ChatGPT这样的生成型人工智能会取代谷歌搜索吗?
几十年来,搜索引擎一直是我们在线查找信息的首选工具。从简单的查询到复杂的研究,我们都依赖像谷歌这样的引擎从数十亿网页中找到我们正在寻找的信息,并在几秒钟内提供最相关的结果。然而,人工智能的最新进展开始挑战这种传统方法。
生成型人工智能(GenAI),特别是像ChatGPT这样的大型语言模型(LLMs),在取代搜索引擎方面迈出了重要一步。这些AI工具在大量数据上预训练,能够理解和生成几乎每个领域的详细且具有上下文意识的类人文本。这引发了一个重要问题:生成型人工智能会取代传统搜索引擎吗?
在本文中,我们将探讨GenAI和传统搜索引擎的工作原理,比较它们的优势和劣势,并讨论整合这两种技术的可能性。
了解生成型人工智能及其能力
生成型人工智能(GenAI)指的是一类可以生成新内容的人工智能模型,从文本和图像到音乐等。与传统专注于识别模式和进行预测的AI技术不同,生成型AI基于它接收的输入(提示)和它训练过的数据创建原始内容。这些模型使用复杂的算法理解和模仿人类语言,使它们非常灵活且强大。
过去几十年生成型AI的发展取得了快速进展。早期的AI模型是基于规则的系统,能力有限。然而,2000年代机器学习和神经网络的兴起标志着一个重大飞跃。研究人员开始开发能够从大型数据集中学习并随时间提高性能的模型。
2017年,谷歌研究人员引入了Transformer架构,这是一个重大突破。这种架构使得能够处理和生成文本的大型语言模型的创建成为可能,其准确性前所未有。在此基础上,OpenAI开发了生成预训练变换器(GPT)系列,其中GPT-4是迄今为止最先进的版本。
ChatGPT及其背后的AI模型
由OpenAI开发的ChatGPT基于GPT-3和GPT-4模型。GPT代表生成预训练变换器,是有史以来创建的最大和最强大的大型语言模型(LLMs)之一。它有1750亿个参数,这些是模型在训练过程中调整以提高其准确性的权重和偏差。
GPT-3在多样化的互联网文本上训练,使其能够对各种提示生成连贯且相关的回应。当你向ChatGPT提问或给它一个任务时,它分析输入,预测最可能的下一个单词,并生成一个遵循上下文和人类对话风格的回应。
ChatGPT的能力是巨大的。它可以回答问题、写文章、生成创意内容、提供各种学科的辅导,甚至参与复杂对话。它理解上下文和生成类人文本的能力使其成为许多应用的强大工具。
然而,需要注意的是,尽管ChatGPT非常先进,它也有局限性。它有时会产生错误或无意义的答案,被称为“幻觉”,并且可能在理解微妙或含糊的查询上挣扎。一种称为检索增强型生成(RAG)的技术出现,以减轻这些幻觉。它通常包括一个向量数据库如Milkus、一个嵌入模型和一个LLM。向量数据库为LLM提供上下文信息,以便模型可以生成更准确和相关的用户查询答案。
尽管存在这些挑战,ChatGPT所代表的生成型AI的进步是显著的,并继续推动AI能够实现的界限。
传统搜索引擎及其工作原理
像谷歌这样的传统搜索引擎是旨在帮助用户在线查找信息的工具。它们爬行、索引并排名网页,以向用户的查询提供最相关的结果。
搜索引擎是一个基于用户查询在互联网上搜索信息的软件系统。当你输入一个搜索词时,搜索引擎扫描其网页索引并返回与你的查询最匹配的结果列表。这些结果可以包括网页、图像、视频、新闻文章和其他类型的内容。
关键搜索组件:爬行、索引和排名
- 爬行:搜索引擎使用称为爬虫或蜘蛛的自动化程序浏览网络并发现新内容或更新内容。这些爬虫从一个页面链接到另一个页面,收集它们访问的每个页面的数据。
- 索引:一旦页面被爬行,搜索引擎处理信息并将其添加到其索引中。索引是一个庞大的数据库,包含搜索引擎发现并标记为相关的所有内容。这个数据库允许搜索引擎在用户搜索时快速检索和显示相关结果。
- 排名:当用户输入查询时,搜索引擎使用复杂的算法根据其与查询的相关性对索引页面进行排名。目标是在搜索结果页面的顶部展示最有用和最相关的结果。
