



观点|从Deepseek-R1看2025模型的未来
年初以来,DeepSeek 的爆火引发了行业震动,各大模型厂商纷纷预告下一代大模型的研发计划,包括 OpenAI的 GPT-4.5和 GPT-5、Anthropic 的 Claude 4,以及国内众多 AI 公司也开始重新聚焦技术研发。本篇短文将探讨几个值得关注的赛道,看看今年是否会迎来技术落地。
01
COT模型的演进:探索Latent Space推理
当前,OpenAI 的 O1 系列模型和 DeepSeek R1 的核心能力依赖于基于文本交互的思维链(Chain-of-Thought, CoT)推理范式。这一范式推动了 Scaling Law 的新发展方向,特别是基于强化学习(RL)的 Scaling Law 以及推理时间(Test-Time)的 Scaling Law。对此,俊林老师在《S 型智能增长曲线:从 DeepSeek R1 看 Scaling Law 的未来》一文中提出的观点——Scaling Law 呈现 S 形曲线,并且多种Scaling law可以叠加,非常有新意,值得大家关注细细品味。
然而,一个核心问题是:推理的本质究竟是什么?
传统 CoT 依赖文本上下文,具备良好的可解释性,但 DeepSeek R1-zero 模型证明了监督微调(SFT)并非必需。尽管 R1-zero 的可解释性有所下降,但它能够自主生成 DSL(领域专用语言)完成推理。这引发了一个新的思考:推理是否必须依赖人类可理解的文本?文本交互是否是必要的?
事实上,大模型的推理过程完全可以在潜在空间(latent space) 中进行,即通过向量表示进行信息传递。这种方法可以解决以下关键问题:
1.减少文字生成的计算开销 —— 传统 CoT 需要生成可读文本,导致额外的算力消耗,而潜在空间推理可直接在隐藏状态中完成计算;
2.自适应计算资源分配 —— 传统 CoT 所有 token 被分配相同算力,未能区分语义重要性,而潜在空间推理可动态调整计算资源,关注关键部分;
3.并行推理与剪枝 —— CoT 采用线性推理路径,一旦出错难以纠正,而潜在空间推理可以并行探索多个可能路径,并逐步剪枝错误选项,提高推理的鲁棒性。
如果对这一方向感兴趣,推荐阅读 Meta 论文 "Training Large Language Models to Reason in a Continuous Latent Space",该研究探讨了如何在潜在空间中优化推理能力,摆脱文本交互的限制,以提升推理效率与泛化能力。
02
Test-Time 记忆范式与外部知识增强
“学而不思则罔,思而不学则殆。” ——《论语》
尽管增加推理时间可以提升模型的表现,但如果无法有效利用外部知识、合理剪枝计算,并优化记忆管理与推理状态维护,模型可能陷入无效循环,徒然消耗算力。因此,如何在测试时设计更高效的推理方式,成为未来模型优化的关键方向。
传统方法的挑战
循环神经网络(RNN) :依赖向量传递上下文,但受限于固定大小的隐藏状态,难以存储长期依赖信息。
注意力机制(Attention): 可捕捉完整的上下文关系,但计算复杂度为 二次方,使得模型的有效记忆受限于固定上下文窗口。
未来优化方向可能有两个重要突破口:
1.引入遗忘与压缩机制,降低长上下文注意力计算成本
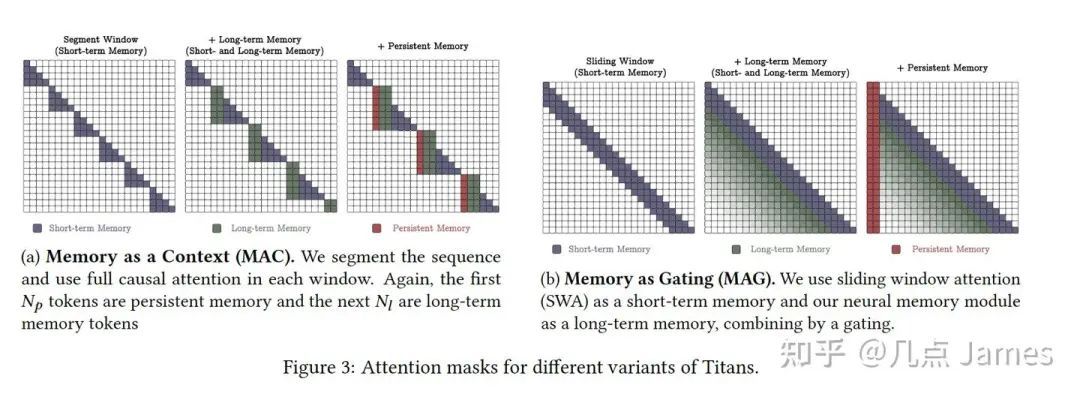
Google Titans 论文针对高效长序列建模进行了深入研究,提出了一种能在减少计算开销的同时保持信息完整性的方法。其核心机制包括:
三种不同的内存类型:
短期记忆(Short-Term Memory, STM): 负责处理当前的上下文信息。
长期记忆(Long-Term Memory, LTM): 利用门控机制(Gating Functions)和遗忘因子(Forgetting Factors)对信息进行筛选并实现长期存储。
任务相关持久记忆(Persistent Memory): 用于存储与特定任务相关的关键信息,例如Titans 引入的一组可训练但与输入无关的参数,用以存储全局知识,提升模型的推理能力。
内存模块的三种使用方法:
(1)Memory as Context
(2)Memory as Gating
(3)Memory as a Model Layer
 2.17-1.jpeg
2.17-1.jpeg
2. 增强外部知识检索,提高推理效率和定制化能力
外部知识检索(External Knowledge Retrieval) 不仅能降低模型幻觉问题,加速推理,还提供了一种 Agent 级别的定制化输出方案,使模型能够根据用户上下文和领域知识生成更精准的回答。
MetaAI在该领域的长期研究:从 KNN-LM 到 最新的 Nearest Neighbor Speculative Decoding for LLM Generation and Attribution
未来,Test-Time 记忆范式 与 外部知识增强 的结合,将进一步推动大模型在 高效推理、个性化输出 以及长期知识
03 推理模型和基础模型的融合
随着Latent space推理和Test time范式的进一步发展,大模型架构正面临根本性重构——推理模块与基础语言模型的深度融合将成为下一代模型的标配。OpenAI的GPT-4.5向多模态推理架构演进,Anthropic在Claude4中引入的"滑动条"(动态计算分配控制器),本质上都在探索同一命题:如何让语言模型在基础文本生成与高阶推理能力之间实现动态切换。这一融合的主要挑战是算力和推理质量之间的可控权衡,这里我有如下大胆的猜测:
动态路由机制
- 类似于 MoE(专家混合模型)的架构,未来推理模块将根据任务动态激活。
联合训练与融合
- 基础模型与推理模块将通过latent space链接,最终融合成单一统一模型,既具备通用文本生成能力,也能高效进行多步推理。其训练范式可能会类似之前的多模态模型,采用冻结基础模型,使用RL Post train,在全参数协同优化的方案。
算力异构分配
- 在推理过程中,将对逻辑推理节点投入更多计算资源,而对描述性文本节点分配较少资源,从而在准确性和效率之间实现最佳平衡。
可以预见,传统MMLU基准将会逐渐失效,需建立包含计算效率-准确性-能耗比的三元评估指标。随着大模型的更加广泛应用,训练的成本被逐步amortize(实际上也是因为数据问题很难继续scale),推理效率将逐步成为主线。这其实也给了硬件厂商,尤其是ASIC供应商弯道超车的机会,2025年也同样谨慎看好硬件加速赛道和推理赛道。
04
写在最后
2025 年,无论从技术还是商业角度,都是激动人心的一年。站在这一历史性拐点,我们唯有在技术敬畏与创新勇气之间保持微妙的平衡,方能驾驭这场认知革命的风暴。
那些在潜空间中悄然进化的 AI,正书写智能演化史的新篇章——这或许是人类历史上第一次,我们不再是唯一的叙事主角。
然而,无论 AI 如何发展,数据始终是智能演进的基石。愿 2025 年,所有深耕 AI + Data 领域的企业都能收获突破与成长。
加油开源AI,加油中国AI,加油 Milvus&&Zilliz!
 栾小凡
栾小凡


