搜索仍然重要:通过生成型人工智能和向量数据库增强信息检索
搜索的历史可以追溯到互联网的最初诞生。没有搜索引擎,在线查找信息几乎是不可能的。第一个推出的互联网搜索引擎是Archie,由Alan Emtage在1990年代开发。之后,又推出了其他几个搜索引擎,包括World Wide Web Wanderer。
如今,算法已经发展到能够理解词语背后的含义,并且在生成型人工智能的帮助下,你可以搜索互联网的深处。虽然看起来搜索引擎可能已经达到了一个平台期,尤其是在像ChatGPT这样的大型语言模型(LLMs)崛起之后,搜索仍然很重要。通过结合GenAI技术和信息检索以及搜索算法,用户可以获得更好的搜索体验和更准确的搜索结果。
在本文中,我们将讨论以下内容:
- 搜索的演变以及GenAI的影响
- 搜索、GenAI和向量数据库的结合
- 挑战和考虑因素
- 搜索的未来
搜索的演变:从精确关键词匹配到语义搜索
搜索引擎的旅程始于传统的关键词搜索。关键词算法使搜索引擎能够根据与查询的相关性对结果进行排名。它们考虑的因素包括关键词的频率、位置和整体内容质量,如术语频率-逆文档频率(TF-IDF)和BM25,这些至今仍非常流行。
 屏幕截图 2024-11-12 201543.png
屏幕截图 2024-11-12 201543.png
表:比较TF-IDF和BM25
传统搜索难以理解上下文、同义词和用户查询背后的更广泛含义。语义搜索是一个巨大的进步,它利用自然语言处理(NLP)来解释查询的意图和上下文。语义搜索的关键优势包括:
- 上下文感知:理解查询背后的含义,而不仅仅是精确的关键词。
- 提高相关性:提供更准确和上下文相关的搜索结果。
- 处理同义词:识别和处理同义词和相关概念。
语义搜索之所以成为可能,是因为向量嵌入和向量相似性搜索技术。向量嵌入是各种非结构化数据(如自然语言)的数值表示,捕获单词和句子的上下文含义。
向量嵌入通常由各种深度学习模型(也称为嵌入模型)生成,如Cohere的embed-english-v3.0和OpenAI的text-embedding-3-large。
向量数据库专门构建用于高效存储、索引和检索大量这些向量嵌入。它们还提供操作符,以根据查询检索相关文档。
向量数据库与传统关系数据库的不同之处在于,它们旨在处理向量数据并执行相似性搜索。然而,它们仍然可以支持与传统基于向量的查询一起的传统搜索能力。这是一个展示Zilliz Cloud向量数据库上向量搜索能力的网络研讨会。
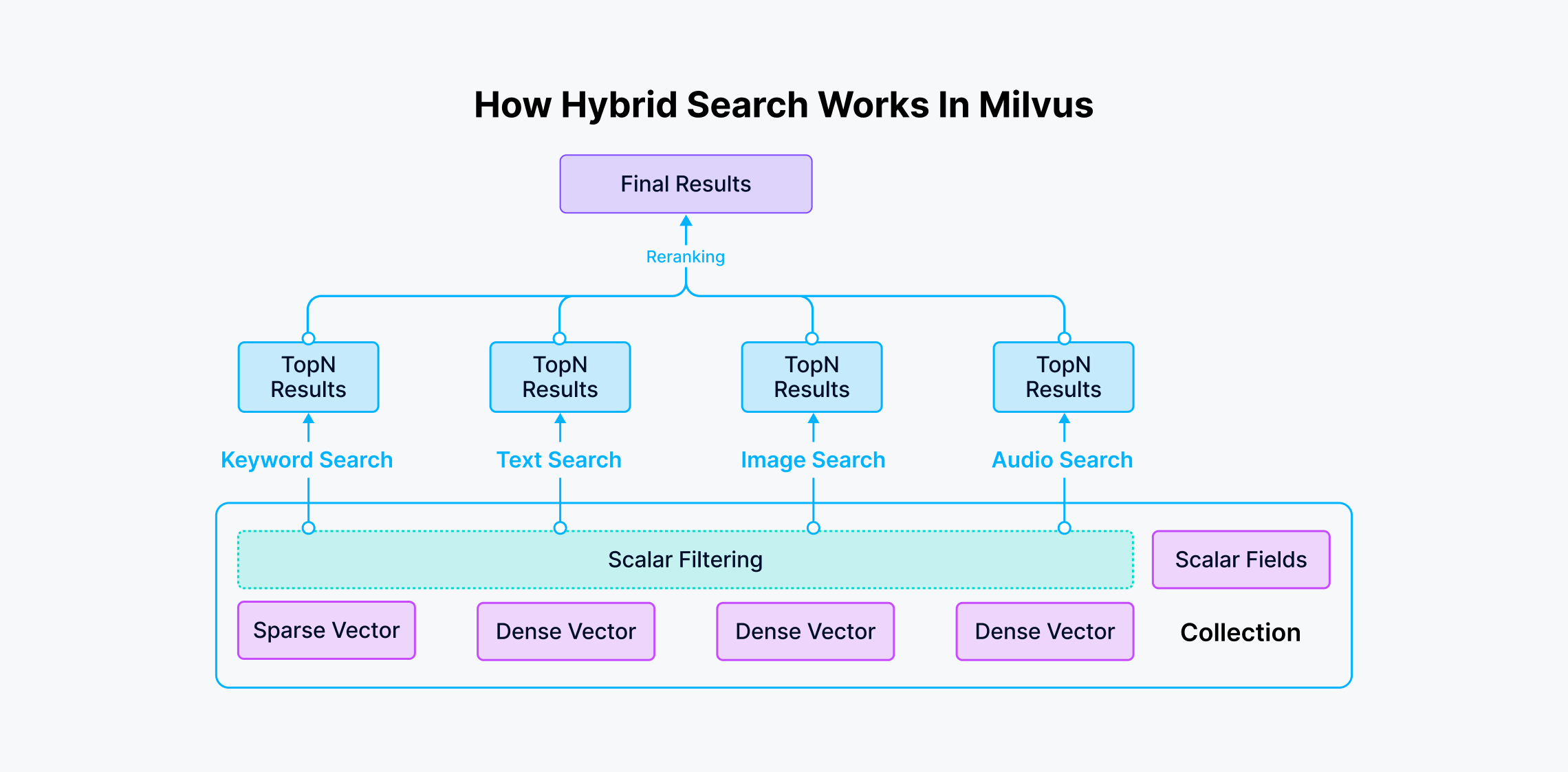 how_hybrid_search_works_5250109da8.png
how_hybrid_search_works_5250109da8.png
图1:在Milvus向量数据库系统中混合搜索的工作原理
结合关键词和语义搜索是可能的,并且通常可以带来更优越的结果。像Milvus这样的向量数据库支持在单个集合中每个数据集最多10个向量字段,从而实现跨多个向量列的同时混合搜索。Milvus的高级功能使不同的列能够:
- 表示信息的多个视角,例如电子商务中产品的不同视图。
