什么是知识图谱(KG)?
互联网是信息的海洋,随着时间的推移不断增长。这一事实导致数据在复杂性和体积上不断增加。管理、解释和从数据中提取意义变得越来越具有挑战性。知识图谱(KGs)提供了一种结构化的方法来连接和上下文化数据,以应对这一挑战。它们是表示实体及其关系的语义网络,专注于不同数据片段之间的连接。
尽管“知识图谱”这个短语早在20世纪80年代就出现了,但它是从语义网络、本体论、语义网和链接数据发展而来的。然而,它在2012年谷歌宣布其知识图谱项目以改善搜索结果后开始流行起来,随后包括亚马逊、Facebook和微软在内的其他公司也宣布了知识图谱。
从那时起,知识图谱在不同领域变得重要,从搜索引擎和推荐系统到人工智能和数据分析。它们提供了对关系和上下文的更深入理解,使系统能够做出更明智的决策。
在本文中,我们将更详细地向您介绍知识图谱,它们的组成部分,如何构建它们,以及它们的不同应用。
什么是知识图谱(KG)?
知识图谱是一种将信息表示为实体及其关系的网络的数据结构。它是一个有向标记图,其中特定领域的意思是与节点和边(关系)相关联的。
知识图谱有三个关键组成部分:节点(实体)、边(关系)和标签。
一个节点可以代表任何现实世界的实体,包括人、公司和计算机。一条边捕捉两个节点之间的感兴趣关系,例如公司和人之间的客户关系,或两台计算机之间的网络连接。为了提高图的清晰度,标签提供有关节点和边的额外信息。它们是指定关系性质的实体属性。
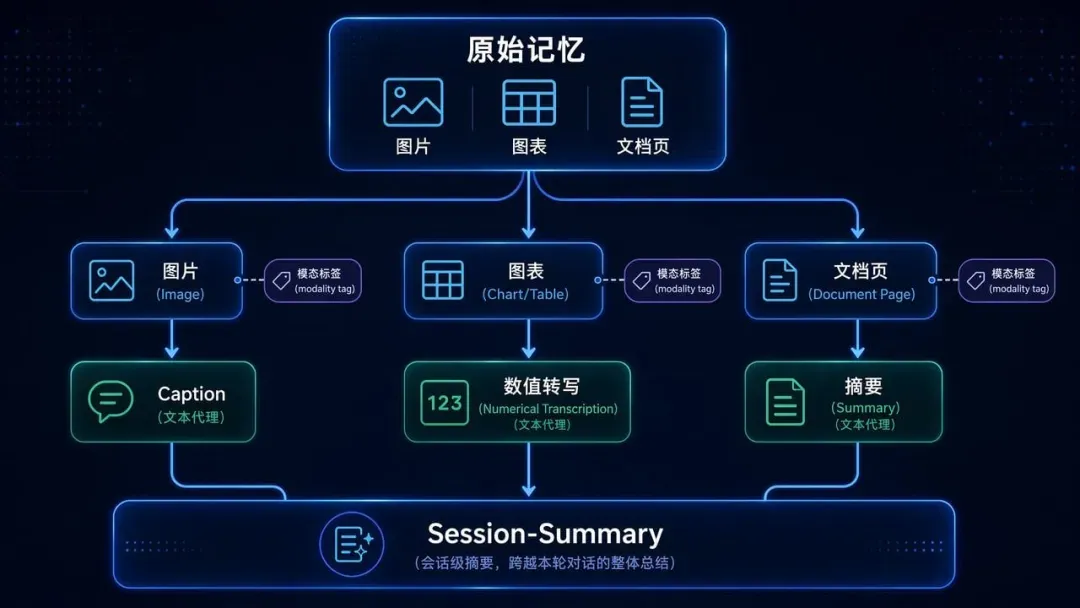
 Figure_1_Knowledge_graphs_illustration_643cec06af.png
Figure_1_Knowledge_graphs_illustration_643cec06af.png
图1:知识图谱插图(图片来源)
与表格等其他数据结构不同的是,知识图谱能够处理实体之间复杂的、相互关联的关系。知识图谱通常存储在像Neo4j和ArangoDB这样的图数据库中。
知识图谱以更动态和相互连接的方式存储数据。下图显示了数据如何在表格和图中表示。图的一个好处是它提供了模式灵活性,消除了预定义的“表头”所施加的限制。因此,图可以在不造成任何数据存储中断的情况下发展。
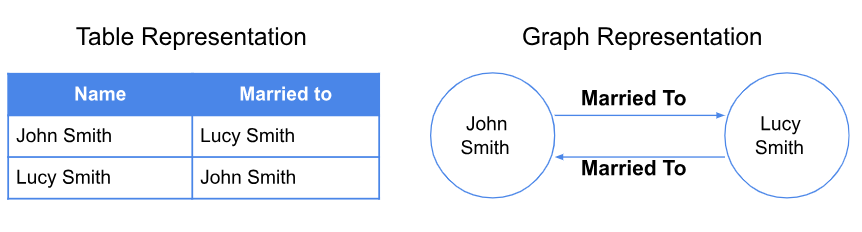 Figure_2_Data_represented_in_the_table_and_graph_bf534e074d.png
Figure_2_Data_represented_in_the_table_and_graph_bf534e074d.png
图2:在表格和图中表示的数据
知识图谱的核心特征
知识图谱是旨在捕捉实体及其关系之间复杂相互联系的结构化数据集。它们具有几个关键特征,使它们对不同应用有价值。
- 实体的相互描述
- 形式化语义和本体论
- 能够整合多个来源的数据
- 可扩展性和灵活性
实体的相互描述
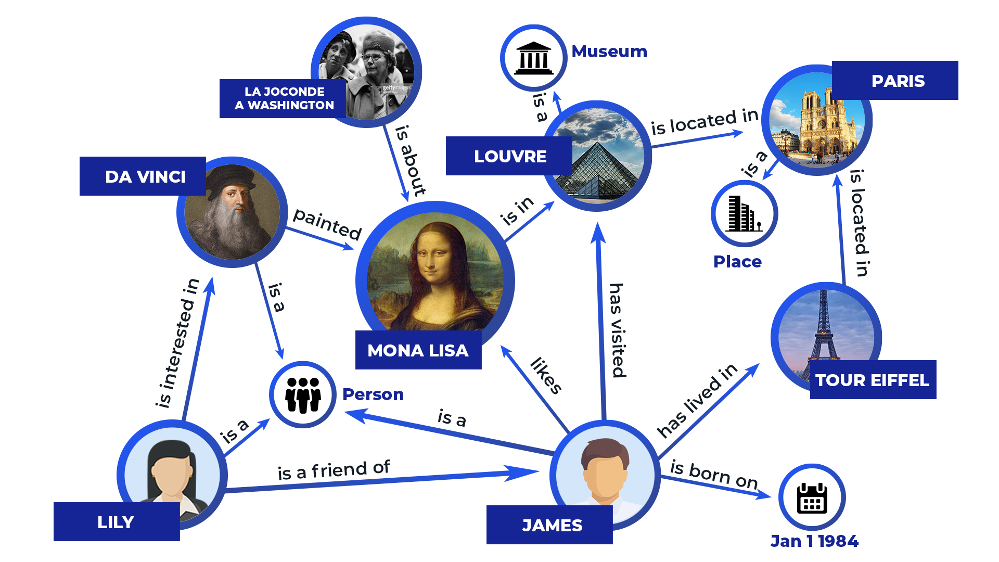
知识图谱不仅仅存储孤立的事实。它们代表了实体的一系列相互关联的描述。在知识图谱中,每个实体都表示为一个节点,例如人,而边表示将一个实体与另一个实体绑定的语义链接。这些连接创建了一个信息网络,并提供了对实体之间上下文和关系更深入的理解。
