



简化企业生成型人工智能应用部署与高效管理非结构化数据
在生产环境中部署生成型人工智能(GenAI)应用并非易事,特别是当涉及到非结构化数据时。公司常常难以有效管理和利用这类数据以获得洞察并保持竞争优势。在Zilliz最近主办的非结构化数据聚会上,Aparavi的研发副总裁Joe Maionchi和Hendrik Knack讨论了管理非结构化数据的尖端技术,以简化GenAI应用的部署。
 aparavi_3_b353499c96.jpg
aparavi_3_b353499c96.jpg
Joe Maionchi在7月旧金山非结构化数据聚会上发言
处理非结构化数据的挑战
非结构化数据包括从电子邮件、社交媒体帖子到视频、图像和文档等无法统一存储的内容。与传统数据库整齐地适应行和列的结构化数据不同,非结构化数据庞大、多样且难以管理。正如Joe Maionchi强调的,“目前75%到80%的企业数据是非结构化的,而且这个体积每年都在增长。”这种快速增长使得组织越来越难以存储、处理和从数据中提取有价值的洞察。
非结构化数据的主要挑战包括:
- 管理复杂性:非结构化数据以多种格式出现,使其难以标准化和处理。此外,这些数据的巨大体量可能导致高昂的存储成本和管理复杂性。
- 数据隐私问题:保护敏感信息是企业的主要关注点。数据泄露,特别是涉及个人身份识别信息(PII)的泄露,可能是灾难性的。在外部环境(如基于云的解决方案或像GPT这样的大型语言模型LLMs)中存储和处理数据增加了数据泄露和违规的风险。
- 数据质量差:非结构化数据通常包含不一致性、缺失值和冗余信息。这个问题使得在不进行广泛数据清洗的情况下提取高质量、可操作的洞察变得具有挑战性。
- 处理和集成复杂性:分析非结构化数据需要高级技术,如自然语言处理(NLP)和信息检索。然而,许多团队缺乏必要的技术专长,导致数据利用效率低下。
使用Aparavi简化非结构化数据管理
为了应对这些挑战,像Aparavi这样的数据管理服务提供商提供了一个全面的数据平台,旨在简化非结构化数据的管理和利用。以下是该平台如何解决关键痛点。
 Flow_of_data_in_the_customer_environment_7ec31cd196.png
Flow_of_data_in_the_customer_environment_7ec31cd196.png
