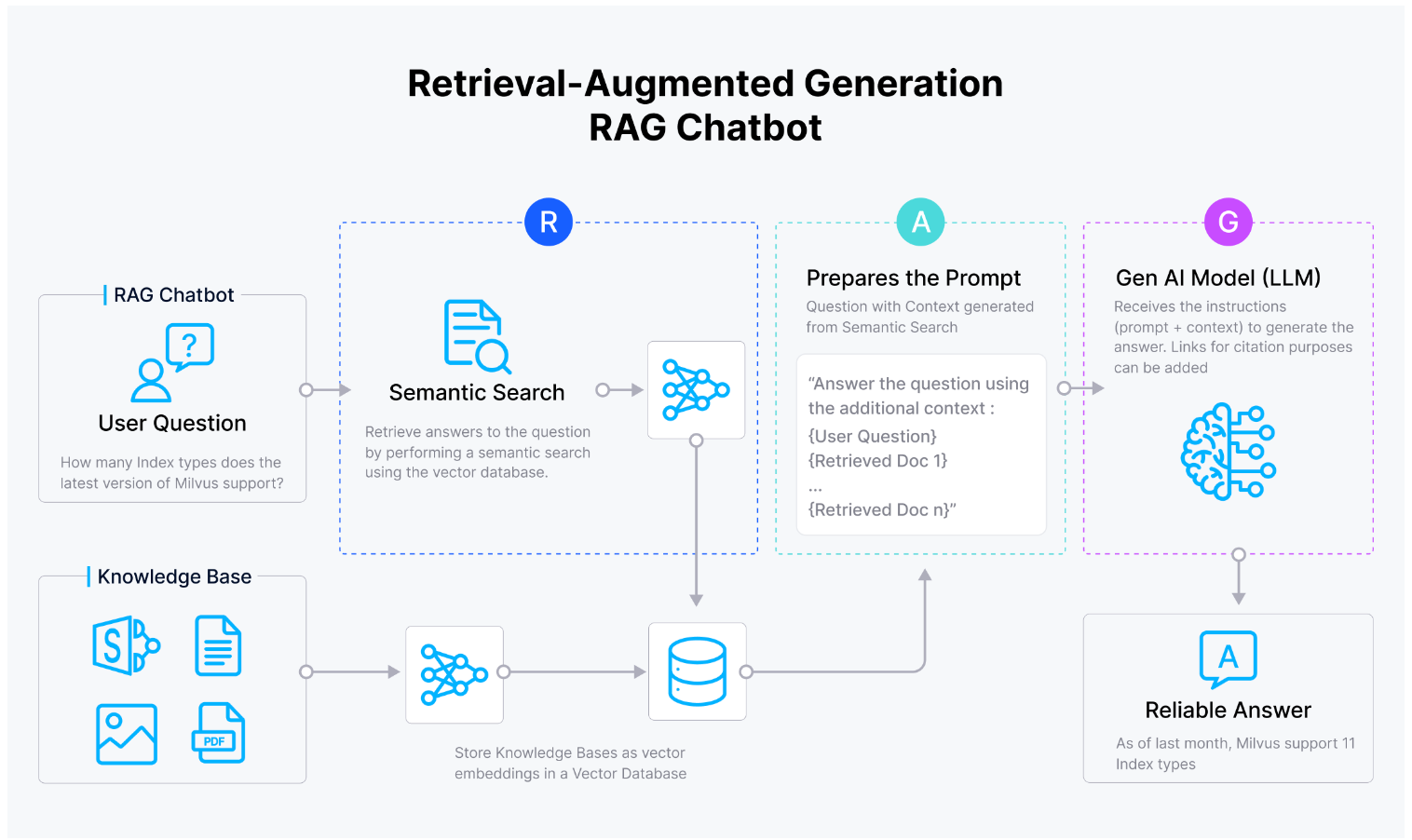
关于 Llama 2,应该知道的两三事

关于 Llama 2,应该知道的两三事
什么是 Llama 2?
