



展向量数据库以满足企业需求
在当今世界,组织面临着由于数据特别是非结构化数据的快速增长所带来的机遇和挑战。需要可扩展的解决方案来有效管理和利用这些庞大的信息。像 Milvus 这样的向量数据库旨在通过在高维空间中将非结构化数据表示为数值向量来处理非结构化数据。
在这篇博客中,我们将探索数据库可扩展性的概念,并解析 Milvus 的扩展能力。我们还将介绍其可扩展性技术,并探索它们如何为非结构化数据管理中的卓越性能和创新铺平道路。
理解数据库可扩展性
通常,数据库可扩展性指的是根据不断变化的业务需求动态扩展或收缩系统资源(如 CPU、存储和内存)的能力。有两种基本类型的可扩展性:垂直和水平可扩展性。
垂直可扩展性(向上扩展):垂直可扩展性涉及通过增加 CPU、内存和存储等资源来增加单个数据库服务器的容量,但它有其局限性。虽然它提供了快速直接的解决方案,但重要的是要注意,单个服务器在遇到硬件限制之前可以扩展的程度是有限的。了解这些限制是关键,以便在现实世界场景中做出有效的可扩展性决策。
水平可扩展性(向外扩展):水平可扩展性涉及添加额外的服务器来分配工作负载,提供了显著的好处。这种策略将大型数据集分割并跨所有这些节点分发。通过逐渐向数据库集群添加节点,水平可扩展性开辟了几乎无限扩展的可能性。它还增强了容错能力,因为系统可以在节点故障的情况下无缝重新分配任务到剩余节点。了解这些优势对于管理大型数据集和确保系统可靠性至关重要。
Milvus 向量数据库的可扩展性
Milvus 是一个开源向量数据库,拥有垂直和水平扩展的能力。凭借其分布式和云原生架构,Milvus 无缝地容纳了天文数字的向量,高达数万亿,所有这些都以毫秒级的闪电般响应时间。基准测试结果展示了 Milvus 向上和向外扩展的能力。
