



理解视觉变换器(ViT)的初学者指南
视觉变换器(ViT)是基于变换器架构的神经网络模型,专为处理图像数据而设计。在变换器中,注意力是一种机制,帮助模型专注于输入数据的相关部分,以更好地理解和生成预测,使它们能够更具有上下文感知和灵活性地处理信息。视觉变换器将注意力概念应用于图像,以从广阔的画布中区分关键元素。注意力还允许 ViT 捕捉全局关系并超越现有的视觉模型。
全局注意力将变换器模型与常规的卷积神经网络(CNN)区分开来。CNN 从相邻像素中捕获和聚合信息,只捕获局部关系。ViT 在更广泛的画布上工作,每个图像段都进行全面比较。虽然这种方法增加了计算复杂性,但 ViT 显著提高了性能。
视觉变换器在目标检测、图像分类和语义分割任务中表现出色。本博客将详细探讨 ViT 架构,并简要解释如何使用 Hugging Face 模型实现它。
什么是变换器?
Vaswani 等人在论文 "Attention Is All You Need"(2017)中引入了变换器架构。变换器模型引入了自注意力机制,允许它在输入数据的不同部分之间建立关系上下文。
变换器在自然语言处理(NLP)中获得了巨大 popularity,特别是由于它们对数据的深入理解以及令人印象深刻的结果。它们使用注意力机制来推导句子中单词之间的关系。这种方法使它们能够收集文本的语义理解,并生成上下文感知、信息丰富的向量嵌入,从而在 AI 建模中获得准确的结果。
变换器如何工作?
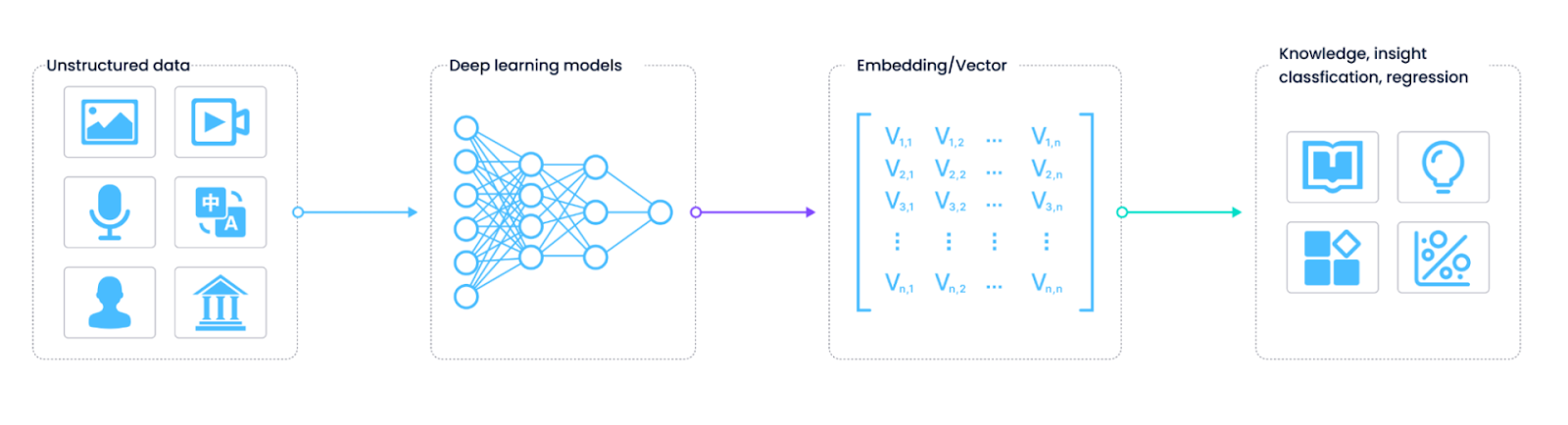
构建语义关系需要将数据点映射到共享的语义 n 维空间。每个数据点在空间中位于特定位置,不同点之间的距离决定了它们的关系。
在 NLP 中,第一步是将自然语言文本分解为标记。然后这些标记被转换为代表它们在语义空间中位置的嵌入。嵌入的创建方式是相似的标记保持接近。
例如,像 'car'、'motorcycle' 和 'airplane' 这样的单词将被映射得更接近彼此,因为它们都属于交通工具类别。接近的数据点也被称为具有更高的对齐分数。
 Figure_1_How_vector_embeddings_are_created_a49508b17d.png
Figure_1_How_vector_embeddings_are_created_a49508b17d.png
向量嵌入的创建方式
然而,语言是复杂的,术语的含义通常根据它们的上下文而变化。变换器根据文本的上下文在潜在空间内移动单词嵌入。像 BERT 这样的流行模型由多个编码器层组成,每个层都应用注意力机制来修改嵌入值。当文本句子通过编码器时,每个单词都与其余标记进行比较,其嵌入根据提供的上下文进行修改。
一旦生成了嵌入,它们就会被传递到最终的头部层,该层根据任务进行预测。头部层的构建取决于任务;例如,它将为分类任务输出类别概率,或者为 seq-2-seq 建模任务输出另一个序列。
什么是视觉变换器?
