RoBERTa:一种优化的预训练自监督NLP系统方法
预训练语言模型在自然语言处理(NLP)中取得了惊人的成功,导致了从监督学习到预训练后微调的范式转变。语言建模的目标是基于大量未标注文本数据(即未用特定信息标记的原始文本数据)预测序列中的下一个标记。BERT(Bidirectional Encoder Representations from Transformers)为这一概念树立了新标准,因为它能够进行双向语言理解,它不仅看一个单词,而是看整个句子。它考虑了前后的单词以更好地理解它们的含义。
然而,BERT的主要问题是其训练不足,这限制了它在NLP任务上的表现。这一局限性促使研究人员在后续模型中探索改进的训练方法,比如RoBERTa。
RoBERTa(A Robustly Optimized BERT Pretraining Approach)是BERT的改进版本,旨在解决其局限性。RoBERTa引入了几项关键改进,增强了其在各种NLP问题上的表现。
本文将讨论RoBERTa开发中使用的方法和技术,包括其训练方法、它所取得的成果,以及它开辟的潜在未来研究机会。
BERT(Bidirectional Encoder Representations from Transformers)快速介绍
要理解RoBERTa,必须了解其前身BERT以及它面临的挑战。BERT引入了双向变换器的概念,使深度学习模型能够以前所未有的方式来理解上下文。
但是,要真正理解BERT的工作原理,我们需要对其进行分解。让我们仔细看看它的架构以及训练方式。
BERT的架构和预训练过程
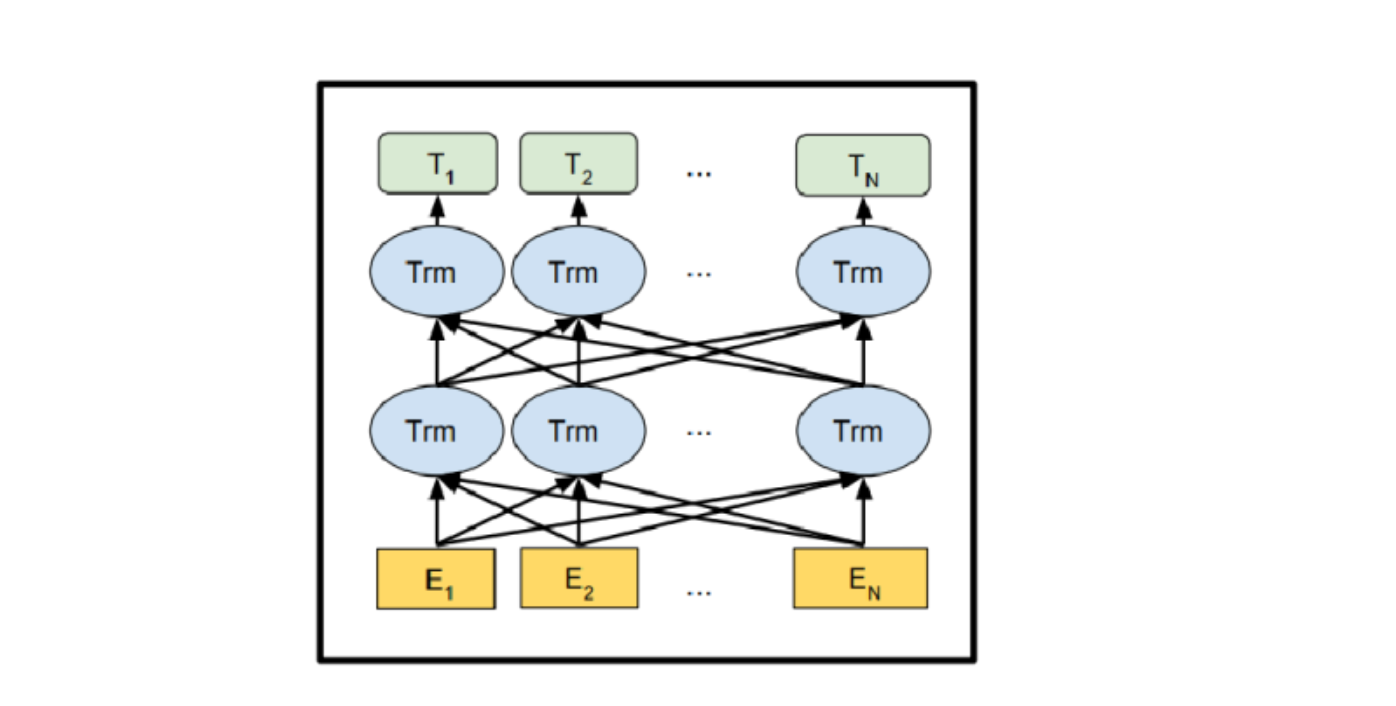
BERT的架构基于变换器,由Devlin等人在2018年引入。它使用多层双向(从左到右和从右到左)编码器来衡量句子中不同单词的重要性。
 BERT_Architecture_9e1ea351ff.png
BERT_Architecture_9e1ea351ff.png
图1:BERT架构
一个单词从嵌入层开始,以嵌入表示;嵌入是单词或标记在高维空间中的密集向量(数值表示)。嵌入层是神经网络中的第一层,将输入单词转换为这些密集向量。每一层都对前一层的单词表示进行多头注意力计算,生成新的中间表示。所有这些中间表示的大小相等。在上图中,E1是嵌入表示,T1是最终输出,Trm是标记的中间表示。
BERT的预训练过程包括两个主要任务:
- 遮蔽语言模型(MLM)
- 下一句预测(NSP)
语言模型预测给定单词序列的下一个单词。在MLM任务中,不是预测每个下一个标记,而是随机遮蔽一定百分比的输入标记,并只预测这些遮蔽的标记。NSP任务则是一个二元分类任务,预测两个给定句子是否在原始文本中跟随彼此。这种方法帮助模型理解句子之间的关系。
 Next_Sentence_Prediction_bf69c2e908.png
Next_Sentence_Prediction_bf69c2e908.png
图2:下一句预测
BERT的预训练过程有局限性,阻碍了它发挥全部潜力。主要问题之一是MLM任务中使用的静态遮蔽模式。在BERT中,一旦在训练期间对单词进行遮蔽,所有迭代中相同的单词都被遮蔽。这种静态方法限制了模型面对多样化遮蔽场景,降低了其泛化能力。此外,训练数据的大小和持续时间也受到限制。
这些局限性导致了BERT在特定领域任务(如法律或医学文本分析)和复杂语言理解场景(如情感分析或多步骤推理)的表现不一致。解决这些短板需要进一步的研究和开发。
RoBERTa的出现
RoBERTa开发的主要动机是解决BERT预训练过程中观察到的挑战。然而,RoBERTa保持了与Bert Large相同的核心架构,包括24层、1024个隐藏单元和16个注意力头,总共3.55亿个参数。
RoBERTa旨在解决的挑战包括:
- 静态遮蔽模式:BERT的静态遮蔽导致训练场景有限,导致过拟合。过拟合是指模型对训练数据表现非常好,但对测试数据(新数据)表现不佳。RoBERTa引入了动态遮蔽,为每个时代生成新的遮罩,提高了处理新数据的能力。
- 训练数据不足:BERT的训练基于大约16GB的文本数据集,这不足以捕捉语言的全部多样性。RoBERTa扩大了训练数据,使用了来自不同来源的超过160GB的文本。
