



英伟达首席工程师Corey: HNSW+CPU过时了!GPU+RAPIDS cuVS才是向量检索最优解
导读
在生产环境中,性能直接决定了我们对AI的使用体验。但通常来说,向量搜索是一项资源密集型任务。存储的数据越多,计算成本和时间消耗就越高。因此,在RAG部署中,如何解决向量检索的性能瓶颈,是我们需要重点关注的内容。
在最近由Zilliz主办的非结构化数据会议上,NVIDIA的首席工程师Corey Nolet讨论了NVIDIA在解决这一问题上的最新进展。
完整内容详见YouTube上Corey的演讲:https://youtu.be/pBaq3CcZOFc
在本篇文章中,我们将重点介绍NVIDIA的cuVS,包含多种与向量检索相关的算法,并能高效利用GPU的加速能力。
向量搜索及向量数据库的作用
向量搜索是一种信息检索方法,其中用户的查询和被搜索的内容(图像、文本、视频等),都会以向量的格式呈现。
非结构化数据转化为向量过程中,会生成多少维度,这取决于我们采用哪种embedding算法。例如,如果我们使用HuggingFace的all-MiniLM-L6-v2模型将查询转换为向量,我们将得到一个384维向量。向量的取值代表了相应的数据或文档的语义信息。因此,如果两段数据相似,它们对应的向量在向量空间中的位置也会接近。
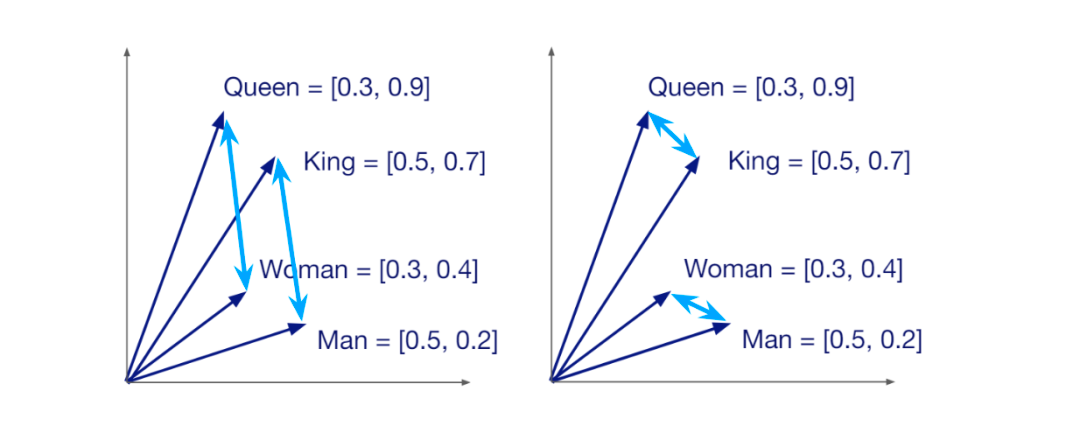 向量空间中向量之间的语义相似性.png
向量空间中向量之间的语义相似性.png
向量空间中向量之间的语义相似性
由于每个向量都携带了其所代表数据的语义信息,我们可以计算任意一对向量之间的相似性。如果它们相似,相似性得分就会很高,反之亦然。向量搜索的主要目的是找到与查询向量最相似的向量。