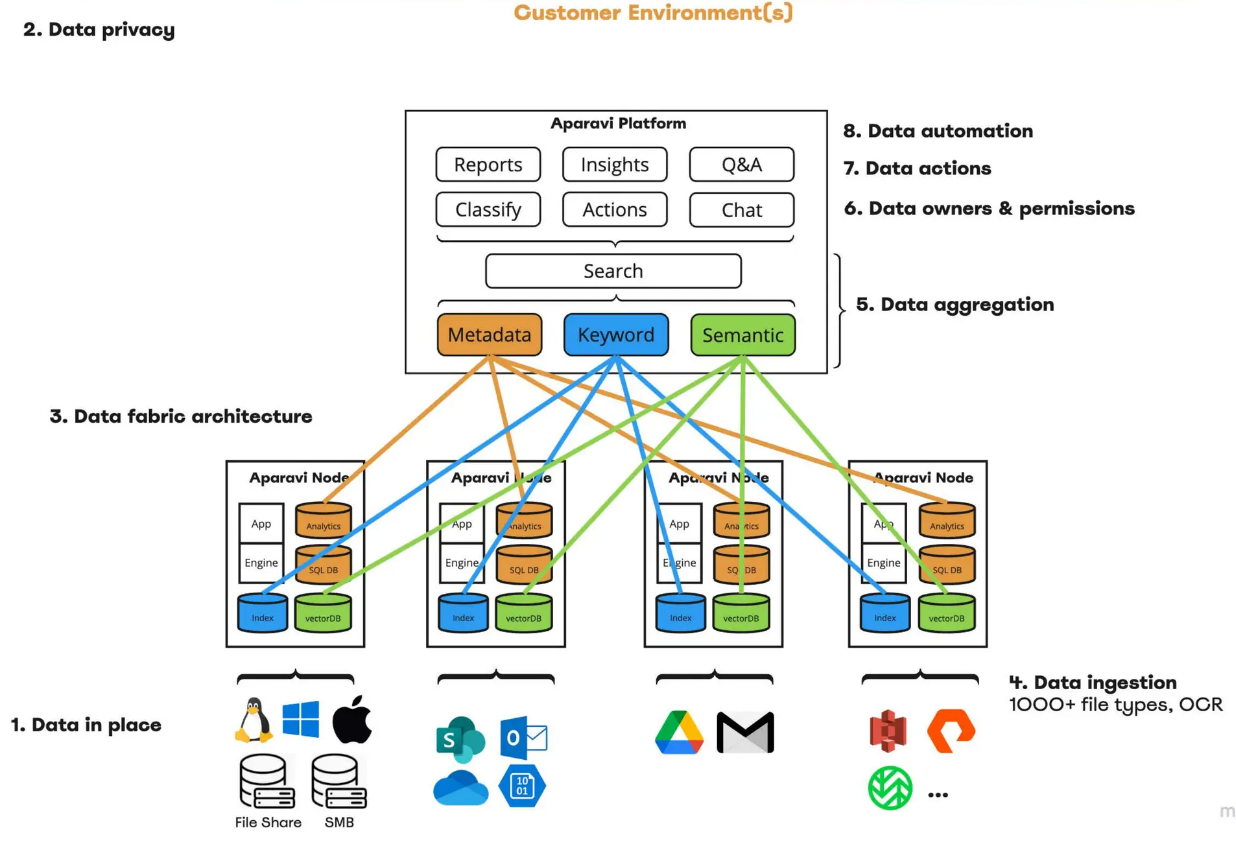
客户环境中的数据流
- 数据就地处理:该平台使企业能够在不将数据传输到外部环境的情况下管理和分析数据,确保数据隐私。该平台与包括向量数据库(如Milvus和Zilliz Cloud,即完全托管的Milvus)在内的广泛数据源、文件存储和Outlook、OneDrive等云服务无缝集成。
- 数据隐私:公司可以在不泄露敏感信息的情况下提取洞察,通过在本地安全地保存数据。平台的应用部署在您的非结构化数据所在的任何地方,减少了数据泄露的风险。
- 分布式架构:Aparavi采用分布式数据架构,使组织能够更高效、更大规模地管理数据。这种架构消除了对大型服务器场的需求,因为元数据、向量存储和索引分布在各个节点上。
- 强大的数据摄取:平台支持摄取超过1000种文件类型,并包括高级OCR(光学字符识别)功能,用于从图像中提取文本。这种能力确保了多样化的数据源可以被有效集成和分析。
- 数据聚合和查询:一旦摄取,非结构化数据被聚合,允许用户执行查询以提取有价值的洞察。这对于识别趋势和进行详细分析至关重要。
- 细粒度数据所有权和权限:平台允许企业在细粒度层面控制数据所有权,确保只有授权用户才能访问敏感信息。这个功能对于保持合规性和保护PII尤为重要。
- 数据操作和自动化:平台包括内置功能,使用户能够在系统内直接对洞察采取行动。自动化流程确保数据保持合规和最新,无需手动干预。
使用Aparavi和Milvus向量数据库扩展企业RAG
检索增强型生成(RAG)是一种AI技术,它为大型语言模型(LLMs)提供有关用户查询的上下文信息,以生成更相关和准确的答案。这种方法可以显著减少LLM幻觉问题。它还允许许多由LLM驱动的应用利用特定领域、专有或私有数据集的潜力,而不必担心数据安全问题。
Milvus是一个开源向量数据库,能够存储、索引和检索数十亿个向量。它专为生产需求而设计,是构建企业RAG系统的理想选择。与Milvus集成,Aparavi的平台提供了具有两个突出特性的企业RAG解决方案:语义搜索检索器和AI数据加载器。
语义搜索检索器
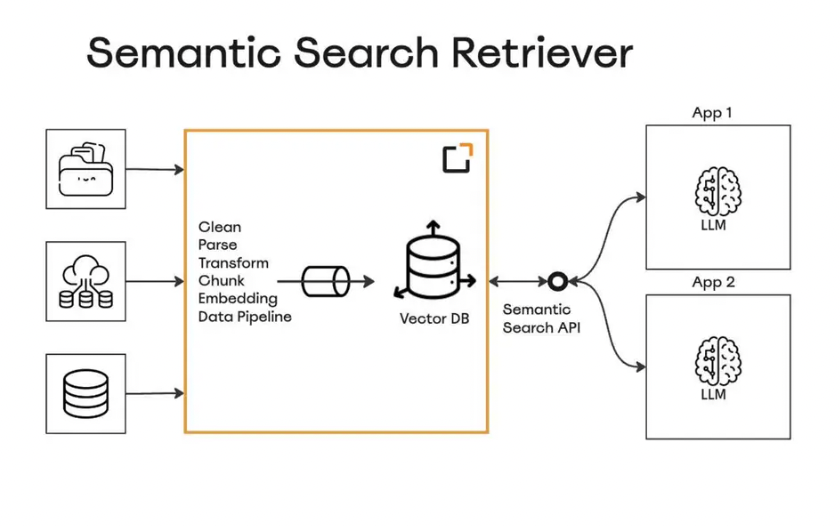