 Figure_3_An_example_of_Graph_representation_Image_by_the_Author_5e54d43b2e.png
Figure_3_An_example_of_Graph_representation_Image_by_the_Author_5e54d43b2e.png
图3:图表示的例子(作者图)
形式化语义和本体论
在知识图谱的背景下,形式化语义和本体论是重要的组成部分,它们使清晰的解释和一致的数据组织成为可能。形式化语义指的是使用明确定义的规则来表示和推理信息,知识图谱在很大程度上依赖于此,这意味着它们使用预定义的结构(本体论)来定义实体和关系的类型。
本体论通常包括:
- 类别定义知识图谱中的实体类型,如“人”、“地点”或“事件”。
- 属性描述实体的属性以及它们之间的关系。例如,“人”类别可能具有“姓名”、“年龄”和“地址”等属性。
- 实例:知识图谱中的具体数据点代表特定类别。
知识图谱可以使用本体论以一致和结构化的方式组织数据,使其更容易分析。
能够整合多个来源的数据
结合来自众多来源的数据可能是复杂的。当我们将结构化数据(如数据库)、半结构化数据(如XML文件)和非结构化数据(如文本)汇集在一起时,可能会变得混乱。幸运的是,知识图谱非常灵活,擅长将这些片段整合成一个清晰的图景。这是因为它们可以以模仿人类理解和认知的格式表示实体和关系。
例如,知识图谱可以将电影数据库(结构化数据)与多个网站的电影评论(非结构化数据)和不同来源的评分(半结构化数据)连接起来。这种整合创造了对每部电影更全面的分析和洞察,包括其演员、导演、类型、评分和人们的意见。
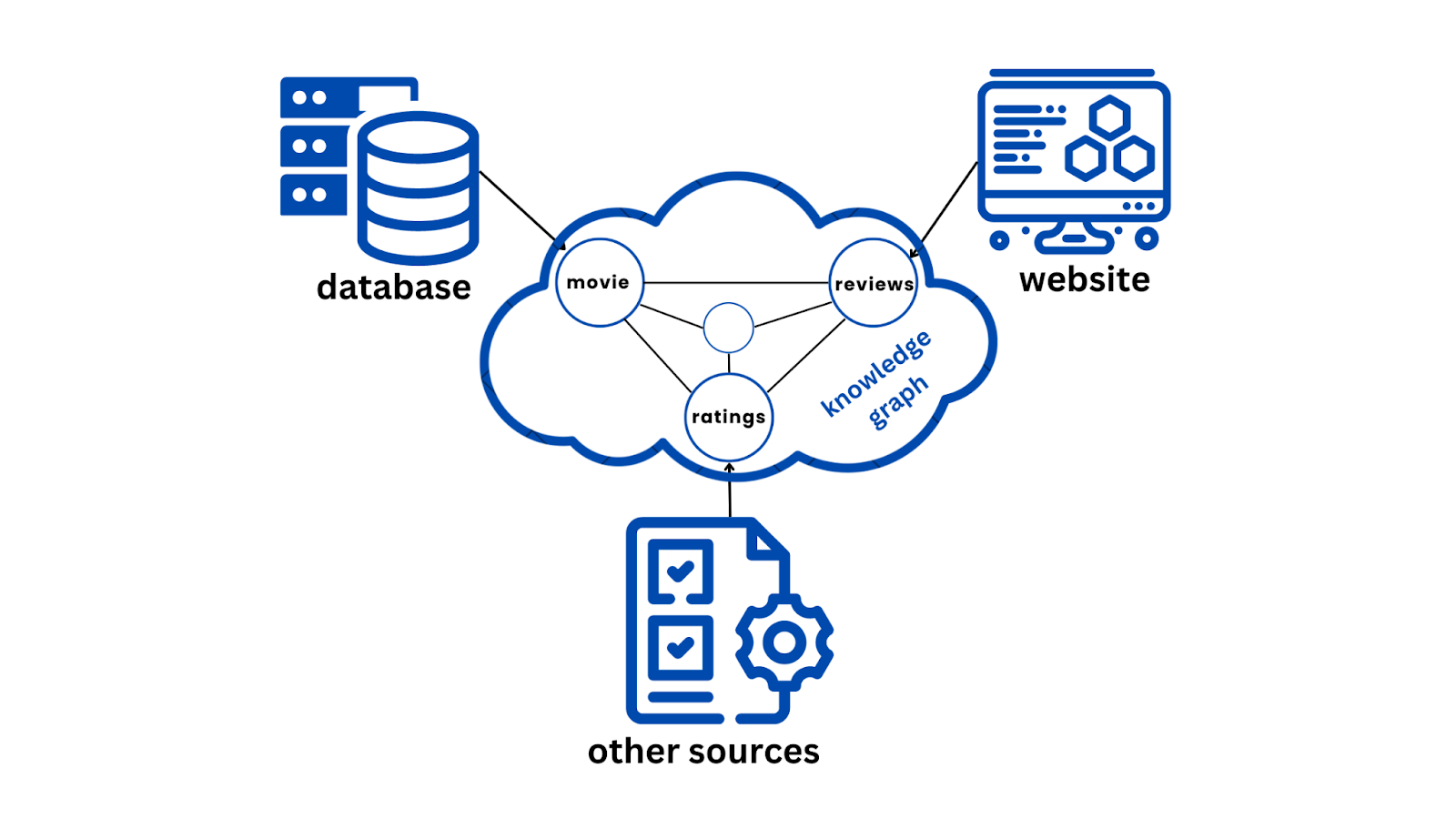 Figure_4_Data_from_multiple_sources_to_KG_7c4cc9fddc.png
Figure_4_Data_from_multiple_sources_to_KG_7c4cc9fddc.png
图4:从多个来源到KG的数据
可扩展性和灵活性
知识图谱是可扩展和灵活的。它们旨在通过有效管理更多的实体、关系和查询来处理增长。
可扩展性可以通过两种主要方式实现:
- 垂直可扩展性:这涉及增加单个系统的能力,例如通过添加更多内存。我们可以升级存储图的数据库系统,以处理更多数据和复杂查询。
- 水平可扩展性:这涉及将数据分布在多个系统上。知识图谱可以跨不同机器分割,每个机器处理图的一部分。
由于它们的基于图的性质,知识图谱可以轻松扩展以处理大量数据,允许轻松的数据集成和修改。
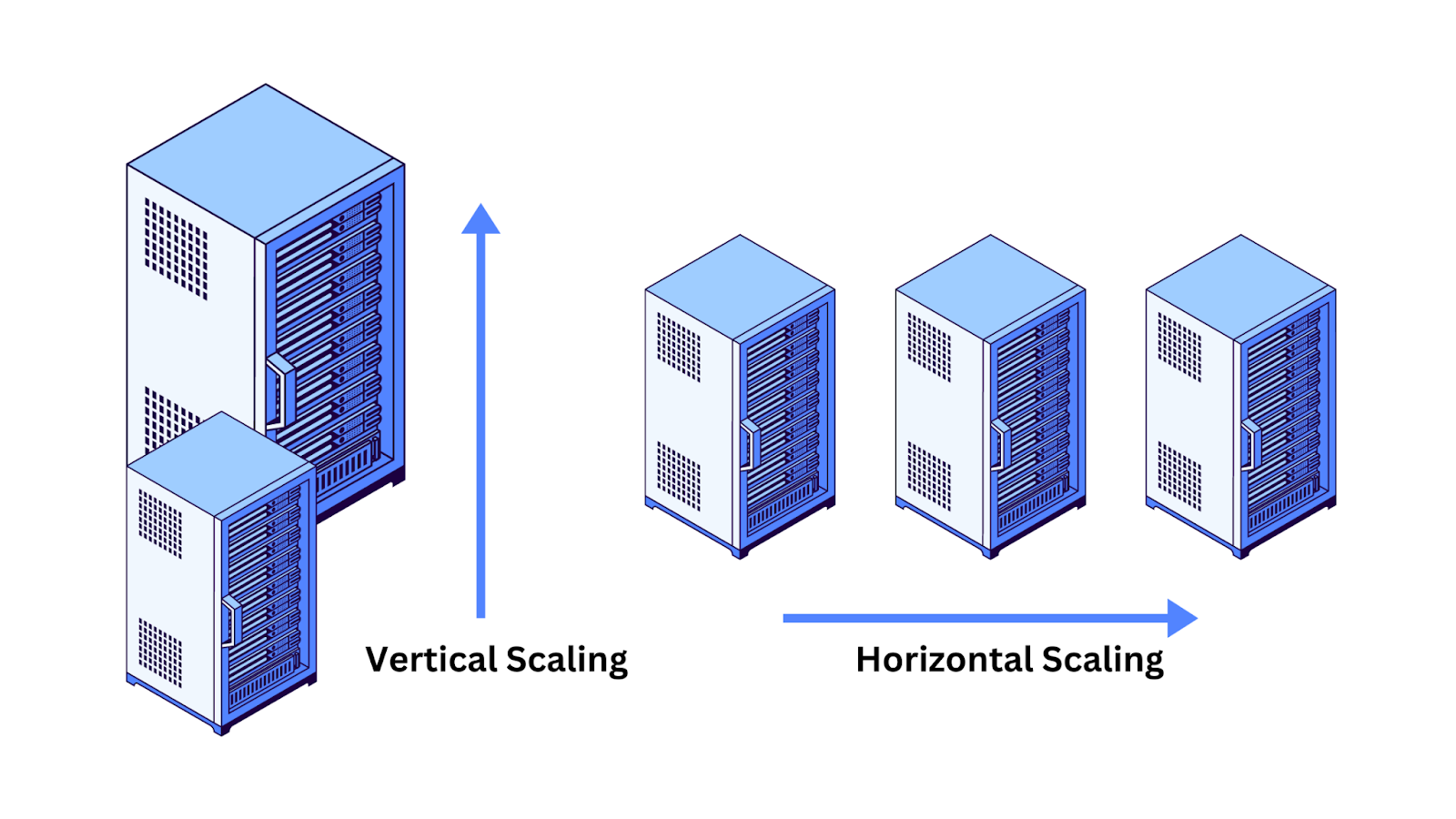 Figure_5_Vertical_and_horizontal_scalability_f2e27e14d7.png
Figure_5_Vertical_and_horizontal_scalability_f2e27e14d7.png
图5:垂直和水平可扩展性
知识图谱与向量嵌入
知识图谱和向量嵌入都是现代数据系统中使用的数据表示,但它们的运作方式根本不同。