Meta AI 在 2023 年推出的 Llama 2,是大语言模型(LLM)领域的一项重要突破。这些模型,包括 Llama 2 和 Llama 2-CHAT,其参数量高达 700 亿,并且可以免费用于研究和商业用途。这一进展极大地提升了自然语言处理(NLP)的能力,从文本生成到编程代码的解读均有了显著的改进。
相较于只能在非商业许可下被研究机构使用的 LLaMa 1,Llama 2 的出现标志着我们向开放获取前沿 AI 技术迈出了重要的一步。与 LLaMa 1 不同,Llama 2 模型是“开源”的,这意味着它们可以自由地应用于研究和商业场景,这反映了 Meta 对于构建一个更加包容和协作的生成式 AI 生态系统的承诺。
Llama 2 的推出使得开发者更容易访问前沿的 LLM,并解决了其开发过程中的计算挑战。在不指数级增加参数数量的前提下,Llama 2 通过性能优化提供了不同规模的模型,参数量从 70 亿到 700 亿不等。这种策略使得小型组织和研究团体也能够在无需巨额计算资源的情况下利用 LLM 的强大功能。
此外,Meta 对透明的追求体现在其决定公开 Llama 2 的代码和模型权重上,这有助于 AI 研究界进行更深入的理解和协作。通过降低门槛并提高可访问性,Llama 2 为 AI 研究与发展开辟了一条更加包容和创新的路径。
Llama 2
Llama 2 是 Llama 1 的升级版本,它在一个新的公共数据混合集上进行训练。预训练数据集增加了 40%,上下文长度翻了一番,并且 Meta 团队在构建 Llama 2 时采用了分组查询注意力机制。
| Training Data | Parameters | Context Length | Group-query attention | Tokens | |
| Llama 1 | See Touvron et al.(2023) | 7B | 2K | - | 1.0T |
| 13B | 2K | - | 1.0T | ||
| 33B | 2K | - | 1.4T | ||
| 65B | 2K | - | 1.4T | ||
| Llama 2 | A new mix of publiclyavailable online data | 7B | 4K | - | 2.0T |
| 13B | 4K | - | 2.0T | ||
| 34B | 4K | ✓ | 2.0T | ||
| 70B | ✓ | 2.0T |
Llama 2-CHAT
Llama 2-CHAT 是 Meta 团队针对自然语言使用场景对 Llama 2 进行微调后的版本。该模型的变体提供了 7B、13B 和 70B 参数的不同版本。Llama 2-Chat 同样面临着其他大语言模型(LLM)所共有的局限性,包括预训练后知识更新的停止、可能产生幻觉或提供错误建议等问题。
Llama 2 open source
虽然 Meta 提供了 Llama 2 模型的启动代码和模型权重,以支持研究和商业应用,但是关于是否应将其称为“开源”的讨论也随之产生。这是因为其许可协议中设定了一些特定的限制。
