向量数据库与图数据库
在数据驱动的世界中,高效管理、存储和分析大量信息的能力变得至关重要。随着数据复杂性和体积的增长,传统数据库系统常常难以满足现代需求。这导致了专门数据库技术的出现,每种技术都旨在特定场景和数据类型中表现出色。
近年来受到关注的两种数据库技术是向量数据库和图数据库。尽管两者都为处理复杂数据结构提供了强大的能力,但它们服务于不同的目的,并在不同的用例中表现出色。
本文将全面比较向量数据库和图数据库,帮助您理解它们的根本差异、优势和理想应用。通过探索它们的独特特性、查询机制和性能属性,您将拥有知识来做出关于哪种数据库技术最适合您特定需求的明智决策。让我们从向量数据库开始。
什么是向量数据库?
向量数据库是一种专门设计的数据库系统,旨在高效存储、管理和查询高维向量数据。这些数据库将数据点表示为多维空间中的数学向量。每个维度对应数据的特定特征或属性。查看下面的图像。它说明了向量数据库如何在高维空间中表示不同的对象。
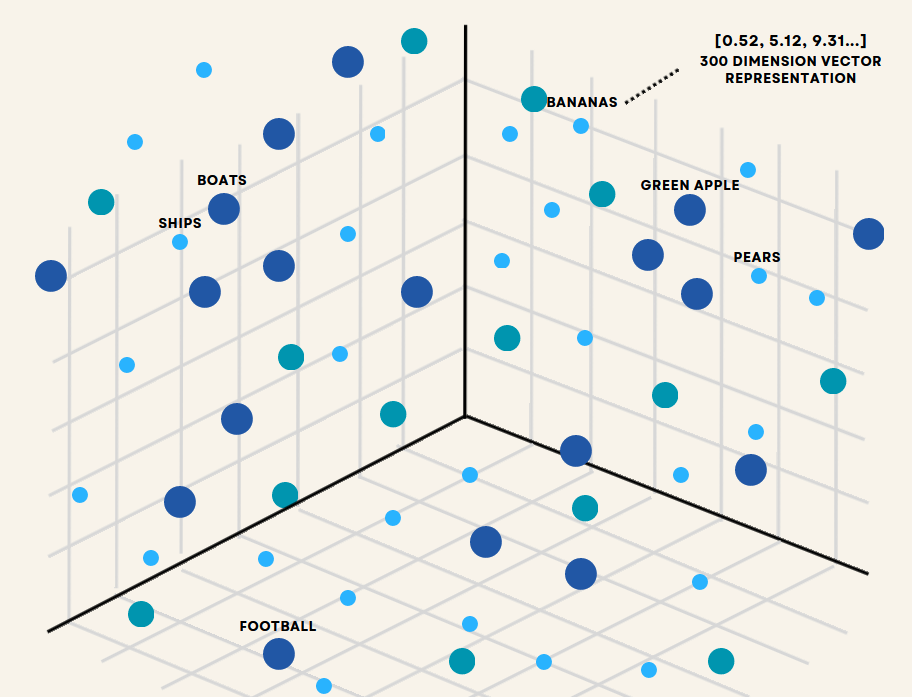 Fig_1_Data_representation_in_a_vector_database_28e36a7b79.png
Fig_1_Data_representation_in_a_vector_database_28e36a7b79.png
图1 - 向量数据库中的数据表示
在插图中,每个项目都被编码为一个数字向量 - 在这种情况下,如右上角所示,是一个300维向量表示。点的位置反映了语义关系,相似的概念聚集在一起(注意“船”和“船”彼此靠近)。这种空间排列允许基于它们在向量空间中的相对位置,快速准确地比较数据点之间的相似性。使它们成为涉及机器学习、人工智能和复杂数据分析的应用程序的理想选择。
关键特性
- 高维数据支持:向量数据库可以高效处理具有数百或数千维度的数据。
- 高效相似性搜索:它们擅长快速找到给定查询向量的最相似项。
- 近似最近邻(ANN)算法:这些数据库通常使用ANN算法来平衡搜索速度和准确性。
- 索引结构:使用专门的索引方法,如HNSW(层次导航小世界)或IVF(倒排文件),以优化搜索性能。
- 可扩展性:向量数据库旨在处理大规模数据集和高查询量。
常见用例
由于您已经了解了向量数据库及其特性,让我们看看它们在各种现实世界场景中的应用。
- 推荐系统:向量数据库擅长根据用户偏好和行为推荐产品、内容或服务。例如,流媒体服务可能会将用户的观看历史和内容特征编码为向量。当用户完成一个节目时,系统可以迅速查询向量数据库以找到类似内容,提供个性化推荐,保持观众的参与度。