知识图谱是结构化表示,其中实体(如人、组织或概念)是节点,这些实体之间的关系是边。这创建了一个类似图的结构,直观和逻辑地映射出不同信息片段如何相互连接。知识图谱在需要清晰、可解释的关系和对显式连接进行推理的场景中表现出色。例如,知识图谱可能显示“阿尔伯特·爱因斯坦”通过“开发”关系与“相对论”相连,提供了一个清晰、可理解的相关概念图。
另一方面,向量嵌入是高维空间中数据的数值表示,通常用于捕获单词、句子甚至整个文档的语义含义。每个实体或信息片段都转换为向量,这些向量之间的距离反映了语义相似性。例如,在向量空间中,单词“国王”和“王后”会靠得很近,反映了它们相关的含义。向量嵌入特别适用于处理非结构化数据,如文本或图像,在这些数据中,目标是捕获不如知识图谱中那样容易定义的微妙、隐式的关系。
知识图谱通常存储在图数据库中,而向量嵌入存储在像Milvus和Zilliz Cloud(Milkus的完全托管版本)这样的向量数据库中。随着人工智能的进步,特别是大型语言模型(LLMs),向量和图数据库可以分别或结合与LLMs集成,构建强大的检索增强生成(RAG)应用。
要探索如何利用知识图谱和向量嵌入创建更先进的RAG应用,请查看这些资源:
构建知识图谱的关键考虑因素
构建知识图谱是一个复杂的过程,涉及从不同来源收集、处理和整合数据,以创建知识的结构化表示。过程中涉及一些关键步骤。
- 数据源
- 提取技术
- 整合和融合
数据源
任何知识图谱的基础都是填充它的数据。数据可以来自不同的来源,每个来源都有自己的结构和格式。了解这些不同的数据源对于构建强大的知识图谱很重要。
- 结构化数据:结构化数据是信息组织成预定义格式的信息,通常存储在关系数据库或电子表格中。它高度组织化,不同信息片段之间的关系清晰。
- 非结构化数据:非结构化数据缺乏预定义结构。它主要以文本、图像或视频的形式存在。处理这种类型的数据很困难,因为它不适合整齐地放入表格或关系数据库中。
- 半结构化数据:半结构化数据介于结构化和非结构化数据之间。它有时是结构化的,有时是非结构化的。JSON文件是半结构化数据的一个好例子,它存储产品信息,键像“名称”、“价格”和“描述”,其中“描述”字段包含自由形式的文本。
提取技术
选择相关数据源后,下一步是提取填充知识图谱所需的信息。我们可以使用不同的技术来识别实体(图中的节点)以及它们之间的关系(边)。
- 自然语言处理(NLP)技术:从文本数据中提取信息。这些技术通过处理非结构化文本并识别实体及其之间的关系来构建知识图谱。
- 机器学习方法:机器学习也可以用来自动化从数据中提取信息。机器学习算法可以通过在标记数据集上训练模型来学习在新数据中发现模式和关系。
整合和融合
下一步是将这些数据整合到知识图谱中。这个过程涉及不同的技术,包括实体解析和数据清理。
- 实体解析:实体解析在知识图谱中找到并合并重复的实体。当数据来自多个来源时,同一个实体(人或地点)以不同方式表示是常见的。实体解析技术,如概率匹配、基于规则的匹配和机器学习方法,找到并链接等价实体。实体解析确保所有对同一实体的引用都链接到知识图谱中的单个节点。
- 数据清理和规范化:在将数据整合到知识图谱之前,清理和规范化数据很重要。数据清理涉及纠正错误、删除重复项和处理缺失或不一致的信息。可以使用句子分割、语音标记和命名实体识别等技术来识别和纠正文本数据中的错误。在规范化中,我们将数据转换为易于整合到知识图谱的标准格式。
使用NLP构建知识图谱
