScore等性能指标通常用于评估LLM在特定任务上的表现。它们提供了生成输出与参考匹配程度的数量化度量。此外,结合自我评估层进一步提高了基于参考的评估方法的可靠性和有效性。
 110.9.png
110.9.png
基于上下文的检索的系统化工作流程
基于不确定性的方法
记得我们之前观察到LLMs自信地产生错误的输出吗?嗯,在幻觉的情况下,情况并不总是如此。幻觉可能发生在不确定的概率分布中,其中一个标记略高于“最佳”真实标记,导致输出生成错误。
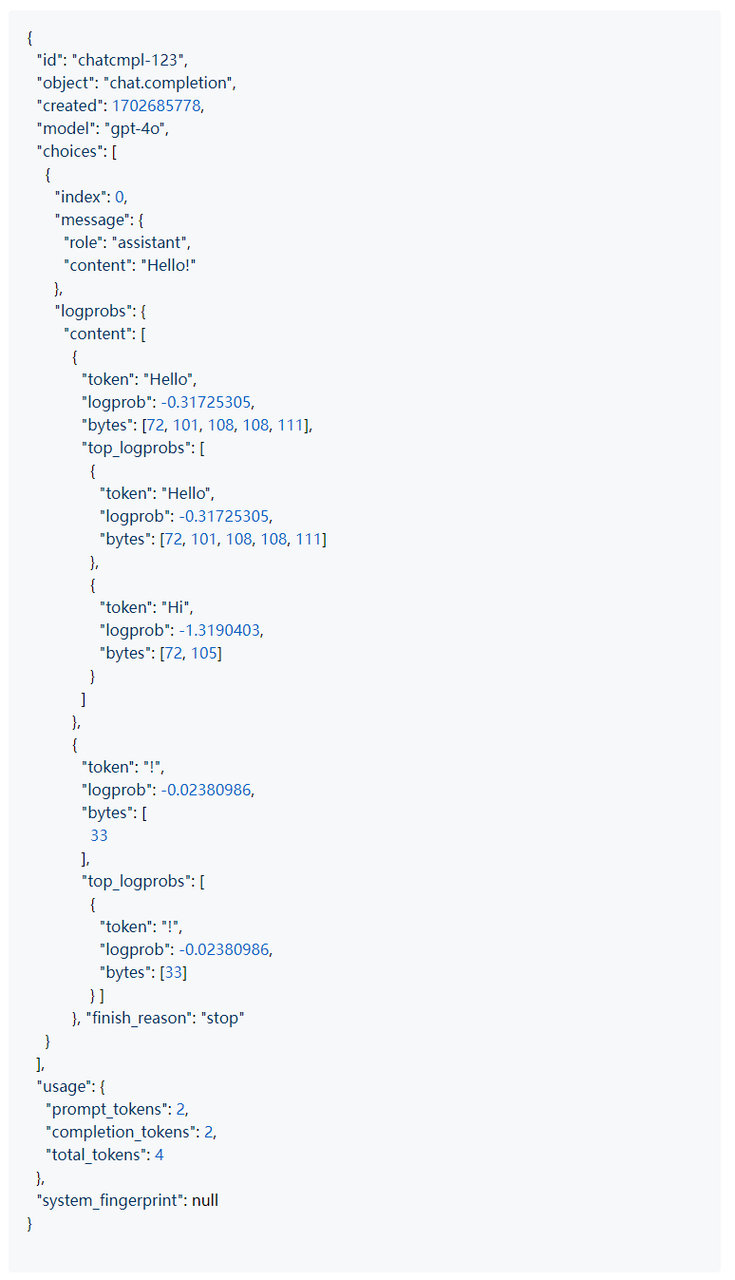
要分析标记概率,您可以利用Hugging Face类方法。这些方法允许您检查与标记生成相关的概率,提供模型如何做出决策的见解,并可能识别出现幻觉的实例。
 110.10.png
110.10.png
您可以使用gpt-4等闭源模型通过logprobs尝试这种方法。
 110.11.PNG
110.11.PNG
logprobs的输出如下JSON所示。
 110.12.png
110.12.png
基于一致性的检测
基于一致性的检测是一种简单但有效的方法,用于识别LLM幻觉。这种方法涉及用相同的问题多次查询LLM并比较其响应。重复查询中一致的输出表明幻觉的可能性较低,而不一致的响应则暗示可能存在问题。
以下是Morena在他的演讲中分享的一个示例,他反复问了LLM三个问题。
ronaldo_prompt = "给我三个关于克里斯蒂亚诺·罗纳尔多的事实。"
toaster_prompt = "给我一个关于烤面包机的荒谬事实。"
seinfeld_prompt = "在《宋飞正传》的哪一集中,克莱默买了一顶巨大的帽子?"
设置提示:
ronaldo\_passages = \[]
for i in range(3):
  prompt = ronaldo\_prompt
  result = chat\_gpt\_prompt(prompt).choices\[0]-message.content
  ronaldo passages.append(result)
toaster\_passages = \[]
for i in range(3):
  prompt = toaster\_prompt
  result = chat\_gpt\_prompt(prompt).choices\[0].message.content
  toaster\_passages.append(result)
seinfeld\_passages = \[]
for i in range(3):
  prompt = seinfeld\_prompt
  result = chat\_gpt\_prompt(prompt).choices\[0].message.content
  seinfeld\_passages.append(result)
在这个例子中,查询关于克里斯蒂亚诺·罗纳尔多的信息,这些信息在LLM训练数据中根深蒂固,往往会得到一致的输出,最小化幻觉风险。这种一致性展示了模型在生成已建立主题的准确响应方面的可靠性。
 110.13.png
110.13.png
LLM生成的关于克里斯蒂亚诺·罗纳尔多的答案
然而,情况对于《宋飞正传》的段落则不同,因为克莱默从未买过“巨大帽子”。
 110.14.png
110.14.png
LLM生成的关于巨大帽子的答案
结论
随着越来越多的企业将大型语言模型(LLMs)用于生产应用,持续解决它们的挑战至关重要。如果未加检查,幻觉可能会变得越来越有害。我们可以通过了解它们的起源、触发因素和检测策略来最小化它们的影响。
本文探讨了幻觉的概念及其潜在触发因素。此外,我们介绍了四种实用的幻觉检测方法:自我评估、基于参考的方法、基于不确定性的方法和基于一致性的检测。这些方法适用于不同的用例,并且可以结合使用以提高幻觉检测的精度。
 Abhiram Sharma
Abhiram SharmaFreelance Technical Writer