- 图像和视频搜索:找到视觉上相似的图像或视频帧是向量数据库的另一项优势。这是通过反向图像搜索完成的。例如,像Pinterest这样的社交媒体平台实现了视觉搜索功能,用户可以上传图像或选择图像的一部分。平台将此输入转换为向量,并在数据库中搜索视觉上相似的内容。这使用户能够根据视觉输入发现相关图像、产品或想法,而不仅仅依赖于文本描述。
- 自然语言处理(NLP):在NLP中,向量数据库促进语义搜索、文本分类和语言翻译。现代搜索引擎将用户查询和网络内容转换为向量嵌入,允许搜索引擎匹配语义含义而不仅仅是关键词。
- 异常检测:向量数据库识别异常模式,用于欺诈检测或系统监控。在金融领域,银行可能会将交易详情(如金额、地点、时间和商户类型)编码为向量。然后,系统可以迅速将新交易与向量数据库中存储的历史模式进行比较。与典型用户行为显著偏离的交易将被标记以供审查。
有许多向量数据库,但它们在可靠性方面各不相同。就GitHub星数而言,最受欢迎的向量数据库是Milvus,它也有一个完全托管的云版本。其他向量数据库包括Chroma、Vald等。
现在我们已经了解了向量数据库,让我们转向图数据库。
什么是图数据库?
图数据库是一种专门设计的数据库系统,旨在使用图结构存储、管理和查询数据。这些数据库将数据表示为节点(实体)和边(实体之间的关系),允许高效遍历和分析复杂的相互连接的数据。查看下面的图像。它说明了图数据库如何表示不同实体之间的关系。
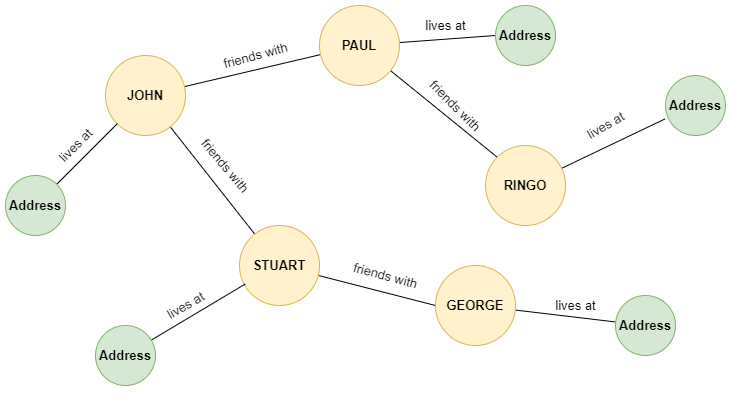 Fig_2_Data_representation_in_a_graph_database_d07f277aeb.png
Fig_2_Data_representation_in_a_graph_database_d07f277aeb.png
图 2 - 图数据库中的数据表示
在上述插图中,有一个相互连接的节点网络,代表人和地址。桃色节点代表个人,银色节点代表地址。连接这些节点的线条显示关系,标签如“与...为朋友”在人之间,以及“居住在”连接人和他们的地址。这种结构允许直观地建模现实世界的关系,并根据这些连接启用强大的查询功能。例如,您可以通过跟随图中的相关边轻松追踪John的朋友圈或找出George住在哪里。
关键特性
- 关系优先方法:图数据库优先考虑数据点之间的连接,使它们非常适合高度互联的数据。
- 灵活的模式:它们可以轻松适应变化的数据结构,而不需要预定义的模式。
- 高效的遍历:图数据库擅长快速导航复杂关系,甚至跨越多个分离度。
- 本地图处理:它们使用针对图操作优化的专用算法,如最短路径计算和中心性度量。
- ACID合规性:许多图数据库支持ACID(原子性、一致性、隔离性、持久性)属性以确保数据完整性。
常见用例
已经了解了图数据库及其特性,让我们探索它们在各种现实世界场景中的应用。