- 训练时间短:原始的BERT模型训练时间相对较短,但RoBERTa显著延长了训练时间,运行了更多的时代和迭代。
- 小批量大小和保守的学习率:BERT的预训练使用了相对较小的批量大小和保守的学习率,这是一种安全但限制性的方法。另一方面,RoBERTa尝试了更大的批量大小和更激进的学习率,这导致了更好的模型表现。
RoBERTa是什么以及它如何工作?
RoBERTa(A Robustly Optimized BERT Pretraining Approach)是BERT的改进版本,旨在解决其局限性以提高性能。它对BERT的训练过程进行了修改,提高了其在自然语言处理任务上的表现。
这些修改包括:
- 动态遮蔽
- 移除下一句预测(NSP)
- 更大的训练数据和延长持续时间
- 增加批量大小
- 字节文本编码
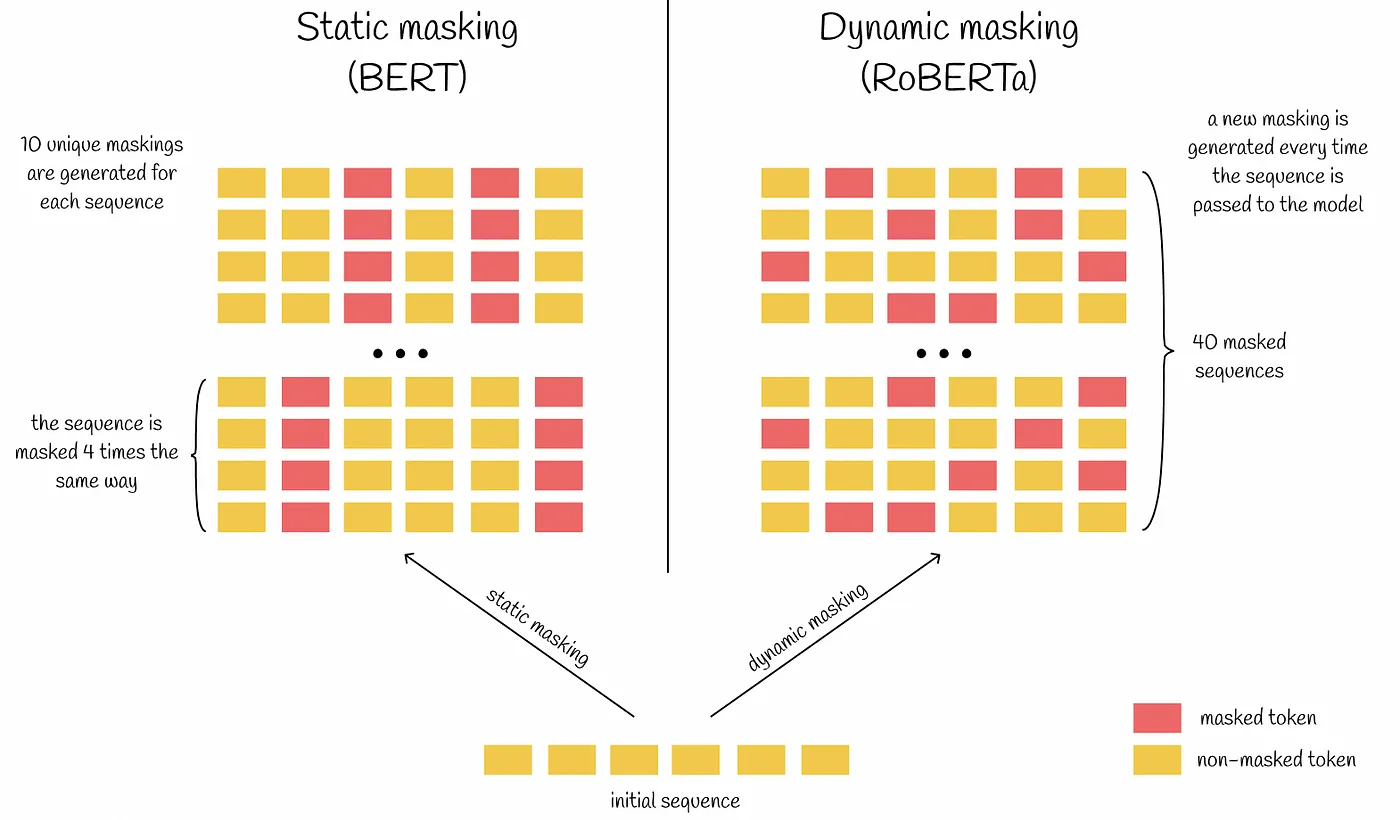
动态遮蔽
从BERT的架构中,我们记得在预训练期间,BERT通过尝试预测一定百分比的遮蔽标记来执行遮蔽语言模型(MLM)。这些选定的遮蔽标记在每次迭代中都是相同的(静态)。
RoBERTa通过实施一种称为动态遮蔽的更好方法来解决这个问题。这种方法在训练期间每次将序列传递给BERT时都会改变遮罩方案。这种变化使训练数据更加多样化,允许模型学习更广泛的语言模式。结果,RoBERTa对上下文有了更深的理解,这提高了下游任务的表现。
 Static_masking_vs_dynamic_masking_3bea7302db.png
Static_masking_vs_dynamic_masking_3bea7302db.png
图3:静态遮蔽与动态遮蔽
开发RoBERTa的研究人员还通过将训练数据复制10次来重新实现了静态遮蔽方法。这种复制允许每个序列在40个训练时代中以十种不同的方式被遮蔽。因此,在训练期间,每个训练序列被看到四次具有相同的遮罩。与原始BERT模型相比,重新实现的静态遮蔽的性能相似。然而,动态遮蔽的表现略优于静态遮蔽。
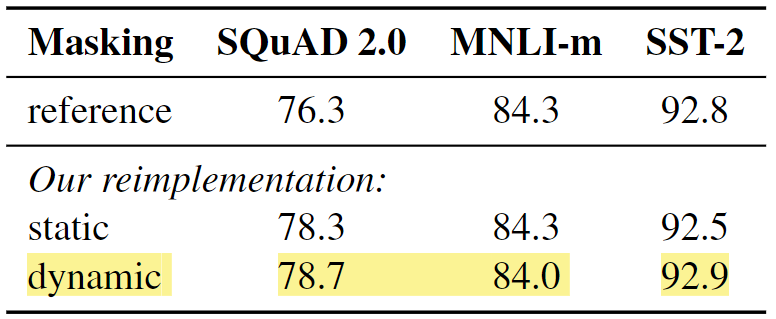 Comparison_between_static_and_dynamic_masking_08a2c71f3a.png
Comparison_between_static_and_dynamic_masking_08a2c71f3a.png
图4:静态和动态遮蔽的比较
移除下一句预测(NSP)
RoBERTa的另一个关键修改是移除了NSP任务。在NSP中,模型会被给定一对句子,并必须预测第二个句子是否跟随原始文本中的第一个。然而,RoBERTa的开发发现NSP任务对模型在下游任务上的表现贡献很小。
RoBERTa使用了全句方法(将多个文档的序列打包)。模型的每个输入都打包了来自一个或多个文档的完整句子,直到达到最大序列长度512个标记。这允许模型更有效地学习长期依赖关系。
 BERT_with_and_without_NSP_b558c39a4a.png
BERT_with_and_without_NSP_b558c39a4a.png
图5:带和不带NSP的BERT
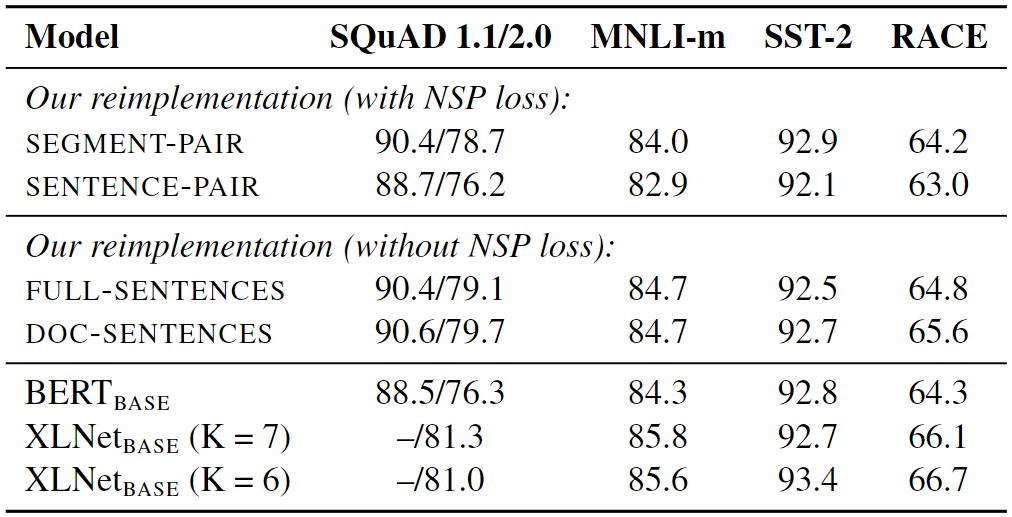
此外,研究人员还研究了四种不同的语言模型输入数据格式化方法。他们比较了两种主要格式:原始的SEGMENT-PAIR和SENTENCE-PAIR。两种格式都使用NSP,但SENTENCE-PAIR格式使用单个句子而不是对。研究人员发现使用单个句子使模型在任务上表现更差,因为它难以理解文本中相距较远的单词之间的联系。
接下来,他们通过在不使用NSP方法的情况下训练模型,并使用来自文档的文本块进行测试,称为DOC-SENTENCES。在大多数情况下,他们发现它比原始的BERT表现更好,不使用NSP损失并没有损害模型的表现。
单一文档的文本(DOC-SENTENCES)方法略优于多个文档(FULL-SENTENCES)。然而,由于DOC-SENTENCES在训练期间导致了不同的批量大小,他们决定在其余实验中使用FULL-SENTENCES。这个选择使得他们的结果更容易与其它相关研究的结果进行比较。