关于 Llama 2 许可条款的分类,争议主要集中在技术细节和语义上。通常,“开源”一词被广泛用来指代可以自由访问源代码的软件,但在开源倡议(OSI)的正式定义中,它有更为严格的含义。要符合“开源倡议批准”的标准,软件许可证必须满足官方开源定义(OSD)中提出的十个条件。
因此,Llama 2 模型是否适用于“开源”这一标签,取决于其许可条款是否符合 OSI 的严格标准。这有助于避免混淆,确保社区成员对软件许可条款有正确的理解,这些条款决定了资源的使用、修改和分发权限。
尽管 Llama 2 的开源程度可能存在一定限制,但相较于 OpenAI、Google 等在生成式 AI 领域的领先企业所提供的封闭模型,它为开发者带来了更高的灵活性,因此依旧是一个极具吸引力的选项。
Llama 2 架构
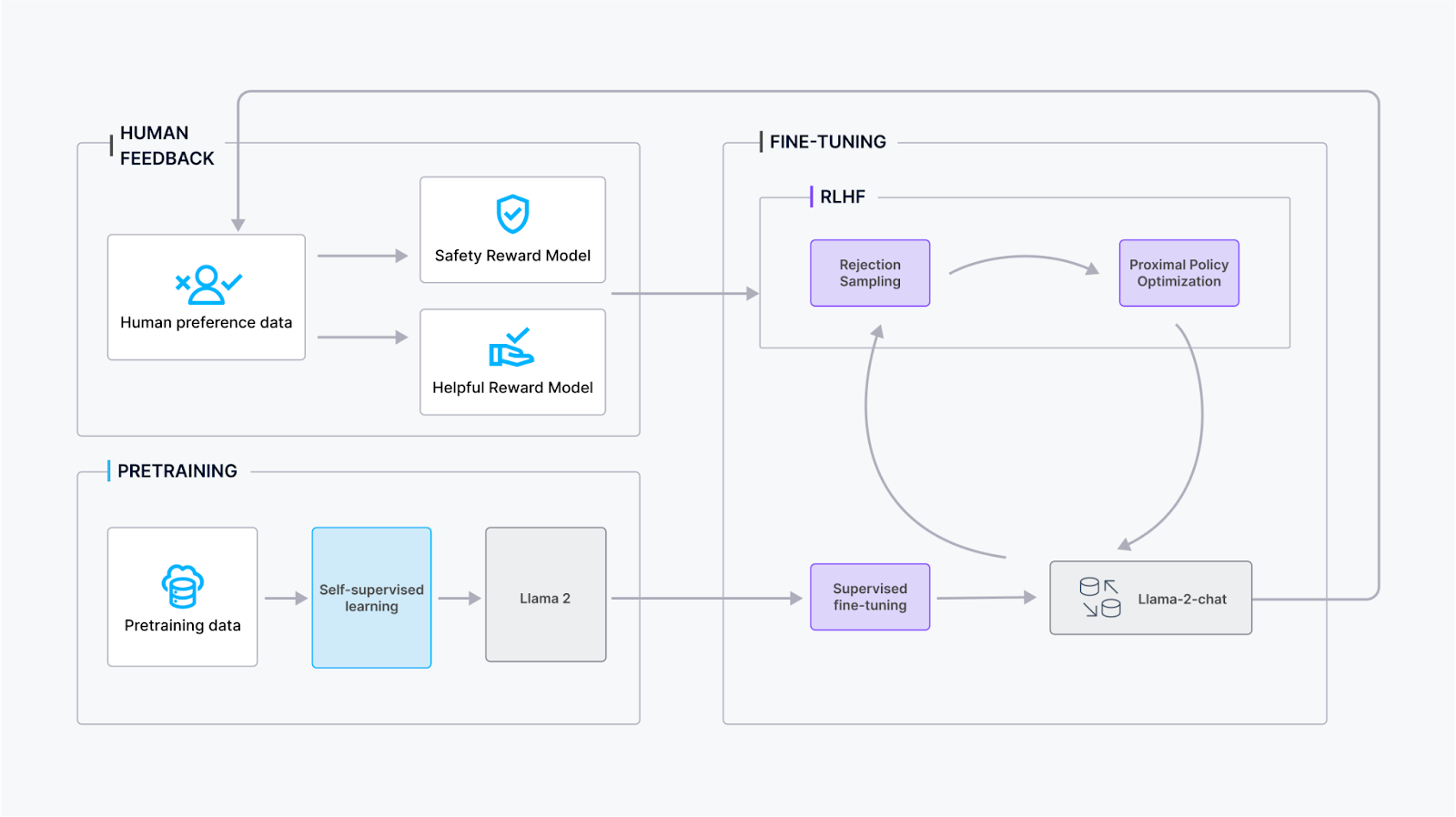
Llama 2-Chat 的研发经历了多个训练阶段,旨在提升对话表现并不断优化:
预训练阶段:利用公开的在线资源对 Llama 2 进行基础训练,形成语言理解和知识基础。
监督微调阶段:Meta 团队基于标注数据对 Llama 2 进行初始的监督微调,以增强其对话交互功能。
强化学习与人类反馈结合(RLHF)阶段:通过拒绝采样和近端策略优化(PPO)等 RLHF 方法对模型进行多轮迭代优化,期间不断收集人类反馈以提升对话的品质。
迭代奖励建模阶段:在 RLHF 阶段,伴随模型优化,持续进行迭代奖励建模,确保奖励模型贴近实际分布,从而不断提高模型的对话技能。 通过这些综合训练步骤,Llama 2-Chat 力求在适应用户反馈的同时,保持与奖励模型的一致性,以达到更加稳健的对话性能。
采用这些综合训练步骤,Llama 2-Chat 的目标是在对话表现上达到稳健性,同时快速响应并适应用户的反馈,保持与奖励模型的高度契合。
机器学习中的 Embedding 是什么?
在机器学习中,Embedding 是指在连续向量空间内学习到的对象表征。这些对象可以是单词、图片或实体等,Embedding 能够捕捉它们之间的语义关系和相似性,这对于计算任务至关重要。例如,在自然语言处理(NLP)领域,单词 Embedding 将词汇表中的单词转换为高维空间中的密集向量,使得语义相近的单词在向量空间中相互靠近。
在 Llama 2 中,Embedding 对于理解和生成自然语言起着核心作用。该模型通过将单词、短语或整个句子表示为连续向量空间中的 Embedding 来处理和生成文本,同时捕捉相关的语义关系和细微差别。
在训练过程中,Llama 2 从大量的文本数据中学习单词和短语的 Embedding。这些 Embedding 包含了关于语言的语义信息,使得 Llama 2 能够对查询或提示做出连贯的理解和响应。
Llama 2 中使用的机器学习 Embedding 为语言和其他数据提供了一个结构化和语义上有意义的表征,从而实现了自然语言的高效处理、理解和生成。
如何使用 Llama 2?