- 使用不同类型的向量嵌入,包括来自BERT和Transformers等模型的密集嵌入,以及来自BM25、BGE-M3和SPLADE等算法的稀疏嵌入。
- 融合来自不同非结构化数据类型的多模态向量,如图像、视频、音频和文本,促进刑事调查中的生物识别等应用。
- 将向量搜索与全文搜索集成,提供多功能和全面的搜索功能。
生成型人工智能及其对搜索的影响
大型语言模型(LLMs)是在大量数据上训练的。这种方法使它们能够理解和处理各种自然语言相关的任务。在搜索的背景下,LLMs在以下方面表现出色:
- 上下文理解:把握查询背后的意图,以获得更准确的结果。
- 语义搜索:解释和匹配内容查询的含义。
- 自然语言处理:处理复杂查询和微妙的语言。
- 同义词识别:识别和处理同义词,以获得更广泛的搜索覆盖。
- 多语言搜索:支持多语言查询,以实现全球可访问性。
以前,Google搜索会返回数千页需要进一步调查的结果。现在,像ChatGPT这样的生成型人工智能已经通过提供对话式和上下文感知的回应,改变了网络搜索,使其对简单查询更加吸引人和有用。在其早期阶段,LLMs有几个限制:
- 权威性限制:生成型人工智能通常无法提供权威来源和直接引用,这对于学术和科学研究至关重要。
- 时效性问题:由于训练需要大量资源,生成型人工智能模型可能无法始终反映最新信息,特别是在快速发展的领域。
- 学习和意外发现:使用AI进行搜索可能会减少发现新的、不相关信息的机会。
- 能源消耗:生成型人工智能系统比传统搜索引擎消耗更多的能源。
- 幻觉:LLMs只能根据它们预先训练的信息给出答案。如果它们没有足够的数据参考,它们可能会提供错误或编造的信息。
- 缺乏特定领域的信息:LLMs仅在公开可用的数据上训练。因此,它们可能缺乏对公众无法访问的特定领域、专有或私人信息。
这些限制可能是有害的,但将生成型人工智能与向量数据库结合起来构建检索增强型生成(RAG)系统可以帮助减轻它们。
RAG:将生成型人工智能与传统搜索结合起来,以获得更准确的搜索结果
一些限制,如过时的信息、缺乏引用或来源以及减少的意外发现,可以通过一种称为检索增强型生成(RAG)的流行技术来减轻,它将生成型人工智能与传统搜索结合起来。
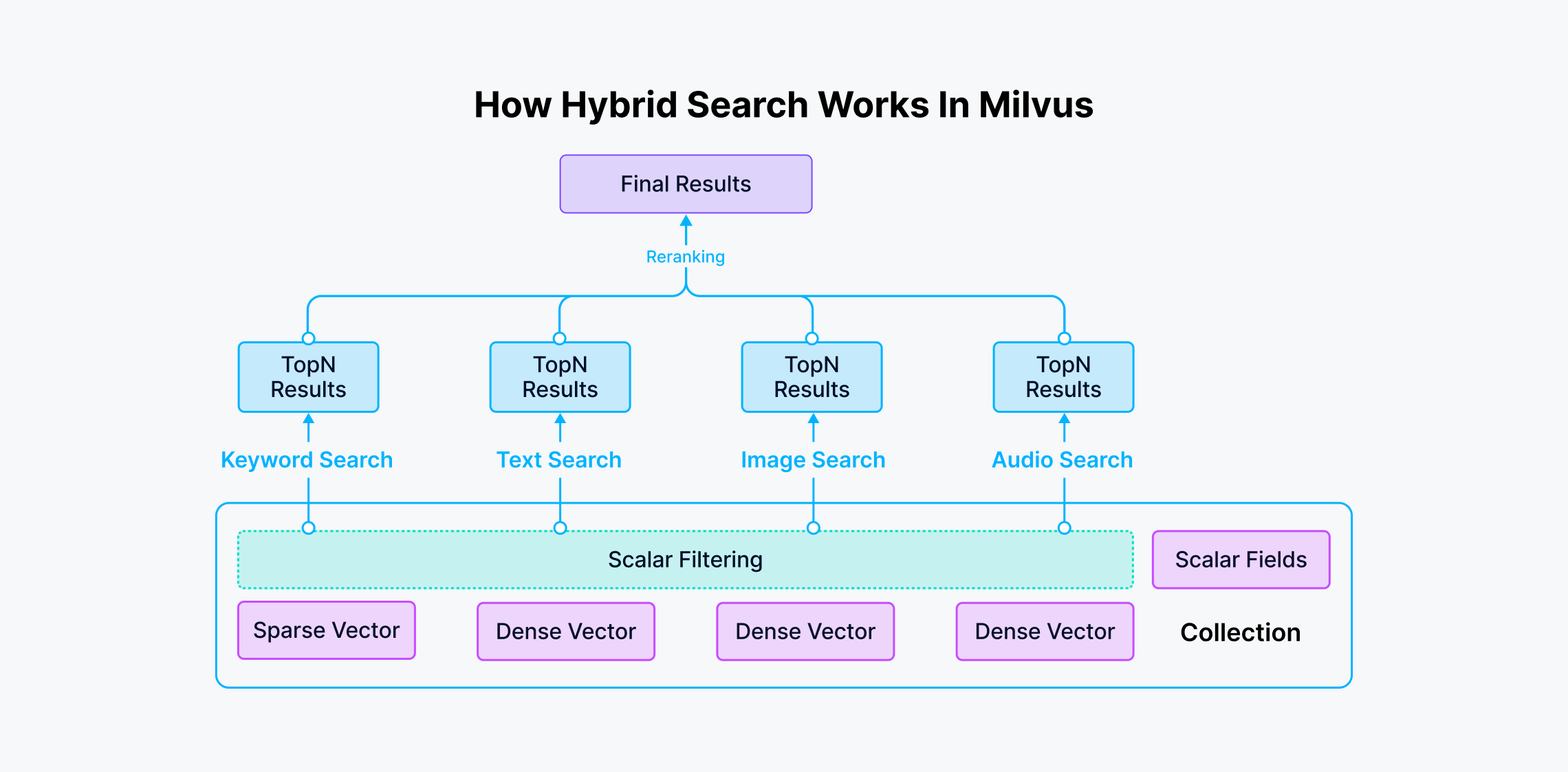 how_hybrid_search_works_5250109da8.png
how_hybrid_search_works_5250109da8.png
图2:RAG的工作原理
RAG首先确定你想要用于生成型人工智能应用的数据源,确保结果是上下文相关的。然后,使用所选的机器学习模型将这些数据源的内容转换为向量嵌入——数据在高维空间中的数值表示。这些嵌入存储在向量数据库中,如Milvus。当应用程序接收到查询时,例如聊天机器人的问题,它将查询转换为向量嵌入。这个嵌入在向量数据库中执行语义搜索,检索相关文档或数据。搜索结果连同原始查询和提示一起发送到语言模型(LLM)以生成上下文准确和相关的回应。
简而言之,RAG使用搜索算法从外部源拉取相关信息,并将其与预训练的LLM集成。这种方法克服了独立LLMs中发现的过时信息和有限来源的问题。
下一节将使用Milvus和LlamaIndex实现一个基本的RAG应用。