 Results_for_base_models_pre_trained_over_BOOK_CORPUS_and_WIKIPEDIA_c3510a6544.png
Results_for_base_models_pre_trained_over_BOOK_CORPUS_and_WIKIPEDIA_c3510a6544.png
图6:在BOOK CORPUS和WIKIPEDIA上预训练的基础模型的结果
更大的训练数据和延长持续时间
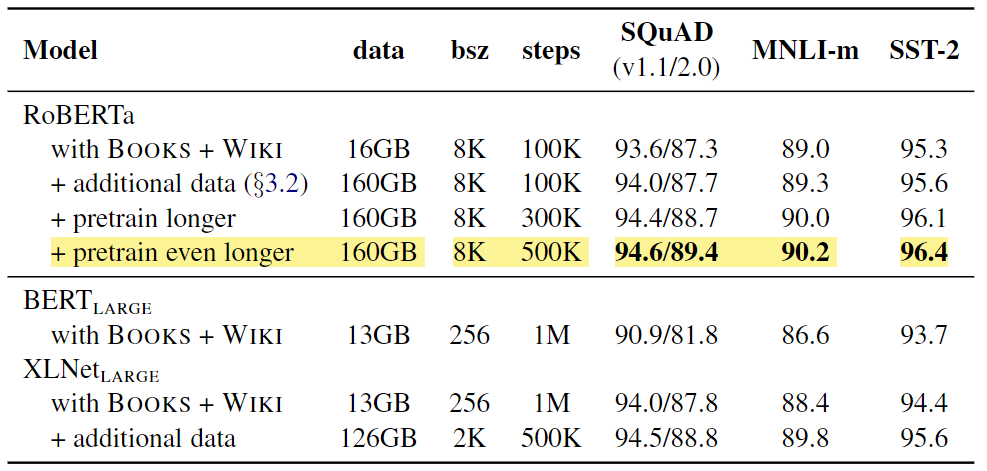
也许最直接的优化,但同样重要的是,简单地在更多的数据上训练更长时间。BERT在大约16GB的文本数据集上训练,而RoBERTa使用了超过160GB的文本。
RoBERTa数据集:
- BOOK-CORPUS和WIKIPEDIA:与BERT相同。
- CC-NEWS:RoBERTa引入了一个新的数据集,称为CC-NEWS,这是一个大规模新闻数据集,包含当代语言以及广泛的主题、风格和视角。
- 其他数据集:RoBERTa将上述数据集与论文中描述的另外三个私有数据集合并,提高了下游任务的表现。
使用更大的训练数据,延长训练持续时间,并运行更多的时代和迭代,与原始BERT结果相比,RoBERTa在下游任务上表现出4-6%的大幅提升(Devlin等人,2018年)。
 Results_for_Ro_BER_Ta_over_the_BERT_cf6c2edbb5.png
Results_for_Ro_BER_Ta_over_the_BERT_cf6c2edbb5.png
图7:RoBERTa相对于BERT的结果
增加批量大小
神经机器翻译的过去工作表明,使用非常大的小批量训练可以改善遮蔽语言建模的困惑度。当学习率适当增加时,这种方法提高了最终任务的表现(Ott等人,2018年)。困惑度是衡量语言模型表现的指标。它量化了模型在预测序列中的下一个单词时的不确定性(概率分布)。例如,困惑度越低,预测越准确。
基于这一概念,RoBERTa在训练期间使用更大的小批量。BERT使用每百万步256个序列的批量大小,RoBERTa将其增加到31000步的8k序列,学习率值为1e-3。然而,最佳表现是在125000步的2k序列时看到的。
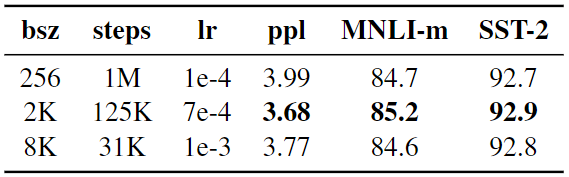 Comparison_of_Perplexity_and_End_Task_Performance_of_BERT_vs_Ro_BER_Ta_ae817fed91.png
Comparison_of_Perplexity_and_End_Task_Performance_of_BERT_vs_Ro_BER_Ta_ae817fed91.png
图8:BERT与RoBERTa的困惑度和最终任务表现比较
字节文本编码
RoBERTa还引入了一种处理词汇表外(OOV)单词的替代方法,通过使用字节级别的字节对编码(BPE)。BERT使用了30K单位的字符级字节对编码(BPE)词汇表。RoBERTa将其扩展到50K子词单元的字节级BPE词汇表,无需额外的输入预处理或标记化。与BERT相比,这种方法允许RoBERTa编码几乎所有单词或子词,而不需要使用未知标记。
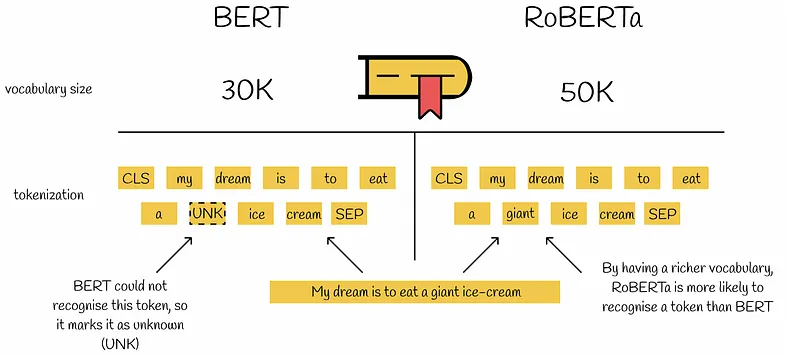 Byte_text_encoding_7bf84b698e.png
Byte_text_encoding_7bf84b698e.png
图9:字节文本编码
实验结果
修改BERT(Devlin等人,2019年)后,RoBERTa在NLP基准测试上进行了测试。我们将讨论其在三个基准测试上的表现:GLUE、SQuAD和RACE。
- GLUE(General Language Understanding Evaluation):用于NLU(自然语言理解)任务的9个数据集合。
- SQuAD(Stanford Question Answering Dataset):为训练和评估问答系统而设计的数据集。它由人类在一组维基百科文章上提出的真正问题组成,每个问题的答案都是相应文章中特定的文本跨度。