传统搜索的排名算法
最著名的排名算法之一是谷歌的PageRank。PageRank根据指向它们的链接数量和质量(称为反向链接)评估网页的重要性。基本思想是拥有高质量传入链接的页面更具权威性和相关性。
多个因素影响搜索引擎对页面的排名。虽然排名算法随时间变化,但一些常见因素包括:
- 相关性:页面内容与用户查询的匹配程度。这包括与主题相关的关键词的存在、内容的上下文以及它如何满足搜索意图。
- 权威性:页面的可信度和可靠性,通常由来自其他知名网站的传入链接的数量和质量决定。
- 用户行为:搜索引擎还考虑用户与搜索结果的互动。点击率(CTR)、在页面上花费的时间和跳出率等指标可以表明页面的相关性和质量。
ChatGPT与搜索引擎的全面比较
让我们在以下几个关键方面比较ChatGPT和传统搜索引擎。
答案生成和信息检索
ChatGPT理解用户意图并生成直接的、对话式的回应。它解释复杂查询并以类似人类的方式提供上下文相关的答案。例如,如果被要求解释HNSW这样的技术概念,ChatGPT可以提供一个详细且简化的解释,适应正在进行的对话。这使其在交互式、基于对话的信息检索中特别有用,用户寻求快速、个性化的答案。
传统的搜索引擎如谷歌的运作方式不同。它们不是生成答案,而是检索和排名包含相关信息的网页链接。这些搜索引擎爬行网络、索引大量内容,并使用复杂的算法根据相关性、权威性和用户行为对结果进行排名。这种方法允许用户访问广泛的内容,从学术文章和新闻报道到视频和博客文章,提供可用信息的全面概述。
权威性、可信度和可靠性
虽然ChatGPT在生成内容方面非常强大,但在确保其回应的准确性和可靠性方面面临挑战。这个模型和其他许多LLMs基于其训练数据中学到的模式生成文本,有时可能导致错误或误导性信息,被称为“幻觉”。此外,ChatGPT无法访问实时信息,这意味着它的答案可能过时。缺乏直接链接到经过验证的来源也限制了用户核对提供的信息的能力。
像谷歌这样的搜索引擎在其搜索结果中优先考虑权威性和可信度。它们根据相关性、来源的权威性和传入链接的质量等因素对内容进行排名。像PageRank这样的算法评估网页的可信度,确保顶部搜索结果来自可靠的来源。这种方法允许用户在多个权威来源之间验证信息,提供对访问内容的更高信心。然而,缺点是它们可能会用过多的结果压倒用户,使得快速找到最相关信息变得困难。
实时信息和更新
ChatGPT的一个重要限制是它无法提供实时信息。其知识基于一个静态数据集,因此它无法提供对当前事件、最近的科学发现或其最后训练周期之外的任何发展的更新。这限制了它对需要最新信息的查询的有用性。
相比之下,传统搜索引擎不断索引新内容并提供实时信息。用户可以快速访问最新的新闻、研究和发展,使这些平台更适合需要当前和持续更新信息的查询。
理解和处理复杂查询
ChatGPT的优势在于其理解和回应细微、内容丰富的查询的能力。它可以参与多轮对话,在此基础上提供更精细的答案。这使其非常适合寻求详细解释或需要提出后续问题以澄清理解的用户。
虽然传统搜索引擎有效地根据关键词检索信息,但在理解和处理需要上下文理解的复杂或微妙查询方面却挣扎。用户可能需要完善他们的搜索词或浏览多个页面以找到所需信息,特别是如果最初的查询是含糊或没有很好地表述的。
AI内容中的伦理问题和偏见
像ChatGPT这样的LLMs可能会反映和放大其训练数据中的偏见,引发伦理关注。这可能导致生成有偏见甚至有害的内容,通常是无意的。此外,使用AI生成的内容进行恶意目的,如传播错误信息或创建欺骗性材料,也存在风险。这些伦理挑战需要仔细考虑和持续努力,以确保AI的负责任开发和使用。
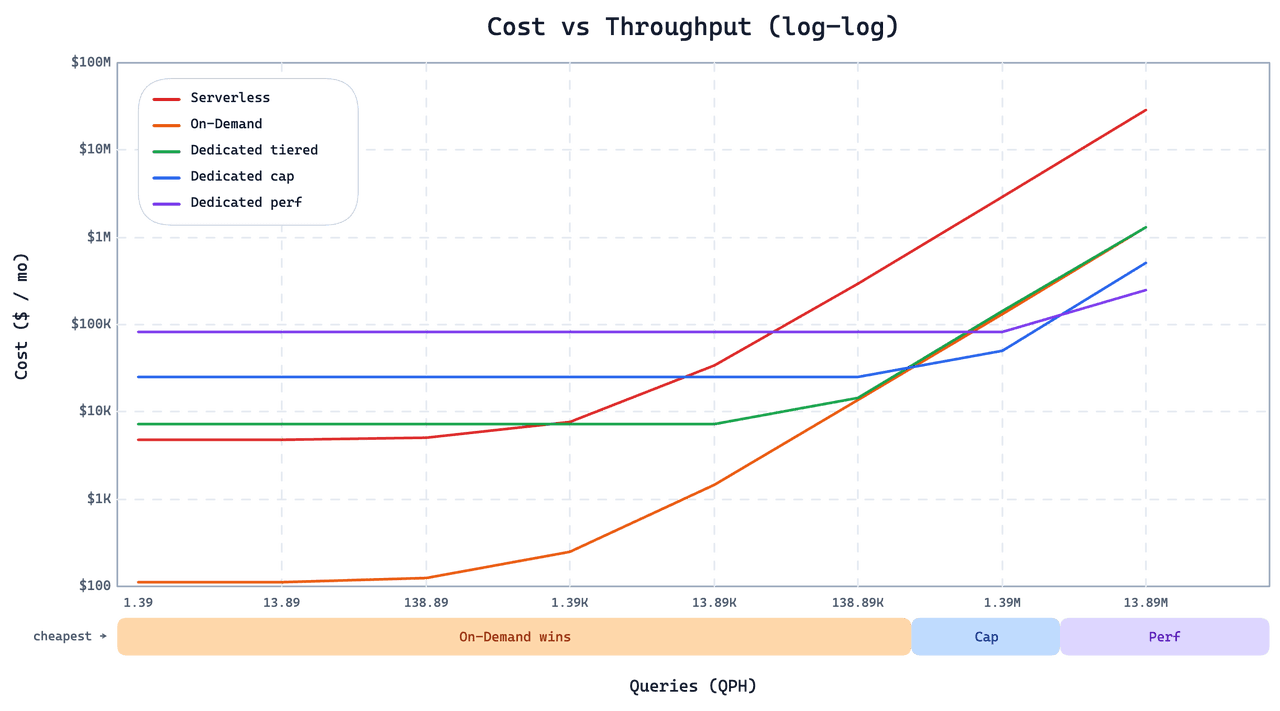