在以下部分中,我们将使用句子分割、依存解析、词性标注和实体识别等NLP技术,从文本中构建知识图谱。本文中使用的数据集和代码可在Kaggle上找到。
导入依赖项和加载数据集
import re
import pandas as pd
import bs4
import requests
import spacy
from spacy import displacy
nlp = spacy.load('en_core_web_sm')
from spacy.matcher import Matcher
from spacy.tokens import Span
import networkx as nx
import matplotlib.pyplot as plt
from tqdm import tqdm
pd.set_option('display.max_colwidth', 200)
%matplotlib inline
# import wikipedia sentences
candidate_sentences = pd.read_csv("../input/wiki-sentences/wiki_sentences_v2.csv")
Candidate_sentences.shape
句子分割
构建知识图谱的第一步是将文本文档分割成句子。然后,我们将只选择那些恰好有一个主语和一个宾语的分割句子。
doc = nlp("the drawdown process is governed by astm standard d823")
for tok in doc:
print(tok.text, "...", tok.dep_)
实体提取
从句子中提取单个词实体很简单。词性(POS)标签使这个任务变得简单。我们的实体将是名词和专有名词。然而,当一个实体跨越多个词时,POS标签是不足够的。需要解析句子的依存树。在创建知识图谱时,节点和连接它们的边是最关键的组成部分。
这些节点将是维基百科句子中存在的实体。将这些项目绑定在一起的连接称为边。我们将以无监督的方式提取这些元素,即,使用句子的语法。
def get_entities(sent):
ent1 = ""
ent2 = ""
prv_tok_dep = "" # dependency tag of previous token in the sentence
prv_tok_text = "" # previous token in the sentence
prefix = ""
modifier = ""
for tok in nlp(sent):
# if token is a punctuation mark then move on to the next token
if tok.dep_ != "punct":
# check: token is a compound word or not
if tok.dep_ == "compound":
prefix = tok.text
# if the previous word was also a 'compound' then add the current word to it
if prv_tok_dep == "compound":
prefix = prv_tok_text + " "+ tok.text
