



向量库与向量数据库
在人工智能(AI)和机器学习(ML)领域,高效的数据管理对于构建健壮且可扩展的模型至关重要。为满足这一需求,出现了两种关键工具:向量库和向量数据库。虽然它们都处理高维向量数据,但它们服务于不同的目的,并提供独特的优势。在本文中,我们将深入探讨这两种技术的差异、它们的优势和实际应用,为开发者在选择适合其AI项目的正确工具提供全面指南。
向量库和向量数据库的核心区别
目的构建的向量数据库是强大的相似性搜索工具,但也存在其他选项。在向量数据库出现之前,开发者依赖于向量搜索库,如FAISS、ScaNN和HNSW等,进行向量检索任务。
向量搜索库可以快速构建高性能向量搜索原型非常有价值。例如,FAISS是由Meta开发的开源库,旨在进行高效的相似性搜索和密集向量聚类。它可以处理任何大小的向量集合,甚至那些不能完全加载到内存中的集合,并提供评估和参数调整工具。尽管FAISS是用C++编写的,但它提供了Python/NumPy接口,使其易于被许多开发者使用。
然而,向量搜索库是轻量级的近似最近邻(ANN)库,而不是具有有限功能的托管解决方案。虽然它们对小规模或原型系统中的非结构化数据处理可能足够,但将这些库扩展到更多用户的向量变得更加具有挑战性。此外,它们不允许在数据导入期间修改索引数据或查询。
另一方面,向量数据库针对大规模非结构化数据存储和检索进行了优化。它们可以存储和查询数百万甚至数十亿个向量,同时提供实时响应。这种可扩展性证明了它们满足不断增长的业务需求的能力,为开发者提供了一种安心感。
像Milvus这样的向量数据库提供了用户友好的结构化和半结构化数据特性,包括云原生性、多租户和可扩展性。随着数据集和用户基础的增长,这些特性变得越来越重要。
此外,向量数据库在不同的抽象层次上运行,与向量搜索库不同。虽然向量数据库是完整的服务,但ANN库是打算集成到你正在开发的应用程序中的组件。从这个意义上说,ANN库是向量数据库构建的众多组件之一,类似于Elasticsearch是建立在Apache Lucene之上的。
向量库:优化高效相似性搜索
向量搜索算法在实现高维数据高效相似性搜索中起着至关重要的作用。有几种类型的算法,每种算法都有自己的优势和权衡,旨在在保持可接受的准确性和召回率的同时加速向量搜索过程。以下是四种不同类型的向量搜索算法列表:
基于哈希的索引(例如,局部敏感哈希), 基于树的索引(例如,ANNOY), 基于聚类的或聚类索引(例如,乘积量化), 基于图的索引(例如,HNSW)。
向量库是轻量级的近似最近邻(ANN)库,如Faiss、HNSW和ScANN。它们旨在优化密集向量的高效相似性搜索和聚类。
顶级向量搜索库和算法
Faiss(Facebook AI Similarity Search)库 Faiss是由Meta团队开发的向量搜索库。它实现了多种索引,包括Flat索引、Cell-probe方法(IndexIVF索引)、IndexHNSW变体、局部敏感哈希方法和基于乘积量化码的索引。
了解更多关于FAISS | Github | 文档
HNSW(基于图) 分层可导航小世界(HNSW)算法是一种完全基于图的近似最近邻搜索方法,它逐步构建多层结构的分层邻近图,元素使用指数衰减概率分布随机分配到最大层。这种设计,结合从上层开始搜索、链接的尺度分离和选择邻近图邻居的启发式,使HNSW能够实现对数复杂度扩展,并在性能上超越以前的开源仅向量方法,特别是在高召回率和高度聚集的数据方面。
了解更多关于HNSW | Github | 论文
DiskANN(基于图) DiskANN是一种通过利用辅助SSD存储来平衡高准确性和低DRAM占用的ANNS算法。这种方法允许DiskANN每台机器索引更大的向量数据集,使其成为成本效益高且可扩展的选项。SSD存储将使DiskANN能够索引高达10亿个向量,同时保持95%的搜索准确性和低5ms的延迟。相比之下,现有的基于DRAM的算法通常在索引1亿至2亿个向量时达到类似的延迟和准确性水平。DiskANN能够在单台机器上索引比基于DRAM的解决方案大5-10倍的数据集,为不同领域中可扩展和准确的向量搜索开辟了新的可能性,而无需昂贵的DRAM资源。
