




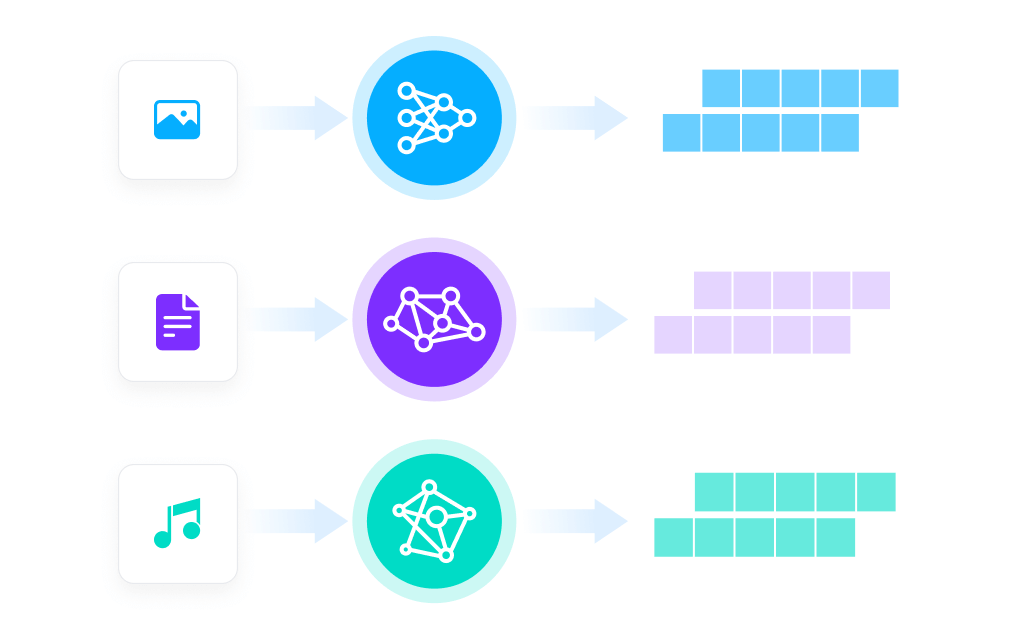
什么是 Zilliz Cloud Pipelines?
Zilliz Cloud Pipelines 能够简化将非结构化数据转换为 Embedding 向量的流程,并对接 Zilliz Cloud 向量数据库存储向量数据,实现高效的向量索引和检索。
简化开发流程
开发人员在处理非结构化数据时,时常面临复杂的非结构化数据转换和检索问题,这会降低开发速度。Zilliz Cloud Pipelines 通过提供一体化解决方案来应对这一挑战,帮助开发人员轻松将非结构化数据转换为可搜索的向量,并对接 Zilliz Cloud 向量数据库确保高质量的向量检索。

出色的向量搜索性能
基于非结构化数据创建高质量的向量搜索流水线(Pipelines)包含多个精细化的步骤,如:解析和清理数据、Embedding、近似最近邻(ANN)搜索等。Zilliz Cloud Pipelines 由众多 AI 专家打造,旨在整体处理端到端的复杂问题,保证在 Pipelines 每个阶段提供出色表现。即使新手用户也可快速上手玩转 Zilliz Cloud Pipelines。
高度可扩展
通常,数据集规模大和查询吞吐量高时,系统无法维持出色的性能。但是,Zilliz Cloud Pipelines 具备高度可扩展性和卓越的性能,能够在面对大规模数据集和高吞吐量查询时高效处理数据,免去开发人员定制代码或修改基础设施的麻烦。
Zilliz Cloud Pipelines 作用