传统搜索引擎并非没有偏见,但它们呈现了来自各种来源的广泛信息,使用户可以比较和对比不同的视角。然而,搜索引擎严重依赖排名算法来确定搜索结果的顺序。这些算法可以通过SEO(搜索引擎优化)实践来操纵,其目的是增加网页的可见性。 下图总结了ChatGPT和传统搜索引擎之间的主要区别。
| Aspect | ChatGPT | Traditional Search Engines |
|---|---|---|
| Understanding User Intent | Excellent at understanding and providing direct, conversational answers | Good at matching keywords but may struggle with nuanced queries |
| Information Retrieval | Generates text based on training data, not real-time information | Crawls, indexes, and retrieves vast amounts of web data in real-time |
| Response Generation | Provides detailed, human-like responses | Provides links to relevant sources, requiring user navigation |
| Accuracy | Can produce incorrect or misleading information (hallucinations) | Uses algorithms to rank authoritative sources, generally reliable |
| Real-Time Updates | Limited to data up to its training cutoff date | Continuously updates with new content from the web |
| Ethical Concerns | Prone to biases in training data, ethical use concerns | Issues with SEO manipulation and ranking fairness |
| User Experience | Interactive and conversational, ideal for specific questions | Efficient for broad searches and accessing a wide range of content |
| Data Sources | Trained on diverse internet text up to a certain date | Continuously crawls and indexes current web content |
| Reliability | Can struggle with providing consistent, accurate information | Generally reliable, especially for well-established topics |
| Use Cases | Ideal for personalized tutoring, creative writing, and conversational tasks | Best for comprehensive research, finding specific documents, and broad information searches |
表:比较ChatGPT和传统搜索
ChatGPT会取代搜索引擎吗?