当处理少量文档时,向量搜索的实现相对简单。然而,随着文档数量的增加和需要存储的向量增多,复杂性也会增加。向量越多,执行向量搜索所需的时间就越长。此外,随着我们在本地内存中存储更多的向量,耗费的成本也会显著增加。因此,我们需要一个可扩展的解决方案,这就是向量数据库的用武之地。
向量数据库为存储大量向量提供了高效、快速且可扩展的解决方案。它们提供了先进的索引方法,以在向量搜索操作中加快检索速度,同时还能够轻松集成流行的AI框架,简化AI应用的开发过程。在Milvus和Zilliz Cloud(托管版Milvus)等向量数据库中,我们还可以存储向量的元数据,并在搜索操作中执行高级过滤。
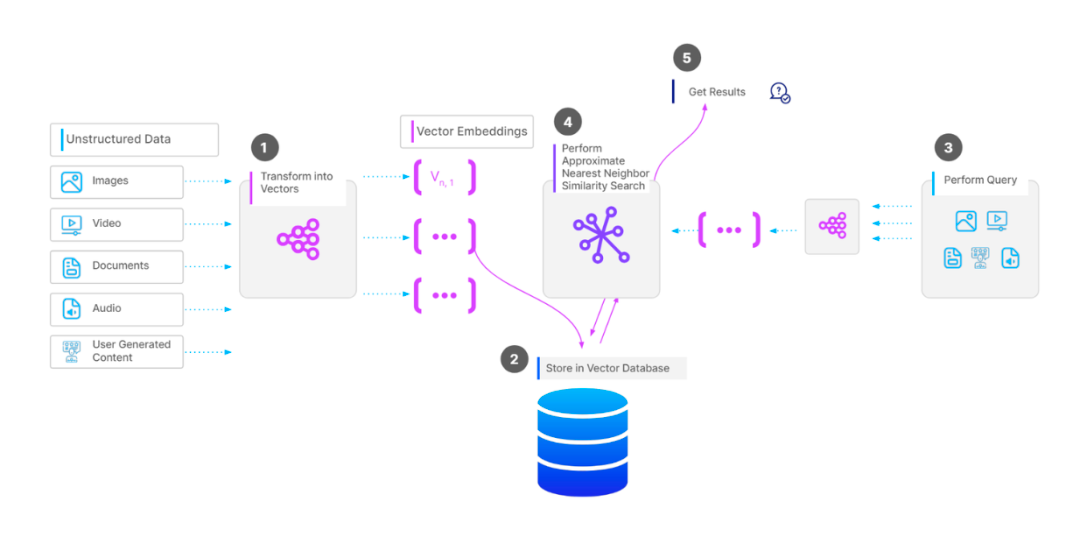 一个向量搜索操作的工作流.png
一个向量搜索操作的工作流.png
一个向量搜索操作的工作流
为了在Milvus等向量数据库中存储向量集合,第一步是根据数据类型进行数据预处理。例如,如果我们的数据是文档集合,我们可以将每个文档中的文本分割成块。接下来,我们使用选择的embedding模型将每个块转换为向量。然后,我们将所有向量导入向量数据库,并为其构建索引,以便在向量搜索操作中更快地检索。
当我们有一个查询并希望执行向量搜索操作时,我们使用之前相同的embedding模型将查询转换为向量,然后计算其与数据库中向量的相似性。最后,返回最相似的向量。
CPU上的向量检索操作
向量检索操作需要大量的计算,随着我们在向量数据库中存储更多的向量,计算成本也会增加。有几个因素直接影响计算成本,例如索引构建、向量总数、向量维度以及期望的搜索结果质量。
CPU是向量检索的核心硬件资源,许多向量检索算法都针对CPU进行了全面优化,其中最流行的是分层可导航小世界(HNSW)。