语义搜索检索器增强了对查询响应的上下文相关性。这个工具提供了一个语义搜索API端点,可以被查询以提取AI项目的相关数据块。
 RAG_as_a_service_for_information_querying_dcc74c7e63.png
RAG_as_a_service_for_information_querying_dcc74c7e63.png
作为信息服务的RAG查询
- 工作原理:数据被摄取、处理并存储在Milvus向量数据库中作为向量嵌入。当您进行查询时,它也被转换成向量嵌入。然后API利用Milkus检索与查询最相似的向量嵌入并返回相关数据。
- 好处:这个工具显著提高了LLM应用响应的准确性。企业可以选择像Milkus这样的高效向量数据库,并通过Aparavi数据管道直接提供数据。
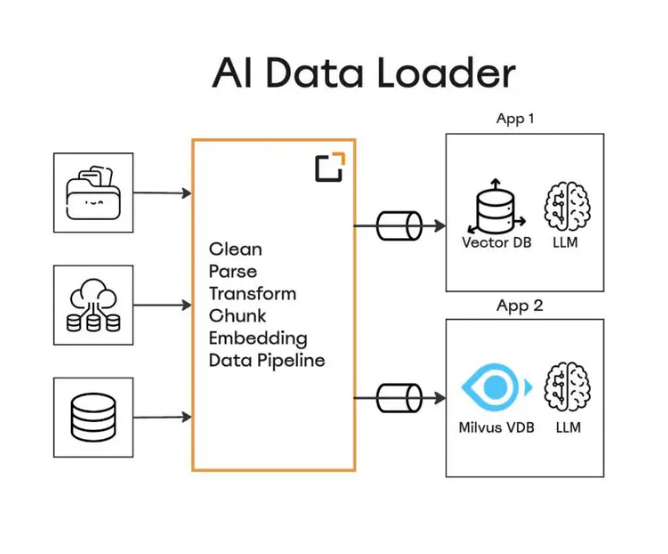
AI数据加载器
AI数据加载器自动化从各种来源导入数据,包括本地系统、云存储和外部存储库。它处理数据清洗、去重和格式化等任务,确保数据为分析做好准备。然后,加载器将预处理的数据发送到像Milkus这样的向量数据库进行相似性搜索。检索到的相关结果将作为用户查询上下文与LLM一起提供,以获得更相关的答案。
 AI_Data_Loader_in_the_pipeline_6d4946c8c4.png
AI_Data_Loader_in_the_pipeline_6d4946c8c4.png
管道中的AI数据加载器
Aparavi企业RAG的当前局限性
虽然Aparavi提供了管理非结构化数据的企业RAG解决方案,但仍存在一些挑战:
- 沉重的足迹:由于Aparavi在客户端托管平台并不将数据外部传输,足迹可能很大,可能会影响性能。
- 用户界面:由于其复杂性,新用户可能会发现很难上手和导航Aparavi平台。
结论
随着企业继续探索GenAI的潜力,管理非结构化数据仍然是一个关键挑战。组织可以通过利用像Aparavi这样的高级数据管理平台,并与像Milkus这样的高性能向量数据库集成,来简化其AI项目并随着业务增长扩展其应用。
 Fendy Feng
Fendy FengTechnical Marketing Writer
- ShriVarsheni R
Freelance Technical Writer