- 社交网络分析:图数据库非常适合建模和分析社交联系。例如,社交媒体平台可能使用图数据库存储用户配置文件作为节点和友谊作为边。这种结构允许在网络内高效推荐朋友、影响力分析和社区检测。
- 欺诈检测:在金融领域,图数据库可以揭示复杂的欺诈模式。通过将交易、账户和个人表示为相互连接的节点,可能在传统系统中被忽视的可疑活动变得显而易见。例如,银行可以使用图数据库识别循环资金流动或不寻常的联系模式,这可能表明洗钱。
- 知识图谱:像Google这样的公司使用图数据库来支持他们的知识图谱,它代表现实世界的实体及其关系。这使得搜索结果更智能,并为Google的信息框等功能提供支持,为用户提供有关人、地点和事物的上下文信息。
- 供应链管理:图数据库模拟复杂的供应链,跟踪货物从制造商到最终消费者的流动。这使公司能够优化路线、识别瓶颈,并进行假设分析,以提高其供应链的效率和韧性。
有几种流行的图数据库可供选择,每种都有其自身的优势。它们包括Neo4j、Amazon Neptune、JanusGraph、OrientDB、WhyHow等。
到现在为止,您已经了解了向量和图数据库以不同的方式存储数据。但这并不是两者之间唯一的区别。
向量和图数据库之间的主要区别
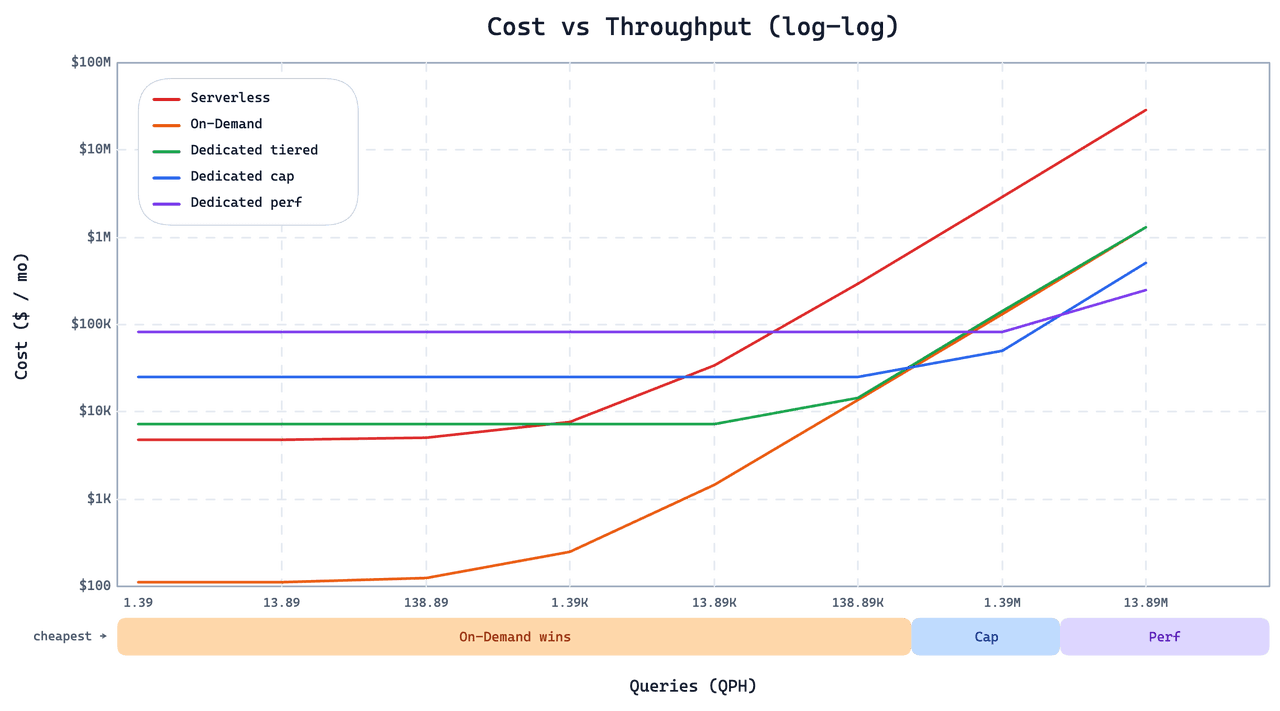
理解向量和图数据库之间的根本区别对于为您的具体数据需求选择正确的技术至关重要。让我们从各个维度对它们进行比较:
数据结构和存储
数据表示和存储构成了任何数据库技术的基础。在向量数据库中,数据点被表示为高维向量,每个向量捕获数据的多个属性。
向量数据库:
- 数据表示:向量数据库将数据表示为高维向量。每个向量由多个维度组成,对应于数据的各个属性。例如,一个向量可能编码图像的特征,每个维度代表一个特定的特征,如颜色或纹理。
- 存储:这些数据库将向量存储在优化高维数据的专用数据结构中,如倒排文件或层次导航小世界(HNSW)图。
- 访问:向量数据库中的数据检索基于相似性搜索。给定一个查询向量,数据库可以快速找到并返回向量空间中最接近它的向量,通常使用近似最近邻(ANN)算法来平衡速度和准确性。
相比之下,图数据库将数据表示为节点和边,使它们成为建模相互连接实体及其关系的理想选择。
图数据库:
- 数据表示:图数据库将数据表示为节点和边。节点对应于实体,而边代表实体之间的关系。这种模型特别适合具有复杂互联的数据,如社交网络或交通图。
- 存储:数据存储在图结构中,节点和边通常被索引以便于遍历和查询处理。许多图数据库使用邻接表或矩阵表示来管理关系。
- 访问:图数据库的查询侧重于遍历图。查询涉及寻找路径、子图或连通分量,利用图中存储的丰富关系数据。
查询和检索