HNSW的核心思想结合了跳表(skip list)和可导航小世界(NSW)的概念。在NSW算法中,每个节点(或称为顶点)都会与相似的节点相连,组成一张完整的NSW图。其检索的底层逻辑是贪婪路由搜索,从任意节点开始,检索起相邻节点中与其更加相似的节点,然后转移到该节点,过程循环往复,直到找到局部最小值,即当前节点比之前访问的任何节点都更接近查询向量,此时停止搜索。
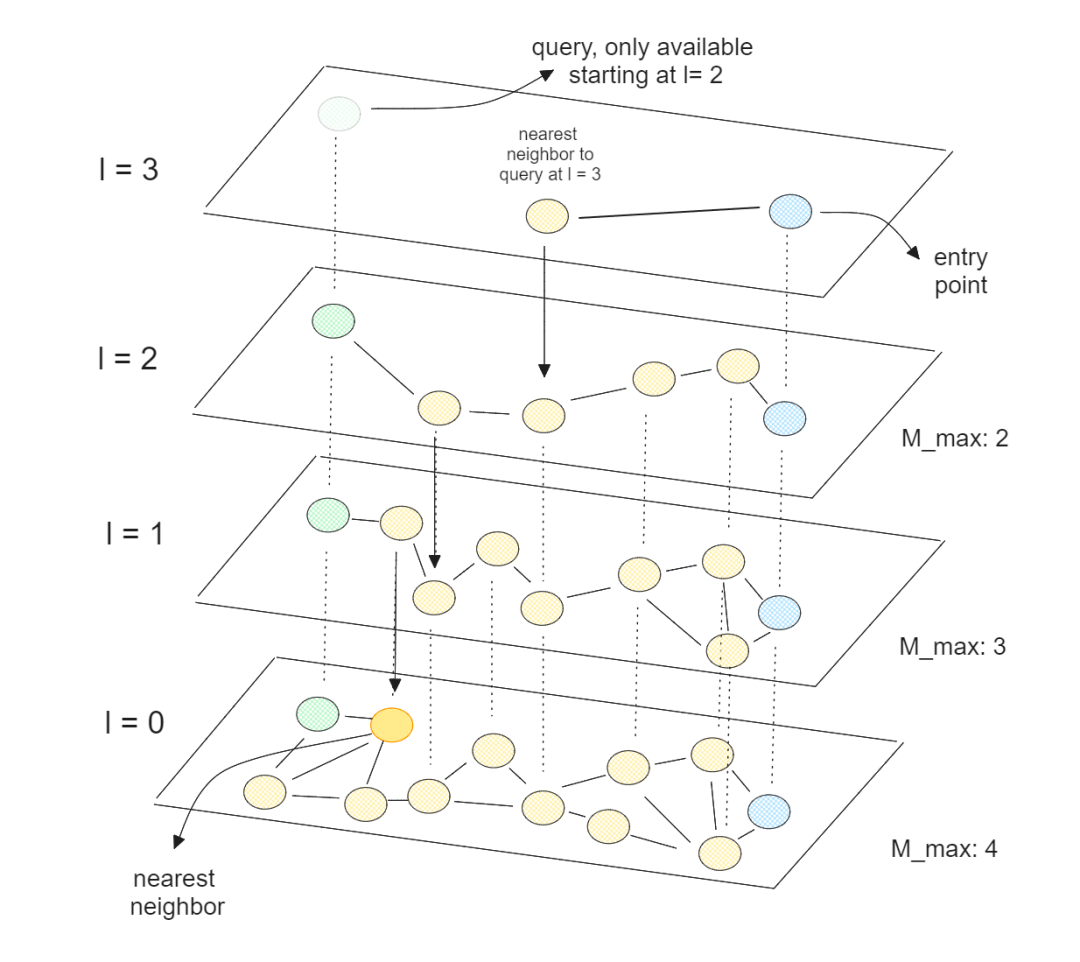 用HNSW来做向量搜索.png
用HNSW来做向量搜索.png
用HNSW来做向量搜索
HNSW是一个多层的NSW,其中最低层包含所有数据点,而最高层仅包含数据点的一小部分。这意味着层数越高,跳过的数据点越多,这与跳表的理论相对应。
通过HNSW,我们得到了一个图,其中大多数节点可以通过很少数量的计算从任何其他节点到达。这一特性使得HNSW能够快速高效地遍历图,找到近似最近邻。由于HNSW针对CPU进行了优化,我们还可以在多个CPU核心上并行执行,以进一步加速向量搜索过程。
然而,随着我们在向量数据库中存储更多数据,HNSW的计算时间仍然会受到影响。如果向量的维度非常高,情况可能会更糟。因此,在处理大量高维向量时,我们需要另一种解决方案。
GPU上的向量搜索操作
在处理大量高维向量时,提升向量搜索性能的一种解决方案是在GPU上操作。为此,我们可以利用NVIDIA的RAPIDS cuVS库,该库包含多种针对GPU优化的向量检索算法。它极大提升了GPU在向量检索和索引构建的效率。
cuVS提供了多种最近邻算法可供选择,包括:
Brute-force(暴力搜索):一种穷举最近邻检索算法,可以对数据库中的每个向量进行比较与检索。
