掌握局部敏感哈希:全面教程和用例
随着数据维度的增加,检索任务(如查找最近邻)变得具有挑战性。这是因为数据点之间的距离增加导致了维度的诅咒、距离集中和空间空洞现象。因此,距离计算和相似性比较成为耗尽资源的任务。
局部敏感哈希(LSH)是解决高维数据检索挑战的游戏规则改变者。它通过在保持数据点之间局部距离的同时将相似项映射在一起,减少了有效数据检索的搜索空间。
LSH在数据科学和机器学习(ML)中扮演着重要角色,对抗“维度的诅咒”并实现实际的信息检索。通过将相似数据点聚集在一起,LSH允许高效的最近邻搜索、数据聚类以及其他需要在大型数据集中进行相似性搜索的任务。
理解LSH
向量对向量比较具有线性时间复杂度O(n),n是搜索空间的大小。将每个向量与每个其他向量进行比较将复杂度指数级提高到O(n^2)。
LSH旨在通过减少搜索空间来降低这种搜索复杂度。它使用高维欧几里得空间,所有数据点都位于其中,并将相似的数据点分组到桶中。
这是通过将一定距离阈值内的相似数据点散列到相同的桶中来实现的。更大的距离意味着更高的不同哈希概率,反之亦然。此外,LSH为每个数据点创建多个桶,每个桶使用不同的哈希函数形成。这增加了鲁棒性并提高了搜索相关性。
LSH的关键原则
LSH算法涉及两个关键步骤。这些包括:
创建多个哈希函数,为每个数据点生成哈希码。
将具有相同哈希码的数据点分配到相同的桶中。
 33.1.png
33.1.png
这种称为桶哈希的过程定义了LSH的关键原则:
局部性:局部性是LSH的核心原则,它指的是将相似的数据点映射到相同的桶中。这种属性保证了高维数据中的近似相似性搜索和聚类。
敏感性:敏感性指的是基于它们在哈希后的距离将不相似的点映射到不同的桶中。这确保了在相似性搜索期间过滤掉不相似的数据点。
近似结果:LSH提供近似搜索,意味着不相似的点可能最终在同一个桶中,相似的点在不同的桶中。这些错误的发生概率取决于哈希函数的设计和哈希表的数量。然而,减少搜索空间和可扩展性超过了潜在错误的可能。
探索LSH算法和实现
可以使用各种LSH算法来解决高维信息检索的挑战。
Minhash LSH
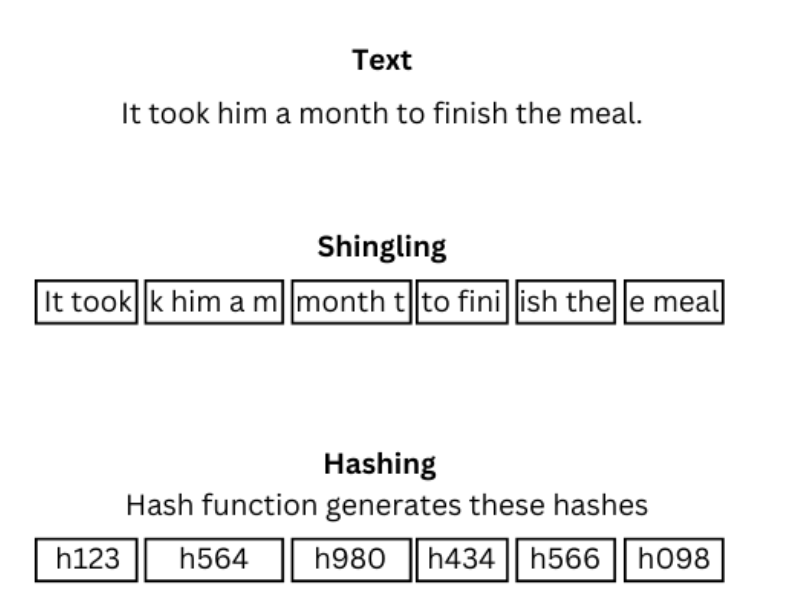
Minhash是一种适用于高维文档或集合的LSH算法。Minhash使用shingling方法,这指的是创建集合的重叠片段。一组随机哈希函数然后获取一组shingles并将它们映射到单个哈希值。
这确保了相似的文档落入相似的桶中。在搜索期间,搜索查询被哈希,其minhashed签名与相似桶中文档的minhashes进行比较。
以下代码演示了Python中LSH的基本实现:
from collections import defaultdict
  """
  Define a function that performs shingling and creates MinHash signatures for a set of data points.
  Args:
  data: A list of data points.
  num\_perm: The number of permutation functions.
  Returns:
  A dictionary with data points as keys and MinHash signatures as values.
  """
def minhash(data, num\_perm):
  minhash\_signatures = defaultdict(list)
  hash\_functions = \[lambda x: hash(str(x) + str(i)) for i in range(num\_perm)]
  for element in data:
  for hash\_function in hash\_functions:
  minhash\_signatures\[element].append(min(hash\_function(x) for x in data))
  return minhash\_signatures
 """
  Define a function that creates an LSH index, assigns items into buckets, and performs a similarity search.