数据结构化和存储后,下一个关键方面是如何有效地查询和检索这些数据。向量数据库擅长相似性搜索,这对于推荐系统等应用程序至关重要。
向量数据库:
- 查询类型:向量数据库针对相似性搜索进行了优化,例如找到查询向量的最近邻居。这些查询在异常检测等应用程序中至关重要。
- 索引机制:向量数据库使用专门的索引方法,如HNSW和倒排文件,以加快相似性搜索。这些索引技术允许高效检索高维数据,平衡速度和准确性。
另一方面,图数据库在基于关系查询方面表现出色,例如最短路径计算。
图数据库:
- 查询类型:图数据库擅长处理涉及关系和路径的查询,例如最短路径计算、模式匹配和网络分析。这些查询对于社交网络分析和欺诈检测等应用程序至关重要。
- 索引机制:图数据库使用各种索引机制,包括邻接表、哈希图和B树,以优化遍历和查询性能。这些索引使得复杂关系和大型图结构的高效导航成为可能。
性能和可扩展性
性能和可扩展性决定了数据库如何处理大规模数据和高查询负载。向量数据库采用近似最近邻(ANN)算法等技术,确保即使在数据集庞大的情况下也能快速准确地进行相似性搜索。
向量数据库:
- 处理大规模数据:向量数据库旨在管理大规模数据集,通常包含数百万或数十亿个高维向量。它们采用高效的索引和分区策略,在高查询负载下保持性能。
- 性能基准:向量数据库通常在相似性搜索方面表现出色,即使在庞大的数据集上也能实现。它们利用ANN算法和分布式计算技术,提供快速的查询响应。
与此同时,图数据库针对处理庞大的互联数据进行了优化,通过先进的索引和遍历算法保持性能。
图数据库:
- 处理大规模数据:图数据库擅长管理庞大的互联数据集。它们使用先进的索引和分区方法,确保高效的查询处理,即使在庞大的图结构中也是如此。
- 性能基准:图数据库在涉及多个跃点或遍历的复杂查询中表现出色。它们针对关系和连接至关重要的场景进行了优化,在重查询负载下保持响应性。
灵活性和适应性
对于现代应用程序而言,适应不断演变的数据模型的灵活性和适应性至关重要。向量数据库提供了直接的模式更改,使得添加或修改数据维度变得容易。
向量数据库:
- 模式更改:向量数据库在模式更改方面非常灵活。由于数据以向量形式表示,添加或修改维度是直接的,允许数据库适应新的数据类型和特征。
- 支持不同数据类型:虽然主要关注高维数值数据,但通过将不同类型的数据编码为向量表示,向量数据库可以适应各种应用程序。
图数据库在模式灵活性方面表现出色,允许动态添加节点和关系,而不需要预定义的模式,这对于数据结构快速变化的应用程序特别有益。
图数据库:
- 模式更改:图数据库非常灵活,可以适应不断变化的数据结构,而不需要预定义的模式。新的节点和关系可以动态添加,使它们成为具有变化数据模型的应用程序的理想选择。