使用Milvus和LlamaIndex实现RAG
我们将使用一些与技术创新和人工智能(AI)进步相关的合成数据。这个数据集将包括两个文件:一个包含技术进步的摘要,另一个包含AI状态的简要概述。
导入和设置
代码片段需要pymilvus和llamaindex依赖项。使用以下命令安装它们:
pip install pymilvus>=2.4.2
pip install llama-index-vector-stores-milvus
pip install llama-index
pip install openai
如果您使用Google Colab,可能需要在安装依赖项后重新启动运行时。点击屏幕顶部的Runtime菜单,然后从下拉菜单中选择"Restart session"。
设置OpenAI
首先,添加您的OpenAI API密钥以访问GPT:
import openai
openai.api_key = "sk-***********"
为确保安全,请将API密钥存储在.env文件中,以防止公开暴露。
准备数据
在这个例子中,我们将创建自己的虚拟数据,这些数据将被摄取到向量数据库中。
创建数据文件
首先,我们将创建两个文本文件。
tech_innovations.txt,包含技术进步的摘要。ai_overview.txt,包含AI状态的概述。
您可以直接在工作目录中创建这些文件,或者使用以下命令生成它们:
mkdir -p 'data/'# Create tech_innovations.txtecho "1. Quantum computing promises to revolutionize the field of computing with its ability to perform complex calculations much faster than classical computers.
2. Blockchain technology enhances security and transparency by providing a decentralized and tamper-proof ledger for transactions.
3. 5G networks offer higher data speeds and lower latency, enabling advancements in IoT and smart city technologies." > data/tech_innovations.txt# Create ai_overview.txtecho "Artificial Intelligence (AI) is rapidly evolving, with recent advancements in natural language processing, computer vision, and robotics. Techniques like deep learning and reinforcement learning are driving innovations in various industries, from healthcare to autonomous vehicles." > data/ai_overview.txt
