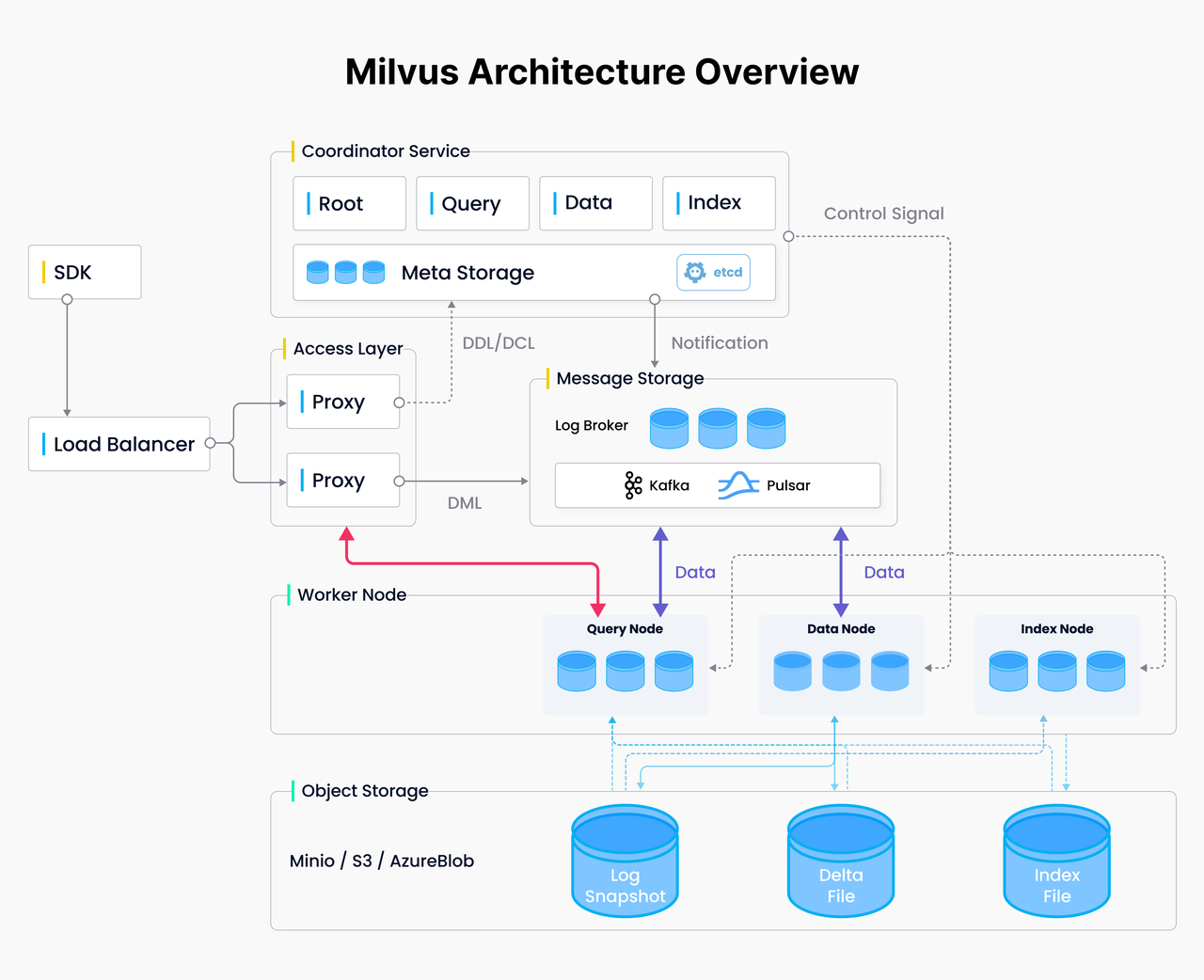
书接上回,如何用 LlamaIndex 搭建聊天机器人?
LlamaIndex 是领先的开源数据检索框架,能够在各种应用中发挥优势,其中一个典型的应用就是在企业内部搭建聊天机器人。
对于企业而言,随着文档数量不断增多,文档管理会变得愈发困难。因此,许多企业会基于内部知识库搭建聊天机器人。在搭建过程中,需要关注三个要点:如何切割数据、保存哪些元数据以及如何路由查询。
01.为什么要用 LlamaIndex 搭建聊天机器人?