- RACE(Reading Comprehension from Examinations):从英语考试中收集的大规模阅读理解数据集。
在GLUE数据集上的测试结果
RoBERTa使用两种微调设置进行了测试。在第一种设置(单任务)中,RoBERTa分别为每个GLUE任务微调了10个时代,仅使用相应任务的训练数据。它在所有九个GLUE任务上都取得了最先进的结果,超越了BERT和XLNet。在第二种设置(集成)中,RoBERTa在GLUE排行榜上得分88.5,与XLNet之前设定的最先进的结果相匹配。RoBERTa在9个GLUE任务中的4个设定了新的最先进的结果:MNLI、QNLI、RTE和STS-B。
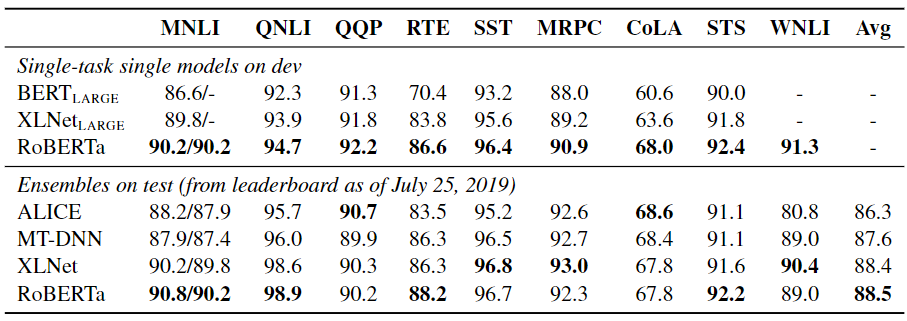 Results_on_GLUE_8ebb390177.png
Results_on_GLUE_8ebb390177.png
图10:GLUE上的结果
SQuAD
RoBERTa使用SQuAD训练数据进行了微调。在SQuAD v1.1上,RoBERTa与XLNet设定的最先进的结果相匹配。在SQuAD v2.0上,RoBERTa取得了89.4的F1分数,为单模型设定了新的最先进的结果,没有数据增强。考虑到RoBERTa没有使用任何SQuAD特定技术,并且仅在SQuAD数据上进行了微调,这尤其令人印象深刻。
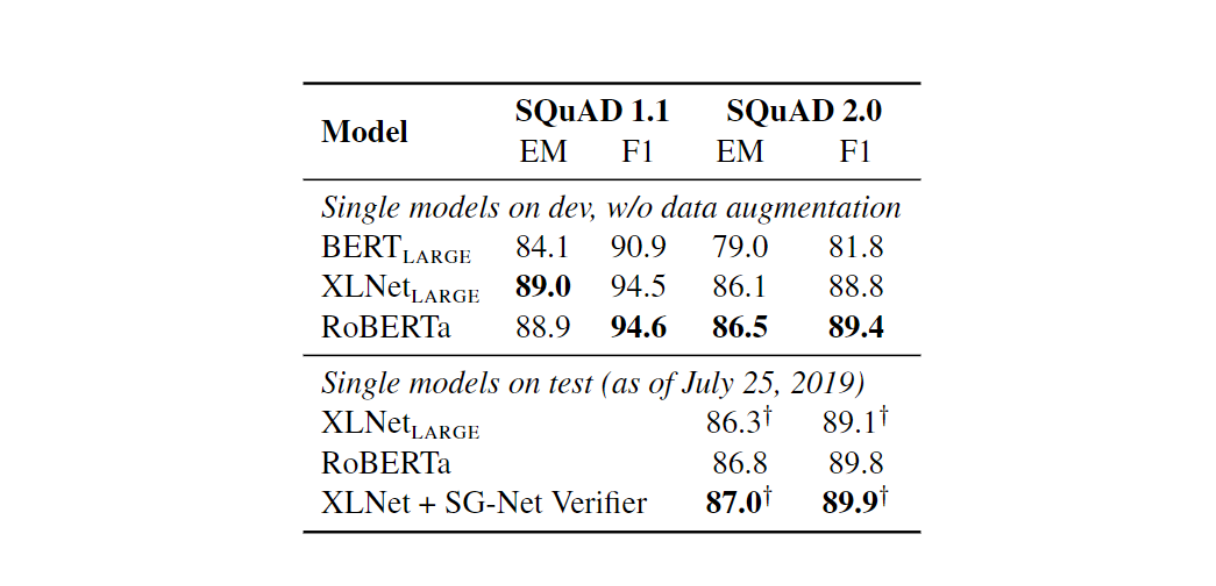 Results_on_S_Qu_AD_f8b1eed124.png
Results_on_S_Qu_AD_f8b1eed124.png
图11:SQuAD上的结果
在RACE数据集上的测试结果
RACE是一个具有挑战性的阅读理解基准,要求模型基于英语考试的段落回答多项选择题。这个基准特别困难,因为它要求模型理解复杂段落,并根据上下文推断正确答案。RoBERTa在RACE基准上取得了83.2%的准确率,并设定了新的最先进的标准。
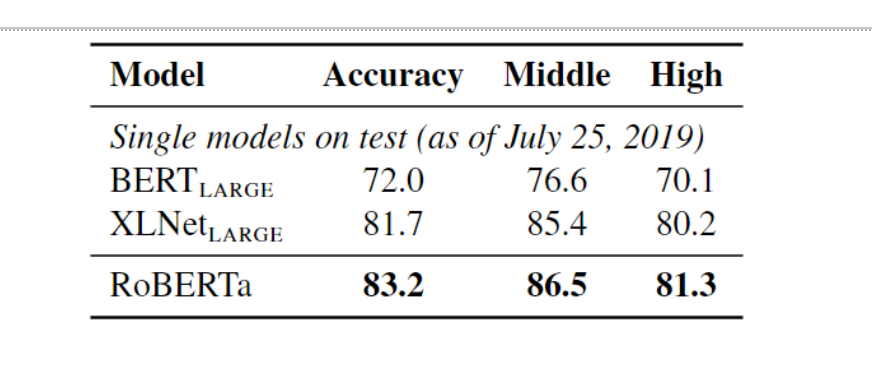 Results_on_the_RACE_test_set_00eff370bd.png
Results_on_the_RACE_test_set_00eff370bd.png
图12:RACE测试集上的结果
对RoBERTa进行微调以进行情感分析
除了在标准基准测试中的表现外,RoBERTa还证明对特定任务(如情感分析)的微调非常有效。微调是取一个预训练模型,并将其适应特定任务,通过在较小的任务特定数据集上训练它。本文使用的源代码来自Hugging Face。
导入和准备数据集
我们将使用Kaggle Competition上可用的数据集,并仅参考数据转储中的第一个csv文件:train.tsv。
导入Python库:
!pip install transformers==3.0.2
导入在这一步运行我们的脚本所需的库和模块。
# Importing the libraries needed
import pandas as pd
import numpy as np
import torch
import transformers
import json
from tqdm import tqdm
from torch.utils.data import Dataset, DataLoader
from transformers import RobertaModel, RobertaTokenizer
import logging
logging.basicConfig(level=logging.ERROR)
# Setting up the device for GPU usage
from torch import cuda
device = 'cuda' if cuda.is_available() else 'cpu'
准备数据集
首先,使用Pandas包加载数据集并读取它。
train = pd.read_csv('train.tsv', delimiter='\t')