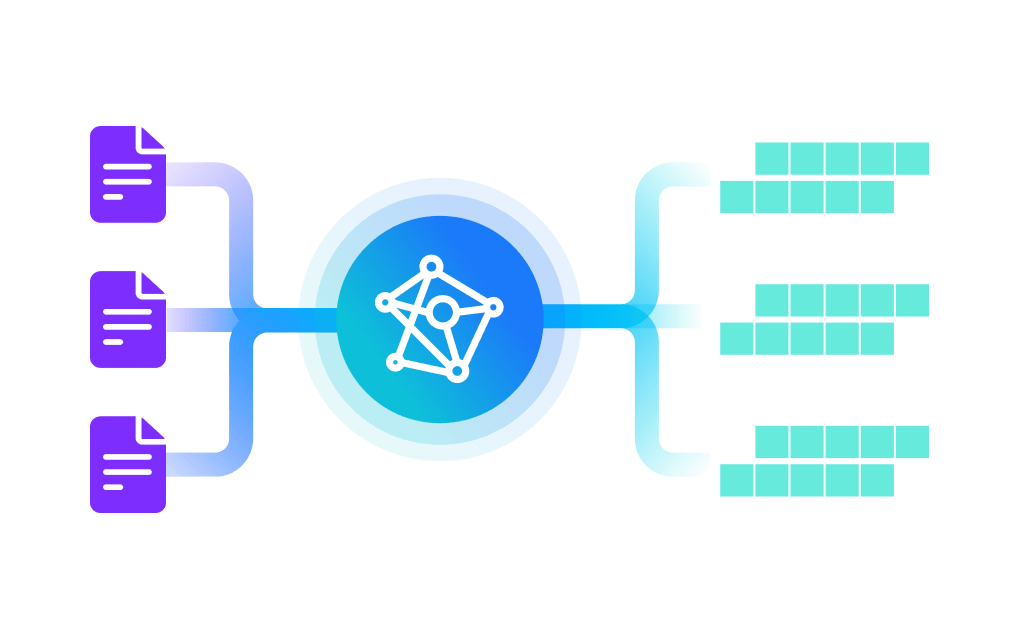
将数据转化为向量
简化将非结构化数据转换为可搜索的向量的过程。Zilliz Cloud Pipelines 支持的功能包括:将文档块转换为 Embedding向量、在搜索过程中保留元数据等。

语义搜索
高效将查询文本转换为 Embedding 向量,返回最相关的 top-K 个文档块(包括文本和元数据)。使用 Zilliz Cloud Pipelines 能够快速有效地从搜索结果中获取数据洞见。

基于元数据过滤
通过使用预先定义的元数据,在搜索时进行过滤,进一步增强检索功能。Zilliz Cloud Pipelines 支持精细搜索原始向量、利用元数据获取精确查询结果等。
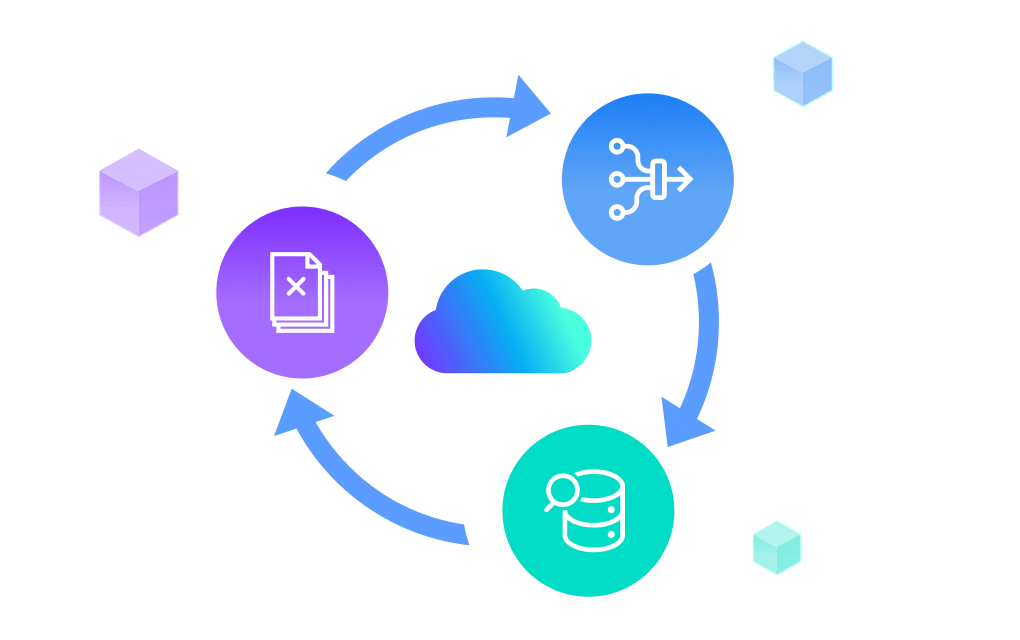
Zilliz Cloud Pipelines 工作流程

常见问题
Zilliz Cloud Pipelines 如何提升语义搜索能力?
哪些 Zilliz Cloud 版本提供 Pipelines 功能
Zilliz Cloud Pipelines 使用哪些 Embedding 模型
Zilliz Cloud Pipelines 如何收费?
Zilliz Cloud Pipelines 能否独立于 Zilliz Cloud 使用
Ingestion Pipeline 支持哪些数据来源?
Pipelines 支持哪些文档文件类型?