  Args:
  data: A list of data points.
  num\_perm: The number of permutation functions.
  Returns:
  A dictionary where keys are data points and values are lists of similar data points based on MinHash signature.
  """
def lsh(data, num\_perm)
  minhash\_dict = minhash(data, num\_perm)
  index = defaultdict(list)
  for point, signature in minhash\_dict.items():
  bucket\_id = tuple(signature)
  index\[bucket\_id].append(point)
  similar\_items = {}
  for query, query\_signature in minhash\_dict.items():
  candidates = index\[tuple(query\_signature)]
  similar\_items\[query] = candidates
  return similar\_items
\# Example dataset
data = \["cat dog rabbit", "dog lizard bird", "cat bear crow", "lion lizard panda"]
\# Adjust permutations as required
num\_perm = 16
similar\_items = lsh(data, num\_perm)print("Similar items:")for query, items in similar\_items.items():
  print(f"\tQuery: {query}")
  print(f"\tItems: {items}")
Jaccard相似性的局部敏感哈希
针对Jaccard相似性的局部敏感哈希非常适合集合或二进制向量。它根据它们的Jaccard相似性识别相似的文档或集合。思想是定义一组随机超平面,位于超平面同一侧的文档被分配到相似的桶中。计算文档之间的Jaccard相似性以确保准确性,具有相似Jaccard得分的文档落入相似的桶中。
在搜索期间,搜索查询被投影到用于桶化的相同超平面上,并检索与查询落在相同超平面上的数据点以进行进一步评估。这意味着检索落在查询超平面同一侧的桶中的文档以进行进一步评估。
Python中的datasketch库提供了LSH实现的简单语法。以下是在Python中实现Jaccard相似性LSH的代码:
 33.2.png
33.2.png
球面LSH
球面LSH算法适用于位于单位球面上的数据点,如地理空间数据。它使用随机球面子空间来查找相似的数据点。位于相同球面子空间的数据点被映射到相似的桶中。计算数据点之间的余弦相似性以验证相似性。在搜索期间,搜索查询被投影到用于桶化的相同球面子空间上。与搜索查询落在相同球面子空间上的点被检索出来,以使用余弦相似性进行进一步的相似性评估。
Python中的lshash库为球面LSH实现提供了简单的语法。以下是在Python中实现它的代码:
from lshash import LSHash
\# Create a 6-bit hash function for input data with 8 dimensions
lsh\_hash = LSHash(6, 8)
\# Apply the hash function to each data point of 8 dimensions input
lsh\_hash.index(\[2, 3, 4, 5, 6, 7, 8, 9])
lsh\_hash.index(\[10, 12, 99, 1, 5, 31, 2, 3])
\# Query a single similar data point
num\_similar\_point = 1
nn = lsh\_hash.query(\[1, 2, 3, 4, 5, 6, 7, 7], num\_results=num\_similar\_point, distance\_func="cosine")print(nn)
LSH的实际应用
LSH对于从大型数据库中检索信息至关重要。它在数据科学应用中表现出色,显著提高了搜索速度,同时保持了准确性:
图像检索:从数百万图像的库中搜索相关图像在计算上是耗尽资源的。LSH从图像中提取特征向量,并将它们投影到较低的维度空间。相似的图像具有相似的特征向量,这些向量存储在相似的桶中。这显著减少了数据集的大小,从而加快了检索速度。
抄袭检测:LSH将文本文档转换为shingles的集合。在抄袭检测期间,算法识别具有相似shingles的文档,表明可能存在抄袭。然后对相关文档进行进一步评估,以验证抄袭。这允许在较短的时间内从大量文档中检测抄袭,同时保持结果的准确性。
近重复检测:近重复文档具有几乎相似的内容,但并不完全相同,即略微修改的产品描述或释义文本。Jaccard LSH是检测近重复文档的合适LSH算法,将文档投影到随机超平面上。然后使用Jaccard相似性将相似的文档映射到相似的桶中。这减少了搜索期间要扫描的文档数量,从而实现了更快、更有效的近重复检测。
LSH能够高效地在大型数据集中导航,以实现准确的信息检索,使其成为高效近似邻域搜索的重要工具。在保持高精度的同时减少相似性搜索的计算负担,LSH从大量数据中提取准确的洞察。
结论
局部敏感哈希是一种强大的技术,它加速了来自大型数据库的最近邻搜索。它通过其强大的哈希函数和相似性度量实现了这一点,而没有在准确性上妥协。这是一个关键的方面,使LSH成为您工作中的重要工具。
凭借所有这些优势,LSH使处理高维数据库变得更容易,并提高了AI系统的效率。LSH是一种具有革命性数据检索方法潜力的技术。
探索Python中的lshash和datasketch等库,以便于实现LSH。虽然这些库简化了您的任务,但算法效率取决于良好的配置调整。设计一个良好的配置需要实践知识和足够的实践,因此尝试不同的LSH技术,以拥抱其真正的潜力。
 Haziqa Sajid
Haziqa SajidFreelance Technical Writer