



向量数据库性能测试技巧
随着非结构化数据的持续增长和人工智能(AI)以及大语言模型(LLM)的爆火,向量数据库已成为至关重要的基础设施。在这种趋势下,如何评估并挑选出最适合您的向量数据库呢?本文将深入探讨向量数据库的关键评估指标和性能测试工具。同时,本文还将介绍如何评估向量数据库性能助您做出明智的决策。
了解向量数据库
非结构化数据(如图像、视频、文本和音频等)可以用高维 Embedding 向量来表示。而向量数据库专为管理这些非结构化数据而生。向量数据库与传统关系型数据库之间的主要区别在于:
- 传统数据库处理的是具有固定格式的结构化或半结构化数据,而向量数据库则处理非结构化数据的 Embedding 向量。
- 传统数据库执行精确搜索,而向量数据库则聚焦于使用近似最近邻(ANN)的技术来进行语义相似性搜索。
向量数据库可以有效解决大语言模型(LLM)的“幻觉”(Hallucination)问题,作为检索增强生成(RAG)应用中的向量存储库(Vector Store)。向量数据库也被广泛应用于多种现代化应用中,包括推荐系统、聊天机器人、异常检测系统、语义搜索及视频去重系统等。在选择适合的向量数据库时,您需要考虑具体应用对数据库的特定需求。了解这些需求将帮助您做出做合适的选择。以下是一些常见应用场景的介绍及需求分析:
- 对于产品推荐系统,高性价比至关重要,这有助于在服务数百万用户时降低成本,而高性能(快速查询)则是确保良好用户体验的必要条件。
- 研究人员在进行新药研发时,可能会利用分子搜索的功能。虽然不必追求极致的性能,但查询应当能够在尽可能低的硬件成本下返回最准确的结果。
- 在实时欺诈检测等应用中,一个错误的判断可能带来严重后果,因此需要使用更高成本的硬件(如 GPU/ASIC)来提高性能和准确性。