生成文档
使用以下Python代码读取文档并将它们加载到llama_index中:
from llama_index.core import SimpleDirectoryReader
# Load documents from the created files
documents = SimpleDirectoryReader(
input_files=["./data/tech_innovations.txt", "./data/ai_overview.txt"]
).load_data()
# Print the document ID of the first documentprint("Document ID:", documents[0].doc_id)
创建索引
索引是一种数据结构,用于通过将文本或数值数据映射到向量表示来快速从大型数据集中检索信息。它通过实现快速比较来促进有效的相似性搜索和查询。以下是如何使用Milvus向量存储创建索引:
from llama_index.core import VectorStoreIndex, StorageContextfrom llama_index.vector_stores.milvus import MilvusVectorStore
# Initialize the vector store
vector_store = MilvusVectorStore(uri="./milvus_demo.db", dim=1536, overwrite=True)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
# Create an index from the loaded documents
index = VectorStoreIndex.from_documents(documents, storage_context=storage_context)
对于MilvusVectorStore的参数:
- 将
uri设置为本地文件,例如../milvus.db,是最方便的方法,因为它自动使用Milvus Lite将所有数据存储在此文件中。 - 对于大型数据集,您可以在Docker或Kubernetes上设置更高性能的Milvus服务器,并使用服务器
uri,例如http://localhost:19530。 - 要使用Zilliz Cloud,请调整
uri和token为Zilliz Cloud中的公共端点和API密钥。
查询数据
现在我们的文档已经存储在索引中,我们可以查询它。索引将使用自身存储的数据作为GPT的知识库。像这样:
query_engine = index.as_query_engine()
# Example queries
res1 = query_engine.query("What are some recent technological advancements?")