# check: token is a modifier or not
if tok.dep_.endswith("mod") == True:
modifier = tok.text
# if the previous word was also a 'compound' then add the current word to it
if prv_tok_dep == "compound":
modifier = prv_tok_text + " "+ tok.text
if tok.dep_.find("subj") == True:
ent1 = modifier +" "+ prefix + " "+ tok.text
prefix = ""
modifier = ""
prv_tok_dep = ""
prv_tok_text = ""
if tok.dep_.find("obj") == True:
ent2 = modifier +" "+ prefix +" "+ tok.text
# update variables
prv_tok_dep = tok.dep_
prv_tok_text = tok.text
return [ent1.strip(), ent2.strip()]
get_entities("the film had 200 patents")
entity_pairs = []
for i in tqdm(candidate_sentences["sentence"]):
entity_pairs.append(get_entities(i))
entity_pairs[10:20]
输出
 7.png
7.png
图7:实体提取的输出(作者图)
正如你所见,这些实体配对包含一些代词,如“她”、“我们”、“它”等。相反,我们希望有专有名词或名词。我们可以增强get_entities()函数以排除代词。
关系提取
实体提取完成了一半的工作。要构建知识图谱,我们需要边(关系)来连接节点(实体)。这些边是一对节点之间的关系。这些谓词可以通过以下函数从句子中提取。在这里,我们使用了SpaCy的基于规则的匹配。
def get_relation(sent):
doc = nlp(sent)
# Matcher class object
matcher = Matcher(nlp.vocab)
#define the pattern
pattern = [{'DEP':'ROOT'},
{'DEP':'prep','OP':"?"},
{'DEP':'agent','OP':"?"},
{'POS':'ADJ','OP':"?"}]
matcher.add("matching_1", None, pattern)
matches = matcher(doc)
k = len(matches) - 1
span = doc[matches[k][1]:matches[k][2]]
return(span.text)
get_relation("John completed the task")
relations = [get_relation(i) for i in tqdm(candidate_sentences['sentence'])]
创建知识图谱