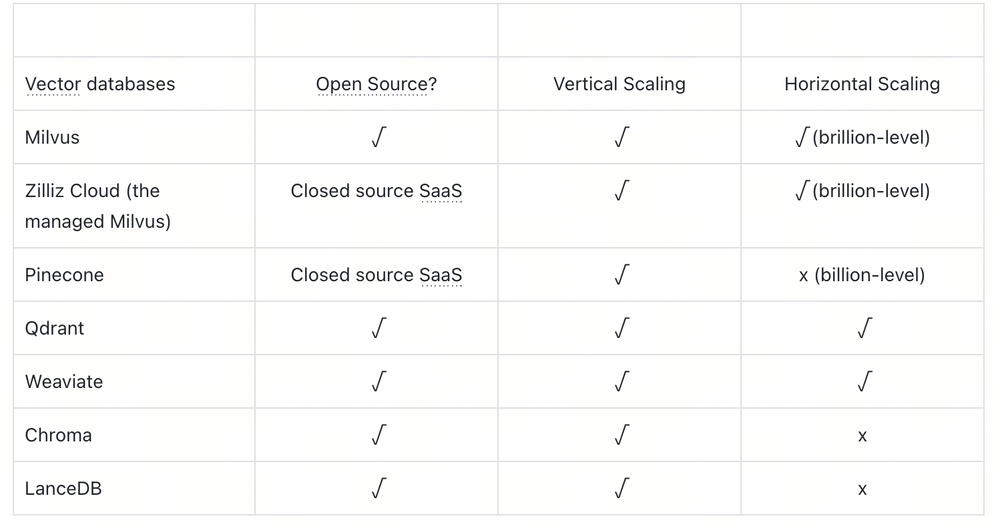
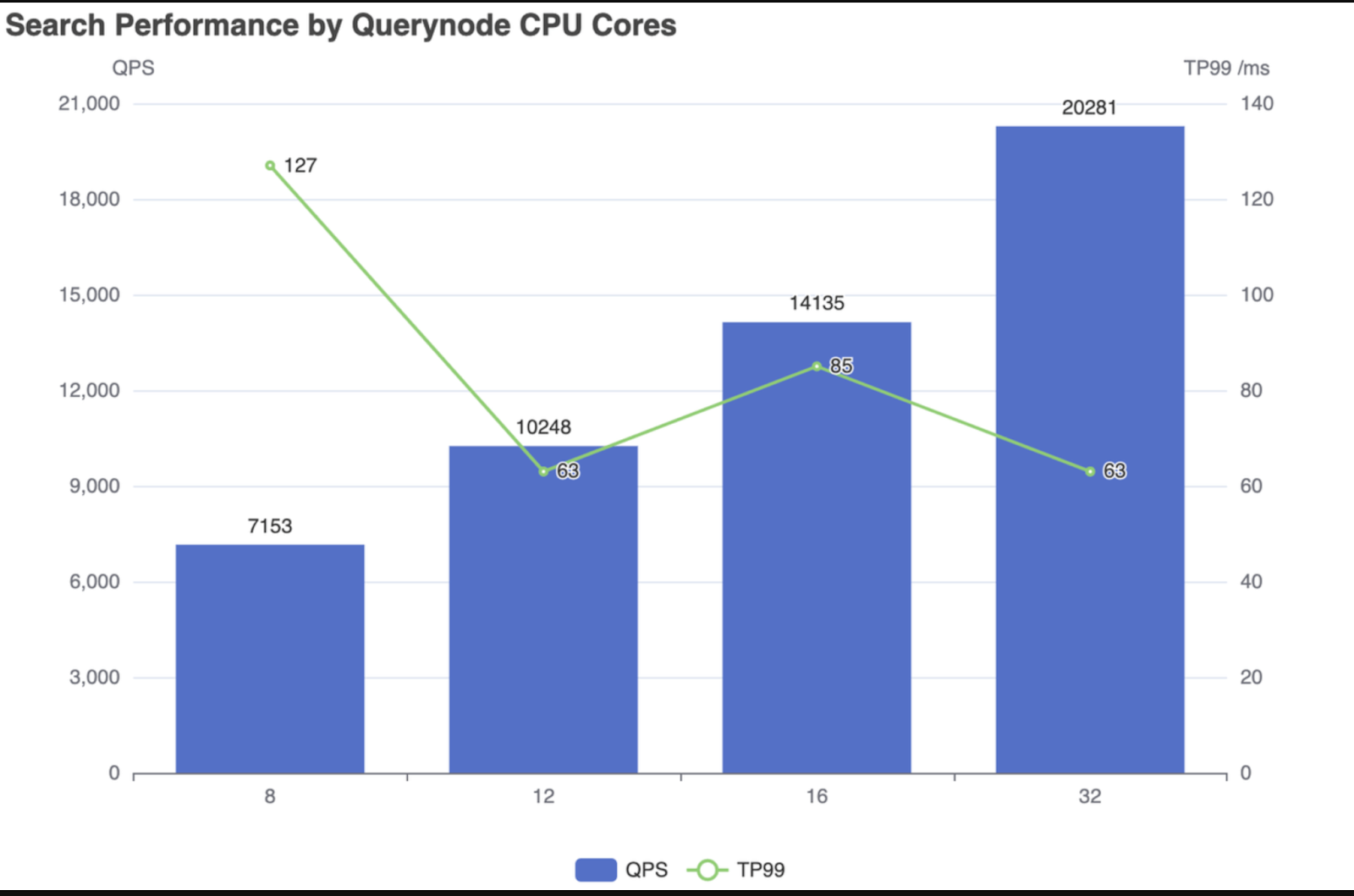
以下是 Milvus 性能动态的快照(版本 2.2.0),随着计算资源的扩展和缩减。无论是增加 Querynode 集群的资源还是扩展 Querynode 副本,Milvus 都显示出其查询处理能力(QPS)的明显增强,并减少了 TP99 延迟。
 77.1.png
77.1.png
通过扩展 Querynode CPU 核心的搜索性能
 77.2.png
77.2.png
通过扩展 Querynode 副本的搜索性能
Milvus 如何实现其无与伦比的扩展
Milvus 采用两种主要的扩展技术来实现卓越的可扩展性:复制、分区和负载均衡。
复制
复制是 Milvus 可扩展性策略的基石。通过在集群的多个节点中复制或复制计算机资源,Milvus 确保用户请求均匀分布,防止任何单个节点变得不堪重负。这种方法增加了系统处理更多数据库读取请求的能力,并增加了一层弹性。集群中的每个节点都包含数据的副本,因此在节点故障的情况下,其他副本节点可以无缝接管,最小化停机时间并确保不间断的服务。
分区
分区是 Milvus 可扩展性框架的关键组成部分,提供了一种复杂但有效的方法来管理和在其基础设施中分发大型数据集。核心上,分区涉及将数据划分为更小、更易管理的单元,称为段或分区。然后将这些分区分布在多个数据库中,使 Milvus 能够几乎无限制地扩展其存储和计算能力。
但在 Milvus 生态系统中,分区在实践中是如何工作的呢?