了解更多关于DiskANN | Github
ANNOY Annoy(近似最近邻哦耶)采用基于树的方法进行近似最近邻搜索,使用一系列二叉树作为其核心数据结构。对于那些熟悉机器学习中的随机森林或梯度提升决策树的人来说,Annoy可以被视为这些算法的自然扩展,但应用于近似最近邻搜索而不是预测任务。
虽然HNSW建立在连接的图和跳过列表上,但Annoy的关键思想是重复划分向量空间,并只搜索这些分区的一个子集以查找最近邻。这种基于树的索引方法提供了搜索速度和准确性之间的独特权衡,使Annoy成为需要在这两者之间取得平衡的应用的有力选择。
了解更多关于ANNOY | Github | 文档
NVIDIA CAGRA CAGRA是一种使用GPU并行性进行近似最近邻搜索的图构建方法。与HNSW中使用的迭代CPU方法不同,CAGRA首先使用IVFPQ或NN-DESCENT创建初始密集图,其中节点有多个邻居。然后它对较不重要的边进行排序和修剪,优化图结构以实现高效的GPU加速遍历。通过采用GPU友好的构建过程,CAGRA旨在充分利用现代GPU的并行处理能力,以进行更快的高维最近邻搜索。
了解更多关于CAGRA | 文档 | 论文
向量数据库:针对生产用例优化
向量数据库是设计用来高效存储、索引和查询向量数据的解决方案。它们特别适合大规模生产应用。
向量数据库的主要优势:
可扩展性:向量数据库建立在处理大量高维数据的能力上,允许随着数据增长跨多台机器水平扩展。生产工作负载:向量数据库可以通过upsert、删除等不断更改您的数据,并自动更新索引以确保查询性能。集成数据管理:向量数据库内置了数据管理、查询和结果检索工具,简化了集成并加速了开发时间。
为了说明向量库和向量数据库在抽象上的差异,请考虑向向量数据库中插入一个新的非结构化数据元素。在Milvus中,这个过程是直接的:
from pymilvus import Collectioncollection = Collection('book')mr = collection.insert(data)
你可以用仅仅三行代码轻松地向Milvus中插入数据。相比之下,像FAISS或ScaNN这样的向量搜索库缺乏这种简单性,通常需要在某些检查点手动重新创建整个索引以适应新数据。即使这是可能的,向量搜索库仍然缺乏使向量数据库对大规模应用非常宝贵的可扩展性和多租户特性。
虽然向量搜索库对原型和小规模应用可能有用,但向量数据库更适合不断增长的数据集和用户基础的生产环境。
通过了解这两种方法的优势和局限性,开发者可以做出明智的决策,并利用最合适的工具来满足他们的向量搜索和非结构化数据管理需求。
选择合适的工具:性能与可扩展性
在选择向量库和向量数据库之间时,决策通常归结为性能和可扩展性之间的权衡。以下是一个简单表格,列出了一些关键差异。
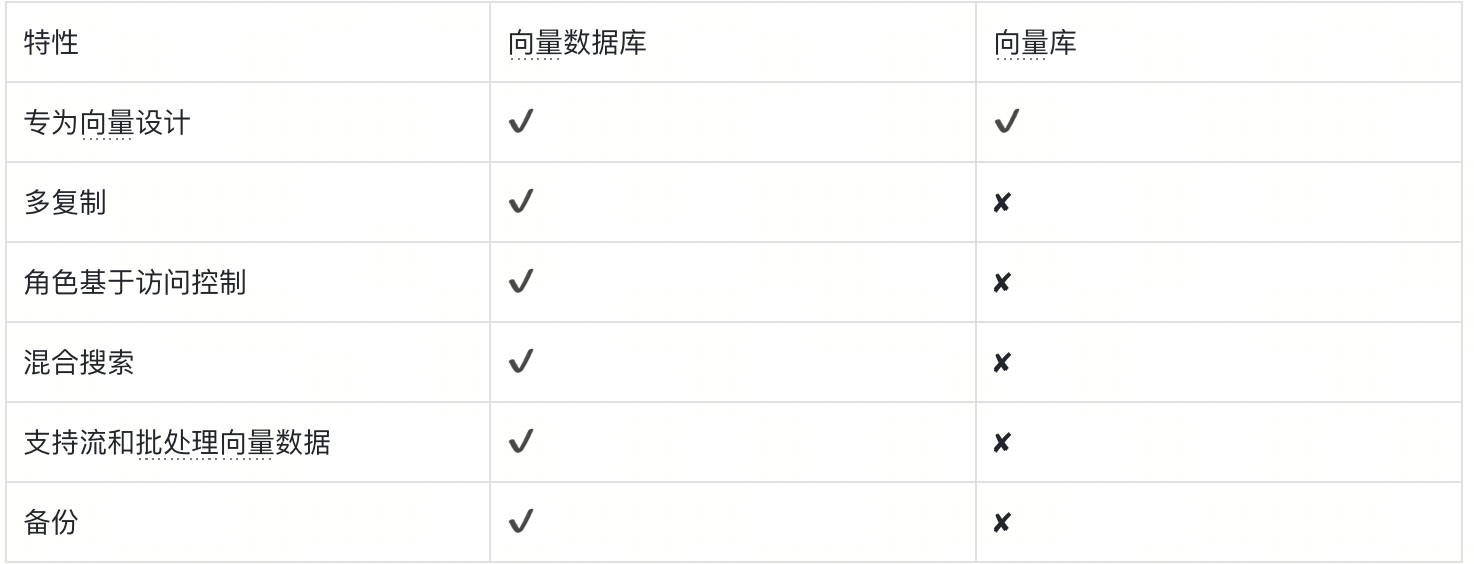 49.png
49.png
向量库:适合原型设计或不经常变化的数据集。
向量数据库:优化了大规模、高维数据的高效存储、检索和管理,使它们非常适合大规模的AI开发和部署。
结论: 随着人工智能和机器学习不断推进创新的边界,高效管理高维向量数据仍然是一个关键挑战。虽然向量库和数据库在这一领域都发挥着重要作用,但了解它们的优势和局限性对于利用合适的工具至关重要。
例如FAISS、Annoy和HNSW等向量库,在提供高性能的相似性搜索和向量聚类能力方面表现出色。这些轻量级库非常适合原型设计、小规模应用以及数据集相对静态且不需要频繁更新的场景。
另一方面,像Milvus这样的向量数据库,旨在生产环境中蓬勃发展,这些环境拥有大规模且不断增长的数据集和用户基础。凭借其可扩展性、集成的数据管理特性,以及无缝处理频繁更新的能力,向量数据库使组织能够轻松开发和部署能够自如扩展的AI解决方案。
最终,选择向量库还是向量数据库,取决于你的项目的具体需求、数据集的大小和动态特性,以及你需要在性能和可扩展性之间取得的平衡。
 Shanika W.
Shanika W.Freelance Technical Writer