我们将通过提取的实体(主宾对)和谓词(实体之间的关系)创建知识图谱。
让我们形成一个实体和谓词的数据框:
# extract subject
source = [i[0] for i in entity_pairs]
# extract object
target = [i[1] for i in entity_pairs]
kg_df = pd.DataFrame({'source':source, 'target':target, 'edge':relations})
接下来,我们将使用networkx库从这个数据框创建一个网络。在这个网络中,节点表示实体,而它们之间的边或链接说明了它们的关系。
这将是一个有向图,意味着任何一对节点之间的连接是单向的。关系从一个节点流向另一个节点,而不是双向的。
# create a directed-graph from a dataframe
G=nx.from_pandas_edgelist(kg_df, "source", "target",
edge_attr=True, create_using=nx.MultiDiGraph())
让我们绘制这个网络。
plt.figure(figsize=(12,12))
pos = nx.spring_layout(G)
nx.draw(G, with_labels=True, node_color='skyblue', edge_cmap=plt.cm.Blues, pos = pos)
plt.show()
输出
 Figure_6_KG_with_all_the_relations_f0a06987da.png
Figure_6_KG_with_all_the_relations_f0a06987da.png
图6:包含所有关系的KG
上图所示的结果是使用我们所有的关系创建的。可视化一个关系过多的图变得困难。
因此,最好只使用一些重要的关系来可视化图。现在,让我们一次只取一个关系。让我们从“由...组成”的关系开始:
G=nx.from_pandas_edgelist(kg_df[kg_df['edge']=="composed by"], "source", "target",
edge_attr=True, create_using=nx.MultiDiGraph())
plt.figure(figsize=(12,12))
pos = nx.spring_layout(G, k = 0.5) # k regulates the distance between nodes
nx.draw(G, with_labels=True, node_color='skyblue', node_size=1500, edge_cmap=plt.cm.Blues, pos = pos)
plt.show()
输出
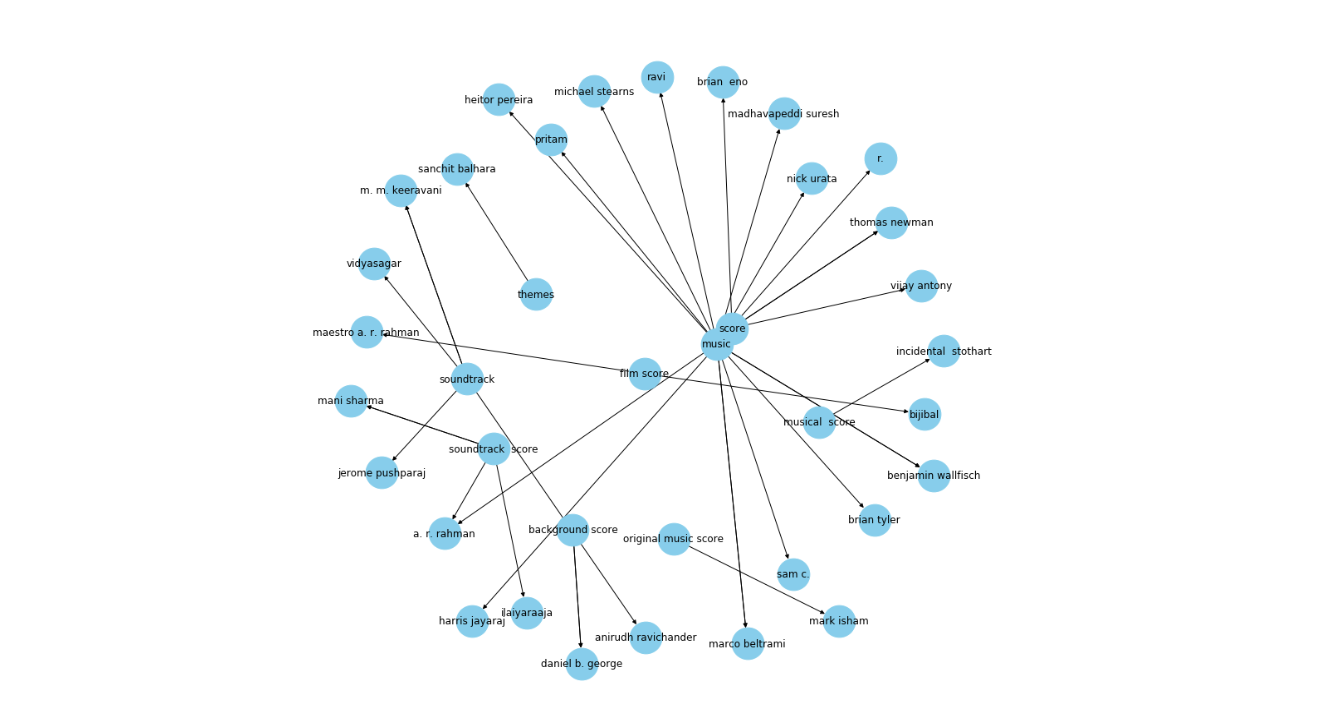 Figure_7_KG_with_one_relation_78a37406c8.png
Figure_7_KG_with_one_relation_78a37406c8.png
图7:只有一个关系的KG
输出揭示了一个更清晰的图。在这里,箭头指向作曲家。例如,Daniel b. George在上图的图中有“背景音乐”和“原声带”等实体与他相连。