虽然变换器主要用于语言任务,但一种称为视觉变换器(ViT)的变体用于建模图像数据。变换器背后的一般直觉是,数据点根据它们在数据集中的位置和上下文具有某种重要性水平。例如,某些单词为整个句子提供了比其他单词更多的意义,应在建模期间优先考虑。对于更大的图像中的像素或补丁也是如此。
图像可能包含多个对象,每个对象根据任务的不同而具有不同的价值。视觉变换器使用注意力机制捕获图像补丁之间的关系。
 Figure_2_Applying_attention_to_images_Source_22146a1919.png
Figure_2_Applying_attention_to_images_Source_22146a1919.png
将注意力应用于图像
ViT 的方法与处理语言数据相同,但我们将图像补丁传递给变换器架构,而不是标记。这种方法比传统的 CNN 捕获了更多信息,并提供了更好的建模图像数据的方法。
视觉变换器的挑战
将变换器用于图像数据增加了某些计算挑战,因为与单个句子相比,图像的尺寸要大得多。一个小尺寸为 255 x 255 的图像包含 65,025 个像素。由于自注意力机制将每个像素与整个数据集进行比较,CPU 计算将不得不执行大约 65,025 x 65,025 = 4.2 x 10^9 次比较操作,这是计算上的噩梦。为了解决这个问题,原始 ViT 论文的作者建议将图像划分为补丁,并将每个补丁视为传递给变换器的输入。这种方法效率更高,并捕获了足够的信息以进行有效的训练。
视觉变换器(ViT)架构
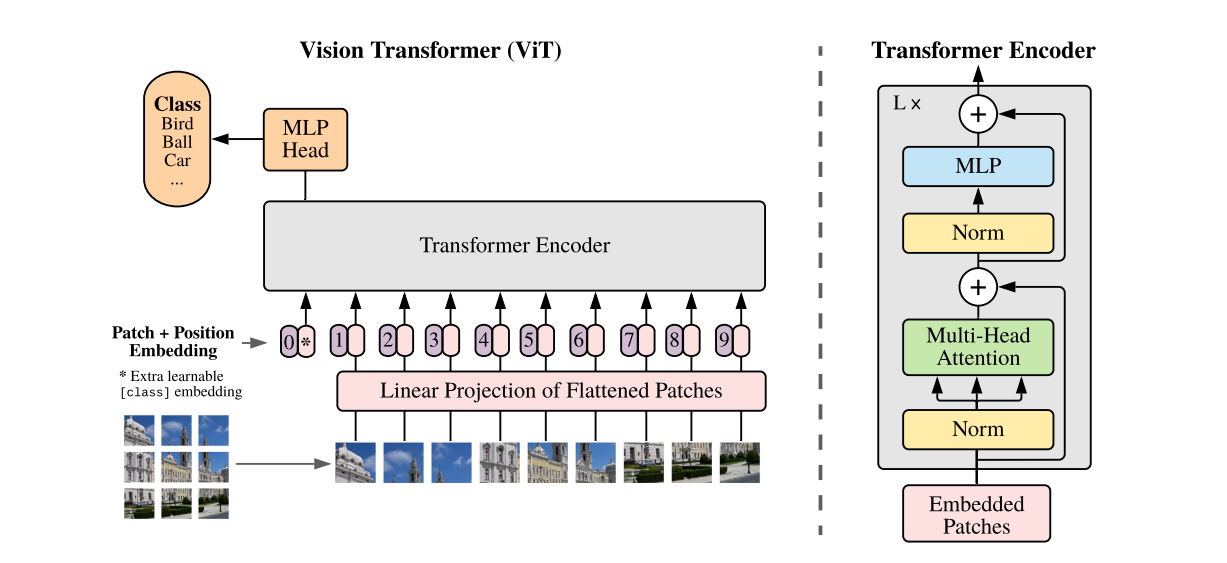
ViT 编码的第一步是生成图像补丁的扁平数组。这些补丁被传递给初始的前馈线性投影层。该层将扁平补丁投影到嵌入空间,以便变换器以后可以处理它们。
 Figure_3_Vi_T_Architecture_Source_5f8b46cff2.png
Figure_3_Vi_T_Architecture_Source_5f8b46cff2.png
ViT 架构
一旦生成了通用图像嵌入,还需要两个步骤。首先,将类别标记(CLS)添加到嵌入中。这种方法是从 BERT 网络中采用的,该网络使用此额外标记进行可学习嵌入。最初,此标记是空白的,不包含任何信息。然而,当它通过变换器层时,它聚合了来自所有补丁的信息,最终输出代表整个原始图像。此标记用于分类任务,并传递给分类器以进行最终预测。
第二步是对补丁嵌入应用位置编码,因为变换器没有任何默认机制来识别数据中的序列。序列很重要,因为混乱的补丁将误导原始图像,并导致学习效果不佳。位置嵌入在预训练期间学习,与补丁嵌入的大小相同,并直接添加到补丁嵌入中。
变换器编码器
编码器是整个变换器模型背后的主要驱动力。它由三个主要组件组成:
- 规范层:层规范化有助于缩放其他主要层的激活,并为训练提供稳定性。缩放激活还允许轻松的权重更新和更快的训练。
- 多头注意力:该层计算不同图像补丁之间的关系。多头意味着多个注意力计算同时进行。每个头部都有自己的参数,并稍微不同地处理输入。直观地说,每个头部从输入中捕获不同的信息,并计算注意力分数,这成为值向量的权重。每个头部的输出被连接,形成一个最终的丰富表示。
- 多层感知器(MLP):这个基本的前馈神经网络引入了非线性,并成为变换器块的输出。将其与 softmax 层结合使用,可以输出分类标签。
视觉变换器(ViT)的实现
现在我们已经讨论了视觉变换器的工作原理,我们可以从 Hugging Face 目录中实现一个模型。在这个教程中,我们将尝试使用 'Painting Style Classification' 数据集对 ViT 模型进行微调。您可以在这个 Google Colab 笔记本中访问此实现的完整代码。
我们首先安装并导入相关库。
pip install datasets transformers[torch]
from datasets import load_dataset, load_metric