IVF-Flat:一种近似最近邻(ANN)算法,将数据库中的向量划分为多个不相交的分区。检索时仅与同一分区(以及可选相邻分区)中的向量进行比较。
IVF-PQ:IVF-Flat的量化版本,减少了数据库中存储向量的内存占用。
CAGRA:一种类似于HNSW的GPU原生算法。
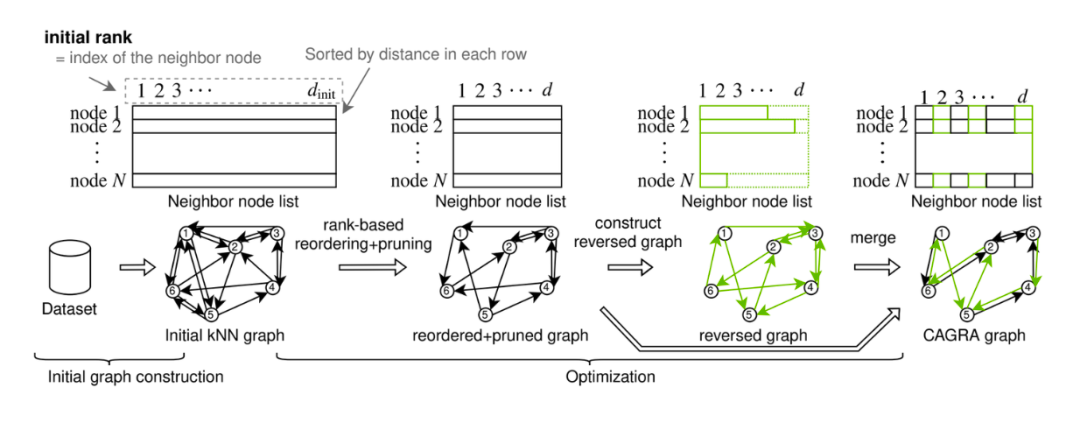 CAGRA图结构.png
CAGRA图结构.png
CAGRA图结构
在这些最近邻算法中,我们将重点介绍CAGRA。
CAGRA是NVIDIA引入的一种基于图的算法,用于快速高效的近似最近邻搜索,可以充分利用GPU的并行处理能力。
CAGRA中的图可以使用IVF-PQ方法或NN-DESCENT方法构建:
IVF-PQ方法:通过将每个点与邻近点相连,利用索引创建一个内存友好的初始图。
NN-DESCENT方法:通过局部搜索和迭代优化的方式,可以高效地构建近似 K-NN 图,广泛应用于各种需要快速近邻搜索的场景。
与HNSW相比,CAGRA的图构建方法更容易并行化,并且任务之间的数据交互更少,这显著提高了图或索引的构建时间。如果你想了解更多关于CAGRA的详细信息,可以查看其官方论文或CAGRA文章。
CAGRA与HNSW性能比较
在向量搜索中,有两个性能至关重要的关键操作:索引构建和检索。我们将比较CAGRA和HNSW在这两个操作中的性能。
首先来看索引构建:
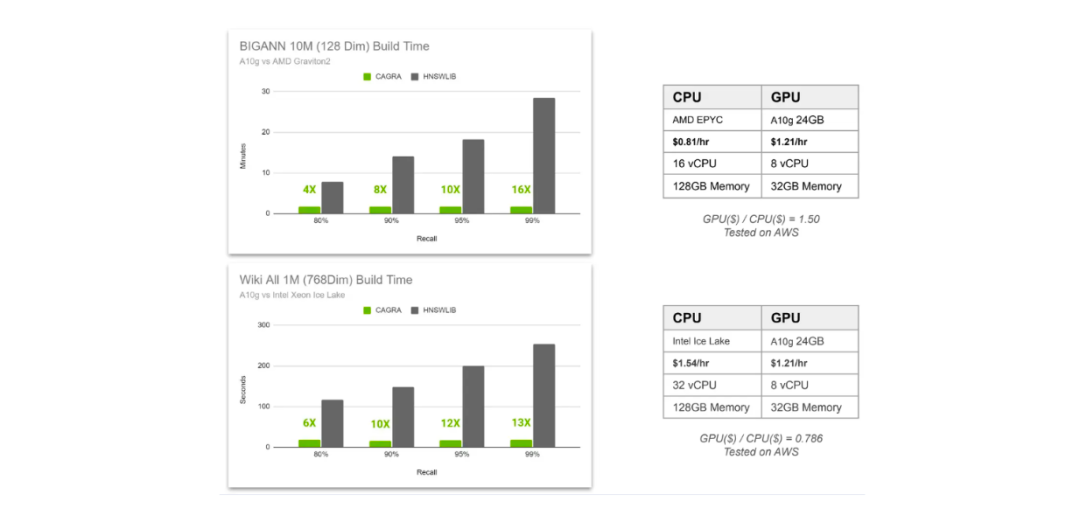 CAGRA和HNSW索引构建的时间对比.png
CAGRA和HNSW索引构建的时间对比.png
CAGRA和HNSW索引构建的时间对比