在上一篇文章中,我们使用 Zilliz Cloud(全托管的 Milvus 云服务)搭建了一个最基本的检索增强生成(RAG)(https://zilliz.com/use-cases/llm-retrieval-augmented-generation)聊天机器人。在本教程中我们可以继续使用 Zilliz Cloud 免费版,大家也可以使用自己的 Milvus(https://milvus.io/) 实例,在 notebook 中快速启动并使用 Milvus Lite(https://milvus.io/docs/milvus_lite.md)。
上一篇文章中我们将文章进行切割,获取许多小的文本块。当输入问题“什么是大型语言模型?”进行简单的检索时,得到的返还文本块在语义上与问题相似,但并没有得到问题的答案。因此,在本项目中,我们使用同样的向量数据库作为后端,但使用不同的检索过程来进一步获得更好的问答结果。在项目中,我们将使用 LlamaIndex 来实现高效的检索。
LlamaIndex(https://zilliz.com/product/integrations/Llamaindex)是一个框架,可以帮助我们在大型语言模型之上处理数据。LlamaIndex 提供的一个主要抽象是“索引”。索引是数据分布的模型。在此基础上,LlamaIndex 还提供了将这些索引转化为查询引擎的能力,查询引擎利用大型语言模型和 embedding 模型来组织高效的查询并检索相关结果。
02.LlamaIndex 和 Milvus 对于 Chat Towards Data Science 的作用
那么,LlamaIndex 是如何帮助我们协调数据检索?Milvus 又如何帮助搭建聊天机器人的呢?我们可以用 Milvus 作为后端,用于 LlamaIndex 的持久性向量存储(persistent vector store)。使用 Milvus 或 Zilliz Cloud 实例后,可以从一个 Python 原生且没有协调的应用程序转换到由 LlamaIndex 驱动的检索应用程序。
设置 notebook,使用 Zilliz 和 LlamaIndex
正如之前文章所提到的,对于这一系列的项目 Chat Towards Data Science |如何用个人数据知识库构建 RAG 聊天机器人?(上),我们选择 Zilliz Cloud。连接到 Zilliz Cloud 和连接到 Milvus 的步骤基本上完全相同。关于如何连接到 Milvus 并将 Milvus 作为本地向量存储,可参见示例比较向量 embedding。
在 notebook 中我们需要安装三个库,通过 pip install llama-index python-dotenv openai来安装,使用python-dotenv管理环境变量。
获取导入后,需要用load_dotenv()加载.env文件。这个项目需要的三个环境变量是 OpenAI API key、Zilliz Cloud 集群的URI 以及 Zilliz Cloud 集群的 token。
! pip install llama-index python-dotenv openai
import osfrom dotenv import load_dotenv
import openai
load_dotenv()
openai.api_key = os.getenv("OPENAI_API_KEY")
zilliz_uri = os.getenv("ZILLIZ_URI")
zilliz_token = os.getenv("ZILLIZ_TOKEN")
将现有的 Collection 带入 LlamaIndex
将现有的 collection 带入 LlamaIndex 这一步骤中有些小挑战。LlamaIndex 有其自己创建和访问向量数据库 collection 的结构,但是此处不直接使用。原生的 LlamaIndex 向量存储接口和带入自己的模型之间的主要区别是 embedding 向量和元数据的访问方式。为了实现本教程,我还写了一些代码并贡献到了 LlamaIndex (https://github.com/run-llama/llama_index/commit/78ed06c95313e933cc255ac17bcd592e3f4b2be1)项目中!