使用LLMs和RAG的挑战和考虑因素
上述提出的观点是新的,并且不是没有挑战的。以下是其中的一些:
- 平衡速度和准确性:像GPT-4和PaLM这样的大型语言模型由于参数数量的增加而实现更高的准确性。然而,随着参数数量的增加,推理速度会降低,成本会增加。这在生成速度和准确性之间产生了权衡。像Microsoft的Phi系列这样的新模型旨在在保持准确性的同时减少参数大小。
- 应对偏见和确保公平性:增强型搜索系统必须面对偏见以确保公平。例如,Google的图像数据库因以美国和西方为中心而受到批评,强化了刻板印象。数据集中的这种潜在偏见导致非高加索人群和女性的不准确率更高。2018年,亚马逊承认其AI招聘工具存在缺陷。在过去的十年中,它根据主要是男性简历中的模式学会了偏好男性申请者。解决这些偏见和确保公平是必要的,AI是这种新型搜索的主要组成部分。
- 隐私和安全问题:AI对大型数据集的需求与隐私法冲突,限制了数据共享和自动化决策,限制了AI的能力。在COVID-19期间,这些限制阻止了AI开发人员访问健康数据。这影响了他们改进控制措施和疫苗分发决策的能力。给予AI无限制的数据访问可能会引发隐私问题,因为它可能在训练期间使用个人的个人内容。
这些严重的问题阻碍了现代搜索引擎的发展。正在进行的研究旨在解决这些问题,并可能很快提供解决方案。
搜索的未来:趋势和预测
搜索的未来正在通过以下创新改变信息获取:
- 个性化搜索:这些创新可以在Google的最新更新中看到。Google的语义搜索利用向量嵌入来理解查询的上下文。例如,如果用户搜索“我附近的最好的意大利餐厅”,Google使用嵌入来返回考虑用户偏好、最近搜索和位置的结果。
- 多模态搜索:以前,搜索仅限于文本,但现在有了嵌入,我们现在可以搜索不同的模态,如文本、图像或音频。用户可以为复杂查询向搜索引擎提供文本和图像。
- 科学和学术搜索:像Semantic Scholar这样的AI驱动工具使用自然语言处理来理解和索引研究论文,提供更相关的搜索结果。Google的AI驱动搜索算法可以识别不同研究主题之间的联系,发现传统搜索方法可能错过的洞察。此外,AI代理可以分配任务,例如找到相关文档、检索关键信息并将其呈现给用户。
结论
在文章中,我们讨论了导致我们长期熟知的搜索引擎如Google和Bing的先前IR系统。我们讨论了由于AI的崛起而出现的新型搜索系统。主要的关键点如下:
- 继续需要搜索系统:尽管生成型AI取得了进步,传统的信息检索(IR)系统仍然至关重要,尤其是对于学术用途。
- 权威性和时效性:用户,特别是学者,重视信息的权威性和最新性,这通常是生成型AI聊天机器人所缺乏的。
- 生成型AI的挑战:缺乏直接引用、潜在的错误信息和能源消耗是搜索中生成型AI的重要问题。
- 利用RAG减轻LLM限制以获得高级搜索:LLM可以通过与向量数据库集成以访问外部数据源作为上下文,从而生成更准确的答案。
- 未来潜力:虽然生成型AI可能增强搜索过程,但需要更多的研究和开发来解决当前的限制。
 Haziqa Sajid
Haziqa SajidFreelance Technical Writer