在上图中,我们比较了CAGRA和HNSW在两种不同场景下的索引构建时间。第一种场景是在向量数据库中存储了1000万个128维向量,第二种场景是存储了100万个768维向量。第一种场景使用AMD Graviton2作为HNSW的CPU,A10G GPU用于CAGRA,而第二种场景使用Intel Xeon Ice Lake作为HNSW的CPU,A10G GPU用于CAGRA。
我们在四个不同的召回值(从80%到99%)下比较了索引构建时间。
通常来说,在基于图的向量搜索中,我们可以微调两个参数:每层中用于查找最近邻的相邻点数量,以及每层中作为入口点的最近邻数量。召回值越高,需要的相邻点越多,检索精度也就越高,但计算成本也越高。
从上图中,我们看到当我们需要的召回结果越多越精细,使用GPU的好处越多。此外,随着向量数据库中存储的高维向量数量增加,使用GPU的加速效果也会增强。
接下来,我们使用向量搜索中的两个常见指标来比较HNSW和CAGRA的性能:
吞吐量:在特定时间间隔内可以完成的查询数量。
延迟:算法完成一个查询所需的时间。
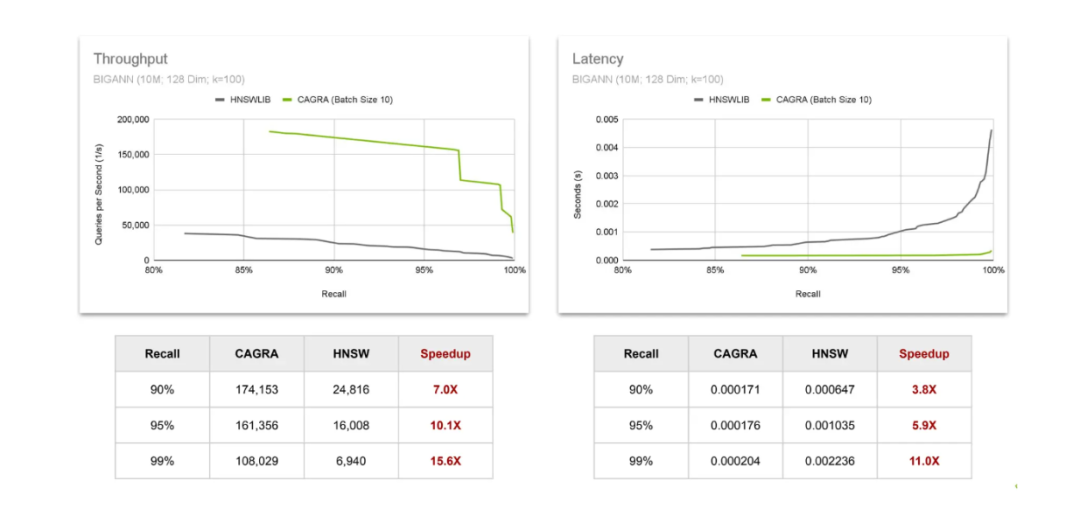 CAGRE和HNSW在吞吐量和延迟两方面的对比.png
CAGRE和HNSW在吞吐量和延迟两方面的对比.png
CAGRE和HNSW在吞吐量和延迟两方面的对比
为了评估吞吐量,我们观察一秒钟内可以完成的查询数量。结果显示,随着我们要求更高的召回值,使用CAGRA在GPU上的加速效果也会增加。延迟方面也观察到相同的趋势,随着召回值的增加,加速效果也会增强。这证实了随着我们寻求更精确的向量搜索结果,使用GPU的价值也在增加。
不过向量检索中,CPU依旧是必要的,因为它简单且易于与AI应用中的其他组件集成。在这一背景下,我们依然可以使用CAGRA实现最近邻算法,因为我们可以之后在GPU和CPU上执行向量搜索。