new_df = train[['Phrase', 'Sentiment']]
让我们定义一些变量:
- MAX_LEN:输入文本的最大长度(256)。
- TRAIN_BATCH_SIZE和VALID_BATCH_SIZE:训练和验证的批量大小(分别为8和4)。
- LEARNING_RATE:模型的学习率(1e-05)。
- Tokenizer:使用RobertaTokenizer实例预处理文本数据。
SentimentData类实现了一个自定义数据集类,接受数据框、标记器和最大长度作为输入。它预处理文本数据,返回包含输入ID、注意力掩码、标记类型ID和目标情感标签的字典。
DataLoader类为训练和测试集创建数据加载器,在训练和验证期间以批量方式迭代数据。
# Defining some key variables that will be used later on in the training
MAX_LEN = 256
TRAIN_BATCH_SIZE = 8
VALID_BATCH_SIZE = 4
LEARNING_RATE = 1e-05
tokenizer = RobertaTokenizer.from_pretrained('roberta-base', truncation=True, do_lower_case=True)
class SentimentData(Dataset):
def __init__(self, dataframe, tokenizer, max_len):
self.tokenizer = tokenizer
self.data = dataframe
self.text = dataframe.Phrase
self.targets = self.data.Sentiment
self.max_len = max_len
def __len__(self):
return len(self.text)
def __getitem__(self, index):
text = str(self.text[index])
text = " ".join(text.split())
inputs = self.tokenizer.encode_plus(
text,
None,
add_special_tokens=True,
max_length=self.max_len,
pad_to_max_length=True,
return_token_type_ids=True
)
ids = inputs['input_ids']
mask = inputs['attention_mask']
token_type_ids = inputs["token_type_ids"]
return {
'ids': torch.tensor(ids, dtype=torch.long),
'mask': torch.tensor(mask, dtype=torch.long),
'token_type_ids': torch.tensor(token_type_ids, dtype=torch.long),
'targets': torch.tensor(self.targets[index], dtype=torch.float)
}
train_size = 0.8
train_data=new_df.sample(frac=train_size,random_state=200)
test_data=new_df.drop(train_data.index).reset_index(drop=True)
train_data = train_data.reset_index(drop=True)
print("FULL Dataset: {}".format(new_df.shape))
print("TRAIN Dataset: {}".format(train_data.shape))
print("TEST Dataset: {}".format(test_data.shape))
training_set = SentimentData(train_data, tokenizer, MAX_LEN)