from transformers import ViTImageProcessor, ViTForImageClassification, TrainingArguments, Trainer
import torch
import numpy as np
接下来,我们将从 HuggingFace datasets 库中加载数据集。
# pass config = 'mini' instead of 'full' for the smaller version
ds = load_dataset('keremberke/painting-style-classification', 'full')
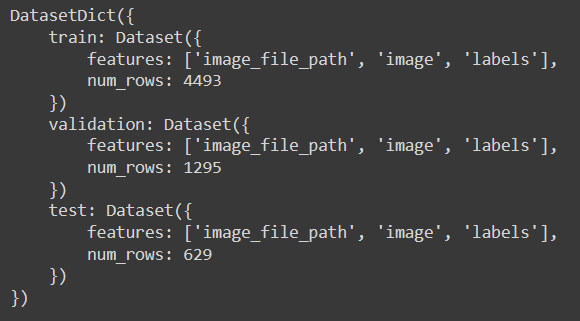
我们可以通过打印 ds 对象来了解数据集配置。
ds
 The_printed_result_1_ff70ec5667.png
The_printed_result_1_ff70ec5667.png
打印结果显示数据集包含图像和标签。此外,它在训练集中有 4493 张图像,在验证集中有 1295 张,在测试集中有 629 张。理想情况下,数据集应该包含数万张图像以进行适当的训练,这将足以用于此演示。
让我们查看一个示例图像及其标签。
data_index = 4000
example = ds['train'][data_index]['image']
labels = ds['train'].features['labels']
example # display image
# print label of above image
labels.int2str(ds['train'][data_index]['labels'])
 Figure_4_example_image_and_its_label_Label_Romanticism_c87ba44c31.png
Figure_4_example_image_and_its_label_Label_Romanticism_c87ba44c31.png
图 4 - 示例图像及其标签。标签 - ‘Romanticism’
一旦加载了数据集,我们可以加载模型。该模型有两个目的。首先,它包含具有正确配置的预处理器,以转换输入图像并将其与模型的要求对齐。其次,它包含包含预训练权重的模型架构。我们将首先初始化预处理器并创建一个处理管道。
# Load the pretrained ViT model from HuggingFace
model_name_or_path = 'google/vit-base-patch16-224-in21k'
processor = ViTImageProcessor.from_pretrained(model_name_or_path)
以下代码使用 Hugging Face 的内置功能,并创建了一个实时管道。这意味着仅在访问图像时才将处理应用于图像。这节省了内存和不必要的处理。
def transform(data_batch):
'''
Function to process batch of images altogether
'''
# Take a list of PIL images and turn them to pixel values
inputs = processor([x for x in data_batch['image']], return_tensors='pt')
inputs['labels'] = data_batch['labels']
return inputs
# the with_transform function applies transformation to the images in real-time
prepared_ds = ds.with_transform(transform)
现在,我们需要一个最终函数,将所有处理过的图像堆叠在一起作为 torch 张量。