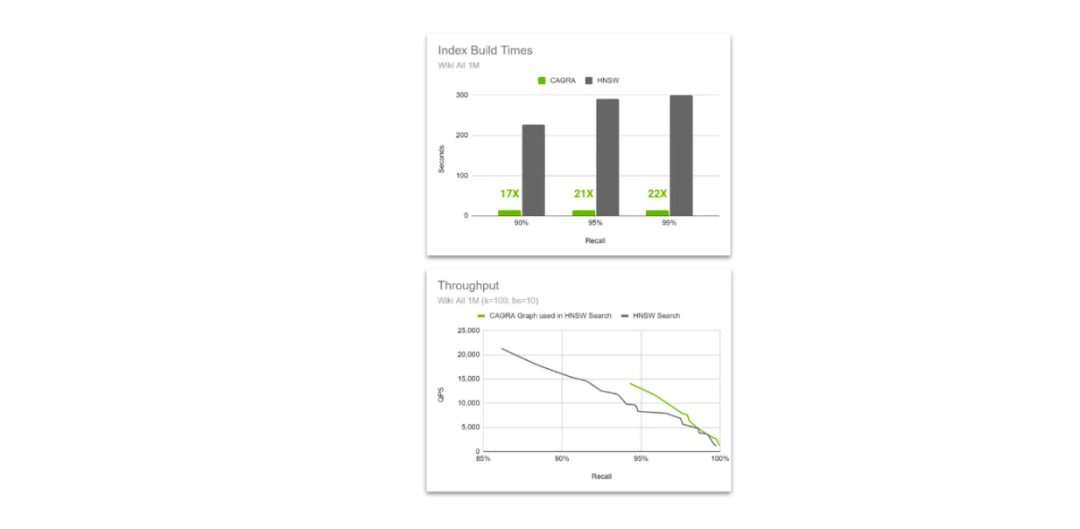 在HNSW搜索中对比原生HNSW和CAGRA图的吞吐量.png
在HNSW搜索中对比原生HNSW和CAGRA图的吞吐量.png
在HNSW搜索中对比原生HNSW和CAGRA图的吞吐量
其核心逻辑是在索引构建期间利用CAGRA和GPU的加速能力,但在向量搜索期间切换到HNSW。这种方法之所以可行,是因为HNSW算法可以使用CAGRA构建的图执行搜索,并且随着向量维度的增加,其性能甚至比使用HNSW构建的图更好。
CAGRA还提供了一种名为CAGRA-Q的量化方法,以进一步压缩存储向量的内存。这对于提高内存分配效率特别有帮助,并允许我们在较小的设备内存上存储量化向量以实现更快的检索。
假设我们有一个设备内存,其内存大小小于主机内存。NVIDIA的初步性能基准测试表明,在较高召回率下,存储在设备内存中的量化向量与存储在设备内存中的原始未量化向量和图相比,性能相似。
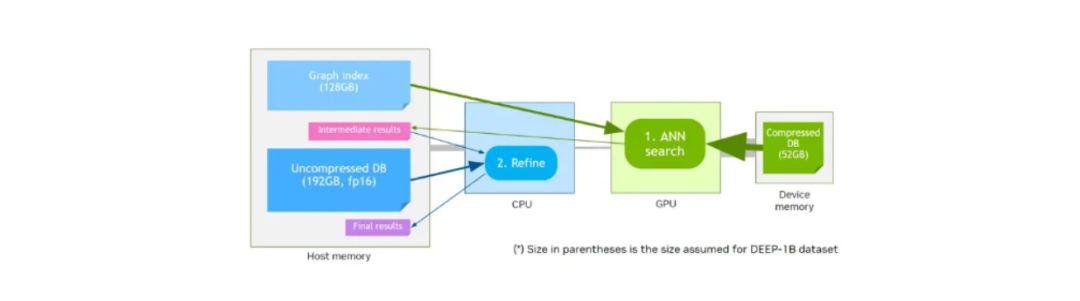 利用设备内存和CAGRA-Q的向量搜索工作图.png
利用设备内存和CAGRA-Q的向量搜索工作图.png
利用设备内存和CAGRA-Q的向量搜索工作图
使用cuVS的Milvus在GPU上的表现
Milvus支持与cuVS库的集成,使我们能够将Milvus与CAGRA结合以构建AI应用。Milvus的架构由多个节点组成,例如索引节点、查询节点和数据节点。cuVS可以通过加速查询节点和索引节点中的流程来优化Milvus的性能。
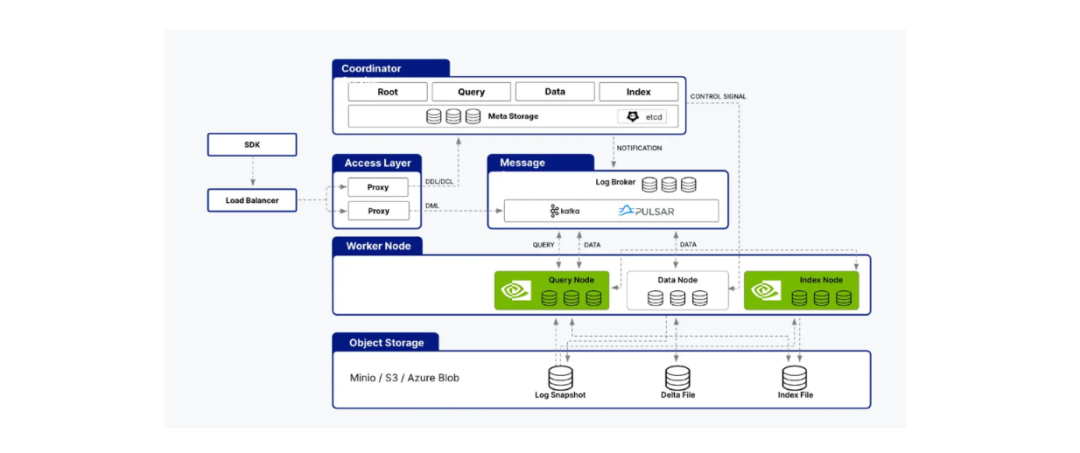 cuVS支持Milvus架构的索引和查询节点.png
cuVS支持Milvus架构的索引和查询节点.png