testing_set = SentimentData(test_data, tokenizer, MAX_LEN)
train_params = {'batch_size': TRAIN_BATCH_SIZE,
'shuffle': True,
'num_workers': 0
}
test_params = {'batch_size': VALID_BATCH_SIZE,
'shuffle': True,
'num_workers': 0
}
training_loader = DataLoader(training_set, **train_params)
testing_loader = DataLoader(testing_set, **test_params)
创建用于微调的神经网络
- 我们将创建一个带有RobertaClass的神经网络。
- 这个网络将有Roberta语言模型,后跟一个dropout,最后是一个线性层以获得最终输出。
- 数据将作为数据集中定义的输入传递给Roberta语言模型。
- 最后一层的输出将与情感类别进行比较,以确定模型预测的准确性。
- 我们将初始化一个名为Model的网络实例。这个实例将用于训练。
class RobertaClass(torch.nn.Module):
def __init__(self):
super(RobertaClass, self).__init__()
self.l1 = RobertaModel.from_pretrained("roberta-base")
self.pre_classifier = torch.nn.Linear(768, 768)
self.dropout = torch.nn.Dropout(0.3)
self.classifier = torch.nn.Linear(768, 5)
def forward(self, input_ids, attention_mask, token_type_ids):
output_1 = self.l1(input_ids=input_ids, attention_mask=attention_mask, token_type_ids=token_type_ids)
hidden_state = output_1[0]
pooler = hidden_state[:, 0]
pooler = self.pre_classifier(pooler)
pooler = torch.nn.ReLU()(pooler)
pooler = self.dropout(pooler)
output = self.classifier(pooler)
return output
model = RobertaClass()
model.to(device)
微调模型
在加载和准备数据集以及创建模型的所有努力之后,这可能是过程中较容易的一步。
在这里,我们定义了一个训练函数,该函数在上述训练数据集上训练模型指定的轮数。一个时代定义了完整的数据将通过网络的次数。
# Creating the loss function and optimizer
loss_function = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(params = model.parameters(), lr=LEARNING_RATE)
def calcuate_accuracy(preds, targets):
n_correct = (preds==targets).sum().item()
return n_correct
# Defining the training function on the 80% of the dataset for tuning the distilbert model
def train(epoch):
tr_loss = 0
n_correct = 0
nb_tr_steps = 0
nb_tr_examples = 0
model.train()