向量数据库评估指标
在对向量数据库进行评估时,性能、扩展性和功能是三个最关键的考量指标。
性能
性能是评估向量数据库时至关重要的指标。主要的性能指标包括数据插入能力和速度、查询延迟(Latency)和最大吞吐量(QPS)。但是,由于向量数据库执行的是近似搜索而非精确匹配搜索,因此还需要额外关注两个指标:
- 索引构建时间:构建向量索引所需要的时间。
- 召回率(recall):衡量检索准确性的指标。
构建索引需要占用大量计算资源,这就需要我们在查询准确性和效率之间做出权衡。过分重视准确性可能会影响查询速度,反之亦然。
扩展性和功能
扩展性是衡量数据库能否处理快速增长数据量的指标。功能则是评价数据库是否支持如多租、灾难恢复和多索引等企业级功能的能力。
向量数据库性能测试工具
在评估向量数据库的过程中,ANN Benchmark 和 VectorDBBench 是两个常用的性能测试工具。
** ANN Benchmark**
ANN-Benchmark 是一种外部性能测试工具,专门用于评估不同的向量索引算法在真实数据集上的性能。向量索引是向量数据库中资源消耗大的组件,其性能直接影响整个数据库的表现。
下图展示了利用 ANN Benchmark 生成的性能测试结果。该图基于 GIST1M 数据集(含100 万个 960 维向量)测试了各种算法的召回率和 QPS。图中的 x 轴代表召回率,y 轴代表 QPS,展示了各种算法在不同检索准确性上的性能。
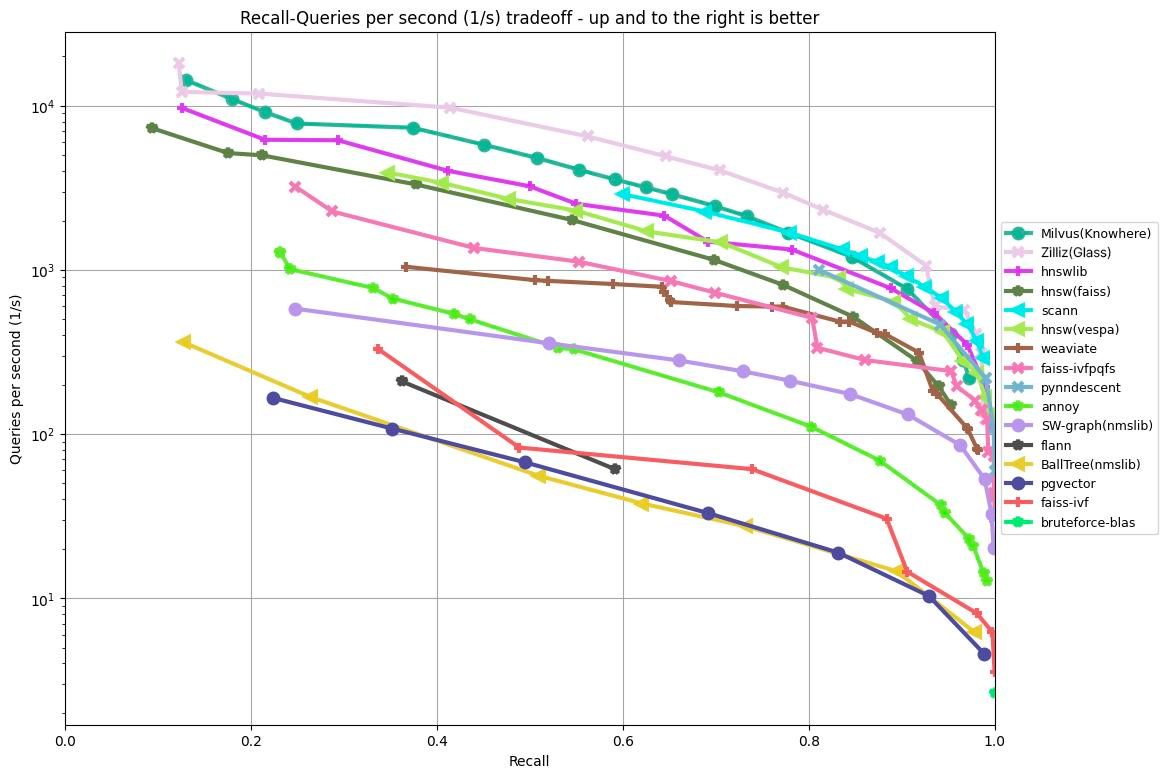 x1.PNG
x1.PNG
VectorDBBench