cuVS支持Milvus架构的索引和查询节点
现在,让我们看看使用cuVS和本地Milvus进行索引构建的性能。具体来说,我们将查看使用CAGRA和IVF-PQ在不同向量数量(1000万、2000万、4000万和8000万)下的索引构建时间。
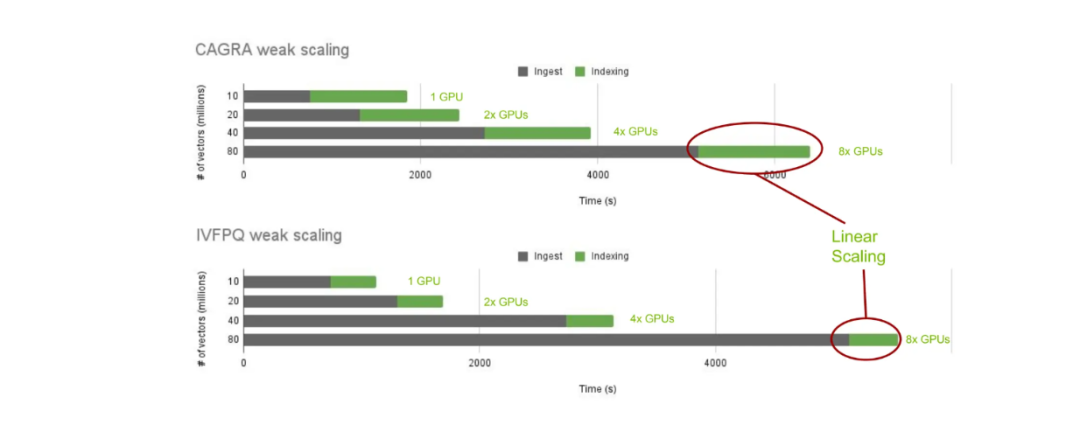 cuVS 在不同最近邻算法中索引构建时间的扩展性.png
cuVS 在不同最近邻算法中索引构建时间的扩展性.png
cuVS 在不同最近邻算法中索引构建时间的扩展性
正如预期的那样,随着存储向量数量的增加,数据导入时间也会增加。然而,我们可以根据存储的向量数量线性增加更多的GPU,索引构建时间保持不变。
我们知道,与CPU相比,GPU提供了更快的计算操作。然而,使用GPU的运营成本也更高。因此,我们需要比较使用Milvus在GPU和CPU的性能比,如下图所示。
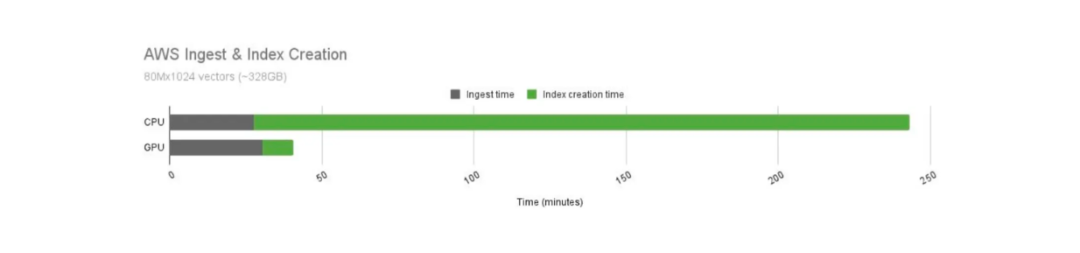 使用Milvus在GPU和CPU上做索引构建所需时间的对比.png
使用Milvus在GPU和CPU上做索引构建所需时间的对比.png
使用Milvus在GPU和CPU上做索引构建所需时间的对比
使用GPU的索引构建明显快于使用CPU。在这个例子中,GPU加速的Milvus比其CPU加速的Milvus快21倍。然而,GPU的运营成本也比CPU更昂贵。GPU每小时的成本为16.29美元,而CPU每小时的成本为9.68美元。
当我们对GPU和CPU的成本性能综合比较时,可以发现使用GPU进行索引构建仍然能带来更好的结果。在相同的成本下,使用GPU的索引构建时间快了12.5倍。