for _,data in tqdm(enumerate(training_loader, 0)):
ids = data['ids'].to(device, dtype = torch.long)
mask = data['mask'].to(device, dtype = torch.long)
token_type_ids = data['token_type_ids'].to(device, dtype = torch.long)
targets = data['targets'].to(device, dtype = torch.long)
outputs = model(ids, mask, token_type_ids)
loss = loss_function(outputs, targets)
tr_loss += loss.item()
big_val, big_idx = torch.max(outputs.data, dim=1)
n_correct += calcuate_accuracy(big_idx, targets)
nb_tr_steps += 1
nb_tr_examples+=targets.size(0)
if _%5000==0:
loss_step = tr_loss/nb_tr_steps
accu_step = (n_correct*100)/nb_tr_examples
print(f"Training Loss per 5000 steps: {loss_step}")
print(f"Training Accuracy per 5000 steps: {accu_step}")
optimizer.zero_grad()
loss.backward()
# # When using GPU
optimizer.step()
print(f'The Total Accuracy for Epoch {epoch}: {(n_correct*100)/nb_tr_examples}')
epoch_loss = tr_loss/nb_tr_steps
epoch_accu = (n_correct*100)/nb_tr_examples
print(f"Training Loss Epoch: {epoch_loss}")
print(f"Training Accuracy Epoch: {epoch_accu}")
return
EPOCHS = 1
for epoch in range(EPOCHS):
train(epoch)
输出:
 Figure_12_Details_of_the_model_training_9066a9191c.png
Figure_12_Details_of_the_model_training_9066a9191c.png
图13-模型训练的详细信息
验证模型性能
在验证阶段,我们将未见过的数据(测试数据集)传递给模型。这一步决定了模型在未见过的数据上的表现,即train.tsv的20%,在数据集创建阶段被分开。
验证阶段检查模型对新未见数据的泛化能力。模型的权重没有更新。只有最终输出与实际值进行比较,然后用于计算模型的准确性。
valid函数实现了验证阶段,接受模型和测试加载器作为输入。它将模型设置为评估模式,初始化变量以跟踪正确和错误的预测,并迭代测试加载器。对于每个批次,它计算损失和准确性,在每5000步和时代结束时打印验证损失和准确性。最后,它返回时代准确性。
def valid(model, testing_loader):
model.eval()
n_correct = 0; n_wrong = 0; total = 0; tr_loss=0; nb_tr_steps=0; nb_tr_examples=0
with torch.no_grad():
for _, data in tqdm(enumerate(testing_loader, 0)):
ids = data['ids'].to(device, dtype = torch.long)
mask = data['mask'].to(device, dtype = torch.long)
