



「X」Embedding in NLP|Token 和 N-Gram、Bag-of-Words 模型释义
ChatGPT(GPT-3.5)和其他大型语言模型(Pi、Claude、Bard 等)凭何火爆全球?这些语言模型的运作原理是什么?为什么它们在所训练的任务上表现如此出色?
虽然没有人可以给出完整的答案,但了解自然语言处理的一些基本概念有助于我们了解 LLM 内在工作原理。尤其是了解 Token 和 N-gram 对于理解几乎所有当前自回归和自编码模型都十分重要。本文为“「X」Embedding in NLP”的进阶版,将带大家详解 NLP 的核心基础!
01.Token 和 N-gram
在 C/C++ 的入门计算机科学课程中,通常很早就会教授字符串的概念。例如,C 语言中的字符串可以表示为以空字符终止的字符数组:
char my_str[128] = "Milvus";
在这个例子中,每个字符都可以被视为一个离散单位,将它们组合在一起就形成了有意义的文本——在这种情况下,my_str表示了世界上最广泛采用的向量数据库。
简单来说,这就是 N-gram 的定义:一系列字符(或下一段讨论的其他离散单位),当它们连在一起时,具有连贯的意义。在这个实例中,N 对应于字符串中的字符总数(在这个例子是 7)。
N-gram 的概念不必局限于单个字符——它们也可以扩展到单词。例如,下面的字符串是一个三元组(3-gram)的单词:
char my_str[128] = "Milvus vector database"
在上面的例子中,很明显my_str是由三个单词组成的,但一旦考虑到标点符号,情况就变得有些复杂:
char my_str[128] = "Milvus's architecture is unparalleled"
上面的字符串,严格来说,是四个单词,但第一个单词Milvus's是使用另一个单词Milvus作为基础的所有格名词。对于语言模型来说,将类似单词分割成离散的单位是有意义的,这样就可以保留额外的上下文:Milvus和's。这些被称为 Token,将句子分割成单词的基本方法称为标记化(Tokenization)。采用这种策略,上述字符串现在是一个由 5 个 Token 组成的 5-gram。
所有现代语言模型在数据转换之前都会进行某种形式的输入标记化。市面上有许多不同的标记器——例如,WordPiece 是一个流行的标记器,它被用在大多数 BERT 的变体中。在这个系列中我们没有过多深入标记器的细节——对于想要了解更多的人来说,可以查看 Huggingface的标记器总结
02.N-gram 模型
接下来,我们可以将注意力转向 N-gram 模型。简单来说,n-gram 模型是一种简单的概率语言模型,它输出一个特定 Token 在现有 Token 串之后出现的概率。例如,我们可以建模一个特定 Token 在句子或短语中跟随另一个Token(∣)的概率(p):
p(database∣vector)=0.1
上述声明表明,在这个特定的语言模型中,“vector”这个词跟在“database”这个词后面的概率为 10%。对于 N-gram 模型,这些模型总是通过查看输入文档语料库中的双词组的数量来计算,但在其他语言模型中,它们可以手动设置或从机器学习模型的输出中获取。
上面的例子是一个双词模型,但我们可以将其扩展到任意长度的序列。以下是一个三元组的例子:
p(database∣Milvus,vector)=0.9
这表明“database”这个词将以 90% 的概率跟在“Milvus vector”这两个 Token 之后。同样,我们可以写成:
p(chocolate∣Milvus,vector)=0.001
这表明在“Milvus vector”之后出现的词不太可能是“chocolate”(确切地说,概率为0.1%)。将这个应用到更长的序列上:
p(Milvus∣the,most,widely,adopted,vector,database,is)=0.999
接下来讨论一个可能更重要的问题:我们如何计算这些概率?简单而直接的答案是:我们计算文档或文档语料库中出现的次数。我将通过以下 3 个短语的例子来逐步解释(每个句子开头的代表特殊的句子开始标记)。为了清晰起见,我还在每个句子的结尾句号和前一个词之间增加了额外的空格:
<S>Milvus是最广泛采用的向量数据库。<S>使用Milvus进行向量搜索。<S>Milvus很棒。
列出以<S>、Milvus或vector开头的双词组:
some_bigrams = {these bigrams begin with <S>
("<S>", "Milvus"): 2,
("<S>", "vector"): 1,these bigrams begin with Milvus
("Milvus", "is"): 1,
("Milvus", "."): 1,
("Milvus", "rocks"): 1,these bigrams begin with vector
("vector", "database"): 1,
("vector", "search"): 1
}
根据这些出现的情况,可以通过对每个 Token 出现的总次数进行规范化来计算概率。例如:
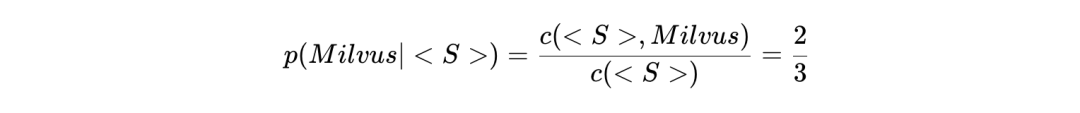
类似:
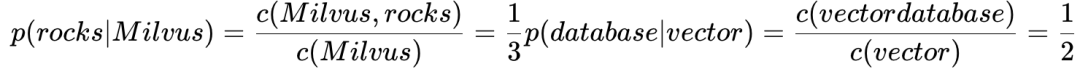
有了这些知识,我们就可以编写一些代码来构建一个双词模型。为了简单起见,我们假设所有输入文档中的每个 Token 都由一些空白字符分隔(回想一下前面的部分,现代标记器通常有更复杂的规则)。让我们从定义模型本身开始,即双词计数和 Token 计数:
from typing import Dict, Tuple
from collections import defaultdict
#keys correspond to tokensvalues are the number of occurences
token_counts = defaultdict(int)
#keys correspond to 2-tuples bigram pairsvalues are the number of occurences
bigram_counts = defaultdict(int)
def build_bigram_model(corpus):
"""Bigram model. """
#loop through all documents in the corpus
for doc in corpus:
prev = "<S>"
for word in doc.split():
#update token counts
token_counts[word] += 1
#update bigram counts
bigram = (prev, word)
bigram_counts[bigram] += 1
prev = word
#add a dummy end-of-sequence token so probabilities add to one
bigram_counts[(word, "</S>")] += 1
return (token_counts, bigram_counts)
def bigram_probability(bigram: Tuple[str]):
"""Computes the likelihood of the bigram from the corpus. """
return bigram_counts[bigram] / token_counts[bigram[0]]
然后,build_bigram_model会遍历整个文档语料库,先按空白字符分割每个文档,再存储双词组和 Token 计数。然后,我们可以调用bigram_probability函数,该函数查找相应的双词组计数和 Token 计数,并返回比率。
我们在 Milvus 的文档上测试这个模型,大家可以在此下载文档,并尝试上面的代码。
with open("README.md", "r") as f:
build_bigram_model([f.read()])
print(bigram_probability(("vector", "database")))
0.3333333333333333
03.词袋模型
除了 N-gram,另一个值得讨论的是词袋模型(BoW)。词袋模型将文档或文档语料库表示为一个无序的 Token 集合——从这个意义上说,它保持了每个 Token 出现的频率,但忽略了它们在每个文档中出现的顺序。因此,BoW 模型中的整个文档可以转换为稀疏向量,其中向量的每个条目对应于文档中特定单词出现的频率。在这里,我们将文档“Milvus 是最广泛采用的向量数据库。使用Milvus进行向量搜索很容易。”表示为一个 BoW稀疏向量:
limited vocabularybow_vector = [
0, # a
1, # adopted
0, # bag
0, # book
0, # coordinate
1, # database
1, # easy
0, # fantastic
0, # good
0, # great
2, # is
0, # juggle
2, # Milvus
1, # most
0, # never
0, # proof
0, # quotient
0, # ratio
0, # rectify
1, # search
1, # the
0, # undulate
2, # vector
1, # widely
1, # with
0, # yes
0, # zebra
]
这些稀疏向量随后可以用于各种 NLP 任务,如文本和情感分类。关于词袋模型的训练和推理学习可参考 Jason Brownlee的博客。
虽然词袋模型易于理解和使用,但它们有明显的局限性,即无法捕捉上下文或单个 Token 的语义含义,这意味着它们不适合用于最简单的任务之外的任何事情。
04.总结
在这篇文章中,我们讨论了自然语言处理的三个核心基础:标记化(Tokenization)、N-gram 和词袋模型。围绕 N-gram 的概念有助于后续了解关于自回归和自编码模型的训练方式。在下一个教程中,我们将分析“现代”NLP,即循环网络和文本 embedding。敬请期待!
 Frank Liu
Frank Liu