- 支持不同数据类型:图数据库支持多种数据类型,包括结构化、半结构化和非结构化数据。它们灵活的模式和丰富的关系建模能力使它们能够适应各种数据需求。
有了这些差异,您可能认为向量和图数据库没有混合使用案例。但事实并非如此。让我们看看一些结合这两种技术可以产生最佳结果的场景。
向量和图数据库混合使用案例
探索了向量和图数据库的独特优势后,让我们看看结合这些技术可以产生强大解决方案的场景。
- 混合搜索引擎:将用于语义搜索的向量数据库与用于基于关系的查询的图数据库集成,增强了搜索能力,提供了更相关和具有上下文意识的结果。
- 高级推荐系统:使用向量数据库建模用户偏好和图数据库捕获社交联系,提高了推荐准确性和用户参与度。
- 多模态应用:利用向量数据库处理像图像和文本这样的高维数据,结合图数据库管理关系,创建了强大的多模态系统。
了解了向量和图数据库的所有知识后,最大的问题变成了知道何时使用向量数据库、图数据库或两者都使用。
为您的需求选择正确的数据库
选择正确的数据库对于优化数据管理和性能至关重要。让我们总结一下在做出这一决定时需要考虑的关键因素。
- 数据类型:确定您的数据主要是高维向量还是相互连接的实体。
- 查询需求:确定您需要执行的查询类型,例如相似性搜索或关系遍历。
- 可扩展性需求:评估您的可扩展性需求,包括数据量和查询负载。
- 灵活性:考虑您的数据模型变化频率以及对模式灵活性的需求。
决策框架:
- 评估数据特征:评估您的数据是否最好表示为向量或图。
- 分析查询模式:确定主要的查询类型,并选择在这些查询中表现出色的数据库。
- 评估性能需求:考虑每种数据库在您特定用例的性能基准。
- 考虑未来增长:计划可扩展性和适应性,以适应未来的数据和查询增长。
示例决策场景:
- 场景1:一家公司需要为流媒体服务构建推荐系统。鉴于相似性搜索和个性化推荐的重要性,向量数据库将是理想的选择。
- 场景2:社交媒体平台希望分析用户连接并推荐朋友。由于图数据库在建模和遍历社交网络方面的优势,它将是最好的选择。
- 场景3:电子商务平台旨在通过结合文本、图像和用户行为来改进产品搜索。使用向量和图数据库的混合方法可能提供最全面的解决方案。
结论
向量数据库擅长处理高维数据和执行相似性搜索,使它们成为推荐系统和自然语言处理等应用程序的理想选择。另一方面,图数据库旨在处理互联数据,在涉及关系和路径的查询中表现出色,使它们成为社交网络分析和欺诈检测的完美选择。
在选择向量和图数据库之间时,必须考虑您的数据类型、查询需求、可扩展性需求和灵活性。通过了解每种数据库技术的独特优势并评估您的特定用例,您可以做出满足数据管理需求的明智决策。
 Denis Kuria
Denis KuriaFreelance Technical Writer