要高效运用 Llama 2,首先通过提供的接口或 API 接入模型,并确保拥有适当的权限。接着,准备输入数据,包括文本、图片或适用的其他格式,并对数据进行必要的预处理。为 Llama 2 明确指定任务,例如文本生成或概括。将预处理后的数据输入到 Llama 2 中,获取其生成的输出,并对输出的质量进行评估。通过调整不同的格式和设置来提升成果的质量。关注性能指标,如准确率和处理速度,并根据反馈调整方法。及时了解并应用模型的更新,以充分发挥其效能,为各种项目和应用程序创造更多可能。在构建 RAG 应用时,还可以结合使用 LangChain、LlamaIndex 和 Semantic Kernel 等工具。
Llama 2 性能表现
Llama 2 的性能可以通过一些广泛认可的综合性基准测试来衡量。以下是根据 Llama 2 论文提供的,与开源模型相比的性能结果表格:
| Model | Size | Code | Commonsense Reasoning | World Knowledge | Reading Comprehension | Math | MMLU | BBH | AGI Eval |
| MPT | 7B | 20.5 | 57.4 | 41.0 | 57.5 | 4.9 | 26.8 | 31.0 | 23.5 |
| 30B | 28.9 | 64.9 | 50.0 | 64.7 | 9.1 | 46.9 | 38.0 | 33.8 | |
| Falcon | 7B | 5.6 | 56.1 | 42.8 | 36.0 | 4.6 | 26.2 | 28.0 | 21.2 |
| 40B | 15.2 | 69.2 | 56.7 | 65.7 | 12.6 | 55.4 | 37.1 | 37.0 | |
| Llama 1 | 7B | 14.1 | 60.8 | 46.2 | 58.5 | 6.95 | 35.1 | 30.3 | 23.9 |
| 13B | 18.9 | 66.1 | 52.6 | 62.3 | 10.9 | 46.9 | 37.0 | 33.9 | |
| 33B | 26.0 | 70.0 | 58.4 | 67.6 | 21.4 | 57.8 | 39.8 | 41.7 | |
| 65B | 30.7 | 70.7 | 60.5 | 68.6 | 30.8 | 63.4 | 43.5 | 47.6 | |
| Llama 2 | 7B | 16.8 | 63.9 | 48.9 | 61.3 | 14.6 | 45.3 | 32.6 | 29.3 |
| 13B | 24.5 | 66.9 | 55.4 | 65.8 | 28.7 | 54.8 | 39.4 | 39.1 | |
| 33B | 27.8 | 69.9 | 58.7 | 68.0 | 24.2 | 62.6 | 44.1 | 43.4 | |
| 65B | 37.5 | 71.9 | 63.6 | 69.4 | 35.2 | 68.9 | 51.2 | 54.2 |
可以看出,Llama 2 在 MMLU 和 BBH 等多个类别中超越了 Llama 1,并且在与 Falcon 模型的对比中也表现出色。
Llama 2 vs GPT 4
Llama 2 的论文还包含了一些与 GPT 4 及其他模型的比较,如下所示:
| Benchmark (shots) | GPT-3.5 | GPT-4 | PaLM | PaLM-2-L | Llama 2 |
| MMLU (5 shot) | 70.0 | 86.4 | 69.3 | 78.3 | 68.9 |
| TriviaQA (1-shot) | — | — | 81.4 | 86.1 | 85.3 |
| Natural Questions (1-shot) | — | — | 29.3 | 37.5 | 33.0 |
| GSM8K (8-shot) | 57.1 | 92.0 | 56.5 | 80.7 | 56.8 |
| HumanEval (0-shot) | 48.1 | 67.0 | 26.2 | — | 29.9 |
| BIG-Bench Hard (3-shot) | — | — | 52.3 | 65.7 | 51.2 |
- MMLU (五次样本):在这个设置中,模型获得了五篇文章或示例,然后基于这些信息生成回答。
- TriviaQA (一次样本):这个数据集让模型在生成答案前只接触一个上下文或问题。
- Natural Questions (一次样本):在这个数据集中,模型接收到一个问题作为输入。
- GSM8K (八次样本):在这个数据集里,模型需要基于八个篇章或示例来回答问题或完成任务。
- HumanEval (零次样本): 这个数据集或评估方式检验的是模型在没有专门训练的情况下处理任务或问题的能力,因此被称作“零次样本”。
Zilliz Cloud 上可以使用 Llama 2 吗?
将 Zilliz Cloud 与 Llama 2 结合使用的主要场景之一是开发检索增强型生成(RAG)应用。这类应用充分发挥了大语言模型(例如 Llama 2)的潜力,尽管这些模型在庞大的数据集上进行训练,但其运作仍受限于有限的数据。单独使用 Llama 2 时,它可能会在没有足够信息或准确上下文的情况下产生幻觉。RAG 正是解决这一问题的方法之一。
通过将 Zilliz Cloud 与 Llama 2 配合使用,您能够将先进的自然语言理解和生成功能与 Zilliz Cloud 提供的高效、可伸缩的向量检索系统紧密结合。这种组合使得开发者能够利用两个平台的优势,打造出在涉及全面语言理解、信息检索和内容生成任务中表现卓越的复杂应用。