数据组织和分割
当数据被引入 Milvus 时,它被组织成集合,每个集合代表一个不同的数据集或数据类型。分区允许这些集合进一步被划分为逻辑段,每个段包含数据的一个子集。这种逻辑组织促进了高效的数据检索和处理,特别是当需要独立访问或操作数据子集时。
动态可扩展性和并行处理:
Milvus 中分区的一个关键优势是其能够随着数据量的增长动态扩展存储容量。当新数据被引入系统时,它会自动分布在可用的分区和段中,确保最佳资源利用和性能。这种动态可扩展性允许组织无缝扩展其数据基础设施,而不会遭遇瓶颈或性能下降。
此外,分区使 Milvus 集群中的多个节点能够并行处理数据。每个节点管理一个分区和段的子集,允许同时进行索引、查询和数据操作操作。这种并行处理能力增强了读写性能,使 Milvus 能够轻松处理大规模数据工作负载。
段大小和管理:
在 Milvus 中,段代表跨节点分布的最小数据单位,通常范围从 512MB 到 1GB。段的大小经过精心平衡,以优化 IO 成本和搜索性能。较小的段可以带来更快的索引和更低的搜索延迟,尽管在搜索期间会增加 IO 操作。段管理对于优化存储效率和性能至关重要。Milvus 使用复杂的算法和数据放置策略,确保段均匀分布在节点上,并优化数据访问模式,以实现最大吞吐量和响应性。