VectorDBBench 是一个为开源向量数据库(如 Milvus 和 Weaviate)以及全托管向量数据库服务(如 Zilliz Cloud 和 Pinecone)设计的开源性能测试工具。它支持查看向量数据库的 QPS 和召回率。
下图表展示了使用 VectorDBBench 生成的性能测试结果。结果显示了在处理 500,000 个 1,536 维向量时,各种主流向量数据库的 QPS 和召回率。
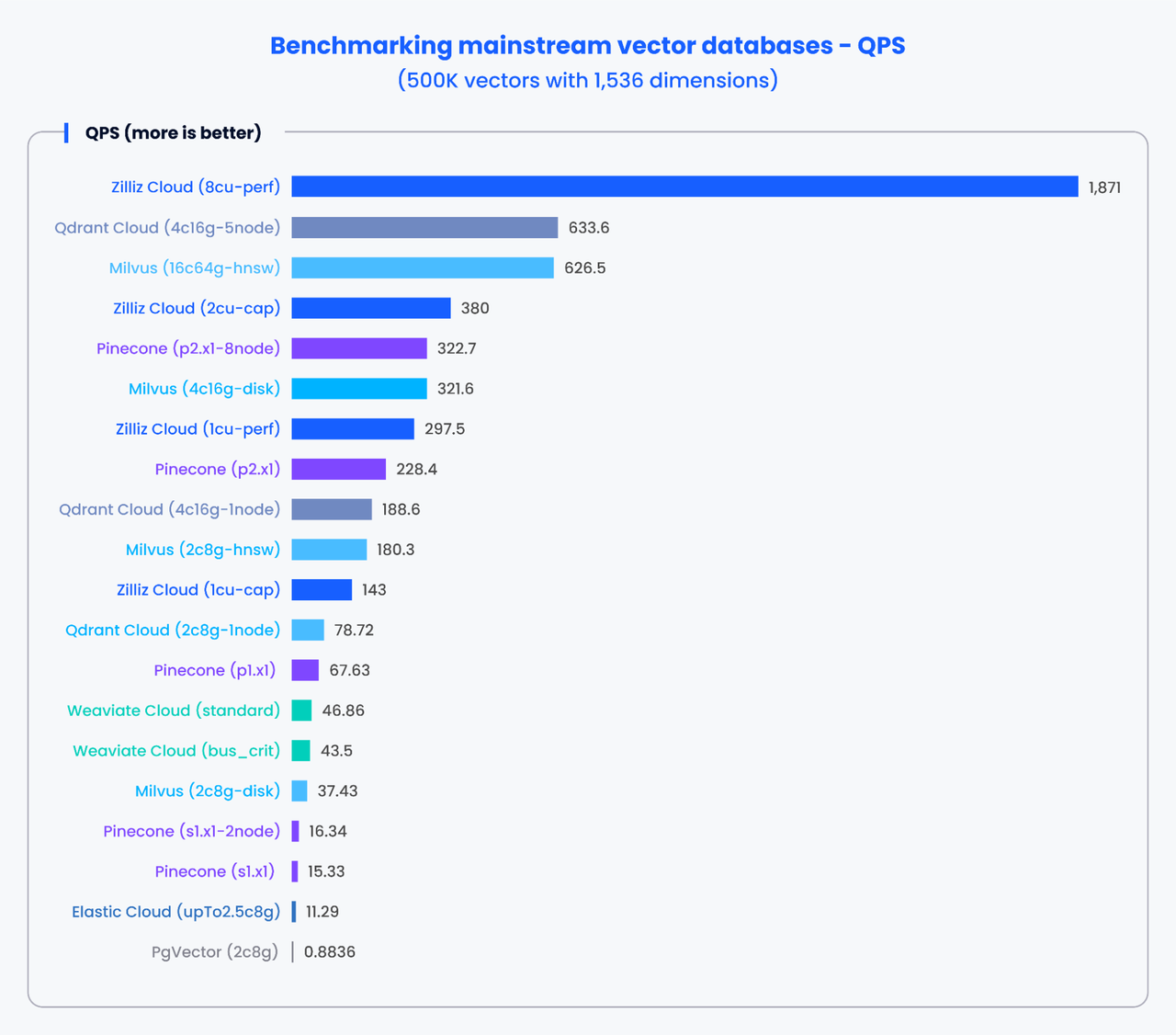 x2.PNG
x2.PNG
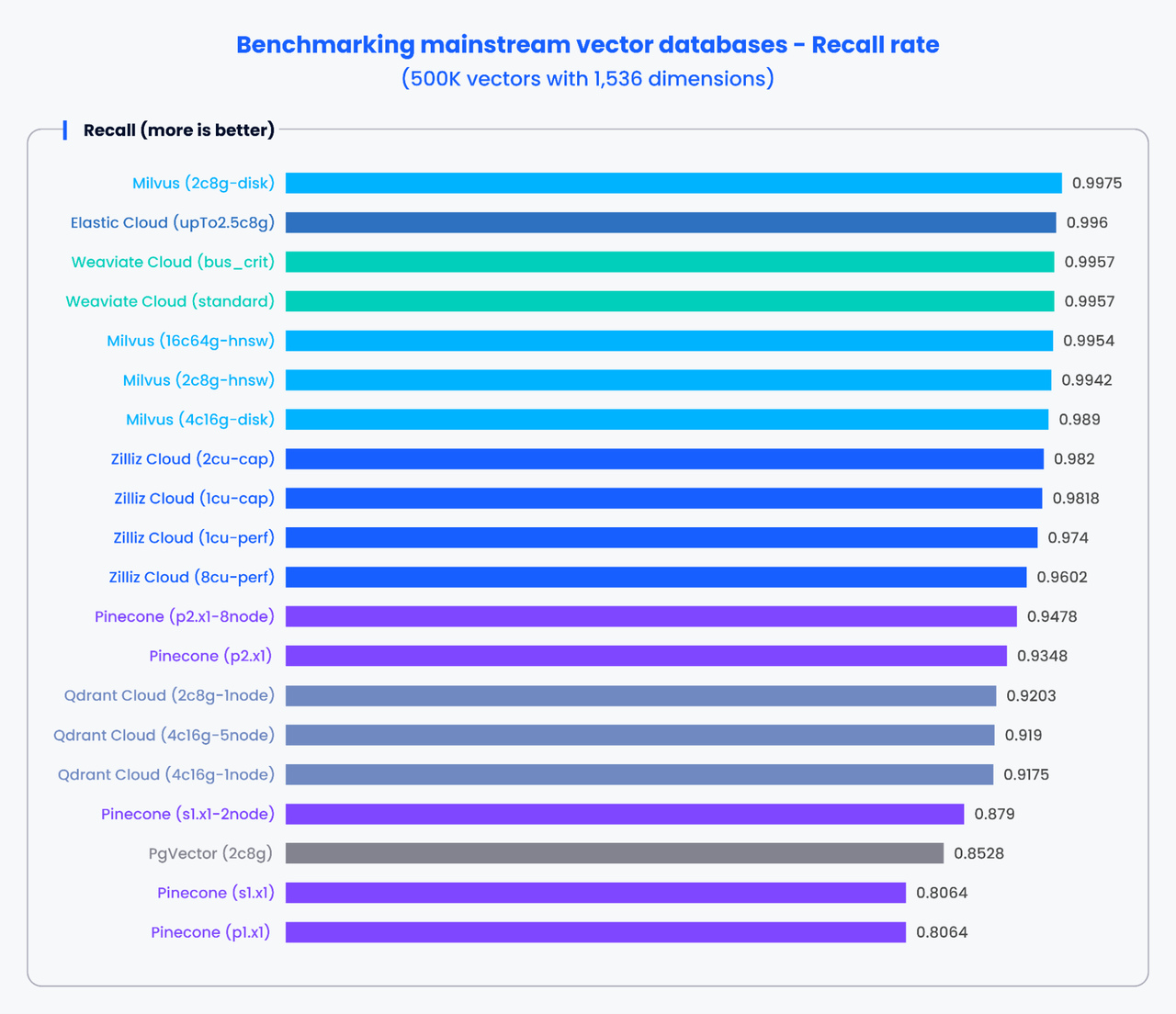 x3.png
x3.png
注意:许多全托管向量搜索服务并不允许用户调整参数,因此 VectorDBBench 分开展示了 QPS 和召回率。
ANN Benchmark vs. VectorDBBench
ANN Benchmark 在评估向量索引算法方面表现出色,有助于选择和比较不同的向量搜索库。然而,它并不适用于评估复杂且成熟的向量数据库系统,也未能涵盖如“向量搜索+条件过滤”这样的情形。
Zilliz 工程师们开发的 VectorDBBench 专为向量数据库全面评估而设计。它关注资源消耗、数据加载能力和系统稳定性等因素。VectorDBBench 能够进行的测试更接近真实世界的生产环境。
性能评估技巧
充分理解性能评估能够帮助我们有效地评估向量数据库的能力。在做出数据库选择时,考虑如何评估插入和查询性能的方法也非常重要。
如何准确评估数据插入性能
要准确评估插入性能,需要检查最大插入容量和插入时间。