ChatGPT是否会取代传统搜索引擎的问题引人入胜但复杂。虽然ChatGPT带来了生成对话式和上下文相关回应的创新特性,但它也有局限性,如幻觉、过时信息和回应偏见的可能性。同样,传统搜索引擎提供了显著的好处,并为无数用户和应用提供了动力,但在生成类似人类的答复和处理复杂多跳问题方面却挣扎。
鉴于这些因素,ChatGPT在可预见的未来不太可能完全取代传统搜索引擎。相反,搜索的未来可能会发展为整合生成型AI和传统搜索引擎。通过结合这两种技术的优势,我们可以创造一个更高效的搜索体验——生成型AI提供直接、对话式的答案,而传统搜索引擎提供全面的资源列表,以确保准确性和权威性。
现实世界中混合AI和搜索方法的例子
像谷歌和微软这样的公司正在将AI整合到他们的搜索引擎中。谷歌使用AI在搜索结果的顶部提供精选片段和快速答案。微软的Bing也整合了AI以提供智能答案和总结搜索结果。这些努力展示了将AI与传统搜索技术结合的好处。
 Figure_An_example_of_Google_s_Hybrid_AI_and_Search_Approach_8d57878f47.png
Figure_An_example_of_Google_s_Hybrid_AI_and_Search_Approach_8d57878f47.png
图-谷歌混合AI和搜索方法的例子
谷歌还在测试生成型AI工具以增强搜索功能。这些工具旨在提供更详细和上下文相关的答案,但在准确性和偏见方面引发了争议。尽管存在这些挑战,AI改变搜索的潜力仍然巨大。
向量数据库在混合AI和搜索中的作用
向量数据库是一种数据管理系统,它通过在高维空间中存储、索引和搜索称为向量嵌入的数值表示,来处理非结构化数据,以快速进行语义信息检索和向量相似性搜索。Milkus和Zilliz Cloud(完全托管的Milkus)是两个主要的专用向量数据库,可以处理数十亿规模的向量数据。
通过将Milkus与LLMs整合,公司可以实施强大的检索增强型生成(RAG)系统。这些系统可以通过结合搜索引擎的实时数据检索优势和像ChatGPT这样的AI模型的上下文感知生成能力,来减轻LLMs中的幻觉问题。这种协同作用还可以显著提高搜索技术的准确性、相关性和用户体验,为下一代信息检索系统铺平道路。
结论
像ChatGPT这样的生成型AI通过提供直接、对话式的回应,重新定义了我们与信息的互动方式。然而,它面临着准确性、实时更新和伦理问题等挑战。传统搜索引擎擅长索引大量信息并确保其相关性和权威性,但可能会被过多结果压倒,并且在处理微妙查询方面挣扎。
搜索的未来可能在于混合AI和搜索方法,结合生成型AI和传统搜索引擎的优势。这种整合承诺了一个更高效、更直观的搜索体验,提供了直接的答案和全面的资源。随着创新的继续,AI和传统搜索引擎可能会共存并互补,增强我们在线访问和互动信息的方式。
 Fariba Laiq
Fariba LaiqFreelance Technical Writer