在另一个基准测试中,我们为6.35亿个1024维向量构建了索引。使用8个DGX H100 GPU,使用IVF-PQ方法的索引构建时间大约为56分钟。相比之下,使用CPU执行相同的任务大约需要6.22天才能完成。
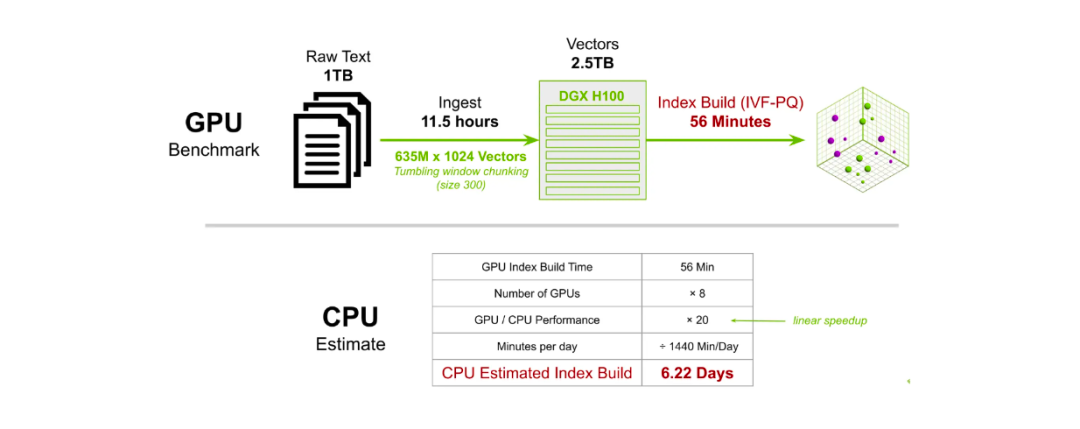 在 GPU 和 CPU 上做大规模Milvus索引构建所需时间的对比.png
在 GPU 和 CPU 上做大规模Milvus索引构建所需时间的对比.png
在 GPU 和 CPU 上做大规模Milvus索引构建所需时间的对比
结论
通过NVIDIA的cuVS库和CAGRA算法,GPU加速的向量搜索在涉及高召回值、高向量维度和大量向量的情况下,具有绝对优势。
得益于Milvus的集成能力,我们现在可以轻松地将cuVS集成到Milvus向量数据库中。尽管GPU的运营成本高于CPU,但在大规模应用中,性能成本比仍然倾向于GPU。
 Ruben Winastwan
Ruben WinastwanFreelance Technical Writer
keepReading

Turbopuffer vs. Zilliz Cloud:多租户向量检索实测对比
实测对比 Turbopuffer 与 Zilliz Cloud 在多租户向量检索中的召回率、延迟、成本与稳定性表现

观点|从Vector Database到Vector Lakebase,如何定义AI data infra的下一个十年
了解 Zilliz Vector Lakebase 如何统一非结构化数据、索引与计算,支撑 RAG、Agent 和批量处理。

Langflow + Milvus,拖拉拽就能搞定的workflow教程来了
如果你想写个agent或者workflow,但是又不想在demo阶段投入太多精力去敲代码;