负载均衡
将数据分割成多个段后,负载均衡变得至关重要,以确保工作负载均匀分布在节点上。Milvus 通过称为平衡器的后台进程实现这一点,这些进程动态地将段分配给节点以实现工作负载平衡。在出现不平衡的情况下,平衡器启动任务以无缝调整节点之间的段分布。重要的是,这些任务以事务性方式执行,确保正在进行的查询不受影响,并确保无缝负载均衡。
比较主流向量数据库的可扩展性
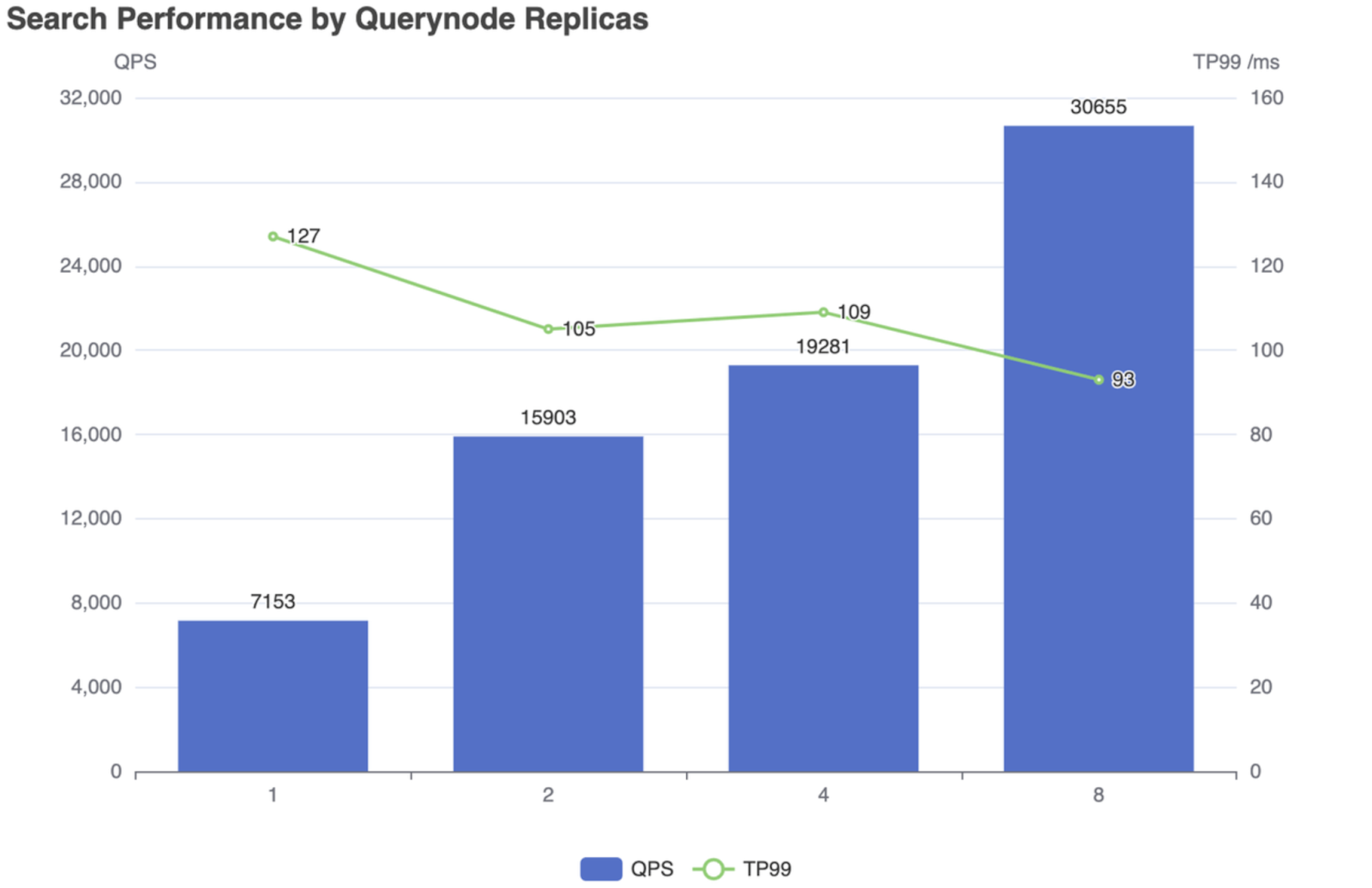
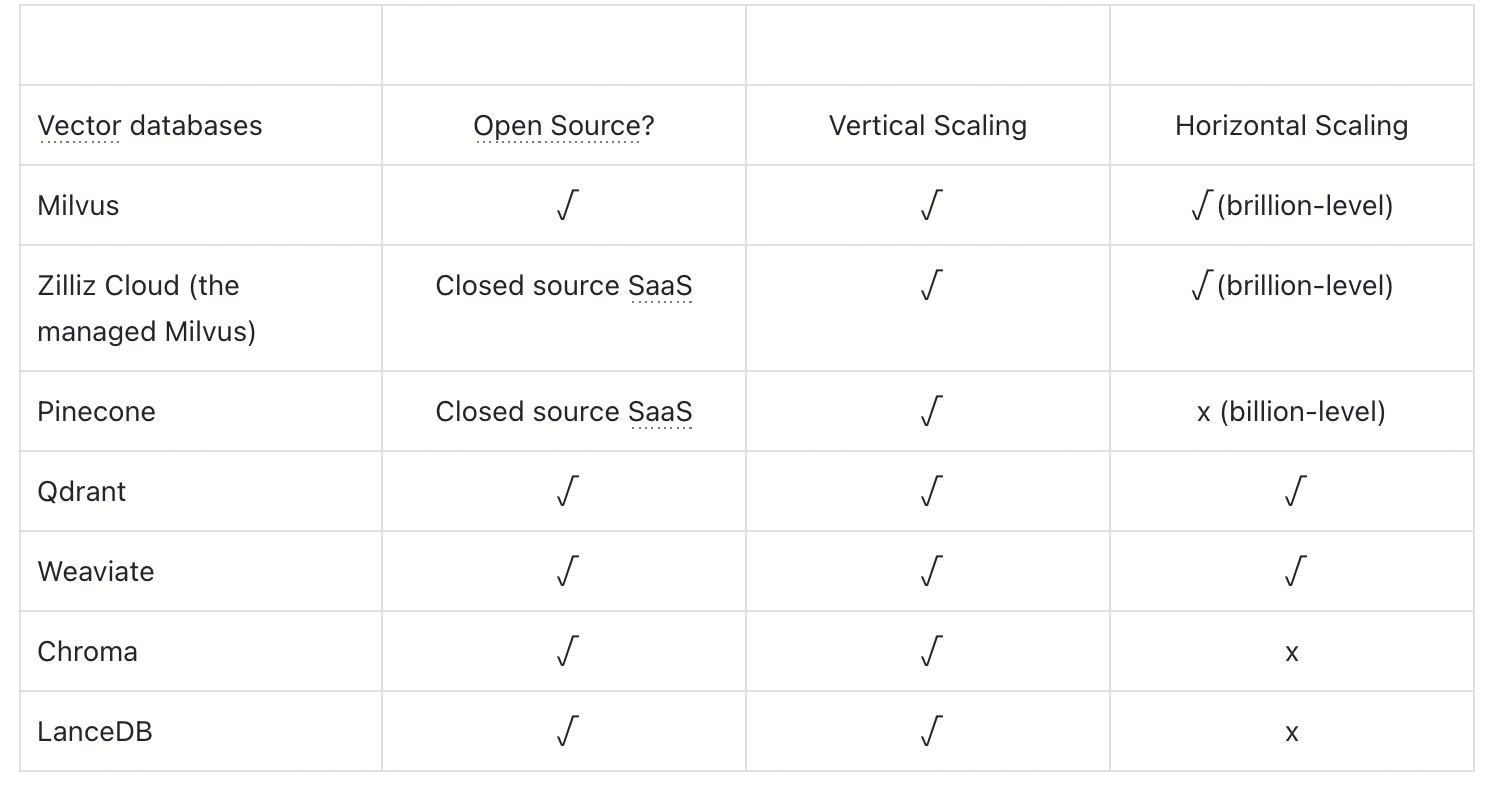
不同的向量数据库满足不同类型的用户,因此它们的可扩展性策略也不同。例如,Milvus 专注于数据量快速增长的用例,并使用具有存储计算分离的水平可扩展架构。Pinecone 和 Qdrant 为数据量适中且扩展需求适度的用户设计。LanceDB 和 Chroma 优先考虑轻量级部署而非可扩展性。
下表显示了主流向量数据库提供的可扩展性策略。
 77表.png
77表.png
总结
在当今以数据为驱动的世界中,寻求可扩展的非结构化数据管理解决方案比以往任何时候都更为关键。随着组织努力应对数据的不断涌入,有效利用和管理这些信息的需求变得越来越迫切。
在本文中,我们探讨了现代数据管理中数据库可扩展性的概念和重要性,并解析了 Milvus 轻松扩展以容纳数万亿向量的能力。从其精心设计的架构到其创新的可扩展性技术,Milvus 站在数据管理的前沿,为卓越的性能和创新铺平了道路。

Fendy Feng
Technical Marketing Writer


技术干货
艾瑞巴蒂看过来!OSSChat 上线:融合 CVP,试用通道已开放
有了 OSSChat,你就可以通过对话的方式直接与一个开源社区的所有知识直接交流,大幅提升开源社区信息流通效率。
2023-4-6
技术干货
向量数据库的行业标准逐渐清晰!Vector DB Bench 正式开源!
本文将从 Vector DB Bench 的特点和优点出发,帮助开发者全面、客观、高效地评估向量数据库。
2023-6-21
技术干货
LLM 快人一步的秘籍 —— Zilliz Cloud,热门功能详解来啦!
此次我们在进行版本更新的同时,也增加了多项新功能。其中,数据迁移(Migration from Milvus)、数据的备份和恢复(Backup and Restore)得到了很多用户的关注。本文将从操作和设计思路的层面出发,带你逐一拆解 Zilliz Cloud 的【热门功能】。
2023-4-10