token_type_ids = data['token_type_ids'].to(device, dtype=torch.long)
targets = data['targets'].to(device, dtype = torch.long)
outputs = model(ids, mask, token_type_ids).squeeze()
loss = loss_function(outputs, targets)
tr_loss += loss.item()
big_val, big_idx = torch.max(outputs.data, dim=1)
n_correct += calcuate_accuracy(big_idx, targets)
nb_tr_steps += 1
nb_tr_examples+=targets.size(0)
if _%5000==0:
loss_step = tr_loss/nb_tr_steps
accu_step = (n_correct*100)/nb_tr_examples
print(f"Validation Loss per 100 steps: {loss_step}")
print(f"Validation Accuracy per 100 steps: {accu_step}")
epoch_loss = tr_loss/nb_tr_steps
epoch_accu = (n_correct*100)/nb_tr_examples
print(f"Validation Loss Epoch: {epoch_loss}")
print(f"Validation Accuracy Epoch: {epoch_accu}")
return epoch_accu
acc = valid(model, testing_loader)
print("Accuracy on test data = %0.2f%%" % acc)
输出:
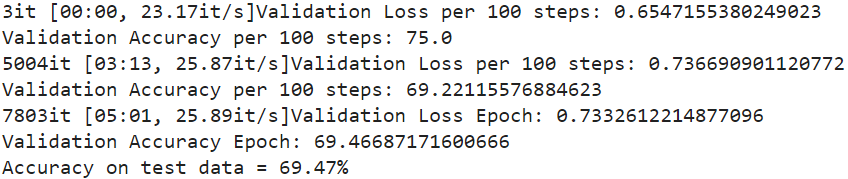 Figure_14_Details_of_the_model_validation_f9aa6e5607.png
Figure_14_Details_of_the_model_validation_f9aa6e5607.png
如您所见,模型以69.47%的准确率正确预测给定样本的类别,这一准确率可以通过更多训练进一步提高。
未来研究机会
RoBERTa的成功为NLP和模型优化领域的研究开辟了新的道路。以下是一些潜在的研究机会:
扩展数据集
更大的数据集和更长的训练时间提高了RoBERTa的表现。未来的研究可以调查动态数据集扩展,即模型随时间在越来越大的数据集上进行训练。这种方法可以帮助我们了解模型如何从新数据中学习,以及它是否可以随着数据规模的扩大而持续改进。
多任务微调
RoBERTa的表现可以通过探索先进的多任务微调程序进一步改善。目前,它在没有同时在多个任务上训练的情况下擅长很多事情。然而,研究人员可能会调查在微调阶段整合多个任务如何改善不同基准测试的表现。
探索预训练目标
移除NSP目标并在RoBERTa中使用动态遮蔽方法而不是静态遮蔽引发了关于是否有更好的方法来教授语言模型的问题。未来的研究可以探索不同的预训练方法,这些方法影响RoBERTa理解和完成任务的能力。
结论
RoBERTa论文对NLP领域做出了几项重要贡献。作者发现,在训练数据中动态改变遮罩模式、训练更长的序列以及移除NSP任务可以改善下游任务的表现。
此外,使用更大的批量大小和训练数据集也有助于这一改进。RoBERTa在GLUE、RACE和SQuAD上取得了最先进的结果,而无需对GLUE进行多任务微调或为SQuAD提供额外数据。
此外,RoBERTa与BERT之间的辩论不仅仅是关于哪个模型更好。它是关于理解计算资源、模型表现和部署这些模型的伦理含义之间的权衡。RoBERTa相对于BERT的进步表明,NLP领域远未停滞不前,并为更高级和复杂的语言处理能力铺平了道路。
 Haziqa Sajid
Haziqa SajidFreelance Technical Writer