def collate_fn(batch):
'''
Function to stack up batch of images
'''
# batch is a list of dicts
return {
'pixel_values': torch.stack([x['pixel_values'] for x in batch]),
'labels': torch.tensor([x['labels'] for x in batch])
}
现在数据处理已经设置好了,我们将定义训练参数,例如评估指标和模型初始化。我们将计算准确性、精确度和召回率以进行评估,因为这是一个分类问题。
# Load accuracy, precision, and recall metrics
accuracy_metric = load_metric('accuracy')
precision_metric = load_metric('precision')
recall_metric = load_metric('recall')
def compute_metrics(p):
# Extract predictions and references
predictions = np.argmax(p.predictions, axis=1)
references = p.label_ids
# Compute accuracy
accuracy = accuracy_metric.compute(predictions=predictions, references=references)
# Compute precision (assume binary classification for simplicity)
precision = precision_metric.compute(predictions=predictions, references=references, average='macro')
# Compute recall (assume binary classification for simplicity)
recall = recall_metric.compute(predictions=predictions, references=references, average='macro')
# Combine all metrics into a single dictionary
return {
'accuracy': accuracy['accuracy'],
'precision': precision['precision'],
'recall': recall['recall']
}
现在,我们初始化模型。我们将传递模型名称和数据集中的类别数量,以便可以初始化分类头部。
labels = ds['train'].features['labels'].names
model = ViTForImageClassification.from_pretrained(
model_name_or_path,
num_labels=len(labels),
id2label={str(i): c for i, c in enumerate(labels)},
label2id={c: str(i) for i, c in enumerate(labels)}
)
最后,我们将初始化训练参数并创建一个 Trainer 对象,我们将在其中指定我们之前初始化的数据处理函数。
training_args = TrainingArguments(
output_dir="./vit-base-art",
per_device_train_batch_size=32,
evaluation_strategy="steps",
num_train_epochs=4,
fp16=True,
save_steps=100,
eval_steps=100,
logging_steps=10,