让我们看看一些更多的关系。现在,我们将可视化“由...编写”的关系图:
G=nx.from_pandas_edgelist(kg_df[kg_df['edge']=="written by"], "source", "target",
edge_attr=True, create_using=nx.MultiDiGraph())
plt.figure(figsize=(12,12))
pos = nx.spring_layout(G, k = 0.5)
nx.draw(G, with_labels=True, node_color='skyblue', node_size=1500, edge_cmap=plt.cm.Blues, pos = pos)
plt.show()
输出
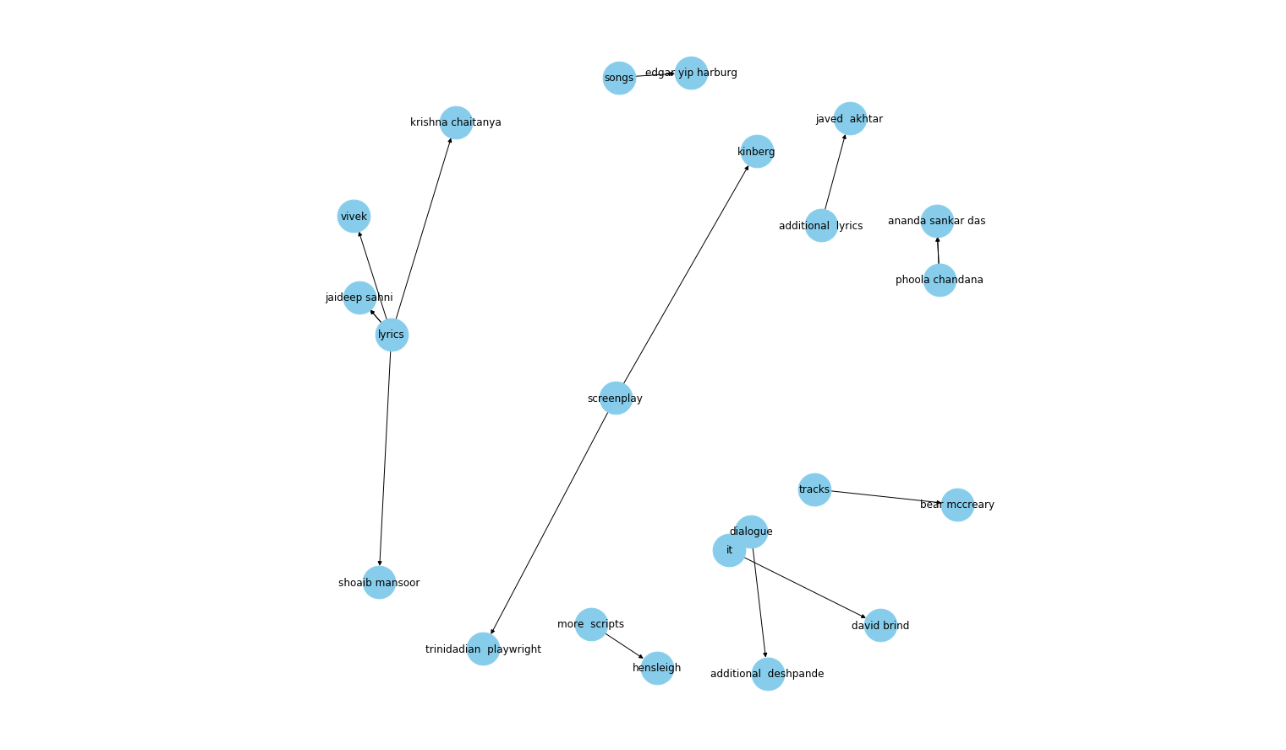 Figure_8_KG_with_one_relation_e15ecb2355.png
Figure_8_KG_with_one_relation_e15ecb2355.png
图8:只有一个关系的KG
这个知识图谱为杰出的抒情诗人之间的联系提供了非凡的洞察,并美观地展示了它们的联系。
让我们看看另一个重要的谓词,即“发布于”的知识图谱:
G=nx.from_pandas_edgelist(kg_df[kg_df['edge']=="released in"], "source", "target",
edge_attr=True, create_using=nx.MultiDiGraph())
plt.figure(figsize=(12,12))
pos = nx.spring_layout(G, k = 0.5)
nx.draw(G, with_labels=True, node_color='skyblue', node_size=1500, edge_cmap=plt.cm.Blues, pos = pos)
plt.show()
输出
 Figure_9_KG_with_one_relation_69a3c415bc.png
Figure_9_KG_with_one_relation_69a3c415bc.png
图9:只有一个关系的KG
这个知识图谱代表了像日期或电影这样的实体,线条代表它们的发布日期“发布于”。现在,让我们看看知识图谱的一些重要应用。
知识图谱的应用
知识图谱由于其能够有意义地表示和连接信息,在不同行业中有广泛的应用。让我们看看它们在一些关键领域的使用情况。
搜索引擎
知识图谱在搜索引擎中最受欢迎的应用之一。它们允许搜索引擎超越简单的关键词匹配,理解用户查询背后的上下文,并提供更全面和信息丰富的搜索结果。今天最受欢迎的两个搜索引擎知识图谱包括谷歌知识图谱和微软的Bing知识图谱。
谷歌的知识图谱:2012年,谷歌推出了其知识图谱,改变了搜索结果的交付方式。知识图谱使谷歌能够理解不同实体之间的关系,并提供更相关的信息。
语义搜索能力:传统搜索引擎依赖关键词匹配返回搜索结果,可能导致不相关的结果。借助知识图谱,搜索引擎可以理解用户查询背后的语义含义,并提供更准确的结果。
推荐系统