为了确定最大插入容量,应使用单一进程按顺序插入小批量数据,直至插入请求被拒绝。这种方法让测试客户端可以批量读取原始数据,从而缓解内存限制并减轻由多重写入过程对数据库造成的压力。这可能会导致过早地限制吞吐量并扭曲最大容量的测试结果。
插入时间应覆盖从开始插入数据集到可以进行有效查询。构建向量索引需要消耗大量的计算资源,这意味着数据插入完成与数据库准备好进行高效查询之间会有时间间隔。如果仅跟踪写入请求所用的时间,可能会因为数据库采取积极的插入策略而延后索引构建,从而出现误导性结果。
如何准确评估查询性能
评估向量数据库的查询性能通常包括三个关键指标:Latency、QPS 和 Recall。
Latency 测试用于测量在串行测试条件下单一查询所需的时间。常用的一个指标是 P99 Latency,它表示99%的查询在该时间内完成。这个指标比平均 Latency提供了更更多参考价值,因为这个指标与用户体验更相关。
需要注意的是:尽管 Latency 测试相对简单,但它受到网络状况的影响极大,尤其是那些通过公共网络访问的云产品。
QPS 表示数据库在高并发条件下的查询处理能力。具体测试包含测试客户端同时发送多条请求来最大化数据库的 CPU 使用率并观察吞吐量。不同于 Latency,QPS 对网络波动的敏感性较低,为评估向量数据库的实际性能提供了全面的视角。
虽然评估向量数据库的 Recall 的方式直观简单,但仅依赖 Recall 来评估查询性能远远不够,需要结合其他指标。
数据集对性能的影响
在真实测试场景中,不同向量数据库在面对多样化数据集时表现出显著的性能差异。较大的数据集对向量数据库的分布式架构构成了较大挑战,这通常会导致性能降低。测试数据集的维度和分布同样深刻影响测试结果。
因此,通过使用具有不同数据大小、维度和分布的测试数据集来评估向量数据库,可以获得更精确和全面的测试结果。