LlamaIndex 默认使用 OpenAI 的 embedding,但我们使用 HuggingFace 模型生成了 embedding。因此,必须传入正确的 embedding 模型。此外,本次使用了一个不同的字段来存储文本,我们使用 “paragraph”,而 LlamaIndex 默认使用“_node_content”。
这一部分需要从 LlamaIndex 导入四个模块。首先,需要 MilvusVectorStore 来使用 Milvus 与 LlamaIndex。我们还需要VectorStoreIndex模块来用 Milvus 作为向量存储索引,用 ServiceContext 模块来传入我们想要使用的服务。最后导入HuggingFaceEmbedding模块,这样就可以使用来自 Hugging Face 的开源 embedding 模型了。
至于获取embedding模型,我们只需要声明一个 HuggingFaceEmbedding 对象并传入模型名称。本教程中使用的是 MiniLM L12 模型。接下来,创建一个 ServiceContext 对象,以便可以传递 embedding 模型。
from llama_index.vector_stores import MilvusVectorStore
from llama_index import VectorStoreIndex, ServiceContext
from llama_index.embeddings import HuggingFaceEmbedding
embed_model = HuggingFaceEmbedding(model_name="sentence-transformers/all-MiniLM-L12-v2")
service_context = ServiceContext.from_defaults(embed_model=embed_model)
当然,我们还需要连接到 Milvus 向量存储。这一步我们传递 5 个参数:我们的 Collection 的 URI、访问我们的 Collection 的 token、使用的 Collection 名称(默认是“Llamalection”)、使用的相似度类型,以及对应于哪个元数据字段存储文本的 key。
vdb = MilvusVectorStore(
uri = zilliz_uri,
token = zilliz_token,
collection_name = "tds_articles",
similarity_metric = "L2",
text_key="paragraph"
)
使用 LlamaIndex 查询 Milvus Collection
现在,我们已经连接至现有的 Milvus Collection 并拉取了需要的模型,接下来讲讲如何进行查询。
首先,创建一个 ServiceContext 对象,以便可以传递 Milvus 向量数据库。然后,将 Milvus Collection 转化为向量存储索引。这也是通过上面创建的 ServiceContext 对象传入 embedding 模型的地方。
有了一个初始化的向量存储索引对象后,只需要调用as_query_engine()函数将其转化为查询引擎。本教程中,通过使用与之前相同的问题 “什么是大型语言模型?”来比较直接的语义搜索和使用 LlamaIndex 查询引擎的区别。
vector_index = VectorStoreIndex.from_vector_store(vector_store=vdb, service_context=service_context)
query_engine = vector_index.as_query_engine()
response = query_engine.query("What is a large language model?")
为了使输出更易于阅读,我导入了pprint并用它来打印响应。
from pprint import pprint
pprint(response)
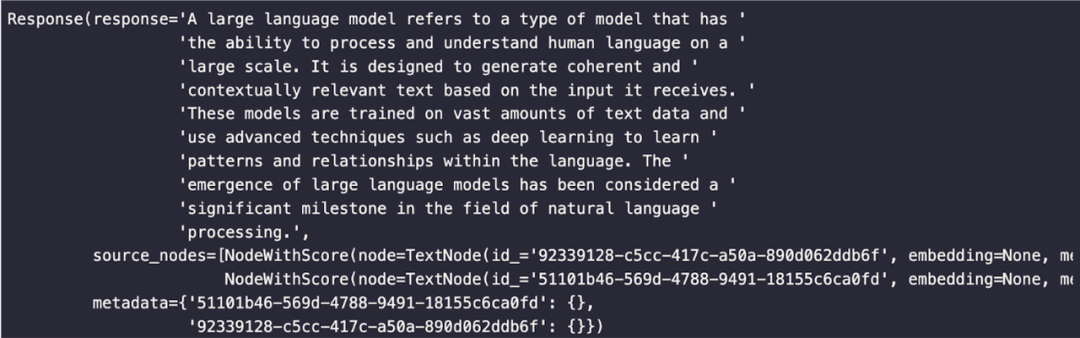
下方是我们使用 LlamaIndex 进行检索得到的响应,这比简单的语义搜索得到的结果要好得多:
03.总结
本次,我们使用了 LlamaIndex 和现有的 Milvus Collection 来改进上一篇文章中搭建的聊天机器人。上一个版本使用了简单的语义相似性通过向量搜索来寻找答案,但结果并不是很好。相较之下,用 LlamaIndex 搭建查询引擎返回的结果更好。
本项目最大的挑战是如何带入已有的 Milvus Collection。现有的 Collection 并没有使用 embedding 向量维度的默认值,也没有使用用于存储文本的元数据字段的默认值。这两点的解决方案是通过 ServiceContext 传递特定的 embedding 模型和在创建 Milvus Vector Store 对象时定义正确的文本字段。
创建向量存储对象后,使用 Hugging Face embedding 将其转化为索引,然后将该索引转化为查询引擎。查询引擎利用 LLM 来理解问题、收集响应和返回更好的响应。