知识图谱长期以来为推荐系统提供动力。像Netflix或Spotify这样的流行流媒体服务使用知识图谱向用户推荐内容。这些图捕获了不同实体之间的相互连接信息和关系,如电影、演员和用户偏好。通过分析这些信息,系统可以识别模式并提供更个性化的推荐。
问答系统
虚拟助手和聊天机器人也使用知识图谱准确回答用户查询。使用KG虚拟助手,通过理解查询中提到的实体之间的关系并做出适当响应来解释查询。例如,如果用户询问最新的詹姆斯·邦德电影的导演,助手使用KG识别“詹姆斯·邦德”实体。接下来,它找到最近的电影并确定导演。
商业智能
商业智能(BI)系统使用知识图谱整合和分析不同来源的数据。这使组织能够在其数据中找到模式、趋势和关系,并做出数据驱动的决策,以提高效率并推动业务成功。
知识图谱的好处
知识图谱有许多好处,包括:
- 改善数据上下文化:知识图谱连接相关信息,使人们更容易了解事物之间的关系,并了解大局。
- 增强数据发现:知识图谱使探索复杂数据、识别趋势、发现新见解和建立最初可能不明显的联系变得容易。
- 更好的决策支持:知识图谱帮助组织通过识别数据中的模式和关系来创新、识别新机会,并做出基于证据的决策。
- 灵活性和可扩展性:知识图谱可以随着数据的增长而增长和变化,使它们非常适合信息不断更新的环境。
知识图谱的挑战
除了优势之外,知识图谱也带来了挑战:
- 数据质量和一致性:确保知识图谱中的信息正确和一致可能是具有挑战性的,特别是当结合来自多个来源的数据时。
- 大规模图的可扩展性:随着知识图谱的增长,它们可能变得更具挑战性,尤其是在性能和存储方面。
- 维护和更新:保持知识图谱的最新需要持续的努力,因为必须不断整合新信息,并且可能需要修订旧信息。
- 隐私和安全问题:当包含敏感信息时,隐私和安全成为主要问题。保护数据和控制谁可以访问它很重要。
未来趋势
随着知识图谱技术的进步,我们可以预期它与新工具和应用的整合,帮助我们理解复杂信息。让我们看看一些关键的未来趋势:
与AI和机器学习的整合
随着行业越来越多地采用机器学习,知识图谱技术可能会携手发展。除了作为向算法提供训练数据的有用格式外,机器学习可以快速构建和结构化图数据库,在数据点之间绘制联系。这种整合允许更高级的应用,如预测分析和自动化决策。
此外,随着技术的发展,我们现在可以将结构和语义含义作为向量嵌入存储在知识图谱中。这涉及将实体和关系转换为向量表示,这些向量表示可以用于机器学习模型。这种技术有助于提高预测和推荐的准确性。
去中心化知识图谱
去中心化知识图谱是一个受区块链技术启发的概念。随着区块链的持续增长,人们对去中心化知识图谱的兴趣日益增加,在这种图谱中,数据托管在开放的数据结构上,而不是由单一中央权威控制。
多模态知识图谱
多模态知识图谱通过添加不同类型的数据,如图像、视频和音频,扩展了传统知识图谱的概念。有效的数据管理和使用使KG成为发展中的一个重要主题。通过整合不同类型的数据,多模态知识图谱可以提供实体和关系的更丰富表示。
结论
知识图谱在今天快速增长的数字世界中变得重要。它们提供了信息的结构化和相互连接的表示。知识图谱通过将实体及其关系表示为网络,帮助我们组织、连接和理解大量数据。
知识图谱的演变、扩展和适应新信息的能力使它们对搜索引擎、虚拟个人助理和推荐等应用有价值。然而,必须解决隐私和安全问题,并开发可扩展的解决方案来应对大规模图谱的需求。
 Haziqa Sajid
Haziqa SajidFreelance Technical Writer