learning_rate=2e-4,
save_total_limit=2,
remove_unused_columns=False,
push_to_hub=False,
report_to='tensorboard',
load_best_model_at_end=True,
)
trainer = Trainer(
model=model,
args=training_args,
data_collator=collate_fn,
compute_metrics=compute_metrics,
train_dataset=prepared_ds["train"],
eval_dataset=prepared_ds["validation"],
tokenizer=processor,
)
一切都已就绪,我们可以执行训练。
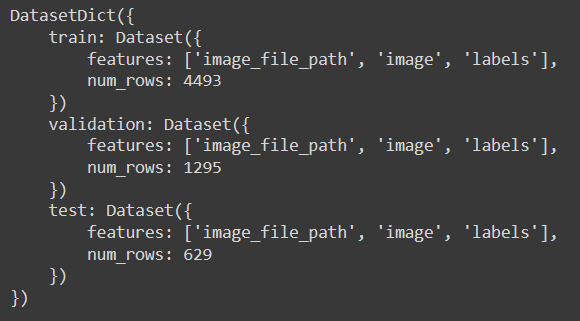
train_results = trainer.train()
trainer.save_model()
trainer.log_metrics("train", train_results.metrics)
trainer.save_metrics("train", train_results.metrics)
trainer.save_state()
 The_printed_result_1_ff70ec5667.png
The_printed_result_1_ff70ec5667.png
打印结果
经过 4 个周期后,我们的验证准确率达到了 50.7%。这些数字可能看起来不太令人印象深刻,但训练更长时间将改善它们。另外,请记住我们的数据集是有限的。
将视觉变换器(ViT)与向量数据库结合,以实现可扩展和高效的图像检索
视觉变换器(ViT)改变了我们理解和处理视觉数据的方式。它们将图像划分为补丁,将每个补丁视为一个标记,并使用自注意力机制捕获图像内的复杂、全局关系。这种方法允许 ViT 生成丰富、高维的特征嵌入,全面代表图像的视觉内容。
像 Milvus 和 Zilliz Cloud(完全托管的 Milvus)这样的向量数据库是专门设计用于高效存储、管理和查询高维向量的系统,这些向量通常由像 ViT 这样的机器学习模型生成。这些数据库针对向量相似性搜索进行了优化,目标是找到与给定查询向量相似的向量(因此数据)。
将 ViT 与向量数据库结合使用提供了巨大的好处。首先,ViT 生成丰富、高维的图像嵌入,捕获详细的视觉信息。这些嵌入可以被索引并存储在像 Milvus 这样的向量数据库中,以进行快速的图像相似性搜索。这种组合增强了构建强大的图像检索系统的能力,用户可以通过上传样本并快速、准确地找到视觉上相似的项目来搜索图像。
这种集成可以产生广泛的应用。在电子商务中,向量数据库和 ViT 组合可以启用基于图像的搜索功能,用户可以找到与上传图像相似的产品,提高用户体验和参与度。在内容管理中,它支持基于视觉特征自动标记和分类图像,减少手动工作量并提高效率。此外,这种协同作用在推荐系统中也很有用,可以根据用户偏好的嵌入建议视觉上相似的项目。
结论
变换器架构是人工智能(AI)领域的开创性发明。它允许模型理解单个数据点的重要性并取得惊人的结果。视觉变换器(ViT)使用相同的架构,但专为处理图像数据而构建。
ViT 将图像补丁视为单个数据点。这些补丁被扁平化并处理,以进行序列编码和额外的类别嵌入。变换器使用多头注意力模块计算每个补丁之间的对齐分数。比较图像补丁有助于我们理解每个段相对于整个图像的重要性。最后,分类头部向注意力输出添加非线性,并成为模块的最终输出。
注意力机制是一个计算密集型过程,因此从头开始进行模型预训练是困难的。然而,HuggingFace hub 上托管了各种预训练的 ViT 模型,可以对它们进行微调以用于下游任务。
注:本文为AI翻译,查看原文
 Haziqa Sajid
Haziqa SajidFreelance Technical Writer