总结
本文探讨了向量数据库及其性能评估技巧,特别强调了如插入容量和查询 Latency 等关键性能指标。我们介绍了 ANN Benchmark 和 VectorDBBench,并展示了它们在评估向量索引算法和专门数据库方面可提供的价值。希望本文能够帮助您做出明智的选择。

keepReading

LLMs 诸神之战:LangChain ,以【奥德赛】之名
毫无疑问,大语言模型(LLM)掀起了新一轮的技术浪潮,成为全球各科技公司争相布局的领域。诚然,技术浪潮源起于 ChatGPT,不过要提及 LLMs 的技术发展的高潮,谷歌、微软等巨头在其中的作用不可忽视,它们早早地踏入 AI 的技术角斗场中,频频出招,势要在战斗中一争高下,摘取搜索之王的桂冠。而这场大规模的 AI 之战恰好为 LLMs 技术突破奏响了序曲。LangChain 的加入则成为此番技术演进的新高潮点,它凭借其开源特性及强大的包容性,成为 LLMs 当之无愧的【奥德赛】。

一次解决三大成本问题,升级后的 Zilliz Cloud 如何造福 AIGC 开发者?
对于应用开发而言,成本问题向来是企业和开发者关注的重点,更迭迅速、变化莫测的 AIGC 时代更是如此。这里的成本既指软件开发成本,也包括硬件成本、维护成本。Zilliz Cloud 可以一次性解决这三大问题,帮助开发者降低开发成本、优化硬件成本、减少维护成本。

Milvus Lite 已交卷!轻量版 Milvus,主打就是一个轻便、无负担
总体而言,无论用户是何种身份(研究人员、开发者或者数据科学家),Milvus Lite 都是一个不错的选择,尤其对于那些想要在受限的环境中使用 Milvus 功能的用户而言,更是如此。